高并发系统设计精讲(二):多线程编程与同步机制
发布时间: 2024-01-03 06:41:10 阅读量: 59 订阅数: 42 

多线程与高并发程序
# 1. 简介
## 1.1 什么是多线程编程
多线程编程是指在一个程序中同时运行多个线程,以达到并发执行任务的目的。每个线程都是独立的执行路径,有自己的代码逻辑、栈和局部变量。多线程编程可以提高程序的效率和响应性,特别是在高并发系统中,能够更好地利用多核处理器的计算能力。
## 1.2 高并发系统的挑战与需求
高并发系统指的是在同一时间段内,系统能够同时处理大量的请求。而在传统的单线程或少线程的情况下,系统往往无法满足大量请求的处理需求。高并发系统面临的主要挑战和需求包括:
- 处理请求的并发性:系统能够同时处理多个请求,提高响应速度;
- 数据的一致性与安全性:系统需要保证各个线程之间的数据一致性,并防止数据竞争和线程安全问题;
- 资源的共享与竞争:系统需要合理管理和分配共享资源,避免资源竞争导致的性能下降和系统崩溃;
- 任务的分解与调度:系统需要将任务合理地分解成多个线程执行,并进行调度和协调,提高系统整体的效率。
在接下来的章节中,我们将详细介绍多线程编程的基础知识、线程并发控制、线程间通信、同步机制的性能优化以及多线程编程的注意事项与最佳实践。
# 2. 多线程基础
在高并发系统中,多线程是一种常见的并发编程模型,通过创建多个线程来处理并发任务,以提高系统的处理能力和性能。本章将介绍多线程编程的基础知识,包括线程与进程的区别、创建线程的方式以及线程的生命周期。
### 2.1 线程与进程的区别
线程是进程的执行单位,一个进程可以包含多个线程。一个进程中的线程共享相同的内存空间,可以直接访问同一进程内的数据,而进程之间是相互独立的。
与进程相比,线程的创建、切换和销毁等操作开销较小,可以更高效地利用计算资源。线程之间的切换也比进程之间的切换更快速,因为在线程切换时只涉及到寄存器、栈和程序计数器等少量数据的保存和恢复。
### 2.2 创建线程的方式
在多线程编程中,可以通过以下两种方式来创建线程:
**1. 继承Thread类**
Java示例代码:
```java
public class MyThread extends Thread {
@Override
public void run(){
// 线程要执行的代码
}
}
// 创建线程对象并启动
MyThread thread = new MyThread();
thread.start();
```
Python示例代码:
```python
import threading
class MyThread(threading.Thread):
def run(self):
# 线程要执行的代码
# 创建线程对象并启动
thread = MyThread()
thread.start()
```
**2. 实现Runnable接口**
Java示例代码:
```java
public class MyRunnable implements Runnable {
@Override
public void run(){
// 线程要执行的代码
}
}
// 创建线程对象并启动
Thread thread = new Thread(new MyRunnable());
thread.start();
```
Python示例代码:
```python
import threading
def my_func():
# 线程要执行的代码
# 创建线程对象并启动
thread = threading.Thread(target=my_func)
thread.start()
```
### 2.3 线程的生命周期
线程的生命周期包括新建、就绪、运行、阻塞和死亡等状态。
- **新建状态(New)**:当线程对象被创建时,它处于新建状态,此时系统资源尚未分配给该线程。
- **就绪状态(Runnable)**:当线程对象调用start()方法后,线程进入就绪状态,等待系统分配执行的时间片。
- **运行状态(Running)**:当就绪状态的线程获得了执行的时间片之后,线程进入运行状态,开始执行run()方法中的代码。
- **阻塞状态(Blocked)**:线程在运行过程中可能会因为某些原因而进入阻塞状态,如等待某个资源的释放或等待I/O操作完成。
- **死亡状态(Dead)**:线程执行完run()方法中的代码后,或者发生异常导致线程终止,线程进入死亡状态。
```java
// Java示例代码
public class MyThread extends Thread {
@Override
public void run(){
// 运行状态
}
public static void main(String[] args) {
MyThread thread = new MyThread(); // 新建状态
thread.start(); // 就绪状态
// ...
}
}
// Python示例代码
import threading
def my_func():
# 运行状态
pass
thread = threading.Thread(target=my_func) # 新建状态
thread.start() # 就绪状态
# ...
```
在实际应用中,通常会涉及到多个线程之间的并发控制和协作。下一章节将介绍线程并发控制的相关内容,包括互斥锁和同步机制等。
# 3. 线程并发控制
在高并发系统中,线程并发控制是非常重要的,它涉及到多个线程之间对共享资源的访问和操作。下面我们将详细讨论线程并发控制的相关内容。
#### 3.1 互斥锁与临界区
在多线程编程中,为了保证共享资源的安全访问,我们通常会使用互斥锁(Mutex)来实现临界区(Critical Section)的保护。这样一来,同一时间只有一个线程可以进入临界区,从而避免了多个线程同时访问共享资源而引发的数据竞争和不确定性结果。下面是一个简单的示例代码:
```java
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class MutexExample {
private int count = 0;
private Lock lock = new ReentrantLock();
public void increment() {
lock.lock();
try {
count++;
} finally {
lock.unlock();
}
}
public int getCount() {
return count;
}
}
```
在上面的示例中,我们使用了ReentrantLock来创建一个互斥锁,然后在increment方法中使用lock()进行加锁操作,在操作完成后使用unlock()进行解锁操作,从而保证了临界区的安全访问。
#### 3.2 相关的同步机制
除了互斥锁外,我们还可以使用其他同步机制来进行线程并发控制,包括信号量、互斥量和条件变量等。这些同步机制在不同的场景下具有各自的特点和优势,可以根据实际需求选择合适的同步机制进行使用。
##### 3.2.1 信号量
信号量是一种经典的同步机制,它可以通过控制许可证的数量来限制并发访问的线程数量。下面是一个简单的Java示例代码:
```java
import java.util.concurrent.Semaphore;
public class SemaphoreExample {
private Semaphore semaphore = new Semaphore(3); // 允许并发访问的线程数量为3
public void accessResource() throws InterruptedException {
semaphore.acquire(); // 获取许可证
try {
// 访问共享资源
} finally {
semaphore.release(); // 释放许可证
}
}
}
```
在上面的示例中,我们使用Semaphore来创建一个允许3个并发访问的信号量,然后在accessResource方法中使用acquire()进行获取许可证,完成后使用release()进行释放许可证。
##### 3.2.2 互斥量
互斥量是一种特殊的信号量,它只允许一个线程访问共享资源。在C++的标准库中,可以使用std::mutex来实现互斥量的功能。
```cpp
#include <mutex>
#include <iostream>
std::mutex g_mutex;
int g_count = 0;
void increaseCount() {
std::lock_guard<std::mutex> lock(g_mutex);
g_count++;
}
int getCount() {
std::lock_guard<std::mutex> lock(g_mutex);
return g_count;
}
int main() {
increaseCount();
std::cout << "Count: " << getCount() << std::endl;
return 0;
}
```
在上面的示例中,我们使用了std::mutex和std::lock_guard来实现互斥量的加锁和解锁操作,从而保证了共享资源的安全访问。
##### 3.2.3 条件变量
条件变量是一种经典的线程同步工具,它可以使线程在某个特定条件下等待或者被唤醒。在C++的标准库中,可以使用std::condition_variable来实现条件变量的功能。
```cpp
#include <condition_variable>
#include <mutex>
#include <thread>
#include <iostream>
std::mutex g_mutex;
std::condition_variable g_cv;
bool g_ready = false;
int g_data = 0;
void producer() {
std::this_thread::sleep_for(std::chrono::seconds(2));
{
std::lock_guard<std::mutex> lock(g_mutex);
g_data = 42;
g_ready = true;
}
g_cv.notify_one();
}
void consumer() {
std::unique_lock<std::mutex> lock(g_mutex);
g_cv.wait(lock, [] { return g_ready; });
std::cout << "The answer is " << g_data << std::endl;
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
```
在上面的示例中,我们使用了std::condition_variable和std::mutex来实现生产者-消费者模式的线程同步,从而保证了条件下的等待和唤醒操作。
这些同步机制在实际的多线程编程中应用广泛,可以根据具体的需求选择合适的同步机制来进行线程并发控制。
# 4. 线程间通信
在高并发系统中,多个线程之间需要进行通信,以便协调各自的工作和共享资源。下面将介绍几种常见的线程间通信方式。
#### 4.1 共享内存
共享内存是最简单、高效的线程间通信方式之一。多个线程可以访问同一块共享内存区域,通过在内存中写入数据和读取数据来进行通信。然而,共享内存的并发控制是一个复杂的问题,需要采取合适的同步机制来保证数据的一致性和避免竞态条件。
以下是一个简单的Python示例,演示了多线程通过共享内存进行通信的场景。
```python
import threading
# 定义一个共享的全局变量
shared_data = 0
# 线程函数,用于向共享内存中写入数据
def write_data():
global shared_data
for _ in range(1000000):
shared_data += 1
# 创建两个线程
thread1 = threading.Thread(target=write_data)
thread2 = threading.Thread(target=write_data)
# 启动线程
thread1.start()
thread2.start()
# 等待线程结束
thread1.join()
thread2.join()
# 打印最终的共享数据
print("Final shared data:", shared_data)
```
代码总结:上述代码创建了两个线程,每个线程都对共享的 `shared_data` 变量进行累加操作。最终打印出 `shared_data` 的值,验证了多线程通过共享内存进行通信的效果。
结果说明:运行该代码会发现,最终打印出的 `shared_data` 值可能不是预期的 `2000000`,这是因为多个线程同时写入 `shared_data` 变量导致的竞态条件问题。
#### 4.2 消息队列
消息队列是另一种常见的线程间通信方式。多个线程可以通过消息队列发送和接收消息,实现解耦和异步通信的目的。消息队列通常基于队列或者发布-订阅模式实现,用于在多个线程之间传递消息。
以下是一个简单的Java示例,演示了多线程通过消息队列进行通信的场景。
```java
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
// 定义一个消息队列
BlockingQueue<String> messageQueue = new LinkedBlockingQueue<>();
// 生产者线程,向消息队列中发送消息
Thread producerThread = new Thread(() -> {
try {
messageQueue.put("Message 1");
messageQueue.put("Message 2");
} catch (InterruptedException e) {
e.printStackTrace();
}
});
// 消费者线程,从消息队列中接收消息
Thread consumerThread = new Thread(() -> {
try {
System.out.println(messageQueue.take());
System.out.println(messageQueue.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
});
// 启动线程
producerThread.start();
consumerThread.start();
```
代码总结:上述代码创建了一个消息队列 `messageQueue`,生产者线程向队列中发送消息,消费者线程从队列中接收消息。通过消息队列实现了多线程间的通信。
结果说明:运行该代码会观察到消费者线程成功接收并打印出生产者线程发送的消息。
#### 4.3 管道与Socket
除了共享内存和消息队列,管道和Socket也是常见的线程间通信方式。在Unix和Linux系统中,管道是一种进程间通信的方式,在多线程编程中,也可以通过管道实现线程间通信。而Socket是一种可实现网络通信的工具,多个线程可以通过Socket实现跨网络的通信。
以上是线程间通信的几种常见方式,不同的场景下可选择不同的通信方式来满足系统设计的需求。
# 5. 同步机制的性能优化
在高并发系统设计中,同步机制的性能优化尤为重要。通过合理选择和使用同步机制,可以有效提高系统的并发处理能力和性能。本节将介绍一些常见的同步机制的性能优化方法。
#### 5.1 自旋锁
自旋锁是一种基于忙等待的锁,当线程尝试获取锁时,如果锁已被其他线程占用,该线程会进行忙等待,不释放CPU的执行权,直到获取到锁为止。自旋锁适用于锁占用时间短、线程竞争不激烈的场景,可以减少线程切换的开销。以下是Java中自旋锁的简单示例:
```java
import java.util.concurrent.atomic.AtomicReference;
public class SpinLock {
private AtomicReference<Thread> owner = new AtomicReference<>();
public void lock() {
Thread currentThread = Thread.currentThread();
while (!owner.compareAndSet(null, currentThread)) {
// 等待获取自旋锁
}
}
public void unlock() {
Thread currentThread = Thread.currentThread();
owner.compareAndSet(currentThread, null);
}
}
```
以上是一个简单的自旋锁实现,在实际应用中需要考虑自旋次数、自旋时间等参数的调优。
#### 5.2 读写锁与多读单写锁
读写锁是指在读操作时可以共享,写操作时需要独占的一种同步机制。在读操作远远多于写操作的场景下,读写锁能显著提高系统的并发性能。而多读单写锁是对读写锁的优化,允许多个线程同时读,但是在写操作时需要独占。Java中的ReentrantReadWriteLock就是一个常用的读写锁实现。
```java
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ReadWriteLockDemo {
private final ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.ReadLock readLock = lock.readLock();
private final ReentrantReadWriteLock.WriteLock writeLock = lock.writeLock();
public void readData() {
readLock.lock();
try {
// 读操作...
} finally {
readLock.unlock();
}
}
public void writeData() {
writeLock.lock();
try {
// 写操作...
} finally {
writeLock.unlock();
}
}
}
```
通过合理使用读写锁,可以充分利用系统资源,提高并发处理能力。
#### 5.3 无锁编程(Lock-free Programming)
无锁编程是一种并发控制的方式,它通过使用CAS(Compare And Swap)等原子操作来实现对共享资源的访问而不需要使用传统的锁机制。无锁编程在高并发场景下能够提供更好的性能和扩展能力,但实现相对复杂,需要开发者对硬件和并发编程有较深的理解。以下是Java中使用AtomicInteger实现的无锁计数器示例:
```java
import java.util.concurrent.atomic.AtomicInteger;
public class LockFreeCounter {
private AtomicInteger count = new AtomicInteger(0);
public void increase() {
count.incrementAndGet();
}
public int getCount() {
return count.get();
}
}
```
以上是无锁计数器的简单示例,通过AtomicInteger提供的CAS操作,可以实现线程安全的并发计数。
在实际应用中,需要根据具体场景选择合适的同步机制,并进行性能测试和调优,以达到最佳的并发性能。
本节介绍了一些常见的同步机制的性能优化方法,包括自旋锁、读写锁与多读单写锁以及无锁编程,通过合理选择和使用这些同步机制,能够有效提高系统的并发处理能力和性能。
# 6. 多线程编程的注意事项与最佳实践
在进行多线程编程时,需要注意一些问题以确保线程安全性和性能。以下是一些常见的注意事项和最佳实践。
#### 6.1 线程安全与线程不安全
多线程环境下,如果多个线程同时访问共享的资源,可能会导致数据的不一致或错误的结果。因此,必须确保多线程操作共享资源时是线程安全的。线程安全意味着多线程同时访问共享资源时不会出现竞态条件(Race Condition)或其他错误。
线程安全的实现方法包括使用互斥锁、信号量、条件变量等同步机制来保护共享资源的访问,或者使用无锁编程(Lock-free Programming)的方式。
#### 6.2 避免死锁与活锁
死锁(Deadlock)是指两个或多个线程互相持有对方所需要的资源,导致它们都无法继续执行的情况。活锁(Livelock)则是指线程不断反复地改变状态,但却无法继续执行下去。
避免死锁和活锁的方法包括避免循环等待、按序获取锁、使用超时机制等。
#### 6.3 锁的粒度控制
锁的粒度控制是指使用合适的锁来保护共享资源的访问。如果锁的粒度过大,即锁住了整个共享资源,可能会导致并发性能下降;如果锁的粒度过小,即锁住了资源中的一个非常小的部分,可能会增加锁的开销,同样会影响并发性能。
需要根据实际场景来选择适当的锁的粒度,尽可能减小锁的竞争范围,以提高并发性能。
#### 6.4 线程池的使用
线程池是一种常用的线程管理方式,可以避免反复创建线程和销毁线程的开销,提高线程的复用性和系统的吞吐量。在并发高的场景下,使用线程池可以更好地管理线程,控制线程数量,避免线程创建和销毁的频繁操作。
使用线程池时,需要根据实际需求设置合适的线程数和队列的大小,以及合理的任务调度策略,以提高系统的并发能力。
以上是多线程编程的一些注意事项和最佳实践,希望能够帮助你在高并发系统设计中进行有效的多线程编程。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《高并发系统设计精讲》专栏全面深入地探讨了高并发系统设计领域的关键问题,通过多篇系统性的文章,囊括了从并行和并发基本概念到高性能网络编程、分布式系统设计原则以及云原生技术的内容。其中,涵盖了多线程编程、并发容器、分布式缓存、分布式数据库、负载均衡算法和性能测试等一系列关键主题,丰富的专栏内容使读者能够全面掌握高并发系统设计的方方面面。此外,专栏还探讨了无锁编程、高效率并发锁、微服务架构等高级话题,针对高可用性系统设计、容灾与数据备份策略、以及云原生技术在高并发系统中的应用进行了深入的论述。无论是对于初学者还是高级工程师,该专栏都提供了宝贵的参考价值,是高并发系统设计领域的系统性学习材料。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CListCtrl行高设置终极指南】:从细节到整体,确保每个环节的完美

# 摘要
CListCtrl是一种常用的列表控件,在用户界面设计中扮演重要角色。本文围绕CListCtrl行高设置展开了详细的探讨,从基本概念到高级应用,深入解析了行高属性的工作原理,技术要点以及代码实现步骤。文章还涉及了多行高混合显示技术、性能优化策略和兼容性问题。通过实践案例分析,本文揭示了常见问题的诊断与解决方法,并探讨了行高设置的
从理论到实践:AXI-APB桥性能优化的关键步骤

# 摘要
本文首先介绍了AXI-APB桥的基础架构及其工作原理,随后深入探讨了性能优化的理论基础,包括性能瓶颈的识别、硬件与软件优化原理。在第三章中,详细说明了性能测试与分析的工具和方法,并通过具体案例研究展示了性能优化的应用。接下来,在第四章中,介绍了硬件加速、缓存
邮件管理自动化大师:SMAIL中文指令全面解析

# 摘要
本文详细介绍了SMAIL邮件管理自动化系统的全面概述,基础语法和操作,以及与文件系统的交互机制。章节重点阐述了SMAIL指令集的基本组成、邮件的基本处理功能、高级邮件管理技巧,以及邮件内容和附件的导入导出操作。此外,文章还探讨了邮件自动化脚本的实践应用,包括自动化处理脚本、邮件过滤和标签自动化、邮件监控与告警。最后一章深入讨论了邮件数据的分析与报告生成、邮件系统的集成与扩展策
车载网络测试新手必备:掌握CAPL编程与应用

# 摘要
CAPL(CAN Application Programming Language)是一种专门为CAN(Controller Area Network)通信协议开发的脚本语言,广泛应用于汽车电子和车载网络测试中。本文首先介绍了CAPL编程的基础知识和环境搭建方法,然后详细解析了CAPL的基础语法结构、程序结构以及特殊功能。在此基础上,进一步探讨了CAPL的高级编程技巧,包括模块化
一步到位!CCU6嵌入式系统集成方案大公开

# 摘要
本文全面介绍了CCU6嵌入式系统的设计、硬件集成、软件集成、网络与通信集成以及综合案例研究。首先概述了CCU6系统的架构及其在硬件组件功能解析上的细节,包括核心处理器架构和输入输出接口特性。接着,文章探讨了硬件兼容性、扩展方案以及硬件集成的最佳实践,强调了高效集成的重要性和集成过程中的常见问题。软件集成部分,分析了软件架构、
LabVIEW控件定制指南:个性化图片按钮的制作教程
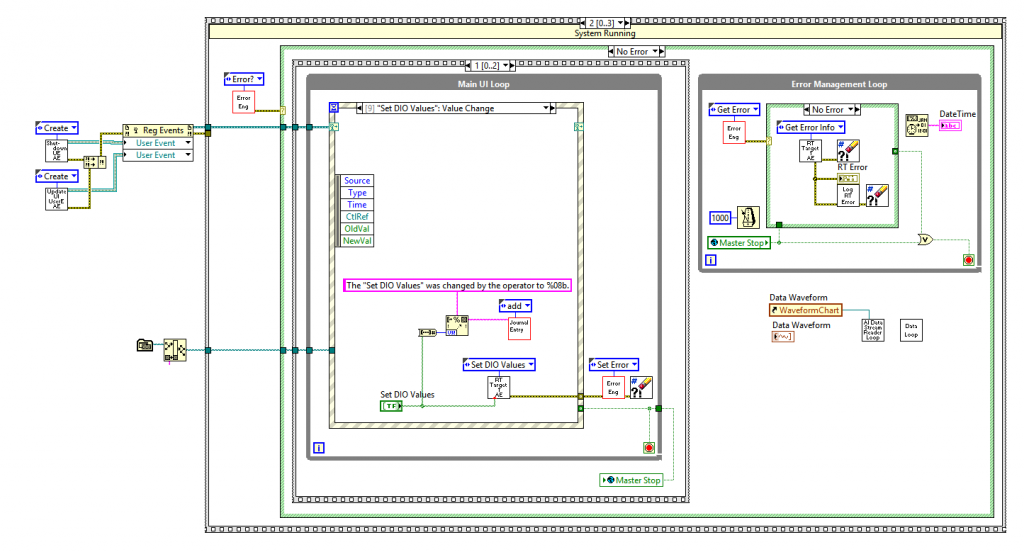
# 摘要
LabVIEW作为一种图形编程环境,广泛应用于数据采集、仪器控制及工业自动化等领域。本文首先介绍了LabVIEW控件定制的基础,然后深入探讨了创建个性化图片按钮的理论和实践。文章详细阐述了图片按钮的界面设计原则、功能实现逻辑以及如何通过LabVIEW控件库进行开发。进一步,本文提供了高级图片按钮定制技巧,包括视觉效果提升、代码重构和模块化设计,以及在复杂应用中的运用
【H3C 7503E多业务网络集成】:VoIP与视频流配置技巧
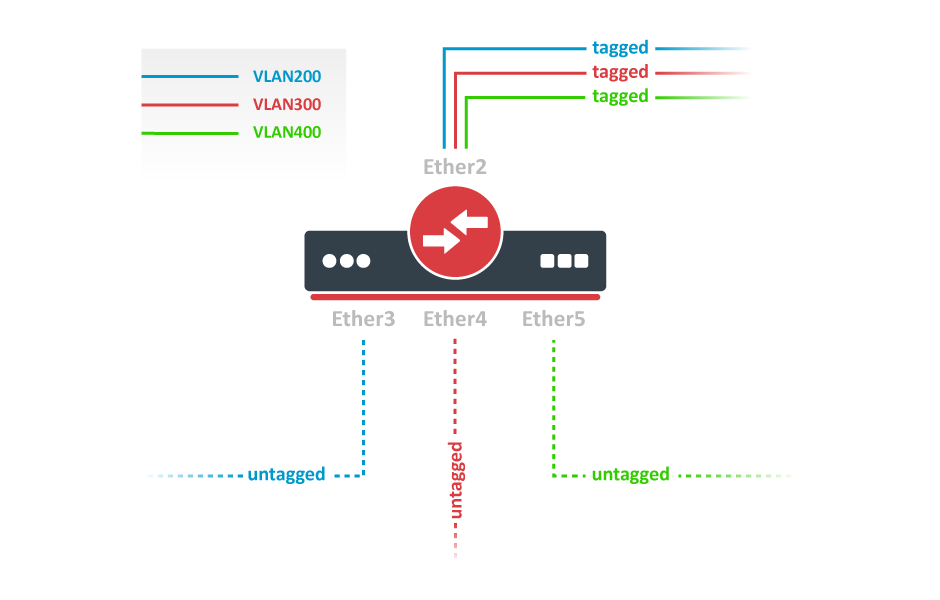
# 摘要
本论文详细介绍了H3C 7503E多业务路由器的功能及其在VoIP和视频流传输领域的应用。首先概述了H3C 7503E的基本情况,然后深入探讨了VoIP技术原理和视频流传输技术的基础知识。接着,重点讨论了如何在该路由器上配置VoIP和视频流功能,包括硬
Word中代码的高级插入:揭秘行号自动排版的内部技巧
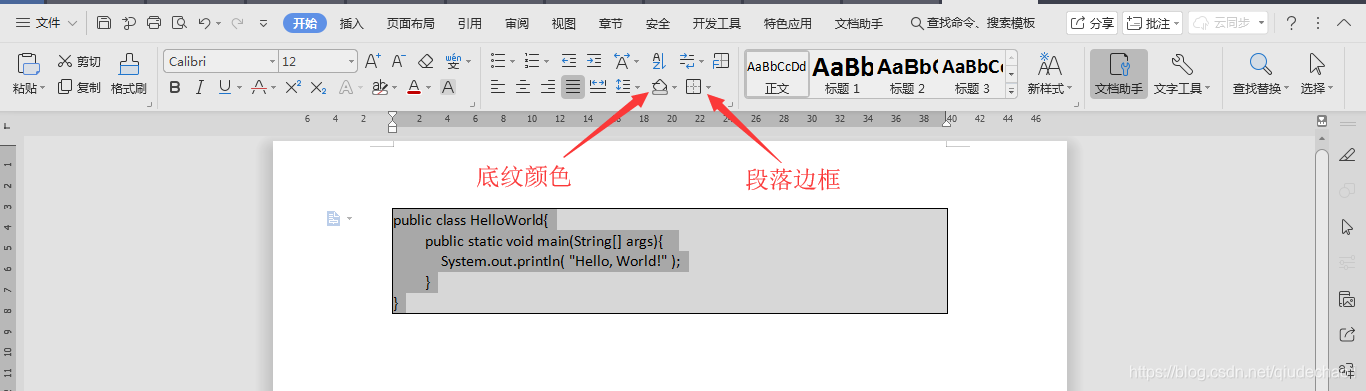
# 摘要
在技术文档和软件开发中,代码排版对于提升文档的可读性和代码的维护性至关重要。本文首先探讨了在Microsoft Word中实现代码排版的常规方法,包括行号自动排版
【PHY62系列SDK技能升级】:内存优化、性能提升与安全加固一步到位

# 摘要
本文针对PHY62系列SDK在实际应用中所面临的内存管理挑战进行了系统的分析,并提出了相应的优化策略。通过深入探讨内存分配原理、内存泄漏的原因与检测,结合内存优化实践技巧,如静态与动态内存优化方法及内存池技术的应用,本文提供了理论基础与实践技巧相结合的内存管理方案。此外,本文还探讨了如何通过性能评估和优化提升系统性能,并分析了安全加固措施,包括安全编程基础、数据加密、访问控制
【JMeter 负载测试完全指南】:如何模拟真实用户负载的实战技巧
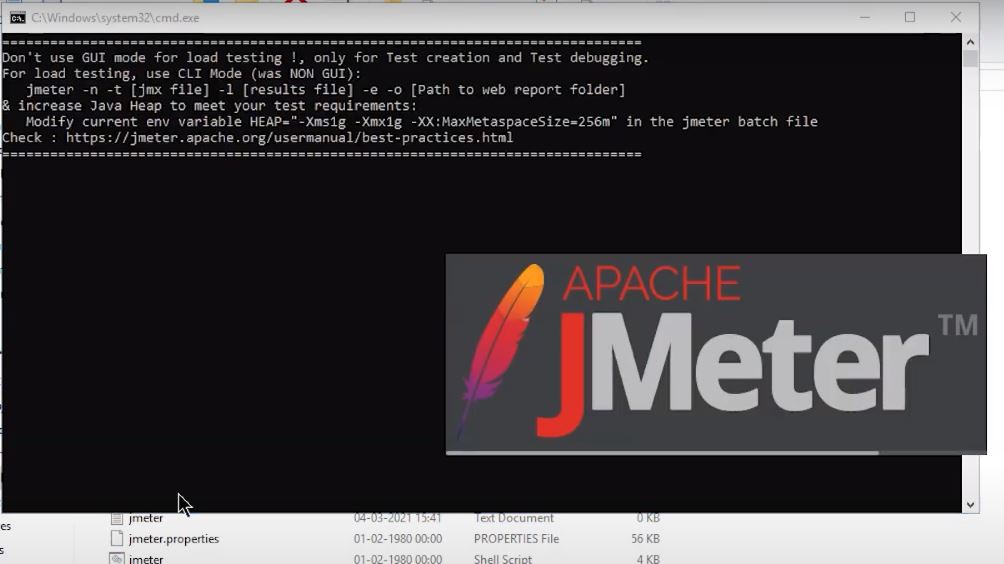
# 摘要
本文对JMeter负载测试工具的使用进行了全面的探讨,从基础概念到高级测试计划设计,再到实际的性能测试实践与结果分析报告的生成。文章详细介绍了JMeter测试元素的应用,测试数据参数化技巧,测试计划结构的优化,以及在模拟真实用户场景下的负载测试执行和监控。此外,本文还探讨了JMeter在现代测试环境中的应用,包括与CI/CD的集成,云服务与分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )