云存储同步攻略:rsync整合AWS S3、Azure Blob Storage
发布时间: 2024-12-11 15:17:39 阅读量: 4 订阅数: 17 

Acronis Backup:Acronis备份策略设计原理.docx
# 1. 云存储同步基础与rsync工具概述
云计算已经成为现代IT架构不可或缺的一部分,其中云存储同步是数据管理和备份的关键环节。对于云存储同步而言,理解基础概念至关重要,这包括数据冗余、数据一致性和网络传输效率等方面。
## 1.1 云存储同步的定义和重要性
云存储同步指的是在不同云服务提供商或云环境中,保持数据副本的实时或定期更新。这涉及到多个层面的操作,包括数据的上传、下载、更新和删除等。同步服务可以确保在发生硬件故障或需要数据恢复时,用户能迅速地从同步的副本中恢复数据,降低业务中断的风险。此外,数据一致性是同步过程中的重要考量,直接影响数据的准确性和可靠性。
## 1.2 rsync工具的功能和优势
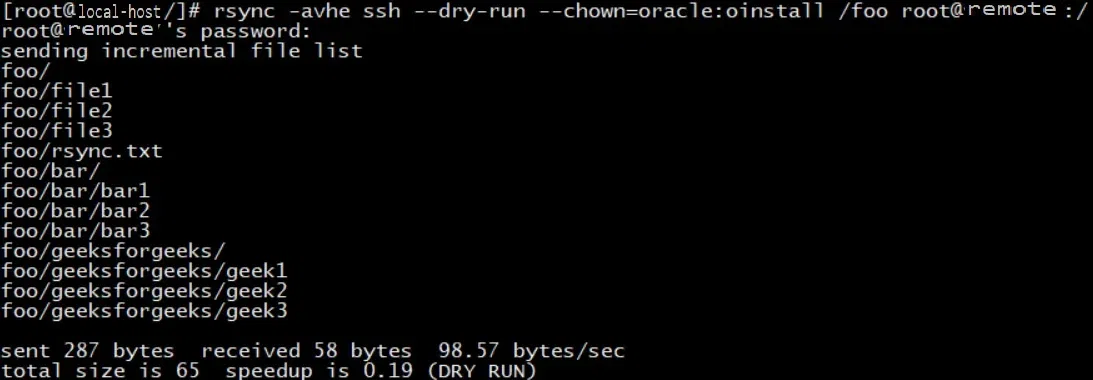
rsync是一个在Unix-like系统上广泛使用的文件传输和同步工具,它特别适合于大规模文件同步场景。rsync的一个显著优势是它的增量同步能力,仅传输文件的差异部分,而非整个文件,从而大大提升了数据传输的效率。rsync通过比较文件的修改时间戳和大小来识别需要同步的内容,有效减少了不必要的数据传输。
## 1.3 rsync在云存储同步中的应用
在云存储同步中,rsync可以与多种存储解决方案集成,例如本地服务器与云存储之间的同步、跨云存储平台的数据同步等。借助rsync,用户能够灵活地管理数据同步任务,实现复杂的同步策略,比如排除不需要同步的文件类型,或者基于文件内容进行同步。通过合理配置rsync的参数,还可以进一步优化同步过程,比如设置合适的缓冲区大小和连接数,以最大化传输速率并减少延迟。
下一章将探讨如何将rsync与AWS S3集成,以及如何利用AWS的服务来实现高效和安全的云存储同步。
# 2. AWS S3集成rsync同步机制
### 2.1 AWS S3云服务基础
#### 2.1.1 S3存储概述
AWS S3(Simple Storage Service)是亚马逊提供的一个高度可扩展的对象存储服务,用于存储和检索任意量的数据。对象存储是一种数据存储架构,其中数据被当作对象来存储,而每个对象都包含数据本身、可选的元数据以及唯一标识符。S3支持多种用途,如网站托管、大数据分析、灾难恢复和云应用数据存储。
使用S3,用户可以存储任何类型的数据,例如文本、图像、视频或音频文件。S3存储类别提供了不同级别的冗余性、可访问性和成本效益,以满足不同存储需求。
- **标准**:为经常访问的数据提供高可用性和耐用性。
- **标准-IA**:对于访问频率较低的大量数据提供较低的成本。
- ** одно AZ**:对频繁访问,需要数据持久性并且分布在单一可用区的数据。
- **智能分层**:自动在S3标准和S3标准-IA之间转换,根据访问频率优化存储成本。
- **归档**:为长期归档而设计,可提供最高的数据持久性,但访问成本高。
S3提供一个全局统一命名空间,意味着用户可以访问任意数量的数据。另外,S3与AWS的其他服务紧密集成,如EBS、EC2等,可以实现跨服务的数据复制和备份。
#### 2.1.2 访问控制和权限管理
访问控制和权限管理是确保数据安全的重要方面,AWS S3通过提供细致的权限模型来支持这一点。每个S3存储桶和对象都可以设置访问控制列表(ACLs)、策略和存储桶策略来控制访问。
- **访问控制列表 (ACLs)**:S3的ACLs允许用户设置特定的权限,如谁可以读取或写入特定对象或存储桶。
- **IAM策略**:通过使用AWS IAM(身份和访问管理),可以创建策略来控制对S3资源的访问,这些策略可以附加到IAM用户、用户组或角色。
- **存储桶策略**:它们允许用户为S3存储桶定义更精细的访问控制规则,也可以用来实现跨账户访问。
- **S3桶加密**:支持使用SSE(服务器端加密)来保护存储在S3中的数据,AWS自动管理加密密钥,用户也可以使用自己的密钥。
使用这些权限管理工具,用户可以确保数据的保密性、完整性和可用性。
### 2.2 rsync与AWS CLI的结合使用
#### 2.2.1 AWS CLI的安装与配置
AWS CLI(命令行接口)是一个命令行工具,它允许用户直接从命令行访问AWS服务。对于使用rsync进行数据同步,AWS CLI能够提供必要的接口与AWS服务交互。
要开始使用AWS CLI,您需要按照以下步骤进行安装和配置:
1. **下载AWS CLI**:访问AWS官方网站下载适合您操作系统的CLI版本。
2. **安装AWS CLI**:根据操作系统的要求进行安装。对于多数Linux发行版,可以使用包管理器进行安装,例如在Ubuntu中使用`sudo apt install awscli`。
3. **配置AWS CLI**:安装完成后,使用`aws configure`命令设置您的AWS凭证,访问密钥和密钥ID,它们通常可以在AWS IAM账户设置中找到。此外,还需指定默认区域(region)和输出格式(比如json)。
命令示例:
```sh
aws configure
```
输出:
```plaintext
AWS Access Key ID [None]: AKID1234567890
AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Default region name [None]: us-west-2
Default output format [None]: json
```
#### 2.2.2 rsync与AWS CLI的命令集成
rsync可以通过SSH与AWS CLI结合使用,实现本地文件系统和S3存储桶之间的同步。这种方式允许用户利用rsync的高级同步功能,并通过AWS CLI将文件上传到S3。
```sh
rsync -avz -e "ssh -i /path/to/key.pem" /local/path/ user@hostname:/s3-bucket/path/
```
参数解释:
- `-a`: 保留文件属性,包括链接、权限等。
- `-v`: 详细模式输出。
- `-z`: 压缩数据。
- `-e`: 指定要使用的shell程序或命令。
- `-i`: 显示同步过程中传输文件的详细信息。
要实现自动化同步,可以结合使用AWS CLI中的`aws s3 sync`命令,该命令在后台调用rsync,简化了同步过程:
```sh
aws s3 sync /local/path/ s3://bucket-name/path/
```
此命令将本地路径与指定的S3存储桶路径同步。
### 2.3 S3同步实践案例分析
#### 2.3.1 基本同步操作流程
基本的S3同步操作流程包括确定本地和远程路径、使用AWS CLI的`sync`命令进行同步,以及检查同步后的结果。以下是详细的操作步骤:
1. **准备本地文件**:确保需要同步的文件在本地路径中正确存放。
2. **配置AWS CLI**:按照之前提供的步骤配置AWS CLI。
3. **执行同步命令**:使用AWS CLI执行`sync`命令,将数据同步到S3存储桶:
```sh
aws s3 sync /local/path/ s3://my-bucket/path/
```
4. **验证同步结果**:通过S3管理控制台或者使用AWS CLI检查存储桶中同步的文件。
#### 2.3.2 高级同步参数与优化
在数据同步过程中,高级参数的使用可以显著优化同步操作,比如使用排除模式来忽略特定文件或目录,或者使用带宽限制来防止同步操作占用过多带宽。
- **排除特定文件或目录**:使用`--exclude`参数,可以指定一个或多个不需要同步到S3的文件或目录。例如:
```sh
aws s3 sync /local/path/ s3://my-bucket/path/ --exclude "*.tmp" --exclude "logs/"
```
- **带宽限制**:使用`--acl`参数可以控制数据传输过程中的带宽占用。例如,限制为1MB/s:
```sh
aws s3 sync /local/path/ s3://my-bucket/path/ --acl public-read --bwlimit 1024
```
- **使用多线程**:`--parallel-count`参数允许您指定并行上传的线程数,这对于上传大量小文件非常有用:
```sh
aws s3 sync /local/path/ s3://my-bucket/pat
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Linux 中使用 rsync 进行文件同步的方方面面。从安全防护秘技(如加密和认证机制)到性能优化秘籍(如调整参数提升效率),再到跨越网络障碍的解决方案,该专栏提供了全面的指南。此外,它还介绍了 rsync 与 SSH 配合使用的安全远程同步指南,以及 Linux 文件系统差异比较和 rsync 应用的版本控制新篇。对于企业级文件同步,该专栏提供了 rsync 脚本化管理构建平台的建议。为了增强监控和故障排除,它介绍了实时监控 rsync 的方法。最后,该专栏还分析了虚拟化环境中 rsync 的应用案例,并比较了 rsync 与其他同步工具的安全性、速度和兼容性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【性能优化实战】:RoseMirror HA 7.0集群调优全面指南
# 摘要
随着信息技术的快速发展,集群技术在保证高可用性和提升性能方面扮演了关键角色。本文综合介绍了RoseMirror HA 7.0集群技术,深入探讨了集群性能优化的理论基础和实施技巧。文章详细分析了性能瓶颈的识别方法、集群硬件及软件层面的调优实践,并结合案例展示了监控与故障诊断的有效策略。通过理论与实践相
【数据导出技巧】:高效使用Wind Excel插件导出数据

# 摘要
本文全面介绍数据导出的基本概念和重要性,并深入探讨了Wind Excel插件的安装、配置及使用技巧。详细说明了如何安装和配置插件,掌握其界面和功能,并提供了数据导出过程中的技巧和高级应用。文章还介绍了导出数据的格式转换,优化大数据量导出的策略,以及如何在自动化脚本中集成Wind Excel插件。通过案例分析,展示了金融、市场
JIS与MDS深度对比:解锁作业三单多样性的秘密
# 摘要
本文旨在解析JIS(Job Information System)和MDS(Management Data System)的概念,并比较两者的基本架构及其在作业三单多样性实现上的不同方法。通过详细阐述两种系统的架构组成、作业单管理策略,以及集成与互操作性机制,本文揭示了JIS与MDS在设计理念、功能性能以及对组织管理影响方面的差异。此外,本文还分析了JIS和MDS在不同行业应用中的案例,提取了实施过程中的成功要素和面临的挑战,为相关行业提供了宝贵的参考和启示。
# 关键字
JIS;MDS;作业三单;集成能力;互操作性;应用案例分析
参考资源链接:[提升效率:SOS、JIS、MDS
深入理解HART协议:掌握命令交互流程及工作原理,确保通信无阻碍
# 摘要
HART协议作为工业自动化中广泛使用的通信协议,是实现现场设备与控制系统的有效桥梁。本文系统地介绍了HART协议的基
精通数据采集:AWR2243与DCA1000的高级应用技巧

# 摘要
本文综述了数据采集技术的核心原理与实践应用,重点介绍了AWR2243雷达传感器和DCA1000数字转换器的技术特点
Windows设备GUID实战:从理论到应用,全方位解析与技巧分享
# 摘要
全局唯一标识符(GUID)是一种在计算机系统中用于生成唯一标识符的标准化技术,它在软件开发、数据管理及系统集成中扮演着至关重要的角色。本文详细阐述了GUID的概念、生成原理、组成结构,以及其在Windows环境下的应用。文章进一步介绍了GUID的管理
精准捕捉用户需求:揭秘系统集成项目需求分析的有效策略

# 摘要
本文对系统集成项目中的需求分析进行了全面的探讨,涵盖了从理论基础到实践案例的分析,再到未来趋势的展望。首先介绍了需求分析的必要性和基本理论,随后深入研究了用户需求分析中的沟通艺术与生命周期管理。接着,本文详细探讨了需求分析工具与技术,包括建模、验证、跟踪与追溯等方面的应用。通过对实际案例的剖析,总结了需求收集与分析过程中的关键步骤和成功策略。此外,文章也指出了需求分析中常见问题的处理方法,
【尺寸标注的革命】:ASME Y14.5标准1994到2018的演进

# 摘要
本文旨在详细介绍并分析ASME Y14.5标准的发展历程,包括1994年版本的标准详解及2018年新标准的更新改进。文章首先概述了ASME Y14.5标准的基本原则、术语和应用范围,并深入探讨了尺寸及公差标注的具体规则。随后,文章详细解读了2018版标准的核心变化,特别是尺寸标注方法的现代化技术,如数字化尺寸标注和概念模
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )