【Python网络编程必看】:只需5步,用BaseHTTPServer打造你的HTTP服务器
发布时间: 2024-10-17 06:24:39 阅读量: 21 订阅数: 30 

Python网络编程实现DHCP服务器
# 1. Python网络编程基础
Python以其简洁的语法和强大的库支持,成为了网络编程的首选语言之一。在本章中,我们将介绍Python网络编程的基础知识,为深入理解BaseHTTPServer模块打下坚实的基础。
网络编程是计算机应用程序之间通过网络进行数据交换的技术。在Python中,网络编程主要涉及套接字(socket)编程。套接字是网络通信的端点,可以理解为网络通信中的“门”或“接口”。
## Python网络编程概念简介
### 套接字(Sockets)
套接字是网络通信的基础,它定义了数据传输的端点。在Python中,套接字操作通常涉及以下几个步骤:
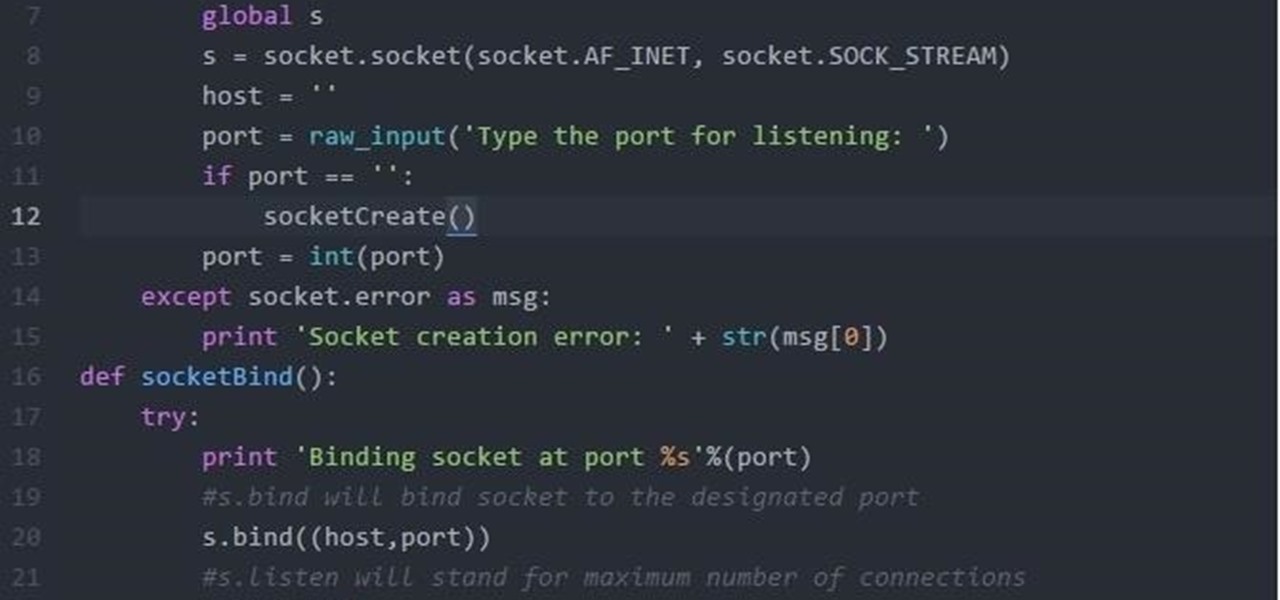
1. 创建套接字:使用`socket.socket()`方法创建套接字对象。
2. 绑定套接字:将套接字绑定到指定的IP地址和端口号上。
3. 监听连接:使用`listen()`方法使套接字进入监听状态。
4. 接受连接:使用`accept()`方法等待并接受客户端的连接请求。
5. 数据传输:使用`send()`和`recv()`方法进行数据的发送和接收。
6. 关闭套接字:使用`close()`方法关闭套接字。
下面是一个简单的TCP服务器示例代码:
```python
import socket
# 创建套接字对象
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 绑定地址和端口
server_socket.bind(('localhost', 8080))
# 监听连接
server_socket.listen()
print("Server is listening on port 8080")
# 接受连接
client_socket, client_address = server_socket.accept()
print(f"Accepted connection from {client_address}")
# 接收数据
data = client_socket.recv(1024)
print(f"Received data: {data.decode()}")
# 发送响应
client_socket.send(b"Hello, client!")
# 关闭套接字
client_socket.close()
server_socket.close()
```
### 网络编程中的重要概念
- **IP地址**:用于标识网络中的设备。
- **端口号**:用于标识设备上运行的网络服务。
- **协议**:规定了数据传输的规则,如TCP和UDP。
通过本章的学习,您将掌握Python网络编程的基本概念和套接字编程的基础知识,为后续深入探讨BaseHTTPServer模块做好准备。
# 2. 深入理解BaseHTTPServer模块
## 2.1 BaseHTTPServer模块概述
### 2.1.1 模块的功能和应用场景
BaseHTTPServer模块是Python标准库中的一个基础模块,用于构建简单的HTTP服务器。它为开发者提供了一个快速搭建基础HTTP服务器的途径,非常适合用于学习和开发小型项目。该模块适用于需要快速原型开发、测试或教学演示的场景。
在本章节中,我们将详细介绍BaseHTTPServer模块的功能和应用场景,帮助读者理解如何利用这一模块快速搭建起一个HTTP服务器,并进行基本的自定义和配置。
### 2.1.2 模块的结构和主要组件
BaseHTTPServer模块主要包括`BaseHTTPRequestHandler`和`HTTPServer`两个类。`BaseHTTPRequestHandler`用于处理HTTP请求,并生成相应的响应。`HTTPServer`则是服务器的核心,负责监听端口并处理连接。
通过本章节的介绍,读者将学会如何使用这两个类来构建一个基本的HTTP服务器,并理解它们在HTTP服务器中的角色和作用。
## 2.2 创建简单的HTTP服务器
### 2.2.1 快速搭建基础服务器的方法
要快速搭建一个基础的HTTP服务器,我们可以直接使用`HTTPServer`和`BaseHTTPRequestHandler`类。下面是一个简单的示例代码,展示了如何创建一个监听本地8080端口的服务器:
```python
from BaseHTTPServer import HTTPServer, BaseHTTPRequestHandler
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b"Hello, world!")
if __name__ == '__main__':
server_address = ('', 8080)
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
httpd.serve_forever()
```
在本章节中,我们详细解释了上述代码,并将逐步介绍如何运行这个服务器,以及如何通过浏览器访问这个服务器来查看输出结果。
### 2.2.2 服务器的自定义和配置
在BaseHTTPServer模块中,我们可以通过继承`BaseHTTPRequestHandler`类来自定义处理不同HTTP请求的方法。例如,我们可以重写`do_GET`方法来处理GET请求,`do_POST`方法来处理POST请求,等等。
此外,我们还可以通过修改`HTTPServer`类的参数来自定义服务器的行为,比如设置超时时间、调整端口监听等。
通过本章节的介绍,读者将学会如何自定义HTTP服务器,以及如何根据需要配置服务器参数。
## 2.3 处理HTTP请求和响应
### 2.3.1 请求和响应对象的结构
在HTTP请求和响应中,每个对象都包含了丰富的信息。请求对象包含了请求行、请求头部和请求正文,而响应对象包含了状态行、响应头部和响应正文。
在本章节中,我们将深入分析HTTP请求和响应对象的结构,并通过代码示例展示如何访问和操作这些信息。
### 2.3.2 状态码和头部信息的管理
HTTP状态码用于表示请求响应的状态,如200表示成功,404表示未找到等。而HTTP头部信息则用于传递额外的元数据,如内容类型、内容长度等。
在本章节中,我们将详细介绍如何管理和操作HTTP状态码和头部信息,包括如何设置状态码、如何添加和修改头部信息等。
在接下来的章节中,我们将进一步探讨如何通过BaseHTTPServer模块构建高效且安全的HTTP服务器,并通过实际案例分析,帮助读者将理论知识应用到实践中。
# 3. 构建高效HTTP服务器的实践
在本章节中,我们将深入探讨如何构建一个高效的HTTP服务器,并着重讲解性能优化、安全性和高级功能的实现。我们将通过代码示例、逻辑分析和参数说明来详细阐述每个概念。
## 3.1 服务器性能优化
### 3.1.1 多线程和多进程服务器模型
为了提高HTTP服务器的性能,我们可以采用多线程或多进程的服务器模型。这些模型可以帮助服务器同时处理多个客户端请求,从而提高并发处理能力。
```python
import socket
import threading
def client_handler(client_socket):
while True:
data = client_socket.recv(1024)
if not data:
break
client_socket.sendall(data)
client_socket.close()
def threaded_http_server(host, port):
server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_socket.bind((host, port))
server_socket.listen(5)
while True:
client_sock, addr = server_socket.accept()
print(f"Accepted connection from {addr}")
client_handler_thread = threading.Thread(target=client_handler, args=(client_sock,))
client_handler_thread.start()
if __name__ == "__main__":
threaded_http_server('localhost', 8000)
```
在这个例子中,我们定义了一个简单的多线程HTTP服务器。每当有新的客户端连接时,服务器都会创建一个新的线程来处理该连接。每个线程都会调用`client_handler`函数,该函数负责接收客户端数据并将其原样返回。
#### 参数说明
- `host`: 服务器绑定的主机名或IP地址。
- `port`: 服务器监听的端口号。
- `server_socket`: 用于监听的socket对象。
- `client_sock`: 接受的客户端连接socket对象。
- `client_handler_thread`: 新创建的线程对象。
#### 执行逻辑说明
1. 创建一个TCP socket对象。
2. 绑定到指定的主机和端口。
3. 监听连接请求。
4. 当有新的连接请求时,接受连接并创建一个新的线程。
5. 在新线程中,接收客户端数据并将其原样返回。
### 3.1.2 异步IO和协程的应用
异步IO和协程是另一种提高服务器性能的有效方法。它们允许服务器在等待I/O操作完成时继续处理其他任务,而不是阻塞等待。
```python
import asyncio
async def client_handler(reader, writer):
while True:
data = await reader.read(1024)
if not data:
break
writer.write(data)
writer.close()
async def main():
server = await asyncio.start_server(client_handler, 'localhost', 8000)
async with server:
await server.serve_forever()
if __name__ == "__main__":
asyncio.run(main())
```
在这个例子中,我们使用了`asyncio`库来创建一个异步IO的HTTP服务器。服务器使用`asyncio.start_server`来启动,并在`main`函数中使用`async with`语句来管理服务器的生命周期。
#### 参数说明
- `reader`: 异步读取客户端请求的读取器。
- `writer`: 异步写入响应的写入器。
- `server`: 异步服务器对象。
#### 执行逻辑说明
1. 使用`asyncio.start_server`启动异步HTTP服务器。
2. 在`main`函数中,使用`async with`语句启动服务器。
3. `await server.serve_forever()`将持续运行服务器,直到被关闭。
## 3.2 安全性考虑
### 3.2.1 SSL/TLS加密通信的实现
为了保护HTTP服务器和客户端之间的通信安全,我们可以使用SSL/TLS来加密通信。
```python
import http.server
import socketserver
import ssl
class HTTPSRequestHandler(http.server.SimpleHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/plain')
self.end_headers()
self.wfile.write(b'Hello, HTTPS!')
PORT = 8443
httpd = socketserver.TCPServer(("", PORT), HTTPSRequestHandler)
httpd.socket = ssl.wrap_socket(httpd.socket, certfile="path/to/certificate.pem", keyfile="path/to/key.pem", server_side=True)
print("Starting HTTPS server on port", PORT)
httpd.serve_forever()
```
在这个例子中,我们使用了`socketserver`模块来创建一个简单的HTTPS服务器。我们通过`ssl.wrap_socket`方法来包装服务器socket,并指定证书和私钥文件来启用SSL/TLS。
#### 参数说明
- `PORT`: 服务器监听的端口号。
- `certfile`: SSL证书文件的路径。
- `keyfile`: SSL私钥文件的路径。
#### 执行逻辑说明
1. 创建一个简单的HTTP服务器。
2. 使用`ssl.wrap_socket`方法包装服务器socket。
3. 指定SSL证书和私钥文件。
4. 启动服务器并监听指定端口。
### 3.2.2 常见的安全漏洞和防护措施
常见的安全漏洞包括SQL注入、跨站脚本攻击(XSS)和跨站请求伪造(CSRF)等。为了防范这些漏洞,我们需要采取相应的防护措施。
#### *.*.*.* SQL注入防护
为了避免SQL注入,我们应该使用参数化查询来处理数据库交互。
```python
import sqlite3
def safe_query(query, params):
connection = sqlite3.connect('example.db')
cursor = connection.cursor()
cursor.execute(query, params)
return cursor.fetchall()
query = "SELECT * FROM users WHERE username=? AND password=?"
params = ('username', 'password')
data = safe_query(query, params)
```
在这个例子中,我们使用了`sqlite3`模块的参数化查询来安全地从数据库中检索数据。
#### 参数说明
- `query`: SQL查询字符串。
- `params`: 与查询相关的参数。
#### 执行逻辑说明
1. 创建数据库连接。
2. 使用参数化查询执行SQL语句。
3. 获取并返回查询结果。
#### *.*.*.* 跨站脚本攻击(XSS)防护
为了防止XSS攻击,我们应该对用户输入进行适当的编码和清理。
```python
import html
def escape_html(text):
return html.escape(text)
user_input = "<script>alert('XSS');</script>"
safe_text = escape_html(user_input)
```
在这个例子中,我们使用了`html.escape`函数来转义用户输入,防止恶意脚本的执行。
#### 参数说明
- `text`: 用户输入的文本。
#### 执行逻辑说明
1. 对用户输入的文本进行HTML转义。
2. 返回转义后的安全文本。
#### *.*.*.* 跨站请求伪造(CSRF)防护
为了防止CSRF攻击,我们应该使用令牌来验证表单提交。
```python
from cryptography.fernet import Fernet
def generate_token():
key = Fernet.generate_key()
cipher_suite = Fernet(key)
token = cipher_suite.encrypt(b'secret')
return token.hex()
def verify_token(token):
key = Fernet.generate_key()
cipher_suite = Fernet(key)
token = cipher_suite.decrypt(bytes.fromhex(token))
return token == b'secret'
token = generate_token()
# Send token to client in form
# On form submission
submitted_token = request.form.get('token')
if verify_token(submitted_token):
print("CSRF token is valid")
else:
print("CSRF token is invalid")
```
在这个例子中,我们使用了`cryptography`库生成和验证CSRF令牌。
#### 参数说明
- `key`: 用于加密和解密的密钥。
- `cipher_suite`: 加密套件。
- `token`: 加密后的令牌。
#### 执行逻辑说明
1. 生成一个CSRF令牌。
2. 将令牌发送到客户端。
3. 在表单提交时验证令牌的有效性。
## 3.3 高级功能实现
### 3.3.1 URL路由和参数解析
为了实现复杂的路由逻辑,我们通常会使用URL路由。这使得我们能够根据请求的URL路径来调用不同的处理函数。
```python
from urllib.parse import urlparse, parse_qs
class RouterHTTPServer(http.server.BaseHTTPRequestHandler):
def do_GET(self):
parsed_path = urlparse(self.path)
if parsed_path.path == '/':
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b'Hello, World!')
elif parsed_path.path == '/info':
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b'Information page')
else:
self.send_error(404, "Page not found")
if __name__ == "__main__":
server_address = ('', 8000)
httpd = http.server.HTTPServer(server_address, RouterHTTPServer)
print("Starting server on port", 8000)
httpd.serve_forever()
```
在这个例子中,我们创建了一个自定义的`RouterHTTPServer`类,它根据请求的URL路径来决定如何响应。
#### 参数说明
- `parsed_path`: 解析后的URL路径对象。
- `self.path`: 请求的原始路径。
#### 执行逻辑说明
1. 解析请求的URL路径。
2. 根据路径决定响应内容。
### 3.3.2 请求和响应的中间件应用
中间件是位于服务器和客户端之间的软件组件,可以用来修改请求或响应数据。
```python
class LoggingMiddleware:
def __init__(self, handler):
self.handler = handler
def __call__(self, request, client_address):
print(f"Request received: {request}")
response = self.handler(request, client_address)
print(f"Response sent: {response}")
return response
class MiddlewareHTTPServer(http.server.BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/plain')
self.end_headers()
self.wfile.write(b'Hello, Middleware!')
if __name__ == "__main__":
server_address = ('', 8000)
httpd = http.server.HTTPServer(server_address, LoggingMiddleware(MiddlewareHTTPServer))
print("Starting server with middleware on port", 8000)
httpd.serve_forever()
```
在这个例子中,我们定义了一个`LoggingMiddleware`中间件,它会在请求处理前后打印日志信息。
#### 参数说明
- `handler`: 被装饰的处理器对象。
#### 执行逻辑说明
1. 创建一个中间件对象,将处理器作为参数传递。
2. 在中间件中调用处理器。
3. 在处理请求前后打印日志。
## 总结
通过本章节的介绍,我们了解了如何构建一个高效的HTTP服务器,并深入探讨了性能优化和安全性考虑。我们还学习了如何实现URL路由、参数解析以及中间件的应用。这些知识将帮助我们构建更加健壮和安全的HTTP服务器。
# 4. 实际案例分析
## 4.1 构建RESTful API服务器
RESTful API是一种基于HTTP协议,使用REST(Representational State Transfer)原则设计的API接口。它是一种资源导向的架构风格,强调无状态的通信,通常使用标准的HTTP方法(如GET、POST、PUT、DELETE)来操作资源。RESTful API设计简洁、易于理解,且易于维护和扩展。
### 4.1.1 RESTful设计原则和实现
RESTful API设计原则包括:
- **资源的URL表示**:每个资源用一个URI(统一资源标识符)表示。
- **统一接口**:使用HTTP协议的标准方法进行资源操作。
- **无状态通信**:服务器不会保存客户端的状态,每次请求都是独立的。
- **使用HTTP状态码**:利用HTTP状态码表达操作结果。
下面是一个简单的RESTful API服务器实现示例,使用Python的Flask框架:
```python
from flask import Flask, jsonify, request
app = Flask(__name__)
# 假设我们有一个用户资源列表
users = [
{'id': 1, 'name': 'Alice'},
{'id': 2, 'name': 'Bob'}
]
@app.route('/users', methods=['GET'])
def get_users():
"""获取用户列表"""
return jsonify(users)
@app.route('/users/<int:user_id>', methods=['GET'])
def get_user(user_id):
"""获取单个用户信息"""
user = next((user for user in users if user['id'] == user_id), None)
if user:
return jsonify(user)
else:
return jsonify({'error': 'User not found'}), 404
@app.route('/users', methods=['POST'])
def create_user():
"""创建新用户"""
user_data = request.get_json()
users.append(user_data)
return jsonify(user_data), 201
if __name__ == '__main__':
app.run(debug=True)
```
在这个例子中,我们定义了三个路由:
- `GET /users`:获取用户列表。
- `GET /users/<user_id>`:通过用户ID获取单个用户信息。
- `POST /users`:创建新的用户。
### 4.1.2 API版本管理和兼容性
API版本管理是RESTful API设计中的一个重要方面,它允许API的迭代和向后兼容。通常,我们通过在URL中包含版本号来实现:
```python
@app.route('/v1/users', methods=['GET'])
def get_users_v1():
# V1版本的用户列表获取逻辑
pass
@app.route('/v2/users', methods=['GET'])
def get_users_v2():
# V2版本的用户列表获取逻辑
pass
```
在这个例子中,我们通过在路径中添加`v1`和`v2`来区分API版本。当API有重大变更时,可以发布新的版本,而不会影响旧版本的调用者。
## 4.2 集成数据库操作
在构建RESTful API时,通常需要与数据库进行交互,以存储和检索数据。以下是如何在我们的API服务器中集成数据库操作的示例:
### 4.2.1 数据库连接和查询操作
我们使用SQLite数据库和SQLAlchemy ORM来管理数据库连接和操作。首先,我们需要安装必要的库:
```bash
pip install flask_sqlalchemy
```
然后,我们可以在Flask应用中配置和使用数据库:
```python
from flask import Flask, jsonify, request
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///example.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
# 定义数据库模型
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(80), nullable=False)
# 创建数据库表
db.create_all()
@app.route('/users', methods=['GET'])
def get_users():
users = User.query.all()
return jsonify([{'id': user.id, 'name': user.name} for user in users])
@app.route('/users/<int:user_id>', methods=['GET'])
def get_user(user_id):
user = User.query.get_or_404(user_id)
return jsonify({'id': user.id, 'name': user.name})
@app.route('/users', methods=['POST'])
def create_user():
user_data = request.get_json()
new_user = User(name=user_data['name'])
db.session.add(new_user)
***mit()
return jsonify({'id': new_user.id, 'name': new_user.name}), 201
if __name__ == '__main__':
app.run(debug=True)
```
在这个例子中,我们定义了一个`User`模型,并在数据库中创建了相应的表。然后,我们在API中添加了对用户的增删改查操作。
### 4.2.2 服务器与数据库的交互实例
下面是一个服务器与数据库交互的实例,展示了如何处理一个用户的注册请求:
```python
from flask import Flask, jsonify, request
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///example.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
# 定义数据库模型
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(80), nullable=False)
# 创建数据库表
db.create_all()
@app.route('/register', methods=['POST'])
def register_user():
user_data = request.get_json()
if User.query.filter_by(name=user_data['name']).first():
return jsonify({'error': 'User already exists'}), 409
new_user = User(name=user_data['name'])
db.session.add(new_user)
***mit()
return jsonify({'id': new_user.id, 'name': new_user.name}), 201
if __name__ == '__main__':
app.run(debug=True)
```
在这个例子中,我们定义了一个`/register`路由,用于处理新用户的注册请求。我们首先检查数据库中是否已经存在同名的用户,如果存在,则返回409冲突状态码。如果不存在,我们创建新用户并保存到数据库中。
## 4.3 日志管理和错误处理
日志记录和错误处理是API服务器运行中不可或缺的两个方面。它们有助于监控服务器状态、调试问题以及提供给用户有意义的错误信息。
### 4.3.1 日志记录的策略和方法
日志记录通常使用Python的`logging`模块,它提供了灵活的日志记录系统。以下是如何在Flask应用中配置和使用日志记录的示例:
```python
import logging
from flask import Flask
app = Flask(__name__)
# 配置日志记录
logging.basicConfig(level=***)
@app.route('/hello')
def hello():
***('Someone visited /hello')
return 'Hello, World!'
if __name__ == '__main__':
app.run(debug=True)
```
在这个例子中,我们配置了基础日志记录,当有人访问`/hello`路由时,会在控制台输出一条信息日志。
### 4.3.2 异常捕获和错误响应定制
为了处理异常和错误,我们可以使用Flask的`@app.errorhandler`装饰器来定义错误处理函数。以下是如何自定义错误响应的示例:
```python
from flask import Flask, jsonify, make_response
from werkzeug.exceptions import HTTPException
app = Flask(__name__)
@app.errorhandler(HTTPException)
def handle_exception(e):
"""全局异常处理"""
response = e.get_response()
response.data = jsonify({
"code": e.code,
"name": e.name,
"description": e.description,
}).data
response.content_type = "application/json"
return response
@app.route('/fail')
def fail():
raise Exception("This is a test exception.")
if __name__ == '__main__':
app.run(debug=True)
```
在这个例子中,我们定义了一个全局异常处理函数,它将所有HTTP异常转换为JSON格式的响应。当访问`/fail`路由时,会触发一个异常,并返回一个自定义的JSON错误响应。
通过以上内容,我们已经展示了如何构建RESTful API服务器,集成数据库操作,以及进行日志管理和错误处理。这些知识对于开发健壮、可靠的API服务至关重要。
# 5. 扩展和部署HTTP服务器
在构建HTTP服务器的过程中,我们不仅要关注其功能实现和性能优化,还需要考虑如何扩展其功能以及如何将其部署到生产环境中。本章节将深入探讨服务器的扩展模块和部署策略,并提供一些维护和监控的建议。
## 5.1 服务器的扩展模块
随着业务需求的增长,单一的功能可能无法满足复杂的场景。因此,我们需要了解如何通过模块化设计和重用代码来扩展服务器的功能,以及如何使用第三方扩展模块来丰富服务器的生态。
### 5.1.1 模块化设计和重用代码
模块化设计是软件工程中的一种重要理念,它可以帮助开发者将复杂的系统分解为更小、更易于管理的模块。在Python中,模块化通常通过定义模块、包和类来实现。
```python
# example_module.py
def example_function():
print("This is an example function.")
class ExampleClass:
def __init__(self):
print("This is an example class.")
def main():
example_function()
example_class = ExampleClass()
if __name__ == "__main__":
main()
```
在上述代码中,我们定义了一个模块`example_module.py`,它包含了函数和类。这样的设计可以很容易地在不同的模块之间重用代码。
#### 模块化设计的优势
1. **代码重用**:模块化使得代码可以在多个项目中共享,提高了开发效率。
2. **便于维护**:模块化的设计使得代码更易于维护和升级。
3. **解耦合**:通过模块化,我们可以将业务逻辑和功能分离,降低了代码之间的依赖。
### 5.1.2 第三方扩展模块的使用
Python拥有一个庞大的第三方模块库,其中不乏一些针对HTTP服务器开发的扩展模块。使用这些模块可以极大地扩展HTTP服务器的功能。
#### 使用第三方模块的步骤
1. **查找模块**:通过Python Package Index (PyPI)查找满足需求的第三方模块。
2. **安装模块**:使用pip工具安装所需的模块。
3. **集成模块**:在项目中导入并使用第三方模块。
```python
# 使用requests模块发送HTTP请求
import requests
response = requests.get('***')
print(response.text)
```
在上述代码中,我们使用了`requests`模块来发送HTTP请求。这是一个典型的第三方模块使用案例。
### 5.1.3 第三方模块的维护
使用第三方模块时,需要注意模块的版本兼容性和安全性。定期检查模块的更新,并关注安全公告,以确保系统的安全性和稳定性。
## 5.2 服务器的部署策略
部署HTTP服务器是将我们的应用推向生产环境的关键步骤。本节将介绍从本地环境到生产环境的过渡,以及云服务和容器化部署的相关知识。
### 5.2.1 本地环境到生产环境的过渡
在开发过程中,我们通常在本地环境中测试和调试应用。当应用准备就绪后,需要将其部署到生产环境。
#### 过渡步骤
1. **代码审查**:确保代码符合生产环境的要求。
2. **配置管理**:设置生产环境的配置文件。
3. **测试部署**:在预发布环境中进行测试。
4. **监控部署**:部署后进行性能监控。
### 5.2.2 云服务和容器化部署
随着云计算技术的发展,云服务和容器化技术成为了部署HTTP服务器的主流方式。
#### 云服务
云服务提供了弹性的计算资源和托管服务,使得部署和扩展服务器变得更加容易。
#### 容器化部署
容器化技术如Docker可以将应用及其依赖打包,确保在不同环境中的一致性。
```yaml
# Dockerfile 示例
FROM python:3.8
WORKDIR /app
COPY . /app
RUN pip install -r requirements.txt
CMD ["python", "server.py"]
```
上述`Dockerfile`定义了一个容器镜像,其中包含了应用的运行环境和启动命令。
## 5.3 维护和监控
即使HTTP服务器部署到生产环境后,也需要对其进行维护和监控,以确保其稳定运行。
### 5.3.1 服务器运行状态监控
监控服务器的运行状态是确保服务稳定性的关键。我们可以使用各种工具来监控服务器的性能指标。
#### 监控工具
- **Prometheus**:一个开源的监控解决方案,可以用来收集和存储指标数据。
- **Grafana**:一个开源的数据可视化工具,可以用来展示监控数据。
### 5.3.2 性能调优和问题诊断
性能调优和问题诊断是维护服务器时不可忽视的环节。通过分析服务器的性能指标,我们可以发现潜在的问题并进行优化。
#### 性能调优步骤
1. **收集性能数据**:使用监控工具收集性能数据。
2. **分析瓶颈**:识别性能瓶颈。
3. **调整配置**:根据分析结果调整服务器配置。
4. **测试优化效果**:验证调优效果。
通过本章节的介绍,我们了解了如何通过模块化设计和第三方扩展模块来增强HTTP服务器的功能,以及如何将服务器从本地环境部署到生产环境,并且掌握了服务器运行状态的监控和性能调优的方法。这些知识对于构建和维护一个高效、稳定的HTTP服务器至关重要。
# 6. HTTP服务器的高级功能实现
## 6.1 URL路由和参数解析
### 6.1.1 路由实现的必要性
在构建HTTP服务器时,路由是根据URL的不同路径来分发请求到相应的处理函数的过程。这对于创建RESTful API或者多页面应用是非常关键的。
### 6.1.2 参数解析
参数解析则是从URL中提取特定的数据,例如在路径`/user/<id>`中,`<id>`就是一个参数,需要从请求的URL中解析出来以便后续处理。
### 6.1.3 路由和参数解析的代码示例
```python
from BaseHTTPServer import BaseHTTPRequestHandler, HTTPServer
import urllib
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
routes = {
'/': handle_root,
'/user/<id>': handle_user
}
def do_GET(self):
parsed_path = urllib.parse.urlparse(self.path)
path = parsed_path.path.lstrip('/')
handler = self.routes.get(path)
if handler:
handler(self)
else:
self.send_error(404, "Not Found")
def handle_root(self):
self.send_response(200)
self.send_header('Content-type', 'text/plain')
self.end_headers()
self.wfile.write(b'Welcome to the home page!')
def handle_user(self):
parsed_path = urllib.parse.urlparse(self.path)
params = urllib.parse.parse_qs(parsed_path.query)
user_id = params.get('id', [''])[0]
self.send_response(200)
self.send_header('Content-type', 'text/plain')
self.end_headers()
self.wfile.write(f"User ID: {user_id}".encode())
if __name__ == '__main__':
server_address = ('', 8080)
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
httpd.serve_forever()
```
## 6.2 请求和响应的中间件应用
### 6.2.1 中间件的概念
中间件是在请求处理流程中的某个特定点插入的处理函数,它可以在请求到达处理函数之前或响应发送到客户端之前执行。
### 6.2.2 中间件的应用场景
中间件常用于实现认证、日志记录、请求数据预处理等功能。
### 6.2.3 中间件的代码示例
```python
def auth_middleware(handler):
def wrapper(self):
auth_header = self.headers.get('Authorization')
if not auth_header:
self.send_error(401, "Unauthorized")
return
# 进行身份验证...
handler(self)
return wrapper
class AuthenticatedHTTPRequestHandler(SimpleHTTPRequestHandler):
before_request = auth_middleware
def do_GET(self):
self.before_request(self)
# 继续后续的请求处理
super().do_GET()
if __name__ == '__main__':
# 使用修改后的请求处理器
httpd = HTTPServer(server_address, AuthenticatedHTTPRequestHandler)
httpd.serve_forever()
```
## 6.3 案例分析:集成第三方身份验证
### 6.3.1 身份验证的重要性
在实际应用中,身份验证是保护资源安全的重要手段,确保只有授权用户才能访问特定的资源。
### 6.3.2 第三方身份验证服务的集成
集成第三方身份验证服务,如OAuth、JWT等,可以简化身份验证流程,并提供更强的安全性。
### 6.3.3 第三方身份验证的代码示例
```python
import jwt
class JWTHTTPRequestHandler(SimpleHTTPRequestHandler):
secret_key = 'your_secret_key'
def auth_middleware(self):
auth_header = self.headers.get('Authorization')
if auth_header:
try:
token = auth_header.split(' ')[1]
payload = jwt.decode(token, self.secret_key, algorithms=["HS256"])
self.user_id = payload['user_id']
except Exception as e:
self.send_error(401, "Unauthorized")
return
return self.do_GET
def do_GET(self):
self.auth_middleware()
if hasattr(self, 'user_id'):
# 继续处理请求,但已知用户ID
self.send_response(200)
self.send_header('Content-type', 'text/plain')
self.end_headers()
self.wfile.write(f"Welcome, User ID: {self.user_id}".encode())
else:
super().do_GET()
if __name__ == '__main__':
# 使用带有JWT的请求处理器
httpd = HTTPServer(server_address, JWTHTTPRequestHandler)
httpd.serve_forever()
```
通过上述代码示例,我们可以看到如何在HTTP服务器中实现URL路由、参数解析、请求和响应的中间件应用,以及如何集成第三方身份验证服务。这些高级功能的实现,使得HTTP服务器变得更加灵活和强大,能够满足更多复杂的应用场景需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习专栏,我们将深入探索 BaseHTTPServer.BaseHTTPRequestHandler 类。本专栏涵盖了从基础到高级的广泛主题,包括:
* BaseHTTPRequestHandler 类的深入解析
* 构建自定义 HTTP 服务的实战教程
* 提升 Python 网络编程能力的高级技巧
* BaseHTTPServer 高效请求处理机制的揭秘
* 用 BaseHTTPServer 构建简易文件服务器的实战案例
* BaseHTTPServer 和 BaseHTTPRequestHandler 的应用与实践
* 错误处理、日志记录和性能优化技巧
* BaseHTTPRequestHandler 的安全性最佳实践
* 多线程应用案例和 HTTP 方法扩展
* 动态内容生成和静态文件服务的实战技巧
* 自定义 HTTP 方法和请求分发机制
* HTTP 请求编码和连接管理策略
通过本专栏,您将掌握 BaseHTTPRequestHandler 类的方方面面,并提升您的 Python 网络编程技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Spartan FPGA编程实战:新手必备的基础编程技巧

# 摘要
本论文首先介绍FPGA(现场可编程门阵列)的基础知识,特别是Xilinx公司的Spartan系列FPGA。接着深入探讨Spartan FPGA的硬件设计入门,包括其基本组成、硬件描述语言(HDL)基础和开发工具。本文还涉及Spartan FPGA的编程实战技巧,例如逻辑设计、时序约束、资源管理和布局布线。随后,论文深入介绍了高级
【安川E1000系列深度剖析】:全面解读技术规格与应用精髓

# 摘要
安川E1000系列伺服驱动器凭借其创新技术及在不同行业的广泛应用而受到关注。本论文首先提供了该系列产品的概览与技术创新的介绍,随后详细解析了其核心技术规格、控制技术和软件配套。通过具体应用案例分析,我们评估了技术规格对性能的实际影响,并探讨了软件集成与优化。此外,论文还分析了E1000系列在工业自动化、精密制造及新兴行业中的应用情况,并提出了故障诊断、维护保养策略和高级维护技术。最后,对安川E1000系列的技术发
【DirectX故障排除手册】:一步步教你如何解决运行时错误
# 摘要
DirectX技术是现代计算机图形和多媒体应用的核心,它通过提供一系列的API(应用程序编程接口)来优化视频、音频以及输入设备的交互。本文首先对DirectX进行了简介,并探讨了运行时错误的类型和产生的原因,重点分析了DirectX的版本及兼容性问题。随后,文章详细介绍了D
提升效率:五步优化齿轮传动,打造高性能二级减速器

# 摘要
齿轮传动作为机械设计中的一项核心技术,其基本原理和高效设计对于提升机械系统的性能至关重要。本文首先概述了齿轮传动的基础理论及其在工业中的重要性,随后深入探讨了齿轮设计的理论基础,包括基本参数的选择、传动效率的理论分析,以及设计原则。紧接着,文章对二级减速器的性能进行了分析,阐述了其工作原理、效率提升策略和性能评估方法。案例研究表明了优化措施的实施及其效果评估,揭示了通过具体分析与改进,
FPGA深度解读:揭秘DDS IP技术在信号生成中的关键应用

# 摘要
本论文全面介绍了现场可编程门阵列(FPGA)与直接数字合成(DDS)技术,并详细探讨了DDS IP核心的原理、实现、参数详解及信号调制技术。通过对FPGA中DDS IP应用实践的研究,展示了基本和高级信号生成技术及其集成与优化方法。同时,本文通过案例分析,揭示了DDS IP在通信系统、雷达导航和实验室测试仪
【Winedt高级定制指南】:深度个性化你的开发环境
# 摘要
Winedt是一款功能强大的文本编辑器,它以强大的定制潜力和丰富的功能插件深受用户喜爱。本文首先介绍了Winedt的基本概念和界面自定义方法,包括界面主题、颜色方案调整、窗口布局、快捷键配置以及智能提示和自动完成功能的强化。接着,本文探讨了如何通过插件进行功能扩展,特别是在编程语言支持和代码分析方面。文章进一步深入到Winedt的脚本和宏功能,讲解了基础脚本编写、高级应用及宏的录制和管理。此外,本文还分析了Winedt在项目管理中的应用,如项目文件组织、版本控制和远程管理。最后,探讨了性能优化和故障排除的策略,包括性能监控、常见问题解决及高级定制技巧分享,旨在帮助用户提高工作效率并优
Linux内核深度解析:专家揭秘系统裁剪的9大黄金法则
# 摘要
Linux内核系统裁剪是一个复杂的过程,它涉及到理论基础的掌握、实践技巧的运用和安全性的考量。本文首先提供了Linux内核裁剪的概览,进而深入探讨了内核裁剪的理论基础,包括内核模块化架构的理解和裁剪的目标与原则。随后,文章着重介绍了具体的实践技巧,如常用工具解析、裁剪步骤和测试验证方法。此外,还讨论了针对特定应用场景的高级裁剪策略和安全加固的重要性。最后,本文展望了Linux内核裁剪未来的发展趋势与挑战,
【用例图与敏捷开发】:网上购物快速迭代的方法论与实践

# 摘要
本文探讨了用例图在敏捷开发环境中的应用和价值。通过分析敏捷开发的理论基础、用例图的绘制和验证方法,以及网上购物系统案例的实践应用,本文揭示了用例图如何在需求管理、迭代规划和持续反馈中发挥作用。特别强调了用例图在指导功能模块开发、功能测试以及根据用户反馈不断迭代更新中的重要性。文章还讨论了敏捷团队如何应对挑战并优化开发流程。通过整合敏捷开发的理论与实践,本文为用例图在快速迭
【KISSsoft全面指南】:掌握齿轮设计的七个秘密武器(从入门到精通)

# 摘要
齿轮设计是机械传动系统中不可或缺的环节,本文系统介绍了齿轮设计的基础理论、参数设置与计算方法。通过深入探讨KISSsoft这一专业齿轮设计软件的界面解析、高级功能应用及其在实际案例中的运用,本文为齿轮设计的专业人士提供了优化齿轮传动效率、增强设计可靠性以及进行迭代优化的具体手段。同时,本文还展望了数字化、智能化技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )