MCode代码生成器 - 核心功能介绍
发布时间: 2024-02-26 15:11:09 阅读量: 44 订阅数: 32 

功能强大的代码生成器
# 1. MCode代码生成器简介
## 1.1 项目背景
在软件开发过程中,代码生成器作为一种自动化工具,能够帮助程序员快速生成大量重复性代码,提高开发效率,降低出错率。
## 1.2 代码生成器的作用和意义
代码生成器可以根据预定义的模板和数据源,生成符合需求的代码文件,减少手工编写代码的工作量,提高开发效率。
## 1.3 MCode代码生成器的定位和特点
MCode代码生成器作为一款轻量级的代码生成工具,致力于提供简单易用的界面和丰富的功能模块,帮助开发人员快速生成所需代码,并支持定制化需求。
# 2. 安装与配置
本章将介绍MCode代码生成器的安装与配置流程,包括系统环境要求、下载安装、以及基本参数的配置等内容。请按照以下步骤进行操作。
### 2.1 系统环境要求
在安装MCode代码生成器之前,请确保您的系统符合以下要求:
- 操作系统:支持Windows、Linux、MacOS等常见操作系统。
- Java版本:需要安装JDK 1.8及以上版本。
- 内存:建议至少4GB内存。
### 2.2 下载和安装MCode代码生成器
1. 访问MCode官方网站 [www.mcode.com](www.mcode.com),下载最新版本的代码生成器安装包。
2. 解压安装包至您希望安装的目录。
3. 运行安装目录下的启动脚本(如start.sh或start.bat),启动MCode代码生成器。
### 2.3 配置MCode代码生成器的基本参数
在启动MCode代码生成器后,您需要进行基本参数配置,包括但不限于:
- 设置默认生成路径。
- 配置代码生成器的模板库路径。
- 确认数据源连接信息。
以上是MCode代码生成器安装与配置的基本流程,确保按照上述步骤完成后,您就可以开始使用代码生成器进行开发工作了。
# 3. 模板设计与管理
在MCode代码生成器中,模板设计与管理是非常重要的一环,它直接关系到最终生成代码的质量和效率。下面我们一起来详细了解这一部分的内容。
#### 3.1 模板的创建与编辑
在MCode代码生成器中,用户可以通过简单的操作创建和编辑模板,为所需的代码生成定义模板内容。以下是一个Python语言的简单模板示例:
```python
# 生成类
class {{class_name}}:
def __init__(self, {{attributes}}):
{% for attr in attributes %}
self.{{attr}} = {{attr}}
{% endfor %}
def display_info(self):
info = ""
{% for attr in attributes %}
info += "{{attr}}: " + str(self.{{attr}}) + "\n"
{% endfor %}
return info
```
在上面的模板中,我们可以看到使用了类似于Jinja2模板引擎的语法,通过双大括号来引用变量,通过`{% %}`来使用控制语句。
#### 3.2 模板参数介绍
模板参数是模板中用来替换和生成代码的变量,可以是用户输入的静态值,也可以是动态计算得到的内容。在MCode代码生成器中,用户可以灵活定义不同类型的模板参数,包括但不限于:
- 静态文本:如类名、属性名等
- 动态数据:如从数据源获取的字段信息
- 控制标志:用于控制代码生成逻辑的条件参数
#### 3.3 模板的分类与管理
为了方便用户组织和管理模板,MCode代码生成器提供了模板的分类与管理功能。用户可以按照项目、功能模块等需求对模板进行分类,方便查找和管理。同时,用户也可以对模板进行导出和导入,方便模板的共享和备份。
通过良好的模板设计与管理,用户可以提高代码生成的效率和质量,快速生成符合需求的代码,提升开发效率。
# 4. 数据源接入
数据源接入是MCode代码生成器中非常重要的一部分,它决定了代码生成的基础数据以及业务逻辑的实现。在本章节中,我们将详细介绍MCode代码生成器中的数据源接入功能,包括支持的数据源类型、数据源的配置与连接以及在模板中引用数据源的方法。
#### 4.1 支持的数据源类型
MCode代码生成器目前支持多种常见的数据源类型,包括但不限于:
- 关系型数据库:MySQL、PostgreSQL、Oracle、SQL Server等
- NoSQL数据库:MongoDB、Redis、Cassandra等
- 文件数据:CSV、Excel、JSON等
- HTTP接口:RESTful API、GraphQL等
#### 4.2 数据源的配置与连接
在MCode代码生成器中,用户可以通过简单的配置步骤连接各种数据源,具体操作如下:
1. 登录MCode代码生成器系统后,进入数据源管理页面;
2. 点击“新增数据源”,选择相应的数据源类型,并填写必要的连接信息;
3. 测试连接,确认连接成功后保存配置。
#### 4.3 如何在模板中引用数据源
一旦数据源配置完成,用户可以在模板中轻松引用数据源的数据,具体步骤如下:
1. 在模板编辑页面,选择“数据源”标签,可以看到已配置的数据源列表;
2. 选择需要引用的数据源,并设置相关查询条件;
3. 在模板中通过MCode代码生成器提供的变量或函数引用数据源的数据,例如`${dataSourceName.columnName}`。
通过以上方法,用户可以方便地将外部数据源的数据引入到代码生成过程中,实现灵活的数据处理和代码生成。
希望本章内容能够帮助您更好地理解MCode代码生成器中的数据源接入功能。
# 5. 代码生成与定制
在本章中,我们将详细介绍MCode代码生成器的代码生成与定制功能。我们将会讨论如何进行代码生成、如何定制生成的代码以及如何展示和验证生成的结果。
#### 5.1 如何进行代码生成
代码生成是MCode代码生成器最核心的功能之一。通过简单的操作,可以快速生成符合需求的代码。下面以Python语言为例,演示代码生成的基本流程。
```python
# 导入MCode代码生成器库
from MCode import CodeGenerator
# 创建代码生成器实例
generator = CodeGenerator()
# 加载模板
template = generator.load_template('python_api_template')
# 设置数据源
data = {
'class_name': 'User',
'attributes': [
{'name': 'id', 'type': 'int'},
{'name': 'name', 'type': 'str'},
{'name': 'age', 'type': 'int'}
]
}
# 生成代码
generated_code = template.generate(data)
# 打印生成的代码
print(generated_code)
```
上面的代码演示了使用MCode代码生成器生成Python API类的过程。首先导入MCode代码生成器库,然后创建代码生成器实例,加载所需的模板,设置数据源,最后调用模板的generate方法生成代码,并打印生成的代码。
#### 5.2 生成代码的定制与扩展
除了基本的代码生成功能,MCode代码生成器还支持对生成的代码进行定制与扩展。用户可以根据实际需求,对生成的代码进行个性化定制,以满足特定的业务场景。
```python
# 定制生成的代码
def customize_code(generated_code):
# 在生成的代码末尾添加额外的注释
customized_code = generated_code + '\n# This is a customized comment'
return customized_code
# 生成代码
generated_code = template.generate(data)
# 定制生成的代码
customized_code = customize_code(generated_code)
# 打印定制后的代码
print(customized_code)
```
上面的代码演示了对生成的代码进行定制的过程。用户可以编写自定义的定制函数,对生成的代码进行个性化的定制处理,例如在生成的代码末尾添加额外的注释。
#### 5.3 生成结果的展示与验证
生成代码后,通常需要对生成的结果进行展示和验证。MCode代码生成器提供了丰富的展示与验证功能,方便用户查看生成的代码并进行验证测试。
```python
# 生成代码
generated_code = template.generate(data)
# 展示生成的代码
template.show_generated_code(generated_code)
# 验证生成的代码
validation_result = template.validate_generated_code(generated_code)
print(validation_result)
```
上面的代码演示了展示生成的代码和验证生成结果的过程。用户可以使用MCode代码生成器提供的展示和验证方法,轻松查看生成的代码并进行验证测试。
通过本章的学习,相信大家已经对MCode代码生成器的代码生成与定制功能有了初步的了解。在实际应用中,用户可以根据具体的业务需求,灵活运用代码生成与定制功能,提高开发效率,降低重复劳动。
# 6. 其他功能介绍
MCode代码生成器提供了许多实用的功能,除了模板设计与代码生成,还包括导入导出功能、批量处理功能和积木化编程支持。
### 6.1 导入导出功能
MCode代码生成器支持将模板和生成的代码进行导入和导出,方便用户在不同环境之间共享和备份模板和生成结果。用户可以将模板导出为文件,也可以从文件中导入模板进行使用。此外,生成的代码也可以导出为各种格式的文件,便于集成到项目中或者进行版本管理。
代码示例(Python):
```python
# 将模板导出为文件
def export_template(template_id, file_path):
# 实现导出模板的逻辑
pass
# 从文件中导入模板
def import_template(file_path):
# 实现从文件中导入模板的逻辑
pass
# 导出生成的代码
def export_generated_code(code, file_path, format):
# 实现导出生成的代码的逻辑
pass
```
### 6.2 批量处理功能
MCode代码生成器提供了批量处理功能,用户可以将多个模板应用到多个数据源上,一次性生成多组代码。这对于需要生成一系列相关代码的场景非常实用,可以提高工作效率,同时保持代码的统一性。
代码示例(Java):
```java
// 批量应用模板并生成代码
public void generateBatch(List<Template> templates, List<DataSource> dataSources) {
for (Template template : templates) {
for (DataSource dataSource : dataSources) {
String generatedCode = template.generateCode(dataSource);
// 处理生成的代码,例如保存到文件或者提交到版本管理系统
}
}
}
```
### 6.3 积木化编程支持
MCode代码生成器提供了积木化编程的支持,用户可以通过拖拽、连接不同类型的积木来定制生成代码的流程,而无需编写复杂的逻辑。这使得非程序员或者业务人员也能参与到代码生成的过程中,极大地提高了可定制性和灵活性。
代码示例(JavaScript):
```javascript
// 积木化编程示例
function onTemplateSelect(template) {
// 根据选择的模板显示相应的参数积木
}
function onDataSourceSelect(dataSource) {
// 根据选择的数据源显示相应的参数积木
}
function onGenerateButtonClick() {
// 获取用户配置的积木信息,拼接生成代码的流程
// 调用生成代码的接口
}
```
以上是MCode代码生成器的其他功能介绍,这些功能使得MCode代码生成器在实际项目中具有更强大的适用性和灵活性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
MCode代码生成器专栏旨在全面介绍MCode代码生成器的各项功能和开发技巧,帮助读者快速掌握MCode代码生成器的应用及开发方法。从概述开始,逐步深入介绍MCode代码生成器的核心功能、高级功能以及各个组件的详细功能和使用技巧,同时提供开发指南、开发流程、技巧分享和实践案例解析,帮助读者全面了解如何高效地使用和开发MCode代码生成器,并展示自定义业务开发方法。该专栏将为读者提供一个系统的学习平台,使他们能够在实际项目中灵活运用MCode代码生成器,提高开发效率和质量。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ROS运动仿真实用指南】:机械臂操作模拟的关键步骤
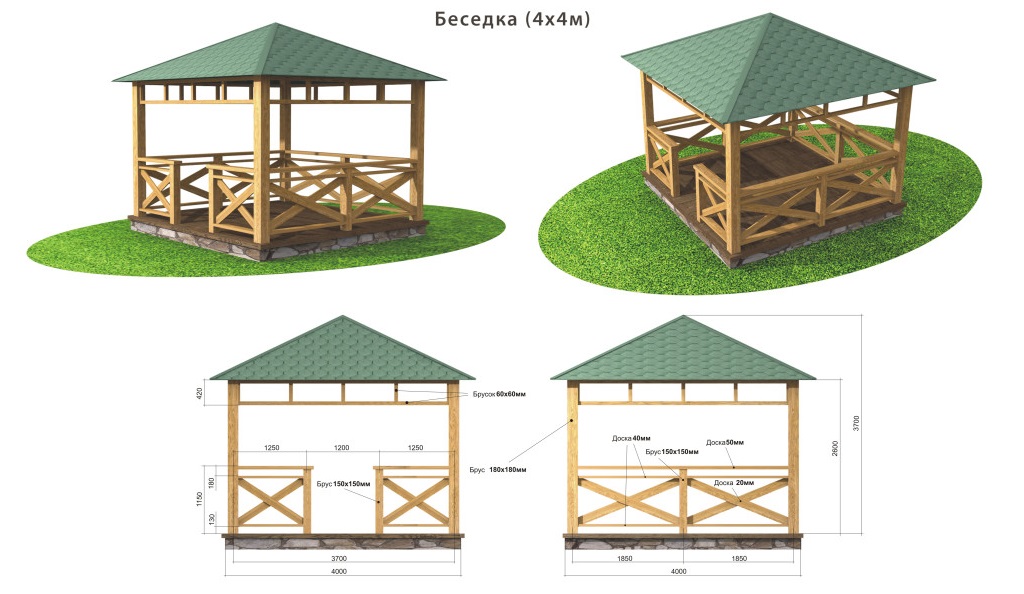
# 摘要
随着机器人技术的快速发展,机械臂仿真技术在自动化领域扮演了至关重要的角色。本文首先介绍了ROS(Robot Operating System)运动仿真基础,强调了机械臂仿真前的准备工作,包括环境配置、模型导入、仿真工具集成等。接着,文章深入探讨了机械臂基本运动的编程实现方法,包括ROS话题、服务和动作协议的应用。第三部分着重于机械臂感知与环境交互能力的构建,包括传感器集成、物体识别、环境建模和避障检测。文章最
【模型泛化秘籍】:如何用ProtoPNet的可解释性助力深度学习模型避免过度拟合

# 摘要
深度学习模型在泛化能力和解释性方面面临着显著挑战。本文首先探讨了这些挑战及其对模型性能的影响,随后深入分析了ProtoPNet模型的设计原理和构建过程,重点讨论了其原型层的工作机制和可解释性。文章接着提出了避免过度拟合的策略,并通过实验验证了 ProtoPNet 在特定问题中的泛化能力。最后,文中对ProtoPNet模型在不同领域的
【MPU-9250数据采集程序】:从零开始,手把手教你编写
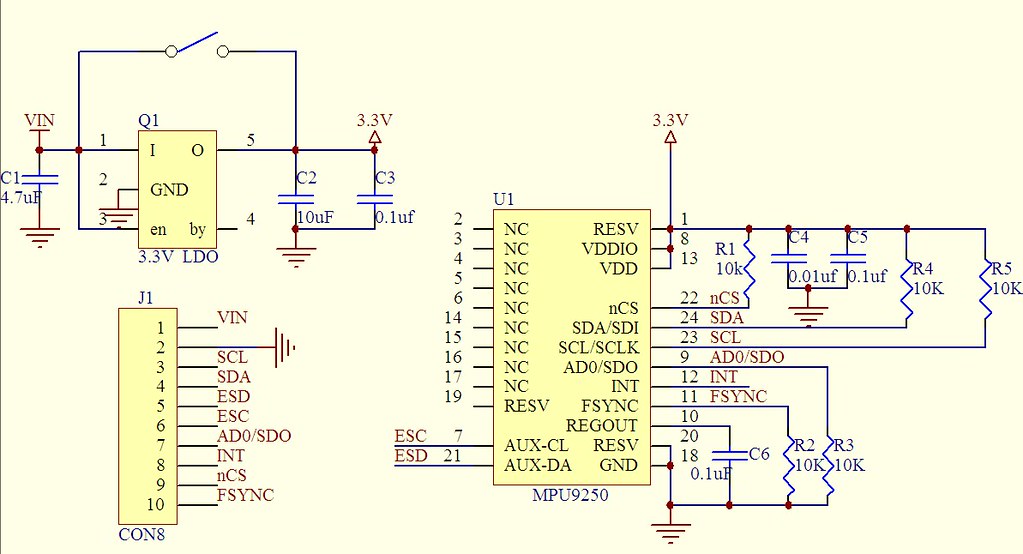
# 摘要
本文旨在全面介绍MPU-9250传感器的工作原理、硬件连接、初始化流程、数据采集理论基础以及编程实践。首先,概述了MPU-9250传感器的功能和结构,并介绍了硬件连接和初始化过程中的关键步骤。随后,详细讨论了数据采集的基本概念、处理技术以及编程接口,为实现精确的数据捕获和分析提供了理论基础。在实践案例与分析部分,通过采集三轴加速度、陀螺仪和磁力计的数据,展示了MPU-9250的实际应用,并
【MAC用户远程连接MySQL全攻略】:一文搞定远程操作
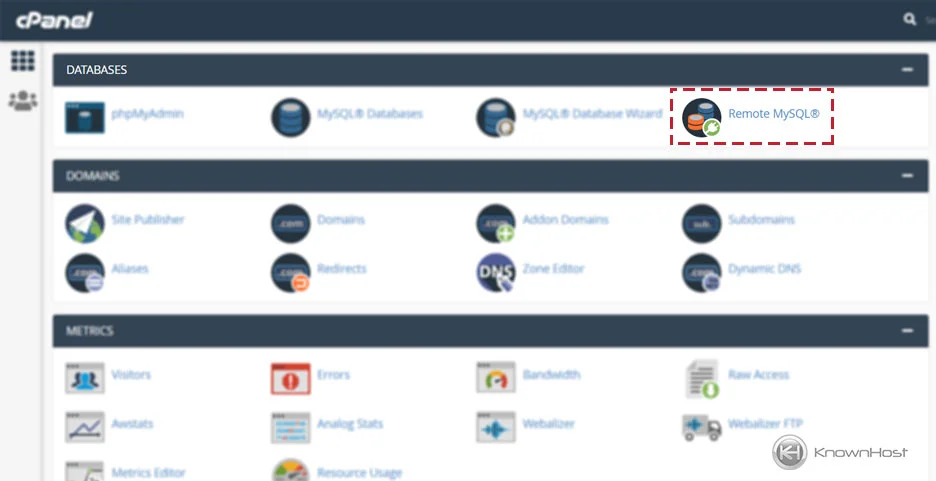
# 摘要
随着信息技术的快速发展,远程连接数据库变得尤为重要,特别是在数据管理和维护方面。本文首先探讨了远程连接MySQL的必要性和准备工作,随后深入到MySQL的配置与安全设置,包括服务器配置、用户权限管理以及远程连接的安全加固。在介绍了MAC端远程连接的软件工具选择后,文章进一步提供了实战操作指导,涵盖了环境检查、操作示例及问题排查
VisionPro监控工具使用手册:实时网络状态监控与实践

# 摘要
随着网络技术的快速发展,网络状态监控变得越来越重要,它能够帮助系统管理员及时发现并处理网络异常,优化网络性能。本文介绍了VisionPro监控工具,从网络监控的基础理论、使用技巧到实践应用进行了全面阐述。文中详细分析了网络监控的重要性及其对系统性能的影响,并探讨了网络流量分析、数据包捕获等关键监控技术原理。同时,本文分享了VisionPro监控工具的安装、配置、使
Matlab专家视角:数字调制系统的完整搭建与案例分析
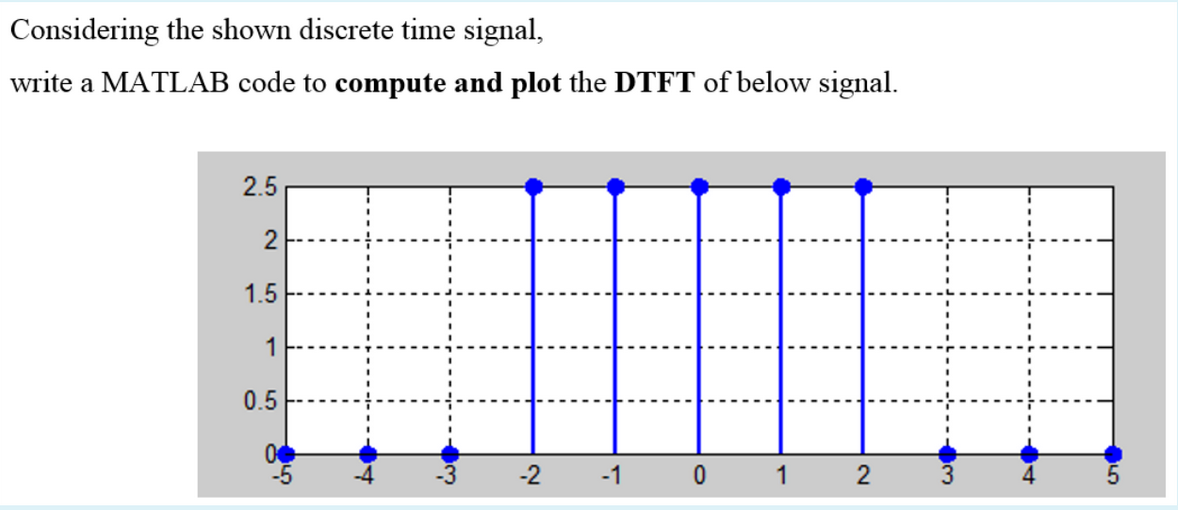
# 摘要
本论文全面探讨了数字调制系统的基本理论、实践应用以及性能分析。首先介绍了数字调制的定义、分类、理论基础和系统组成,随后通过Matlab环境下的调制解调算法实践,展示了调制与解调的实现及其仿真分析。第三章通过模拟分析了不同信号调制过程和噪声对传输信号的影响。在高级数字调制技术章节中,介绍了OFDM和MIMO技术,并评估了其性能。最后一章通过案例研究探讨了数
信号完整性分析:FPGA设计中的PCIE接口优化要点
# 摘要
信号完整性是高性能FPGA设计的关键因素,尤其在PCIE接口的应用中尤为重要。本文首先介绍了信号完整性的基础概念,并概述了FPGA及其在高速数据通信中的作用。随后,深入分析了PCIE接口技术标准以及它在FPGA设计中的作用,强调了信号完整性对FPGA性能的影响。第三章详细探讨了信号完整性基本理论,包括反射、串扰和同步切换噪声等,并讨论了信号完整性参数:阻抗、
【模拟与实验对比】:板坯连铸热过程的精准分析技术

# 摘要
本文综合分析了板坯连铸热过程的基础理论、模拟技术应用、实验方法的重要性以及模拟与实验数据对比分析,并展望了连铸热过程精准分析技术的挑战与发展。通过深入探讨理论、模拟与实验技术的结合,揭示了它们在连铸热过程精准控制中的作用和优化路径。同时,文章也指出了当前技术面临的主要挑战,并对未来技术发展趋势提出了建设性的展望和建议。
# 关键字
板坯连铸;热过程分析;模拟技术;实验方法;数据对比;精准分析技术
参考资源链接
通讯录备份系统云迁移指南:从本地到云服务的平滑过渡

# 摘要
本文全面探讨了通讯录备份系统的云迁移过程,涵盖了从云服务基础理论的选择到系统设计、实现,再到迁移实践和性能调优的整个流程。首先介绍了云迁移的概念和云服务模型,包括不同模型间的区别与应用场景,并对云服务提供商进行了市场分析。随后,重点讨论了通讯录备份系统的架构设计、数据库和应用迁移的优化策略。在迁移实践部分,详细阐述了数据迁移执行步骤、应用部署与测试以及灾难
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )