【Python异步编程秘籍】:一文掌握asyncore库的高级技巧和性能优化
发布时间: 2024-10-09 12:33:00 阅读量: 224 订阅数: 40 

Python中asyncore异步模块的用法及实现httpclient的实例

# 1. Python异步编程概述与asyncore库基础
## 1.1 Python异步编程的重要性
Python传统上被认为是一种同步编程语言,但随着网络应用的发展,需要处理大量并发连接时,同步编程模式会导致资源利用率低下。异步编程允许程序在等待I/O操作完成时继续执行其他任务,从而显著提高效率。Python通过asyncore库以及其后继者asyncio,为开发者提供了编写异步网络应用程序的工具。
## 1.2 asyncore库的定义与作用
asyncore库是Python标准库的一部分,它提供了一组用于异步网络编程的工具,尤其是针对底层网络通信。其核心组件包括 dispatcher 和 loop 方法,用于构建异步事件循环。这允许开发者编写更复杂的网络应用,如服务器、客户端或同时作为服务器和客户端的代理。
## 1.3 asyncore库的基本使用
使用asyncore库进行异步编程,首先需要理解其事件驱动的模式。与传统的阻塞式编程相比,开发者需要转换思维,关注各种事件,如连接、读取、写入和关闭。一个典型的asyncore应用程序包括定义网络对象的类,这些类需要处理各种事件,并在事件循环中注册它们。下面是一个简单的dispatcher对象使用示例,该对象用于处理网络连接:
```python
import asyncore
class MyDispatcher(asyncore.dispatcher):
def handle_connect(self):
print("New connection")
def handle_close(self):
self.close()
def handle_read(self):
data = self.recv(8192)
if data:
print('Received data', repr(data))
# 创建 dispatcher 实例并开启监听
s = MyDispatcher('localhost', 12345)
asyncore.loop()
```
此代码段演示了如何使用asyncore创建一个简单的服务器端套接字,并在接收到连接、关闭和读取事件时进行处理。后续章节将深入探讨asyncore的高级用法和优化技巧。
# 2. asyncore库的高级应用技巧
## 2.1 异步网络编程基础
### 2.1.1 异步与同步网络编程的对比
异步网络编程与传统的同步网络编程在执行流程上有显著的不同。在同步网络编程中,程序在执行过程中,一条线程一次只能处理一个任务。每个请求都会阻塞当前线程,直到完成所有相关处理。这种模式简单直观,但当处理大量并发请求时,效率低下,因为每个请求需要占用线程,导致线程资源的大量消耗。
异步网络编程则允许程序在处理一个请求时,如果需要等待某些操作(如网络I/O、磁盘I/O),程序可以不阻塞,而是继续处理其他请求,直到之前的操作完成,再进行相应的回调处理。异步编程极大地提高了资源利用率,适合处理高并发的场景,但其编程模型相对复杂,需要开发者管理状态和回调逻辑。
### 2.1.2 asyncore库的安装与环境搭建
安装asyncore库相对简单,它已经包含在Python的标准库中,因此无需额外安装。使用asyncore库,需要有Python环境的支持,并确保使用的Python版本与asyncore库兼容。
环境搭建通常包括以下步骤:
1. 确认Python环境:在命令行中输入`python --version`(或者`python3 --version`),确认Python的版本。需要确保版本大于等于Python 2.7,因为Python 2.7以后的标准库才开始支持asyncore。
2. 创建项目文件夹:新建一个目录用于存放asyncore项目文件,例如`mkdir asyncore_project`。
3. 配置项目结构:在项目文件夹内,创建Python文件,例如`main.py`,用于编写asyncore代码。
4. 编写初始化代码:在`main.py`中编写基础代码,初始化asyncore环境。
```python
import asyncore
from asynchat import async_chat
class MyServer(async_chat):
def __init__(self, host, port):
async_chat.__init__(self)
self.create_socket(socket.AF_INET, socket.SOCK_STREAM)
self.set_reuse_addr()
self.bind((host, port))
self.listen(5)
asyncore.loop()
if __name__ == '__main__':
MyServer('localhost', 8000)
```
5. 运行项目:在命令行中运行`python main.py`,启动asyncore服务器。
通过以上步骤,即可完成asyncore库的安装与环境搭建,接下来可以着手开发异步网络应用。
## 2.2 asyncore的核心组件解析
### 2.2.1 dispatcher对象的使用与原理
asyncore库中的`dispatcher`对象是异步网络编程的基础。`dispatcher`用于创建一个异步的socket连接,其作用类似于`socket`模块创建的socket对象,但不同的是,`dispatcher`能够融入asyncore的事件循环机制中。
`dispatcher`对象的主要方法包括:
- `create_socket(family, type)`:创建一个异步socket对象。
- `bind(address)`:将socket绑定到指定的地址上。
- `listen(backlog)`:开始监听指定的端口,等待连接。
- `accept()`:接受连接请求。
- `send(data)`:发送数据。
- `recv(size)`:接收数据。
要使用`dispatcher`对象,创建一个继承自`dispatcher`的类,并在其中实现`handle_connect`、`handle_accept`、`handle_read`、`handle_write`等方法,来处理不同类型的事件。
```python
import asyncore
class MyDispatcher(asyncore.dispatcher):
def handle_connect(self):
# 处理连接建立事件
pass
def handle_accept(self):
# 处理接受连接事件
pass
def handle_read(self):
# 处理读取数据事件
pass
def handle_write(self):
# 处理写入数据事件
pass
def handle_close(self):
# 处理关闭连接事件
self.close()
```
当服务器接收到来自客户端的连接时,`handle_accept`方法会被调用,创建一个新的`dispatcher`对象用于处理新的连接。每当有数据到达时,`handle_read`方法会被调用;每当可以发送数据时,`handle_write`方法会被调用。
### 2.2.2 loop方法与事件循环机制
`asyncore.loop()`方法是asyncore库中用于运行异步事件循环的核心方法。当调用`loop()`时,程序会进入一个主循环,不断检查并处理所有的异步事件。这个循环会一直运行,直到程序中没有任何活跃的socket连接。
事件循环机制包括以下几个方面:
- 检查是否有新的连接到来,并调用`handle_accept`。
- 检查是否有数据可读,并调用`handle_read`。
- 检查是否准备好写数据,并调用`handle_write`。
- 检查是否有连接关闭,并调用`handle_close`。
`loop()`方法支持多种参数,例如`timeout`,可以用来指定等待事件的最大时间,`use_poll`参数可以用来选择使用select()还是poll()机制来处理事件。
```python
import asyncore
def main():
server = MyDispatcher()
server.create_socket(socket.AF_INET, socket.SOCK_STREAM)
server.set_reuse_addr()
server.bind(('localhost', 8000))
server.listen(5)
asyncore.loop(timeout=1, use_poll=True)
if __name__ == '__main__':
main()
```
在上述代码中,服务器监听本地8000端口,使用`loop()`方法来管理所有的异步事件。`timeout=1`表示每次循环最多等待1秒,`use_poll=True`指定使用poll()机制而不是默认的select()。
理解并掌握`dispatcher`和事件循环机制,是深入使用asyncore库进行网络编程的关键。
## 2.3 asyncore中的高级功能
### 2.3.1 异步socket编程实例
在asyncore中进行异步socket编程通常涉及创建自定义的handler类,这些类继承自`asyncore.dispatcher`或者`asynchat.async_chat`。以下是一个简单的异步socket编程实例:
```python
import asyncore
import socket
class MyHandler(asyncore.dispatcher):
def __init__(self, sock, addr):
asyncore.dispatcher.__init__(self, sock=sock)
self.buffer = ''
def handle_connect(self):
# 处理连接建立事件
pass
def handle_accept(self):
# 处理接受连接事件
pass
def handle_read(self):
# 接收数据时被调用
data = self.recv(8192)
if data:
self.buffer += data.decode('utf-8')
self.process_buffer()
else:
self.handle_close()
def handle_write(self):
# 数据准备好发送时被调用
if self.send(self.buffer):
self.buffer = ''
else:
self.handle_close()
def process_buffer(self):
# 处理接收到的数据
lines = self.buffer.split('\n')
for line in lines[:-1]:
# 处理每一行数据
pass
self.buffer = lines[-1]
if __name__ == "__main__":
reactor = asyncore.dispatcher()
reactor.create_socket(socket.AF_INET, socket.SOCK_STREAM)
reactor.set_reuse_addr()
reactor.bind(('', 8000))
reactor.listen(5)
asyncore.loop()
```
在这个例子中,`MyHandler`类处理了连接、接收和发送数据的事件。每当有数据到来,`handle_read`方法就会被调用,并把接收到的数据保存在buffer中。当buffer累积了一行数据时,`process_buffer`方法就会被调用来处理这行数据。
### 2.3.2 处理器和服务器的高级定制
在asyncore中进行高级定制意味着你需要创建更加复杂和功能丰富的网络应用。这通常包括对处理器(handler)和服务器(server)的自定义。
对于处理器的高级定制,可以实现以下功能:
- 维护连接状态:使用类属性来跟踪每个连接的特定信息。
- 异步事件处理:覆盖`handle_*`方法来处理不同类型的异步事件。
- 数据封装:设计自己的协议来接收和发送数据。
- 异常处理:覆盖`handle_error`方法来处理异常。
```python
import asyncore
class AdvancedHandler(asyncore.dispatcher):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self._buffer = []
def handle_connect(self):
print("Connection established.")
def handle_close(self):
print("Connection closed.")
def handle_read(self):
chunk = self.recv(4096)
if chunk:
self._buffer.append(chunk)
else:
self.handle_close()
def handle_write(self):
if not self._buffer:
return
out_buffer = "".join(self._buffer)
sent = self.send(out_buffer)
self._buffer = out_buffer[sent:]
if not self._buffer:
self.handle_write = lambda: None
if __name__ == "__main__":
reactor = AdvancedHandler()
reactor.create_socket(socket.AF_INET, socket.SOCK_STREAM)
reactor.set_reuse_addr()
reactor.bind(('', 8000))
reactor.listen(5)
asyncore.loop()
```
服务器的高级定制可能包括:
- 使用SSL/TLS加密通信。
- 自定义日志记录,跟踪事件。
- 支持协程和异步I/O,使用`asyncio`库。
- 对接其他异步框架,例如`Twisted`。
通过以上高级定制,可以构建满足特定需求的网络应用,并且能够高效地处理成百上千的并发连接。
# 3. 性能优化与最佳实践
性能优化是任何编程实践的核心部分,尤其是在异步编程环境中,由于其并发的本质,性能问题更加复杂和微妙。而最佳实践则是社区在多年实践中形成的解决方案和建议。本章将探讨asyncore性能优化的策略和最佳实践案例。
## 3.1 异步编程的性能挑战
### 3.1.1 性能瓶颈的诊断方法
在异步编程中,性能瓶颈可能发生在系统的任何地方,从I/O操作到CPU密集型任务。诊断性能瓶颈通常需要多方面的工具和方法。
首先,可以使用`asyncore`内置的日志功能来记录异步事件的发生时间和顺序。通过对日志文件的分析,开发者可以识别出哪个部分的事件处理时间过长。此外,对于CPU密集型任务,可以使用Python的性能分析工具如`cProfile`来确定代码中执行最慢的部分。
对于I/O密集型任务,可以使用专门的工具,例如`dtrace`(在Unix-like系统中),或者Python的`trace`模块来监控I/O操作。这些工具可以帮助开发者发现和定位性能瓶颈。
### 3.1.2 异步编程中的常见性能问题
异步编程中常见的性能问题包括:
- **I/O阻塞**:在异步处理中,即使一个I/O操作被挂起,程序仍应继续执行其他任务。但有时程序中的某些部分可能无意中阻塞了I/O操作,导致整体性能下降。
- **内存泄漏**:在异步编程中,如果异步任务完成后没有适当地释放资源,就会发生内存泄漏。
- **线程安全问题**:在多线程环境中,多个线程可能会尝试同时访问同一个资源,如果没有正确处理,可能会导致数据竞争和其他并发问题。
## 3.2 asyncore性能优化技巧
### 3.2.1 内存和资源管理优化
优化内存和资源管理是提升asyncore性能的关键步骤。开发者应当遵循以下原则:
- **避免全局变量**:全局变量会在程序的整个生命周期内一直存在,可能导致不必要的内存使用。尽量避免使用全局变量,或者在适当的时候释放不再使用的全局变量。
- **及时清理对象**:确保在对象不再需要时,及时调用`close`方法或类似机制来释放资源。Python的垃圾回收机制会定期清理未使用的对象,但这种机制并非立即生效,因此开发者需要手动介入。
- **使用弱引用**:当对象不需要强引用时,应考虑使用弱引用。弱引用不会阻止对象被垃圾回收,因此可以在不增加内存使用量的情况下,保持对象的可访问性。
### 3.2.2 异步任务的负载均衡与调度策略
负载均衡和调度策略是异步任务管理的另一个重要方面。`asyncore`在创建异步任务时,应考虑到任务之间的负载均衡,避免将资源集中分配给某一类任务,造成其他任务饥饿。
调度策略可能包括:
- **轮转调度**:按顺序分配CPU时间给各个任务。
- **优先级调度**:根据任务的优先级来决定分配CPU时间的顺序。
`asyncore`库本身提供了基础的调度机制,但开发者可能需要扩展这些功能,以适应特定的应用场景。
## 3.3 异步编程最佳实践
### 3.3.1 异步编程模式和架构设计
在异步编程模式中,建议采用以下架构设计最佳实践:
- **模块化设计**:将代码分解为多个独立的模块和组件,每个部分负责处理特定的任务。模块化设计可以提高代码的可维护性和可扩展性。
- **状态机**:使用状态机来管理异步事件和状态的变化。状态机可以使异步逻辑更加清晰,易于理解和维护。
- **异常处理**:在异步编程中妥善处理异常至关重要。确保在发生异常时能够及时捕获并进行适当的处理,避免程序崩溃。
### 3.3.2 真实世界中的asyncore应用案例
一个真实的`asyncore`应用案例可以帮助开发者更好地理解性能优化和最佳实践:
- **服务器应用**:例如,一个异步HTTP服务器,使用`asyncore`来处理多个并发连接。在这个案例中,服务器需要高效地处理来自客户端的请求,并保持高效的资源使用。
- 在代码层面,我们可以通过限制并发连接数来避免过载,利用`asyncore`的`dispatcher`来创建`socket`对象,并通过自定义的`handle_accept`和`handle_read`方法来处理新的连接和读取操作。
- 在架构层面,服务器应用可以采用分层设计,将请求处理和数据访问分离,以实现更好的性能和可扩展性。
通过此类案例,我们可以看到如何在实际项目中应用`asyncore`来实现高性能的异步网络编程,并结合性能优化技巧和最佳实践,提升整体应用的性能。
# 4. asyncore与其他异步库的对比
在现代的Python异步编程领域,asyncore并不是孤立存在的,它只是众多异步编程库中的一个。随着技术的发展,其他诸如asyncio、Twisted等异步编程库也逐渐兴起并广泛使用。了解asyncore与其他异步库的对比,不仅有助于选择适合特定场景的工具,还能加深对异步编程范式的理解。
## 4.1 异步编程库概览
在深入比较各个库之前,我们先对市场上存在的几个主要异步编程库进行一个快速概览。
### 4.1.1 asyncio库的简介与对比
asyncio是Python官方推荐的用于编写并发代码的库。它提供了一个事件循环、线程池以及一些用于网络通信和处理IO密集型任务的工具。asyncio特别适合于需要大量并发连接的场景,如web服务器和网络客户端。
- **事件循环**:asyncio的核心是事件循环,它是驱动整个程序的引擎。所有的异步操作都是基于这个事件循环来完成的。
- **协程(Coroutines)**:协程是asyncio中的轻量级线程,由关键字`async def`定义,并且可以使用`await`来挂起执行,等待异步操作完成。
- **Future和Task**:Future是异步操作的最终结果的占位符,Task则是Future的包装器,用于处理异步操作并最终返回结果。
asyncio与asyncore相比,有着以下几个显著的区别:
- **并发模型**:asyncio使用基于协程的并发模型,而asyncore主要依赖于基于回调的事件循环。
- **灵活性**:asyncio更加灵活,支持单线程或与线程池相结合的方式来处理IO操作。
- **生态系统**:asyncio拥有更加强大的生态系统和更广泛的社区支持。
### 4.1.2 twisted和其他Python异步库
Twisted是另外一个广受好评的异步编程框架。它比asyncore早出现,因此拥有更长时间的迭代和成熟的社区。Twisted提供了一整套网络编程工具,包括对TCP、UDP、SSL/TLS的支持。
- **协议和传输**:Twisted的核心是协议和传输的抽象,这与asyncore中的 dispatcher 和 channel 类似。
- **事件驱动**:Twisted采用事件驱动的方式来处理网络事件,每个网络事件都会触发相应的回调函数。
Twisted与asyncore的区别主要在于:
- **底层抽象**:Twisted使用了协议和传输的抽象,而asyncore更多地使用了对象来处理这些任务。
- **扩展性**:Twisted有着丰富的插件和扩展,对于需要复杂网络协议支持的应用特别有帮助。
## 4.2 asyncore与asyncio的结合使用
随着asyncio的流行,越来越多的开发者想要将asyncore迁移到asyncio,或者在同一个项目中同时使用asyncore和asyncio。
### 4.2.1 将asyncore集成到asyncio中
将asyncore集成到asyncio中并非直接的任务,因为它们的底层模型和API有很大差异。要集成asyncore,通常需要通过一个适配层,将asyncore事件转化为asyncio事件循环可以处理的事件。这需要对两个库的内部工作方式都有深入了解。
### 4.2.2 异步库间的迁移和兼容性处理
迁移和兼容性处理是个复杂的过程,需要考虑到不同异步库之间的运行时差异。如果是在项目中同时使用asyncore和asyncio,你需要确保它们之间没有依赖冲突,并且在并发模型和数据处理上做到同步。
- **线程安全**:某些库可能会在多线程环境中运行,需要注意线程安全的问题。
- **任务协作**:处理不同库中任务之间的协作,需要额外的逻辑来同步状态和处理结果。
## 4.3 异步编程库的选择和评估
选择合适的异步编程库,需要根据应用场景、性能需求、社区支持和开发者的熟悉程度来评估。
### 4.3.1 根据应用场景选择合适的库
对于低延迟的网络应用,asyncio可能是最好的选择,因为它由Python官方维护,与Python的其他标准库集成度高,并且拥有现代的并发模型。
对于需要处理复杂协议的场景,Twisted可能更适合。它在处理协议的细节和异常处理上有着更丰富的经验。
### 4.3.2 异步库性能和功能的综合评估
评估一个异步编程库的性能和功能时,需要考虑以下几个因素:
- **性能基准**:了解库在不同负载和使用场景下的性能基准测试结果。
- **功能特性**:评估库提供的功能是否符合你的需求,例如是否支持协程、是否有内置的安全机制等。
- **易用性**:库的API是否直观易懂,社区文档是否完善,社区是否活跃。
在实际的开发过程中,开发者应基于具体的需求和场景,来选择最合适的异步编程库。以下是一个表格,对比了asyncio、asyncore和Twisted的功能:
| 功能特性 | asyncio | asyncore | Twisted |
|----------|---------|----------|---------|
| 协程支持 | 是 | 否 | 否 |
| 事件循环 | 是 | 是 | 是 |
| 网络协议 | 支持 | 支持 | 丰富 |
| 安全机制 | 内置 | 基本 | 强大 |
| 社区支持 | 强大 | 较弱 | 较强 |
对比这些异步编程库可以帮助我们更好地理解它们的优缺点,从而做出更合适的技术选择。
# 5. asyncore项目的部署与维护
## 5.1 部署asyncore应用的关键步骤
部署asyncore应用到生产环境是确保应用稳定性和性能的关键环节。一个成功的部署流程包含几个重要的步骤,包括打包和分发、持续集成与自动化部署等。
### 5.1.1 打包和分发asyncore应用
在将应用部署到生产环境之前,首先要对其进行打包。使用`distutils`或`setuptools`可以将你的Python代码和所有依赖打包成一个可分发的格式,如wheel文件。以下是打包asyncore应用的一个简单示例:
```python
# setup.py
from setuptools import setup, find_packages
setup(
name="my_asyncore_app",
version="1.0",
packages=find_packages(),
# 其他元数据...
)
```
执行以下命令将创建一个wheel文件:
```shell
python setup.py bdist_wheel
```
生成的wheel文件位于`dist`目录下,可以用于分发。
### 5.1.2 应用的持续集成与自动化部署
持续集成(CI)和自动化部署(Auto-Deploy)是现代软件开发流程中不可或缺的环节。通过CI/CD工具,如Jenkins、GitLab CI/CD或GitHub Actions,可以自动执行构建、测试、打包以及部署过程。
以GitHub Actions为例,以下是一个基础的自动化部署工作流配置文件`.github/workflows/deploy.yml`:
```yaml
name: CI/CD
on:
push:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: 3.x
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install .[dev]
- name: Run Tests
run: |
pytest --verbose tests/
- name: Build and Deploy
run: |
python setup.py bdist_wheel
twine upload dist/*
```
当有代码推送到main分支时,上述工作流将自动执行,并且会尝试构建应用并上传到PyPI,实现自动化部署。
## 5.2 维护与监控asyncore应用
维护和监控asyncore应用确保了应用在生产环境中的稳定运行和快速故障恢复。这需要预防措施、解决方案、性能监控和日志分析。
### 5.2.1 常见问题的预防和解决方案
为了预防潜在的问题,开发者应当在应用设计阶段就考虑好错误处理和异常管理。异步应用中常见的问题包括但不限于超时、资源竞争和内存泄漏。以下是一些基本的预防措施:
- **超时管理**: 设置合理的超时限制,可以防止连接占用资源过久。
- **资源竞争**: 确保所有的网络资源如socket能够被适当地关闭和释放。
- **内存泄漏**: 使用代码分析工具定期检查内存使用情况,发现并修复潜在的内存泄漏问题。
### 5.2.2 应用性能监控与日志分析
性能监控是维护asyncore应用的关键一环。通过工具如Prometheus和Grafana,可以设置监控指标,实时监控应用的性能表现。日志分析则通过工具如ELK栈(Elasticsearch, Logstash, Kibana)来实现,可以有效地帮助开发者定位问题、分析趋势,并且优化应用。
## 5.3 asyncore项目的未来展望
随着技术的发展,asyncore及其背后的异步模型也在不断地演进。社区的支持和新版本的特性对于保持asyncore项目的活力至关重要。
### 5.3.1 新版本特性和向后兼容性
asyncore的开发团队持续在工作以增加新特性和改进现有功能。新版本可能会包括性能提升、API优化和对新Python版本的兼容支持。向后兼容性是每次升级时考虑的一个重要因素,以确保现有的应用不会因升级而出现问题。
### 5.3.2 社区支持与异步编程的未来趋势
开源社区的支持对于asyncore的未来至关重要。社区通过贡献代码、报告问题、提供反馈和进行讨论来推动项目的进步。异步编程的未来趋势包括对异步I/O的更多硬件级支持、编程模型的简化,以及在Web框架和数据库客户端中的更广泛应用。
在后续的章节中,我们将对这些展望进行深入探讨,并分析它们对asyncore项目可能产生的具体影响。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探究 Python 的 asyncore 库,全面涵盖从高级技巧到性能优化、实战应用到事件循环剖析、性能瓶颈分析到顶级优化方案等各个方面。专栏还探讨了 asyncore 库在多线程与异步环境下的对比应用,并提供网络服务开发指南和复杂场景下的使用技巧。此外,专栏还涉及调试与问题诊断高级技巧、自定义协议实现、与其他异步框架的对决分析、安全编程实践、与协程结合使用提升效率、API 全解析、常见问题解答以及在复杂应用中的应用策略等内容,为读者提供了全面而深入的 asyncore 库学习指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
93K缓存策略详解:内存管理与优化,提升性能的秘诀

# 摘要
93K缓存策略作为一种内存管理技术,对提升系统性能具有重要作用。本文首先介绍了93K缓存策略的基础知识和应用原理,阐述了缓存的作用、定义和内存层级结构。随后,文章聚焦于优化93K缓存策略以提升系统性能的实践,包括评估和监控93K缓存效果的工具和方法,以及不同环境下93K缓存的应用案例。最后,本文展望了93K缓存
Masm32与Windows API交互实战:打造个性化的图形界面
# 摘要
本文旨在介绍基于Masm32和Windows API的程序开发,从基础概念到环境搭建,再到程序设计与用户界面定制,最后通过综合案例分析展示了从理论到实践的完整开发过程。文章首先对Masm32环境进行安装和配置,并详细解释了Masm编译器及其他开发工具的使用方法。接着,介绍了Windows API的基础知识,包括API的分类、作用以及调用机制,并对关键的API函数进行了基础讲解。在图形用户界面(GUI)的实现章节中,本文深入
数学模型大揭秘:探索作物种植结构优化的深层原理
# 摘要
本文系统地探讨了作物种植结构优化的概念、理论基础以及优化算法的应用。首先,概述了作物种植结构优化的重要性及其数学模型的分类。接着,详细分析了作物生长模型的数学描述,包括生长速率与环境因素的关系,以及光合作用与生物量积累模型。本文还介绍了优化算法,包括传统算法和智能优化算法,以及它们在作物种植结构优化中的比较与选择。实践案例分析部分通过具体案例展示了如何建立优化模型,求解并分析结果。
S7-1200 1500 SCL指令性能优化:提升程序效率的5大策略

# 摘要
本论文深入探讨了S7-1200/1500系列PLC的SCL编程语言在性能优化方面的应用。首先概述了SCL指令性能优化的重要性,随后分析了影响SCL编程性能的基础因素,包括编程习惯、数据结构选择以及硬件配置的作用。接着,文章详细介绍了针对SCL代码的优化策略,如代码重构、内存管理和访问优化,以及数据结构和并行处理的结构优化。
泛微E9流程自定义功能扩展:满足企业特定需求

# 摘要
本文深入探讨了泛微E9平台的流程自定义功能及其重要性,重点阐述了流程自定义的理论基础、实践操作、功能扩展案例以及未来的发展展望。通过对流程自定义的概念、组件、设计与建模、配置与优化等方面的分析,本文揭示了流程自定义在提高企业工作效率、满足特定行业需求和促进流程自动化方面的重要作用。同时,本文提供了丰富的实践案例,演示了如何在泛微E9平台上配置流程、开发自定义节点、集成外部系统,
KST Ethernet KRL 22中文版:硬件安装全攻略,避免这些常见陷阱

# 摘要
本文详细介绍了KST Ethernet KRL 22中文版硬件的安装和配置流程,涵盖了从硬件概述到系统验证的每一个步骤。文章首先提供了硬件的详细概述,接着深入探讨了安装前的准备工作,包括系统检查、必需工具和配件的准备,以及
约束理论与实践:转化理论知识为实际应用
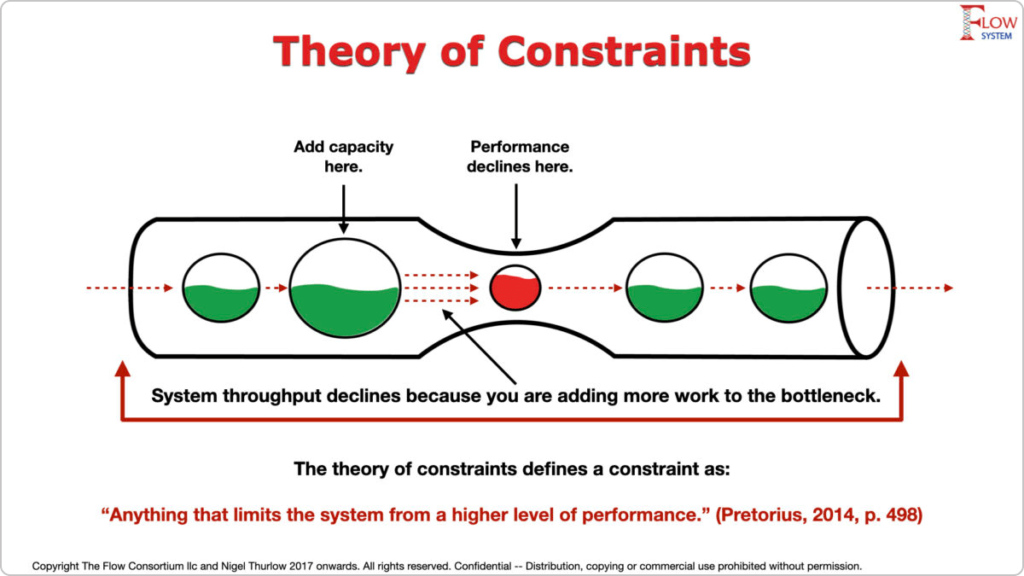
# 摘要
约束理论是一种系统性的管理原则,旨在通过识别和利用系统中的限制因素来提高生产效率和管理决策。本文全面概述了约束理论的基本概念、理论基础和模型构建方法。通过深入分析理论与实践的转化策略,探讨了约束理论在不同行业,如制造业和服务行业中应用的案例,揭示了其在实际操作中的有效性和潜在问题。最后,文章探讨了约束理论的优化与创新,以及其未来的发展趋势,旨在为理论研究和实际应用提供更广阔的
FANUC-0i-MC参数与伺服系统深度互动分析:实现最佳协同效果
# 摘要
本文深入探讨了FANUC 0i-MC数控系统的参数配置及其在伺服系统中的应用。首先介绍了FANUC 0i-MC参数的基本概念和理论基础,阐述了参数如何影响伺服控制和机床的整体性能。随后,文章详述了伺服系统的结构、功能及调试方法,包括参数设定和故障诊断。在第三章中,重点分析了如何通过参数优化提升伺服性能,并讨论了伺服系统与机械结构的匹配问题。最后,本文着重于故障预防和维护策略,提
ABAP流水号安全性分析:避免重复与欺诈的策略
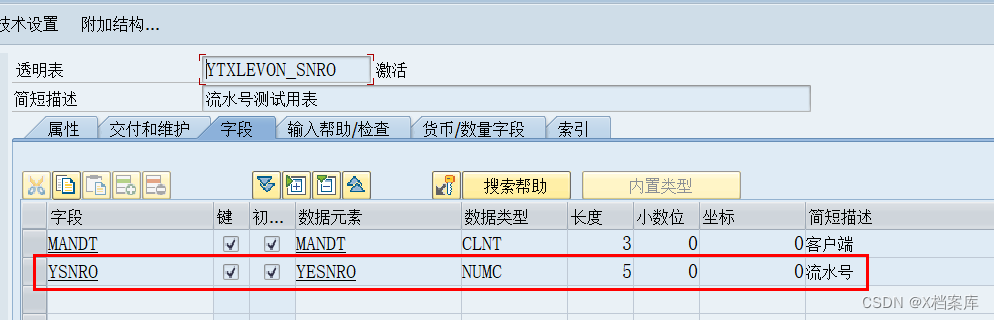
# 摘要
本文全面探讨了ABAP流水号的概述、生成机制、安全性实践技巧以及在ABAP环境下的安全性增强。通过分析流水号生成的基本原理与方法,本文强调了哈希与加密技术在保障流水号安全中的重要性,并详述了安全性考量因素及性能影响。同时,文中提供了避免重复流水号设计的策略、防范欺诈的流水号策略以及流水号安全的监控与分析方法。针对ABAP环境,本文论述了流水号生成的特殊性、集成安全机制的实现,以及安全问题的ABAP代
Windows服务器加密秘籍:避免陷阱,确保TLS 1.2的顺利部署
# 摘要
本文提供了在Windows服务器上配置TLS 1.2的全面指南,涵盖了从基本概念到实际部署和管理的各个方面。首先,文章介绍了TLS协议的基础知识和其在加密通信中的作用。其次,详细阐述了TLS版本的演进、加密过程以及重要的安全实践,这
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )