OpenCV人脸检测与虚拟现实技术的结合:打造沉浸式人脸交互体验
发布时间: 2024-08-08 05:09:04 阅读量: 23 订阅数: 34 
.png)
# 1. OpenCV人脸检测技术概述**
OpenCV(Open Source Computer Vision Library)是一个开源计算机视觉库,广泛用于图像处理、视频分析和机器学习等领域。人脸检测是OpenCV中一项重要的功能,它能够从图像或视频中识别出人脸。
人脸检测技术在许多应用中都有着广泛的应用,例如:
- 安全和监控:识别和跟踪人员,防止未经授权的访问。
- 医疗保健:用于面部识别、疾病诊断和治疗。
- 娱乐:用于虚拟现实、增强现实和游戏中的面部跟踪和交互。
# 2. 人脸检测算法与实现
人脸检测是计算机视觉领域的一项基本技术,它旨在从图像或视频中识别和定位人脸。OpenCV提供了多种人脸检测算法,其中最著名的是Viola-Jones算法。
### 2.1 Viola-Jones算法
Viola-Jones算法是一种基于特征的分类算法,它使用级联分类器来检测人脸。该算法由Paul Viola和Michael Jones于2001年提出,至今仍是人脸检测领域最常用的算法之一。
#### 2.1.1 特征提取
Viola-Jones算法使用Haar特征来提取人脸图像中的特征。Haar特征是一种矩形特征,它计算矩形区域内像素的和之间的差异。这些差异可以用来描述人脸的形状和纹理。
#### 2.1.2 级联分类器
级联分类器是一种由多个较弱分类器组成的分类器。每个分类器都针对特定的人脸特征进行训练。当一个图像通过级联分类器时,它将被依次传递给每个分类器。如果图像通过了所有分类器,则它将被分类为包含人脸。
### 2.2 Haar特征与积分图像
#### 2.2.1 Haar特征
Haar特征是一种矩形特征,它计算矩形区域内像素的和之间的差异。Haar特征可以分为三种类型:
* **边缘特征:**计算垂直或水平边缘的像素和差异。
* **线特征:**计算水平或垂直线的像素和差异。
* **中心特征:**计算矩形中心区域和周围区域的像素和差异。
#### 2.2.2 积分图像
积分图像是一种数据结构,它存储图像中每个像素的累积和。使用积分图像可以快速计算矩形区域内的像素和。
```python
import cv2
import numpy as np
# 计算积分图像
def integral_image(image):
integral = np.zeros(image.shape, dtype=np.int32)
integral[0, 0] = image[0, 0]
for i in range(1, image.shape[0]):
integral[i, 0] = integral[i - 1, 0] + image[i, 0]
for j in range(1, image.shape[1]):
integral[0, j] = integral[0, j - 1] + image[0, j]
for i in range(1, image.shape[0]):
for j in range(1, image.shape[1]):
integral[i, j] = integral[i - 1, j] + integral[i, j - 1] - integral[i - 1, j - 1] + image[i, j]
return integral
# 计算 Haar 特征
def haar_feature(image, integral, x, y, width, height):
sum1 = integral[y + height, x + width] - integral[y, x + width] - integral[y + height, x] + integral[y, x]
sum2 = integral[y + 2 * height, x + 2 * width] - integral[y + 2 * height, x] - integral[y, x + 2 * width] + integral[y, x]
return sum1 - sum2
```
# 3. OpenCV人脸检测实践
### 3.1 人脸检测函数的使用
#### 3.1.1 cv2.CascadeClassifier()
`cv2.CascadeClassifier()` 函数用于加载预训练的人脸检测模型。它接受一个参数:
- `cascade_file`:预训练模型的路径。
**代码块:**
```python
import cv2
# 加载预训练的人脸检测模型
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 C++ OpenCV 人脸检测专栏,在这里,我们将深入探索人脸检测的奥秘。从基础原理到高级优化,我们将逐步揭开人脸检测算法的秘密。专栏涵盖了人脸检测的各个方面,包括 Haar 特征、性能优化、常见问题解决、跟踪、识别、情绪分析、安防、口罩识别、身份验证、医疗影像、生物特征识别、人机交互、虚拟现实、游戏开发、社交媒体、广告营销、电子商务和金融科技。通过深入浅出的讲解和丰富的示例代码,您将掌握人脸检测的精髓,并将其应用于各种实际场景中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
社交媒体数据分析新视角:R语言cforest包的作用与影响
# 1. 社交媒体数据分析简介
在当今数字化时代,社交媒体已成为人们日常沟通、信息传播的重要平台。这些平台所产生的海量数据不仅为研究人员提供了丰富的研究素材,同时也对数据分析师提出了新的挑战。社交媒体数据分析是一个涉及文本挖掘、情感分析、网络分析等多方面的复杂过程。通过解析用户的帖子、评论、点赞等互动行为,我们可以洞察用户的偏好、情绪变化、社交关系
R语言cluster.stats故障诊断:快速解决数据包运行中的问题

# 1. cluster.stats简介
cluster.stats 是 R 语言中一个强大的群集分析工具,它在统计分析、数据挖掘和模式识别领域中扮演了重要角色。本章节将带您初步认识cluster.stats,并概述其功能和应用场景。cluster.stats 能够计算和比较不同群集算法的统计指标,包括但不限于群集有效性、稳定性和区分度。我们将会通过一个简单的例子介绍其如何实现数据的
R语言数据包与外部数据源连接:导入选项的全面解析

# 1. R语言数据包概述
R语言作为统计分析和图形表示的强大工具,在数据科学领域占据着举足轻重的位置。本章将全面介绍R语言的数据包,即R中用于数据处理和分析的各类库和函数集合。我们将从R数据包的基础概念讲起,逐步深入到数据包的安装、管理以及如何高效使用它们进行数据处理。
## 1.1 R语言数据包的分类
数据包(Pa
R语言统计建模深入探讨:从线性模型到广义线性模型中residuals的运用

# 1. 统计建模与R语言基础
## 1.1 R语言简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。它的强大在于其社区支持的丰富统计包和灵活的图形表现能力,使其在数据科学
R语言非线性回归模型与预测:技术深度解析与应用实例

# 1. R语言非线性回归模型基础
在数据分析和统计建模的世界里,非线性回归模型是解释和预测现实世界复杂现象的强大工具。本章将为读者介绍非线性回归模型在R语言中的基础应用,奠定后续章节深入学习的基石。
## 1.1 R语言的统计分析优势
R语言是一种功能强大的开源编程语言,专为统计计算和图形设计。它的包系统允许用户访问广泛的统计方法和图形技术。R语言的这些
R语言高级教程:深度挖掘plot.hclust的应用潜力与优化技巧
# 1. R语言与数据可视化的基础
在数据分析与统计领域中,R语言已经成为一种不可或缺的工具,它以其强大的数据处理能力和丰富的可视化包而著称。R语言不仅支持基础的数据操作,还提供了高级的统计分析功能,以及多样化的数据可视化选项。数据可视化,作为将数据信息转化为图形的过程,对于理解数据、解释结果和传达洞察至关重要。基础图表如散点图、柱状图和线图等,构成了数据可视化的基石,它们能够帮助我们揭示数据中的模式和趋势。
## 1.1 R语言在数据可视化中的地位
R语言集成了多种绘图系统,包括基础的R图形系统、grid系统和基于ggplot2的图形系统等。每种系统都有其独特的功能和用例。比如,ggpl
生产环境中的ctree模型

# 1. ctree模型的基础理论与应用背景
决策树是一种广泛应用于分类和回归任务的监督学习算法。其结构类似于一棵树,每个内部节点表示一个属性上的测试,每个分支代表测试结果的输出,而每个叶节点代表一种类别或数值。
在众多决策树模型中,ctree模型,即条件推断树(Conditional Inference Tree),以其鲁棒性和无需剪枝的特性脱颖而出。它使用统计检验
【R语言生存分析高级应用】:时间依赖协变量处理的实战指南

# 1. 生存分析基础和R语言概述
在当今数据驱动的科研和工业界,生存分析作为一种统计方法,专注于研究时间至事件发生的数据,是健康、工程和经济学等领域的核心技术之一。本章将带领读者入门生存分析的基础知识,同时介绍R语言在该领域的强大应用。R语言,以其丰富的统计包和数据处理能力,被广泛应用于各类数据科学任务中,特别是在生存分析这一细分领域中,它提供了一套完整的生存分
R语言生存分析:Poisson回归与事件计数解析

# 1. R语言生存分析概述
在数据分析领域,特别是在生物统计学、医学研究和社会科学领域中,生存分析扮演着重要的角色。R语言作为一个功能强大的统计软件,其在生存分析方面提供了强大的工具集,使得分析工作更加便捷和精确。
生存分析主要关注的是生存时间以及其影响因素的统计分析,其中生存时间是指从研究开始到感兴趣的事件发生的时间长度。在R语言中,可以使用一系列的包和函数来执行生存分析,比如`survival
缺失数据处理:R语言glm模型的精进技巧
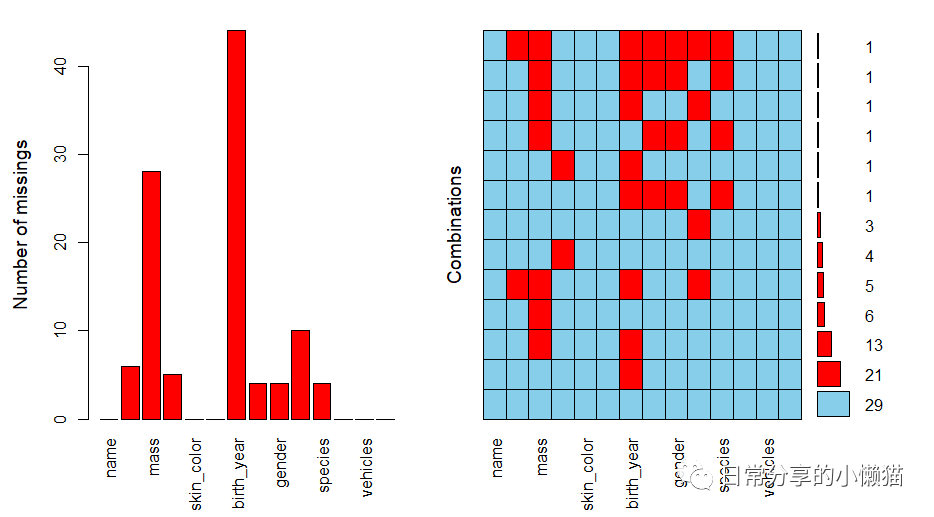
# 1. 缺失数据处理概述
数据处理是数据分析中不可或缺的环节,尤其在实际应用中,面对含有缺失值的数据集,有效的处理方法显得尤为重要。缺失数据指的是数据集中某些观察值不完整的情况。处理缺失数据的目标在于减少偏差,提高数据的可靠性和分析结果的准确性。在本章中,我们将概述缺失数据产生的原因、类型以及它对数据分析和模型预测的影响,并简要介绍数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )