Linux服务器监控艺术:性能优化的工具与策略
发布时间: 2024-09-28 01:52:46 阅读量: 80 订阅数: 45 

基于纯verilogFPGA的双线性差值视频缩放 功能:利用双线性差值算法,pc端HDMI输入视频缩小或放大,然后再通过HDMI输出显示,可以任意缩放 缩放模块仅含有ddr ip,手写了 ram,f

# 1. Linux服务器监控的重要性与基础
## 1.1 为什么监控Linux服务器至关重要
在现代的IT环境中,Linux服务器作为承载业务运行的核心力量,其稳定性直接关联到企业运营的连续性和数据的安全性。通过有效的监控手段,系统管理员能够实时掌握服务器的性能状态、响应问题并进行及时调整,防止潜在的服务中断。更重要的是,监控数据能够帮助开发者和运维团队深入分析系统行为,优化资源配置,提升整体性能和用户体验。
## 1.2 监控的基础概念
监控通常指通过采集和分析系统的关键性能指标(KPIs),来评估系统健康状况和性能表现的活动。在Linux环境下,监控可以分为多个层面:
- 系统监控:主要关注服务器硬件资源的使用情况,如CPU、内存、磁盘和网络。
- 应用监控:关注运行在服务器上的应用程序的性能和状态。
- 日志监控:收集和分析服务器和应用程序的日志,以便进行故障排查和安全审计。
## 1.3 获取监控数据的方法
获取监控数据的方法多种多样,包括但不限于:
- 使用内置命令,如`top`, `htop`, `free`, `df`, `iostat`, `ifstat`, `netstat`等。
- 利用系统提供的日志文件,如`/var/log/syslog`, `/var/log/messages`, `/var/log/nginx/access.log`等。
- 运行专业的性能监控工具,例如Nagios、Zabbix、Prometheus等。
监控数据是进行系统优化和故障排查的关键依据,而下一章节将深入讨论更多关于性能监控工具的使用与选择。
# 2. 性能监控工具的深入剖析
性能监控工具是确保服务器健康运行和及时发现性能瓶颈的关键。本章节将深入探讨一些基本和高级的性能监控工具,分析它们的使用方式和数据解读方法,并提供针对这些工具的配置和定制技巧。
## 2.1 基本监控工具介绍
在进行性能监控时,通常首先会用到的是几个基本的监控工具,它们可以帮助我们获取关于CPU、内存、磁盘I/O以及网络使用情况的基础信息。
### 2.1.1 CPU、内存与磁盘I/O监控
在Linux环境下,`top`和`htop`是两个非常流行且强大的实时系统监控工具。
- **top**:显示系统概览,包括CPU使用率、内存使用、运行中的进程等。
- **htop**:扩展版本的`top`,带有更友好的用户界面和更多交互功能。
**示例代码**(top的使用):
```bash
# 打开top工具查看实时系统状态
top
```
该命令会在终端中打开一个实时更新的系统状态界面。在`top`的输出界面中,主要可以查看以下几个关键指标:
- **load average**:系统平均负载值。
- **tasks**:当前运行的任务数。
- **cpu usage**:CPU的使用百分比,包括用户空间和内核空间的使用情况,以及等待I/O的时间。
- **memory usage**:内存的使用情况,包括物理内存和交换内存。
- **Swap**:交换分区的使用情况。
### 2.1.2 网络监控工具的选用
对于网络的监控,我们可以使用`iftop`、`nethogs`等工具来查看实时网络流量和进程网络使用情况。
- **iftop**:显示当前网络接口的实时流量,包括进出流量及流量来源。
- **nethogs**:以进程为单位显示每个进程的网络使用情况。
**示例代码**(iftop的使用):
```bash
# 安装iftop(如果尚未安装)
sudo apt-get install iftop
# 使用iftop监控网络流量
sudo iftop
```
iftop工具会列出当前系统中所有活跃的网络连接,显示每个连接的带宽使用情况,这有助于快速识别出哪个进程正在使用最多的网络资源。
## 2.2 高级性能分析工具
随着监控需求的深入,我们可能需要使用更为高级的性能分析工具来诊断系统性能问题。
### 2.2.1 sar和vmstat的深入分析
**sar** 和 **vmstat** 是两个历史久远但仍然非常有用的性能监控工具。
- **sar**:从系统保存的历史数据中提取统计信息,也可以实时监控系统状态。
- **vmstat**:报告关于内核线程、虚拟内存、磁盘、陷阱和CPU活动的信息。
**示例代码**(sar的使用):
```bash
# 安装sysstat包(如果尚未安装)
sudo apt-get install sysstat
# 使用sar查看CPU使用情况
sar -u 2 5
```
这个命令会每2秒采样一次,连续采样5次,显示CPU的使用情况。这对于分析短期的CPU使用趋势非常有用。
### 2.2.2 perf和BPF的性能分析技术
**perf** 是Linux内核提供的一个性能分析工具,它可以用来分析CPU的性能事件。而 **BPF(Berkeley Packet Filter)** 已经发展成为一种强大的内核跟踪和分析工具。
**示例代码**(perf的使用):
```bash
# 使用perf record收集性能数据
sudo perf record -a -g -o perf.data -- sleep 60
# 使用perf report分析收集到的性能数据
sudo perf report -i perf.data
```
这里首先用`perf record`命令记录了一分钟的性能数据,然后用`perf report`命令分析这些数据,输出包含了丰富的性能信息,有助于开发者发现和优化性能瓶颈。
## 2.3 监控工具的配置与定制
系统管理员经常需要根据特定的需求对监控工具进行配置和定制。
### 2.3.1 配置监控告警机制
建立有效的监控告警机制可以确保在关键指标偏离正常值时,能及时通知到相关负责人。
**示例代码**(配置Nagios监控告警):
```bash
# 安装Nagios及其插件
sudo apt-get install nagios3 nagios-nrpe-plugin
# 配置服务检查命令
define service{
use generic-service
host_name localhost
service_description CPU Load
check_command check_nrpe!check_load
}
# 配置邮件告警
define command{
command_name notify-by-email
command_line /usr/bin/printf "%b" "Notification: $NOTIFICATIONTYPE$ $SERVICEDESC$ on $HOSTALIAS$ is $SERVICESTATE$\n\nDetails:\n$SERVICEOUTPUT$" | mail -s "Alert: $NOTIFICATIONTYPE$ Service $SERVICEDESC$ on $HOSTALIAS$" $CONTACTEMAIL$
}
```
上述配置文件片段定义了一个服务检查命令以及邮件告警命令,可以将它们加入到Nagios的配置文件中以实现监控告警功能。
### 2.3.2 自定义监控脚本的编写
有时候,为了特定的监控需求,管理员可能需要编写自己的监控脚本。Python脚本因其简洁和高效而成为编写监控脚本的首选语言。
**示例代码**(一个简单的监控脚本):
```python
#!/usr/bin/env python3
import psutil
import socket
def check_disk_usage(threshold=90):
partitions = psutil.disk_partitions()
for partition in partitions:
usage = psutil.disk_usage(partition.mountpoint)
if usage.percent >= threshold:
return f"Disk usage is high on {partition.device}"
return "Disk usage is normal"
def check_cpu_usage(threshold=80):
cpu_usage = psutil.cpu_percent(interval=1)
if cpu_usage >= threshold:
return f"CPU usage is high: {cpu_usage}%"
return "CPU usage is normal"
if __nam
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
“面向开发者的最佳 Linux 发行版”专栏为开发人员提供了全面指南,帮助他们选择最适合其需求的 Linux 发行版。专栏深入探讨了 Linux 命令行,文件系统,服务器监控,数据库管理和图形界面与命令行之间的差异。
通过一系列文章,专栏提供了提高开发效率的实用技巧,深入了解 Linux 文件系统和权限管理,优化服务器性能的工具和策略,以及部署和管理 MySQL 和 PostgreSQL 数据库的指南。专栏还比较了图形界面和命令行,帮助开发人员确定最适合其工作流程的界面。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Swift报文安全秘籍:确保数据传输无懈可击的5大策略
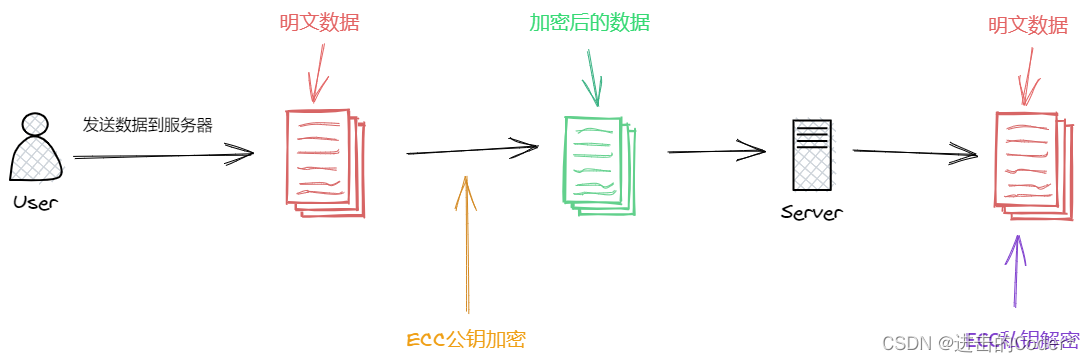
# 摘要
本文旨在全面探讨Swift报文在传输过程中的安全性问题,涵盖加密技术、认证与授权机制、传输层安全策略、以及报文处理与存储的安全性实践。通过对加密算法的概述、Swift语言中的加密实践、认证机制、授权策略和SSL/TLS协议的深入解析,文章提供了一系列安全策略来增强Swift报文的安全性。同时,本文还探讨了安全报文的序列化与反序列化、存储安全性以及高级安全应用策略,包括安全审计与日志管理以及持
企业级部署宝典:Windows 7 SP1更新包的最佳实践与案例
# 摘要
本文全面概述了Windows 7 SP1更新包的准备工作、企业级部署实践以及自动化与优化的策略。文章首先介绍了更新包的系统需求分析、更新策略规划和获取管理过程,随后深入探讨了批量部署技术、更新过程监控与管理和更新包的验证与审核步骤。通过应用案例分析,作者分享了成功和失败的部署经验,并提出了应对策略。文章最后展望了更新部署的自动化工具和持续集成/持续部署(CI/CD)流程的应用,以及更新策略
【OpenWRT Portal认证速成课】:常见问题解决与性能优化
# 摘要
OpenWRT作为一款流行的开源路由器固件,其Portal认证功能在企业与家庭网络中得到广泛应用。本文首先介绍了OpenWRT Portal认证的基本原理和应用场景,随后详述了认证的配置与部署步骤,包括服务器安装、认证页面定制、流程控制参数设置及认证方式配置。为了应对实际应用中可
【Putty与SSH代理】:掌握身份验证问题的处理艺术
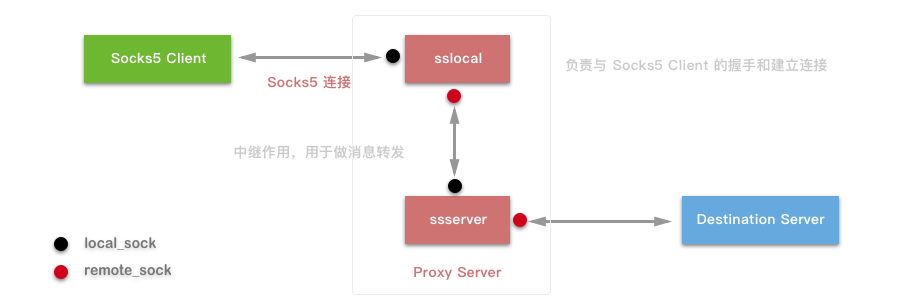
# 摘要
随着网络技术的发展,Putty与SSH代理已成为远程安全连接的重要工具。本文从Putty与SSH代理的简介开始,深入探讨了SSH代理的工作原理与配置,包括身份验证机制和高级配置技巧。文章还详细分析了身份验证问题的诊断与解决方法,讨论了密钥管理、安全强化措施以及无密码SSH登录的实现。在高级应用方面,探讨了代理转发、端口转发和自动化脚本中的应用。通过案例研究展示了这些技术在企业环境中的应
【环境适应性分析】:DROID-SLAM在室内外场景中的性能差异

# 摘要
随着机器人和自动驾驶技术的发展,DROID-SLAM技术作为一项关键的自主定位与地图构建解决方案,越来越受到学术界和产业界的关注。本文首先概述了DROID-SLAM技术的理论基础及其与传统SLAM技术的区别,然后详细解析了DROID-SLAM的核心
【系统性能分析】:如何利用迹线图诊断和改善计算性能
# 摘要
本文系统性地介绍了系统性能分析的概述,并详细阐述了迹线图的理论基础、类型特征、数学原理及其在系统诊断中的应用。文章首先界定了迹线图的概念及其在性能分析中的重要性,随后探讨了不同类型的迹线图以及如何识别其特征。接着,文章深入讲解了迹线图分析工具的使用方法,包括常见软件的对比和功能选择、数据采集及生成步骤,以及数据解读的技巧。在应用方面,文章讨论了迹线图在识别性能瓶颈、优化指导以及与
【国赛C题算法精进秘籍】:专家教你如何选择与调整算法

# 摘要
随着计算机科学的发展,算法已成为解决问题的核心工具,对算法的理解和选择对提升计算效率和解决问题至关重要。本文首先对算法基础知识进行概览,然后深入探讨算法选择的理论基础,包括算法复杂度分析和数据结构对算法选择的影响,以及算法在不同场景下的适用性。接着,本文介绍了算法调整与优化技巧,强调了基本原理与实用策略。在实践层面,通过案例分析展示算
S32K SPI开发实战指南:DMA传输与多设备通信策略
# 摘要
本文系统地介绍了S32K微控制器的SPI接口及其DMA传输机制,探讨了多SPI设备通信的技术需求、挑战与实现策略,并提供了高级配置技巧和面向对象编程范式的应用。文中详细分析了S32K SPI的基础知识,解释了DMA传输的基本原理及其在数据传输中的优势,并深入探讨了SPI与DMA的配置方法,以及在多设备通信中如何处理同步与控制问题。此外,本文还探讨了在物联网应用中S32K SPI
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )