【Prometheus & Grafana】:Linux系统监控:使用Prometheus和Grafana的实战指南
发布时间: 2024-12-09 21:02:55 阅读量: 13 订阅数: 13 
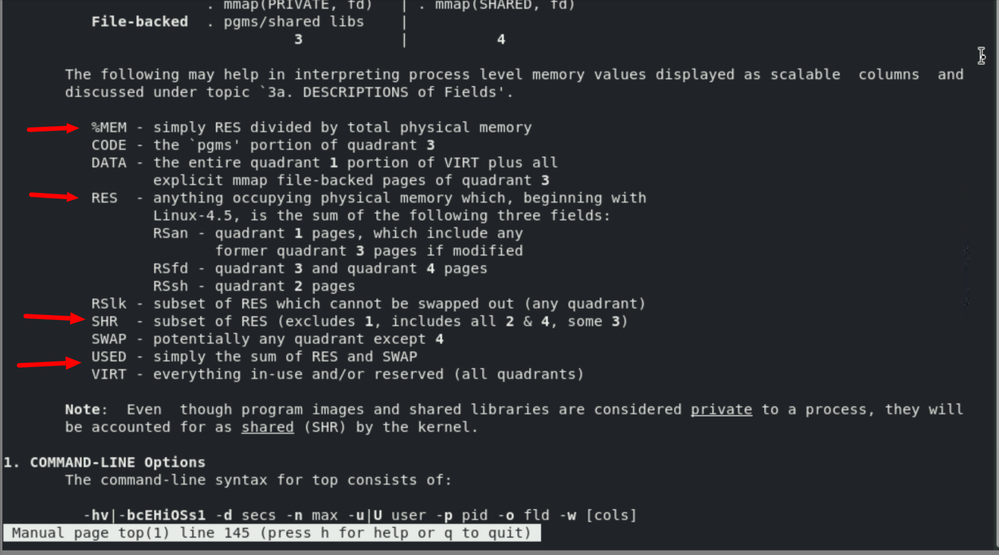
# 1. Prometheus与Grafana概述
## Prometheus简介
Prometheus 是一个开源的监控和警报工具包,以其高性能和可靠性而受到广泛的欢迎。它是一个用于时序数据的多维数据模型,支持强大的查询语言PromQL。Grafana,作为一款流行的开源可视化工具,常与Prometheus联合使用,提供动态的图表和仪表板,帮助用户从多个数据源中获取和展示数据。
## Prometheus与Grafana的关系
Prometheus主要用于收集和存储时间序列数据,以及提供规则和告警功能,而Grafana则擅长于数据的可视化和展示。这种组合使得用户可以通过Grafana仪表板来直观地查看Prometheus收集的数据,同时也能够通过Grafana创建复杂的图表和分析图,以便快速诊断和解决系统或服务的问题。
## 监控和可视化的重要性
在现代IT环境中,监控系统运行状况和可视化数据对于保障服务的稳定性和性能至关重要。 Prometheus和Grafana的结合为用户提供了完整的监控解决方案,不仅能够实时监控系统状态,还能够通过图表和告警来预测和响应可能的问题,从而实现系统的健康维护和优化管理。接下来,我们将深入探讨Prometheus的核心概念、Grafana的使用方法,以及如何将它们应用于实际的系统监控中。
# 2. Prometheus核心概念与实践
## 2.1 Prometheus基础架构
### 2.1.1 Prometheus组件介绍
Prometheus 是一个开源的监控解决方案,由 SoundCloud 公司于 2012 年启动,并于 2016 年成为云原生计算基金会(CNCF)的一个项目。它的设计目标是通过收集和存储时间序列数据,实现对系统的实时监控和告警。
Prometheus 架构主要由以下组件构成:
- **Prometheus Server**:收集和存储时间序列数据。它从配置的抓取目标(目标可以是静态配置的,也可以是通过服务发现动态获取的)拉取(pull)数据,并提供查询语言 PromQL 来对收集到的数据进行查询。
- **Pushgateway**:用于短期工作或批处理任务。由于 Prometheus 是基于 Pull 模式的,Pushgateway 允许批处理作业将指标推送给 Prometheus Server。
- **Exporters**:用于导出特定应用或服务的指标。例如,Node Exporter 用于导出系统级别的硬件和操作系统指标,而 Blackbox Exporter 用于网络探测。
- **Alertmanager**:用于处理由 Prometheus Server 发送的警报。它负责去重、分组和发送警报到指定的接收器(如电子邮件、PagerDuty 等)。
- **服务发现机制**:与云环境(如 Kubernetes)或传统服务注册表(如 Consul、etcd)集成,自动发现监控目标。这允许 Prometheus 动态抓取目标,而无需每次添加或移除实例时手动修改配置。
### 2.1.2 数据模型和时间序列
Prometheus 的数据模型非常简单。所有收集到的数据都是以时间序列的形式存储的,其中每一个时间序列由以下两部分唯一标识:
- **Metric Name(度量名称)**:一个度量名称标识了一个特定的度量行为,例如 `http_requests_total` 表示 HTTP 请求的总数。
- **Labels(标签)**:一组标签(Key-Value 对)附加在度量名称上,用于进一步区分同一度量名称的不同维度。例如,`http_requests_total` 可以通过标签 `method="GET"` 和 `status_code="200"` 来具体化为针对 GET 请求并且状态码为 200 的请求总数。
时间序列数据通常以以下形式表示:
```
<metric name>{<label name>=<label value>, ...}
```
Prometheus 收集的数据以浮点数和时间戳的形式存储。在存储时,数据将被压缩,并默认保留 15 个月左右,具体取决于存储空间和配置。
## 2.2 Prometheus监控实践
### 2.2.1 配置监控目标和抓取规则
在 Prometheus 中,监控目标通常配置在名为 `scrape_configs` 的配置文件中,或者在 Kubernetes 环境中通过 ConfigMap 和 Operator 动态配置。抓取规则定义了 Prometheus 如何从目标中获取指标数据。
以下是一个简单的抓取配置示例:
```yaml
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['node-exporter-node1:9100', 'node-exporter-node2:9100']
```
在这个例子中,我们定义了两个 `job`:`prometheus` 和 `node_exporter`。`prometheus` 作业会从运行在本地的 Prometheus 服务器的 9090 端口收集数据,而 `node_exporter` 作业则分别从两个不同的节点上的 Node Exporter 的 9100 端口收集系统级指标。
### 2.2.2 使用PromQL进行数据查询和聚合
PromQL(Prometheus Query Language)是 Prometheus 自带的数据查询语言,它允许用户检索和聚合时间序列数据。PromQL 对于数据的可视化、告警规则的设置和数据的分析处理至关重要。
例如,要查询过去一小时内所有节点的 CPU 使用率,可以使用以下 PromQL:
```promql
100 - (avg by (instance) (rate(node_cpu{mode="idle"}[5m])) * 100)
```
这条查询语句做了以下事情:
- `node_cpu{mode="idle"}` 选择了所有 `mode` 标签为 `idle` 的 CPU 使用率指标。
- `rate(...[5m])` 计算在五分钟内的平均每秒增长量(即 CPU 使用率的速率)。
- `avg by (instance) (...)` 对于每个不同的 `instance`(在本例中为每个节点)计算平均值。
- `100 - ...` 计算 CPU 使用率的百分比。
## 2.3 Prometheus告警管理
### 2.3.1 告警规则配置
告警规则是在 Prometheus 中定义的一组规则,用于指定何时应该触发告警。告警规则使用 PromQL 表达式进行条件检查,并且可以设置阈值。
在告警规则文件中,每个告警规则看起来像这样:
```yaml
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: job:http_inprogress_requests:sum{job="myjob"} > 5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
```
这里定义了一个名为 `HighRequestLatency` 的告警。如果 `expr` 中的表达式在 10 分钟内持续为真,则触发告警。此告警被标记为 `page` 级别,并有一个注释,说明 `summary` 是高请求延迟。
### 2.3.2 告警通知和抑制策略
一旦告警被触发,Prometheus 会将告警通知发送到 Alertmanager。Alertmanager 负责告警的去重、分组、抑制和通知。
**去重**:相同的告警实例(相同标签集和原因)只会发送一次。
**分组**:告警可以按照不同的策略进行分组,例如按照标签进行分组。
**抑制**:抑制策略允许在特定条件下停止发送告警。这通常用于避免在已知问题下游的其他告警被触发。
**通知**:A

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Linux 系统监控与性能分析的终极指南!本专栏将带你踏上从入门到精通的旅程,掌握 10 个必备技巧,深入了解内核参数以优化系统性能,并获取监控和管理内存的秘诀。此外,你将探索 CPU 性能瓶颈的解决策略,了解 I/O 性能调优的工具和方法,并通过实战案例学习性能分析的技巧。本专栏还提供专家访谈,帮助你深入了解 Linux 监控和性能分析的最佳实践。通过比较 Linux 性能分析工具,你将找到最适合你的工具。最后,你将了解云原生监控和容器化视角,以全面掌握 Linux 系统监控和性能分析。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭示Tetgen算法原理:从理论到实践的精髓
参考资源链接:[tetgen中文指南:四面体网格生成与优化](https://wenku.csdn.net/doc/77v5j4n744?spm=1055.2635.3001.10343)
# 1. Tetgen算法概述
## 1.1 Tetgen算法简介
Tetgen是一个用于三维网格生成的软件包,它能够将复杂几何模型转换为高质量的四面体网格。该算法在科学和工程领域中具有广泛的应用,特别是在有限元分析(FEA)和计算流体动力学(CFD)等领域。Tetgen的核心优势在于其能够处理具有复杂边界的几何体,并在生成的网格中保持一致性与精确性。
## 1.2 算法的发展与应用背景
Tetgen算
【Python模块导入机制深度解析】:掌握PYTHONPATH与模块搜索的秘诀
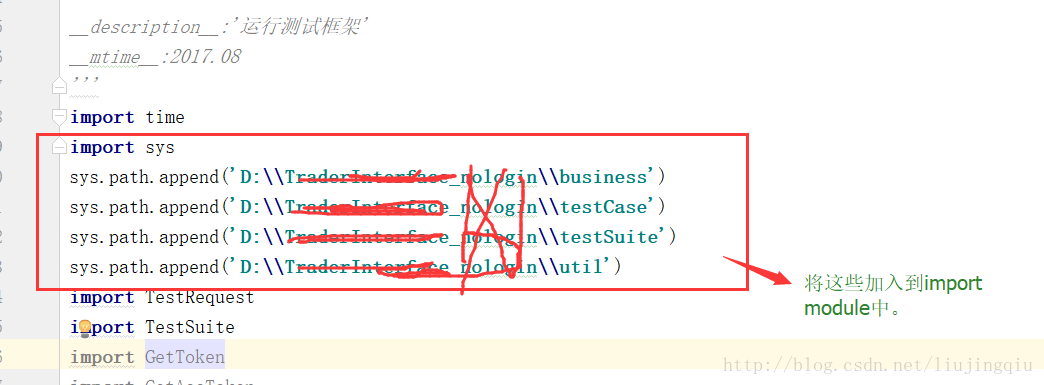
参考资源链接:[pycharm运行出现ImportError:No module named的解决方法](https://wenku.csdn.ne
【UDEC模型构建全流程】:手把手教你从零开始
参考资源链接:[UDEC中文详解:初学者快速入门指南](https://wenku.csdn.net/doc/5fdi050ses?spm=1055.2635.3001.10343)
# 1. UDEC模型基础介绍
## 1.1 UDEC模型概述
UDEC(Universal Distinct Element Code)是一款应用离散元方法模拟岩土体应力-应变行为的计算软件。它能够模拟岩土材料的裂纹生长、块体运动和整体稳定性,是工程岩土、采矿及地质灾害分析中不可或缺的数值分析工具。
## 1.2 UDEC模型的应用范围
UDEC广泛应用于岩土工程的各个领域,包括但不限于矿山开采、岩体稳
印刷色彩管理秘籍:中英文术语对照与调色技巧(颜色大师的秘密)
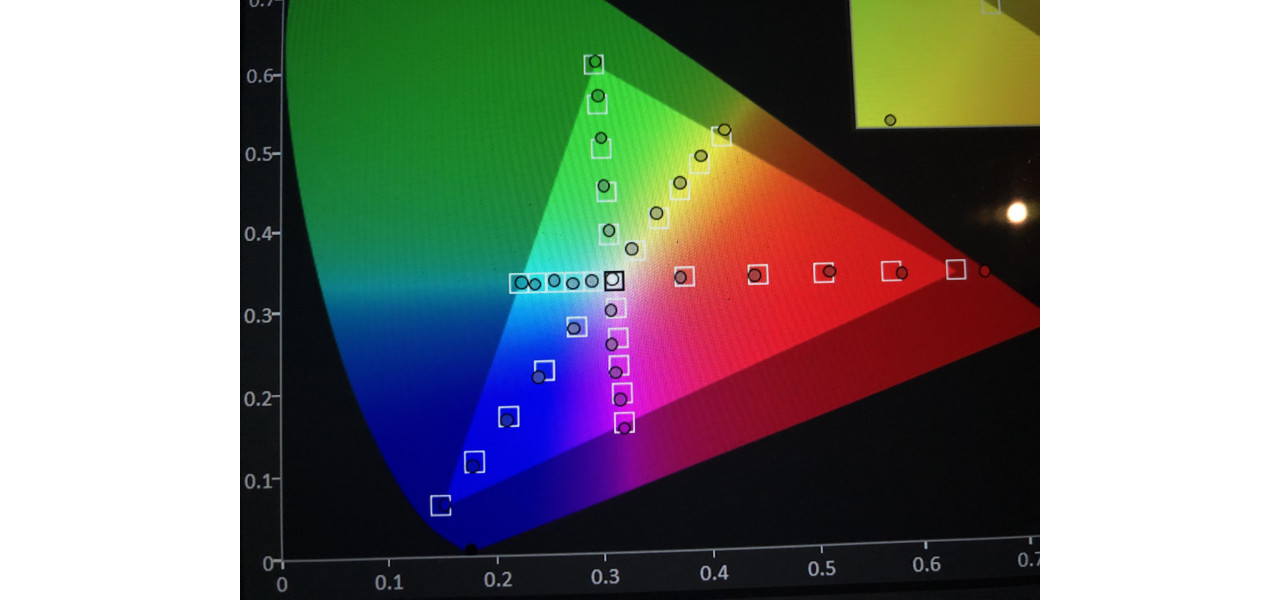
参考资源链接:[印刷术语大全:中英文对照与专业解析](https://wenku.csdn.net/doc/1y36sp606t?spm=1055.2635.3001.10343)
# 1. 印刷色彩管理的基础
在印刷业和数字媒体中,色彩管理是确保从设计
掌握信号完整性,确保硬件性能
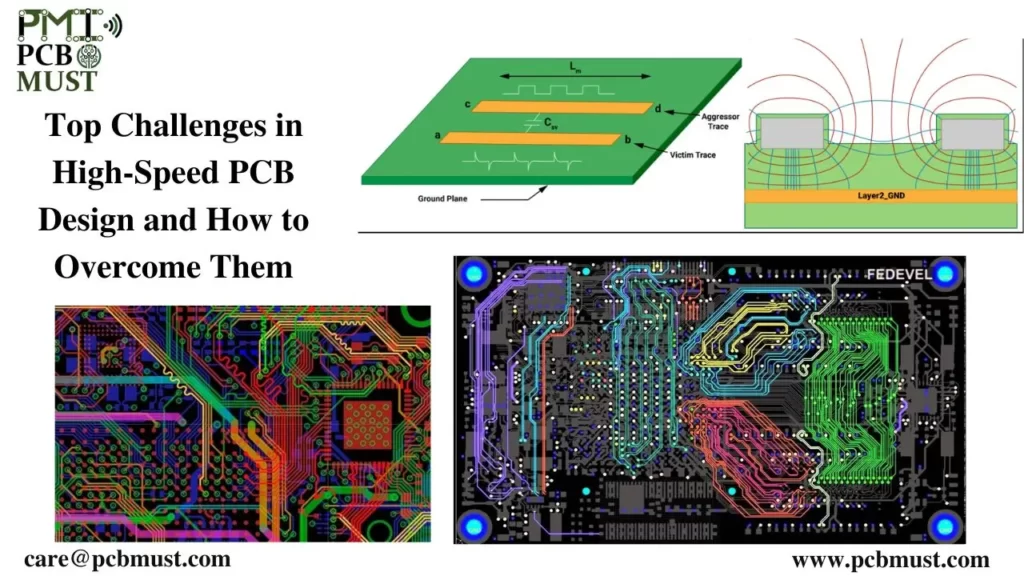
参考资源链接:[PR2000K_AHD转MIPI调试原理图.pdf](https://wenku.csdn.net/doc/645d9a0995996c03ac437fcb?spm=1055.2635.3001.10343)
# 1. 信号完整性基础理论
## 1.1 信号完整性概念解析
信号完整性指的是在高速数字电路中,信号在传输过程中能够保持其原始特
DEFORM-3D_v6.1全流程攻略:掌握模拟到结果分析的每一个环节
参考资源链接:[DEFORM-3D v6.1:交互对象操作详解——模具与毛坯接触关系设置](https://wenku.csdn.net/doc/5d6awvqjfp?spm=1055.2635.3001.10343)
# 1. DEFORM-3D_v6.1基础入门
## 1.1 DEFORM-3D_v6.1软件概述
DEFORM-3D_v6.1是一款广泛应用于金属加工、热处理等领域模拟软件,它通过模拟材料在各种条件下的变形行为,帮助工程师和研究人员进行产品设计优化和生产过程的决策。该软件具有强大的仿真能力,同时也能帮助用户预测可能出现的问题并加以解决。
## 1.2 DEFORM-3D
六西格玛流程改进:立即掌握优化秘籍,使用思维导图实现飞跃
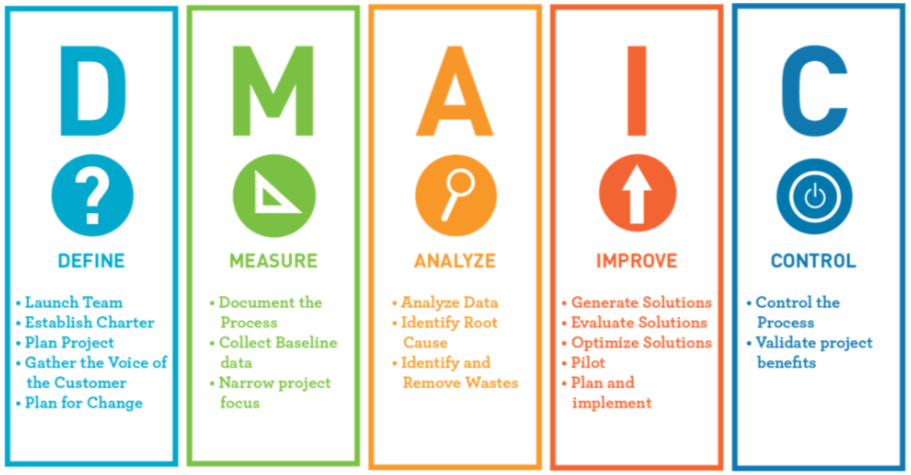
参考资源链接:[六西格玛管理精华概览:从起源到战略应用](https://wenku.csdn.net/doc/646194bb5928463033b19ffc?spm=1055.2635.3001.10343)
# 1. 六西格玛流程改进概述
## 1.1 六西格玛的起源与定义
六西格玛是一种旨在通过减少过程变异来提高产品和服务质量的管理哲学和一套工具集。它起源于20世纪80年代的摩托罗拉,随着通用
【破解代码质量之谜】:掌握SpyGlass LintRules,提升硬件设计到新高度

参考资源链接:[SpyGlass Lint规则参考指南:P-2019.06-SP1](https://wenku.csdn.net/doc/5
Python错误处理艺术:优雅解决代码中的异常
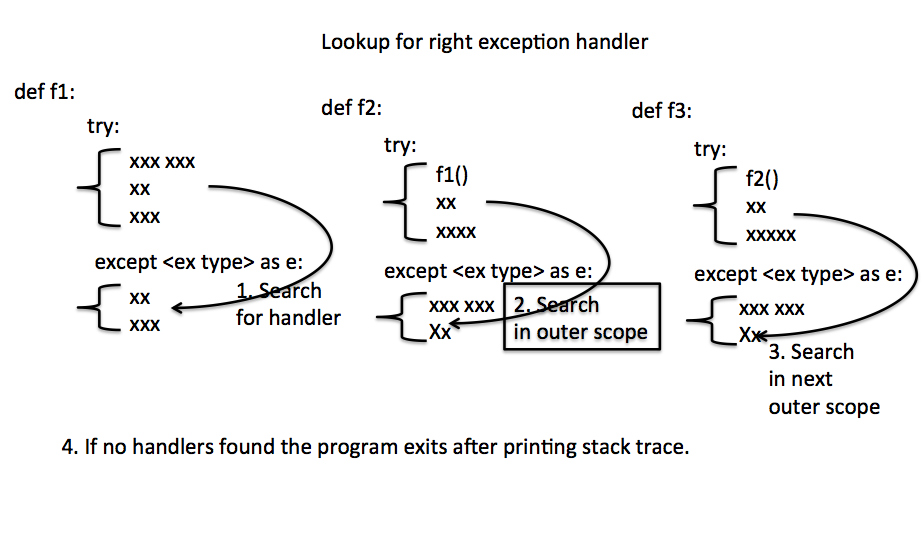
参考资源链接:[头歌Python实践:顺序结构与复数运算解析](https://wenku.csdn.net/doc/ov1zuj84kh?spm=1055.2635.3001.10343)
# 1. Python错误处理基础
Python作为一种高级编程语言,其错误处理机制是保证程序健壮性的重要组成部分。当程序运行时,可能会遇到各种预期之外的情况,如输入错误、资源不可用或程序逻辑错误等。这些情况往往会导致程序出现异常,并可能以错误
揭秘进化算法:CEC05 benchmark的十大挑战与突破

参考资源链接:[CEC2005真实参数优化测试函数与评估标准](https://wenku.csdn.net/doc/ewbym81paf?spm=1055.2635.3001.10343)
# 1. 进化算法基础与CEC05挑战概述
## 1.1 进化算法的起源与原理
进化算法是一种模拟生物进化过程的优化算法,它起源于自
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )