高级数据探索:ggtech包在R中的顶尖应用技巧
发布时间: 2024-11-07 16:12:46 阅读量: 24 订阅数: 20 

runeterraGGTech:Runeterra GGTech
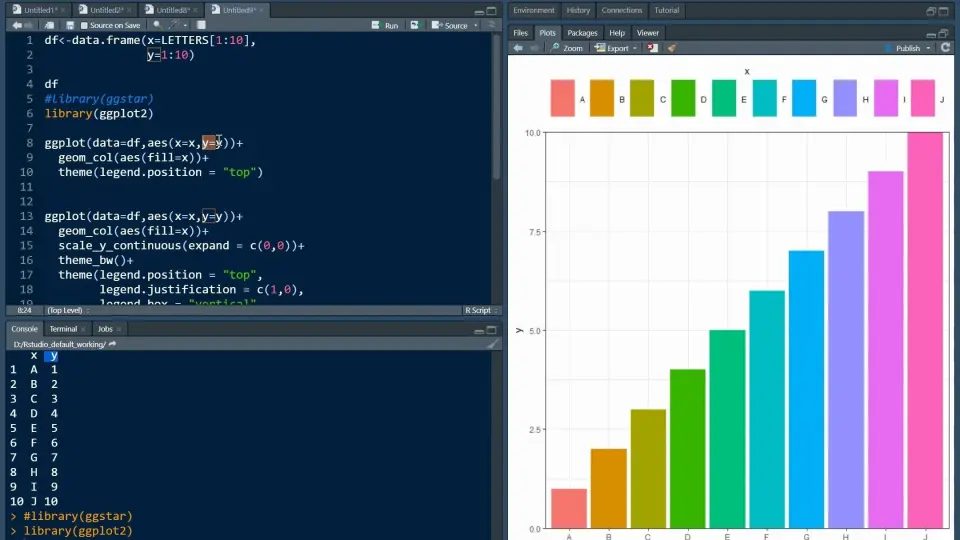
# 1. ggplot2包概述和基本用法
在数据科学领域,可视化工具是传达信息和分析见解的关键。R语言的ggplot2包已经成为生成复杂图形的首选工具之一。它基于“图形语法”概念,允许用户以分层的方式构建图形,每个层都可以添加不同的视觉元素,如点、线、文本等。ggplot2非常适合处理各种类型的数据集,尤其在进行统计分析时,它提供了一种简洁且功能强大的方式来表达数据。
## 1.1 ggplot2包的安装和加载
在R环境中,ggplot2包可以通过以下命令进行安装和加载:
```r
install.packages("ggplot2") # 安装ggplot2包
library(ggplot2) # 加载ggplot2包
```
## 1.2 ggplot2的基本语法结构
ggplot2的基本语法结构是构建图形的基础。一条典型的ggplot2命令如下:
```r
ggplot(data = <DATA>) +
<LAYER> +
<SCALE_> +
<THEME>
```
其中,`<DATA>`表示数据源,`<LAYER>`定义了图形的几何对象层,`<SCALE_>`用于调整数据的范围和颜色映射,`<THEME>`则用于定制图形的整体外观。通过这些层次化的组件,用户可以灵活地定制和展示数据图形。
在下一章中,我们将深入探讨ggplot2的高级绘图技巧,揭示它如何通过细节上的调整来实现美观且信息丰富的数据可视化。
# 2. ggplot2的高级绘图技巧
## 2.1 ggplot2的高级颜色和主题设置
### 2.1.1 颜色映射和调色板
在数据可视化中,颜色不仅是美学元素,更是传达信息的重要手段。ggplot2允许用户自定义调色板,以适应各种数据展示的需要。调色板的使用可以通过内置函数如`scale_color_brewer`或`scale_fill_brewer`,结合`RColorBrewer`包提供的颜色方案来实现。用户也可以使用`scale_color_gradient`来创建一个连续的颜色渐变,或者`scale_color_manual`来自定义每种类别的颜色。
```R
library(ggplot2)
library(RColorBrewer)
# 创建数据集
data <- data.frame(
category = rep(c("A", "B", "C"), each = 100),
value = c(rnorm(100), rnorm(100, mean = 3), rnorm(100, mean = 5))
)
# 绘图并应用调色板
ggplot(data, aes(x = category, y = value, fill = category)) +
geom_boxplot() +
scale_fill_brewer(palette = "Set2") # 应用RColorBrewer调色板
```
在上述代码中,`scale_fill_brewer`函数被用来应用`Set2`配色方案。这种配色方案在图表中呈现出清晰、易区分的颜色,适合类别数据的可视化。
### 2.1.2 主题定制和保存
ggplot2的主题系统允许用户控制非数据属性,比如背景颜色、字体、网格线等。用户可以通过`theme`函数来实现高度个性化的主题定制。此外,`ggtheme`提供了许多预设主题,以帮助用户快速设定一个美观的图表主题。
```R
# 使用预设的ggplot2主题
ggplot(data, aes(x = category, y = value)) +
geom_bar(stat = "identity", fill = "steelblue") +
theme_minimal() # 应用简洁主题
```
在上面的示例中,`theme_minimal`函数提供了一个简洁主题,该主题去除了多余的装饰,使数据更加突出。如果需要保存自定义主题,可以将`theme`函数的结果赋值给一个变量,然后在其他图形中重复使用。
## 2.2 ggplot2的图层添加和组合技巧
### 2.2.1 图层的添加和修改
ggplot2的强大之处在于其图层系统,允许用户逐步构建复杂的图形。每个图层可以添加新的几何对象(如点、线、条形)、统计变换、位置调整等。每个图层都可以独立控制和修改。
```R
# 创建基础图形
base_plot <- ggplot(data, aes(x = category, y = value)) +
geom_bar(stat = "identity", fill = "steelblue")
# 添加和修改图层
final_plot <- base_plot +
geom_hline(yintercept = mean(data$value), linetype = "dashed", color = "red") +
labs(title = "Category Value Distribution",
x = "Category",
y = "Value") +
theme_classic() # 应用经典主题
print(final_plot)
```
在上述代码中,`geom_hline`用于添加一条参考线,`labs`用于修改图表的标题和轴标签,`theme_classic`则应用了一个经典风格的主题。图层的添加和修改都是通过简单的函数调用来完成,非常直观。
### 2.2.2 图层组合的实现和应用
有时候,需要将多个图表组合在一起展示,这时可以使用`cowplot`包或者`patchwork`包。这些包能够提供灵活的组合方式,允许用户以网格形式或者自定义布局来组织多个独立的ggplot2图形。
```R
library(patchwork)
# 创建多个图形
p1 <- ggplot(data, aes(x = category, y = value)) +
geom_violin(fill = "lightblue") +
labs(title = "Violin Plot")
p2 <- ggplot(data, aes(x = value)) +
geom_histogram(binwidth = 1, fill = "darkred") +
labs(title = "Histogram")
# 组合图形
combined_plot <- p1 + p2 + plot_layout(nrow = 1, guides = 'collect')
print(combined_plot)
```
上述代码中,`plot_layout`函数用于设置布局,其中`nrow`参数定义了行数,`guides`参数用于统一图例。使用`+`运算符可以简单地将图形对象组合在一起,`patchwork`包自动处理重叠图例的问题。
## 2.3 ggplot2的交互式图形
### 2.3.1 ggplot2与plotly的结合
ggplot2在与`plotly`包结合后可以创建动态和交互式的图表。这为网页和报告提供了丰富的展示形式。`ggplotly`函数可以将ggplot2创建的图形转换为plotly对象,这样用户就可以通过鼠标操作来探索数据。
```R
library(plotly)
# 将ggplot2图形转换为plotly对象
plotly_plot <- ggplotly(final_plot)
# 输出交互式图形
plotly_plot
```
在代码块中,`ggplotly`函数接收之前创建的`final_plot`,并将其转换为一个交互式的plotly图形。用户现在可以在交互式环境中缩放、拖动,甚至是悬停查看具体的数值信息。
### 2.3.2 交互式图形的创建和修改
创建交互式图形后,还可以对它进行进一步的修改和增强。例如,添加文本标注、改变坐标轴属性、增加特定的数据点标记等。
```R
# 增加交互式图形的元素
plotly_plot %>%
layout(title = "Interactive Category Value Distribution",
xaxis = list(title = "Category"),
yaxis = list(title = "Value")) %>%
add_annotations(x = "A", y = max(data$value), text = "Max value", showarrow = TRUE, arrowhead = 1) %>%
style(hoverinfo = "text", marker = list(size = 10, color = "yellow"))
```
上述代码中,`layout`用于调整图形的标题和坐标轴标签,`add_annotations`用于增加注释,而`style`函数则用于修改交互时的鼠标悬停效果。这些细节的调整使得交互式图形更加易读和有用。
# 3. ggplot2的数据处理和探索
## 3.1 ggplot2的数据转换和处理
在数据处理和转换方面,`ggplot2` 提供了与 `dplyr` 包的无缝接口,这使得数据清洗和初步处理变得轻而易举。本节会深入探讨如何使用 `dplyr` 与 `ggplot2` 结合对数据进行操作,以及这些操作在数据探索中的应用。
### 3.1.1 ggplot2与dplyr的结合
`dplyr` 是一个功能强大的数据处理包,它提供了一系列易于理解的数据操作函数,比如 `filter()`, `select()`, `mutate()`, `summarize()` 等。当与 `ggplot2` 结合时,可以先对数据进行清洗和预处理,然后直接传递给 `ggplot()` 函数进行可视化。
```r
# 安装和加载必要的包
install.packages("ggplot2")
install.packages("dplyr")
library(ggplot2)
library(dplyr)
# 使用dplyr处理数据,然后用ggplot2绘图
diamonds %>%
filter(carat > 0.5) %>%
ggplot(aes(x = cut, fill = cut)) +
geom_bar() +
theme_minimal()
```
在上述代码块中,首先使用 `dplyr` 的 `filter()` 函数筛选出 `diamonds` 数据集中 `carat` 大于 0.5 的钻石数据,然后通过管道操作符 `%>%` 传递给 `ggplot()` 函数创建柱状图。`aes()` 函数中定义了分类变量 `cut` 用于分组,`geom_bar()` 绘制了条形图。`theme_minimal()` 则是应用了一种简洁的主题样式。
### 3.1.2 数据转换和处理的技巧
数据转换与处理是任何数据分析工作的基础。`ggplot2` 和 `dplyr` 的组合使得数据的转换变得非常直观和灵活。例如,使用 `mutate()` 创建新变量,或者使用 `summarize()` 进行汇总统计。
```r
# 使用dplyr创建新变量,然后绘图
diamonds %>%
mutate(price_per_carat = price / carat) %>%
ggplot(aes(x = color, y = price_per_carat, color = color)) +
geom_jitter() +
stat_summary(fun = mean, geom = 'line', aes(group = 1), color = 'red') +
labs(x = "Diamond Colour", y = "Price per Carat")
```
在这段代码中,`mutate()` 用于创建一个新的变量 `price_per_carat`,表示每克拉的价格。然后,通过 `ggplot2` 的 `aes()` 定义了颜色和价格关系,并使用 `geom_jitter()` 在点图中展示数据的分布。`stat_summary()` 函数则添加了表示每种颜色钻石平均价格的线,并通过参数 `fun` 和 `geom` 定义了统计函数和图形类型。
在进行数据转换时,经常需要按组进行操作,`dplyr` 中的 `group_by()` 函数可以实现这一目的,之后可以使用 `summarize()` 对分组后的数据进行汇总。
## 3.2 ggplot2的数据探索和分析
数据探索和分析是理解数据集和发现数据背后故事的关键步骤。`ggplot2` 不仅可以创建美观的图形,还能帮助我们更好地理解数据分布、趋势和关联性。
### 3.2.1 数据探索的方法和技巧
在数据探索阶段,常用的图形包括散点图、箱线图、直方图和条形图等。`ggplot2` 提供了这些图形的绘制函数,通过这些图形可以快速识别数据中的模式和异常值。
```r
# 绘制散点图探索变量间的关系
ggplot(mpg, aes(x = displ, y = hwy, color = class)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE) +
labs(title = "Relationship between engine displacement and highway miles per gallon")
```
这段代码展示了 `mpg` 数据集中的 `displ`(发动机排量)和 `hwy`(高速公路行驶里程每加仑)之间的关系,并使用 `geom_smooth()` 添加了线性回归模型拟合线。每个点的颜色根据 `class`(汽车类型)进行了区分。
### 3.2.2 数据分析的实现和应用
数据分析涉及到计算描述性统计、进行假设检验、建立预测模型等。`ggplot2` 可以辅助可视化这些分析步骤,提供直观的理解。
```r
# 使用ggplot2进行组间比较的箱线图
ggplot(mpg, aes(x = class, y = hwy, fill = class)) +
geom_boxplot() +
coord_flip() +
theme(legend.position = "none") +
labs(title = "Highway miles per gallon by car class")
```
此代码段通过 `geom_boxplot()` 绘制了箱线图,展示了不同类别的汽车在高速公路行驶里程每加仑上的差异。`coord_flip()` 函数用于将图形旋转90度,便于阅读。
## 3.3 ggplot2的数据可视化
数据可视化是将复杂数据通过图形展示出来,使得观察者可以快速理解数据集的关键特征和趋势。
### 3.3.1 高级数据可视化的实现
`ggplot2` 不仅支持基础图形,还支持更为高级和复杂的可视化方法。例如,分面(faceting)、多变量绘图、交互式图形等。
```r
# 使用ggplot2的分面功能进行多图展示
ggplot(diamonds, aes(x = carat, fill = cut)) +
geom_density(alpha = 0.7) +
facet_wrap(~ color, ncol = 4) +
labs(title = "Density of diamond carat by cut and color")
```
在该段代码中,`facet_wrap()` 用于创建分面图形,每个面展示不同颜色钻石按切割质量的密度分布。`nrow` 和 `ncol` 参数可以调整分面的行列数。
### 3.3.2 数据可视化在实际问题中的应用
高级数据可视化通常用于发现数据中更深层次的模式或异常,以及在报告和展示中清晰地传达复杂信息。
```r
# 利用ggplot2进行复杂数据的可视化展示
diamonds %>%
group_by(cut) %>%
summarize(n = n(), avg_price = mean(price)) %>%
ggplot(aes(x = cut, y = avg_price)) +
geom_col() +
geom_text(aes(label = scales::dollar(avg_price)), vjust = -0.5) +
labs(title = "Average diamond price by cut", x = "Cut", y = "Average Price") +
theme_minimal()
```
这段代码先通过 `group_by()` 和 `summarize()` 对 `diamonds` 数据按切割质量进行分组,计算了每组的平均价格,然后用 `geom_col()` 绘制柱状图,并通过 `geom_text()` 在每个柱子上添加了显示平均价格的文本。这有助于快速比较不同切割质量钻石的平均价格。
## 表格
接下来,让我们来看看表格在数据可视化中的重要性,以及如何在Markdown中创建和展示表格。
```markdown
| 钻石颜色 | 平均克拉数 | 平均价格 |
|----------|-----------|------------|
| D | 0.70 | $1568.50 |
| E | 0.70 | $1482.45 |
| F | 0.71 | $1635.95 |
| G | 0.72 | $1487.95 |
| H | 0.72 | $1448.05 |
```
以上表格展示了不同颜色的钻石的平均克拉数和平均价格。表格是清晰传达这些统计数据的有效方式,能够帮助观察者快速捕捉到关键信息。
## Mermaid 流程图
Mermaid 是一种基于文本的图表绘制语言,可以用来创建流程图、序列图、甘特图等。我们来看看如何用Mermaid绘制一个数据可视化流程图。
```mermaid
graph TD;
A[开始] --> B[收集数据];
B --> C[清洗数据];
C --> D[数据探索];
D --> E[数据可视化];
E --> F[分析和解释];
F --> G[报告];
G --> H[结束];
```
通过Mermaid流程图,我们能够一目了然地理解数据可视化的整个过程。
## 代码块与执行逻辑
最后,我们提供一个R代码块,展示如何使用 `ggplot2` 进行数据可视化的详细步骤。
```r
# 安装和加载所需的库
install.packages("ggplot2")
library(ggplot2)
# 使用ggplot2绘制简单的散点图
ggplot(mtcars, aes(x = wt, y = mpg)) +
geom_point() + # 添加散点图层
geom_smooth(method = "lm", se = FALSE) + # 添加线性回归线
labs(title = "汽车重量与油耗的关系") # 添加图表标题
```
在这个例子中,我们首先加载了 `ggplot2` 库,然后使用 `mtcars` 数据集绘制了汽车重量与油耗的散点图,加入了线性回归线,并添加了图表标题。
通过结合本章的内容,读者不仅能够熟练使用 `ggplot2` 进行数据处理和探索,还可以将分析结果以更加直观和信息丰富的形式展现出来。这样的技能在任何数据科学项目中都是非常宝贵的。
# 4. ggplot2在实际项目中的应用
在数据分析领域,ggplot2不仅仅是一个可视化工具,它更是一种强大的分析语言,能够将复杂的数据结构和关系通过图形的方式展现出来。在不同行业领域中,ggplot2的实际应用能够带来不同方面的数据理解和决策支持。在本章,我们将深入探讨ggplot2在金融、生物和社交媒体数据分析中的具体应用案例。
## 4.1 ggplot2在金融数据分析中的应用
金融行业依靠数据来揭示市场动向、客户行为和风险管理。ggplot2通过其强大的图形表达能力,为金融分析师提供了直观的数据展示方式,帮助他们更好地理解市场和数据。
### 4.1.1 金融数据的可视化
在金融分析中,时间序列数据是常见的数据类型。ggplot2可以通过时间序列数据来展示股票价格趋势、交易量等信息。
```r
library(ggplot2)
# 假设我们有股票价格数据
stock_data <- data.frame(
Date = seq(as.Date("2022-01-01"), by = "day", length.out = 100),
Close = sin(seq(0, 2 * pi, length.out = 100)) * 100 + 1000 # 生成模拟的股票收盘价
)
# 使用ggplot2绘制股票价格趋势图
ggplot(stock_data, aes(x = Date, y = Close)) +
geom_line() +
labs(title = "股票价格趋势图", x = "日期", y = "收盘价")
```
在上述示例中,我们使用ggplot2绘制了一个简单的时间序列图。通过`geom_line()`函数,我们以线图的方式展示了股票价格随时间的变化趋势。`labs()`函数用于添加图表的标题和轴标签。
### 4.1.2 金融数据分析的实现
除了可视化,ggplot2还能够帮助分析师通过图形发现数据中的模式。例如,通过绘制价格与交易量的关系图,可以揭示价格变动背后的市场动力。
```r
# 假设我们有模拟的交易量数据
stock_data$Volume <- rnorm(100, mean = 1000, sd = 300) * 1000
# 绘制价格与交易量的关系图
ggplot(stock_data, aes(x = Close, y = Volume)) +
geom_point() +
labs(title = "股票价格与交易量关系图", x = "收盘价", y = "交易量")
```
通过上述代码,我们创建了一个散点图来表示股票收盘价与交易量之间的关系。分析这样的图可以帮助识别价格波动与交易活动之间的关联。
## 4.2 ggplot2在生物数据分析中的应用
在生物信息学领域,ggplot2同样发挥着关键作用。它可以帮助研究人员探索基因表达数据、生物标记物等,并通过图形展示结果。
### 4.2.1 生物数据的可视化
基因芯片数据的分析和可视化可以借助ggplot2实现。例如,热图是用于显示基因表达模式的常用图形,ggplot2提供了相应功能。
```r
# 生成模拟基因表达数据
gene_expression <- data.frame(
Gene = paste("Gene", 1:20),
Expression = runif(20, min = -1, max = 1)
)
# 绘制基因表达热图
ggplot(gene_expression, aes(x = Gene, y = "Expression", fill = Expression)) +
geom_tile() +
scale_fill_gradient2(low = "blue", high = "red", mid = "white",
midpoint = 0, limit = c(-1,1), space = "Lab") +
theme_minimal() +
labs(title = "基因表达热图", x = NULL, y = NULL)
```
在这个例子中,我们使用`geom_tile()`函数创建了一个热图,用以展示不同基因在不同样本中的表达水平。颜色映射是通过`scale_fill_gradient2()`来定义的,不同的颜色代表表达水平的不同范围。
### 4.2.2 生物数据分析的实现
在生物数据分析中,ggplot2还能帮助我们展示样本之间的关系。例如,通过绘制聚类图,我们可以观察不同样本间的相似性和差异性。
```r
# 假设我们有样本聚类数据
sample_cluster <- data.frame(
Sample = paste("Sample", 1:10),
Cluster = sample(1:2, 10, replace = TRUE)
)
# 绘制样本聚类图
ggplot(sample_cluster, aes(x = Sample, y = "Cluster", fill = factor(Cluster))) +
geom_bar(stat = "identity") +
scale_fill_manual(values = c("#999999", "#E69F00"), name = "Cluster") +
labs(title = "样本聚类图", x = NULL, y = NULL)
```
这里我们创建了一个条形图来表示样本的聚类信息。样本按照所属的簇进行着色,从而直观展示不同簇之间的样本分布情况。
## 4.3 ggplot2在社交媒体数据分析中的应用
社交媒体产生的数据量巨大,通过ggplot2的分析和可视化功能,可以揭示用户行为模式、话题趋势等关键信息。
### 4.3.1 社交媒体数据的可视化
推特上的热门话题或趋势可以通过时间序列分析来可视化。ggplot2的图形功能可以很直观地展示话题随时间的变化。
```r
# 假设我们有推特热门话题的提及次数数据
twitter_data <- data.frame(
Date = seq(as.Date("2022-06-01"), by = "day", length.out = 30),
Mentions = sample(1:500, 30, replace = TRUE)
)
# 绘制热门话题提及次数的趋势图
ggplot(twitter_data, aes(x = Date, y = Mentions)) +
geom_line() +
geom_point() +
labs(title = "推特热门话题提及次数趋势", x = "日期", y = "提及次数")
```
通过上述代码,我们绘制了一个线图与点图相结合的图形,直观地显示了话题在一段时间内的提及频率变化。
### 4.3.2 社交媒体数据分析的实现
社交媒体数据中的文本信息同样可以通过ggplot2进行可视化分析。例如,通过词云图可以展示与特定话题相关的高频词汇。
```r
# 假设我们有热门话题的相关词汇数据
wordcloud_data <- data.frame(
Word = sample(c("R", "ggplot2", "data", "visualization", "analysis"), 100, replace = TRUE),
Frequency = sample(1:10, 100, replace = TRUE)
)
# 绘制词云图
library(wordcloud)
ggplot(wordcloud_data, aes(label = Word, size = Frequency)) +
geom_text_wordcloud_area(shape = "circle") +
scale_size_area(max_size = 25) +
labs(title = "话题相关词汇词云图")
```
使用`geom_text_wordcloud_area()`函数,我们根据词频生成了一个词云图,让读者可以直观地看出与话题相关联的关键词汇。
以上章节仅是ggplot2在实际应用中的一瞥。在接下来的章节中,我们将继续深入探讨ggplot2的高级应用技巧,包括性能优化、扩展包应用以及未来的趋势预测。
# 5. ggplot2的高级应用技巧总结
ggplot2作为R语言中最受欢迎的绘图包之一,其高级应用技巧是数据分析师和科学家不可或缺的知识。本章节将重点介绍ggplot2的性能优化、扩展包应用以及未来的发展趋势。通过深入解析,读者将能够进一步提高数据可视化效率,扩展ggplot2功能,并紧跟其发展趋势。
## 5.1 ggplot2的性能优化
随着数据集的增大,ggplot2绘图的性能问题可能会变得明显,尤其是在复杂图形的渲染过程中。性能优化是提高工作效率的关键。
### 5.1.1 ggplot2的性能问题和解决方案
性能问题主要表现在:
- **数据处理速度慢**:大型数据集在绘图前的处理阶段可能需要较长的时间。
- **图形渲染速度慢**:复杂的图形,特别是那些包含大量数据点或者多个图层的图形,在渲染时可能会花费较多时间。
解决方案包括:
- **数据下采样**:当数据量过大时,可以采用随机抽样或者聚合的方法减少数据点。
- **使用更高效的数据结构**:如使用data.table代替data.frame,或者优化数据的读取和存储格式。
- **代码优化**:例如,避免在绘图前进行大量的数据操作,将操作前移至数据准备阶段。
### 5.1.2 ggplot2的性能优化技巧
接下来,我们将介绍一些具体的ggplot2性能优化技巧。
#### *.*.*.* 使用ggsave优化文件保存
`ggsave`函数不仅用于保存图形,还可以通过调整参数来优化保存过程中的性能。
```R
# 示例代码
p <- ggplot(data, aes(x, y)) + geom_point()
ggsave("plot.png", plot = p, type = "cairo-png", dpi = 300, limitsize = FALSE)
```
- `type`参数决定了保存图形的类型,使用`"cairo-png"`可以提高保存向量图形的性能。
- `dpi`参数控制输出图形的分辨率,较高的值可能会影响保存速度。
- `limitsize`为`FALSE`时,允许输出大图,有时这能提升性能。
#### *.*.*.* 使用Rcpp提高ggplot2底层效率
对于需要更底层的性能提升,可以考虑使用Rcpp包将关键代码段转换为C++代码。
```R
# 示例:Rcpp 包装函数
library(Rcpp)
cppFunction('
DataFrame my_summary(DataFrame df) {
// C++ 代码来处理数据
return df;
}')
```
需要注意的是,虽然Rcpp可以显著提升性能,但同时也增加了编程的复杂度,需要慎重考虑是否使用。
## 5.2 ggplot2的扩展包应用
ggplot2已经非常强大,但其扩展包可以进一步增强其功能,以适应更复杂的场景。
### 5.2.1 ggplot2的扩展包介绍
ggplot2的核心是`ggplot`,而其扩展包则提供了新的功能或者改善现有功能。
- **ggthemes**:提供了多种现成的主题,可以快速改变图形的外观。
- **ggridges**:用于创建山脊图(ridge plots),非常适合展示多组数据的分布情况。
- **ggalt**:提供了一些额外的几何对象,如误差线、梯形、梯形条等。
- **ggforce**:增强ggplot2的动画功能,提供了多点连接、圆点等额外的几何图形。
### 5.2.2 扩展包在ggplot2中的应用
我们来看一个使用ggplot2扩展包的例子。
```R
# 安装并加载扩展包
install.packages("ggthemes")
library(ggthemes)
# 使用ggthemes扩展包来改变主题
p <- ggplot(data, aes(x, y)) + geom_point()
p + theme_economist()
```
这段代码应用了Economist杂志风格的主题,使图形看起来更加专业。
## 5.3 ggplot2的未来发展趋势
随着数据科学的发展,ggplot2也在不断进步以适应新的需求。
### 5.3.1 ggplot2的未来发展预测
未来的发展方向可能包括:
- **交互式图形的改进**:随着Shiny和htmlwidgets的结合,交互式图形将变得更加便捷和强大。
- **跨平台支持**:支持更多数据格式和导出选项,让ggplot2的图形更容易在不同的环境中展示。
- **性能的进一步优化**:随着R语言的优化,ggplot2的性能也会得到提升。
### 5.3.2 如何跟上ggplot2的发展步伐
要跟上ggplot2的发展步伐,有以下几点建议:
- **定期阅读官方文档和社区讨论**:这是了解最新进展和讨论问题的最佳方式。
- **参与社区**:通过提问和解答,可以与社区进行互动并学习新技巧。
- **实践和尝试**:新版本发布后,尝试新功能,通过实践来掌握它们。
通过本章节的介绍,我们可以看到ggplot2不仅是一个强大的绘图工具,而且拥有不断进化的生态系统。掌握性能优化、扩展包应用以及跟踪最新动态,对于提升ggplot2应用技巧至关重要。
# 6. ggplot2的实战案例分析
## 6.1 案例研究:使用ggplot2绘制复杂数据图表
在本章中,我们将深入探讨如何使用ggplot2包来创建复杂的图表,并结合实际案例进行分析。这将帮助我们理解ggplot2的实用性以及如何在实际项目中有效地利用它的强大功能。
### 6.1.1 数据准备和导入
在开始绘图之前,首先需要对数据进行处理。这包括数据的导入、清洗、转换和准备。
```r
# 加载ggplot2和其他有用的包
library(ggplot2)
library(dplyr)
library(readr)
# 读取数据集
data <- read_csv("data.csv")
```
### 6.1.2 高级绘图技巧应用
在这个部分,我们将重点介绍如何应用ggplot2的高级绘图技巧来构建复杂的图形。例如,我们将展示如何创建多变量的散点图矩阵。
```r
# 创建多变量散点图矩阵
ggplot(data, aes(x = var1, y = var2)) +
geom_point() +
facet_wrap(~var3)
```
接下来,我们将探讨如何通过图层叠加的方式来增强图表的信息量。
### 6.1.3 图层叠加和信息增强
通过图层叠加,可以添加额外的数据信息,比如趋势线、置信区间等。
```r
# 添加线性回归趋势线
ggplot(data, aes(x = var1, y = var2)) +
geom_point() +
geom_smooth(method = "lm")
```
通过这种方式,我们可以逐步建立一个包含丰富信息的图表。
### 6.1.4 交互式元素的集成
ggplot2可以与plotly包集成,创建交互式图表。
```r
# 使用ggplotly将静态图表转换为交互式图表
library(plotly)
ggplotly(p = ggplot(data, aes(x = var1, y = var2)) +
geom_point())
```
## 6.2 案例分析:ggplot2在具体领域中的应用
在本节中,我们将讨论ggplot2在不同领域的应用,包括金融、生物和社交媒体数据分析案例。
### 6.2.1 ggplot2在金融领域的应用
例如,我们如何用ggplot2来展示股票价格的动态变化。
```r
# 加载股票价格数据
stock_data <- read_csv("stock_prices.csv")
# 绘制股票价格趋势图
ggplot(stock_data, aes(x = Date, y = Close, group = Symbol)) +
geom_line(aes(color = Symbol)) +
theme_minimal()
```
### 6.2.2 ggplot2在生物数据分析中的应用
生物信息学数据的可视化,例如基因表达数据的可视化。
```r
# 加载基因表达数据集
expression_data <- read_csv("expression_data.csv")
# 绘制基因表达热图
ggplot(expression_data, aes(x = Gene, y = Sample, fill = Expression)) +
geom_tile() +
scale_fill_gradient(low = "blue", high = "red") +
theme_minimal()
```
### 6.2.3 ggplot2在社交媒体数据分析中的应用
社交媒体数据可视化的一个例子是,分析推文的情感趋势。
```r
# 加载推文情感分析数据
sentiment_data <- read_csv("sentiment_data.csv")
# 绘制推文情感趋势图
ggplot(sentiment_data, aes(x = Time, y = Sentiment)) +
geom_line() +
facet_wrap(~Topic) +
theme_minimal()
```
## 6.3 案例总结和未来展望
通过本章的案例分析,我们可以看到ggplot2的灵活性和应用的广度。未来,随着ggplot2版本的更新和R语言的不断发展,我们可以预见更多的特性和工具将被集成到ggplot2中,以满足更高级和专业的需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 R 语言中功能强大的 ggtech 数据包,提供了一系列全面的教程和指南。从基础入门到高级应用,专栏涵盖了 ggtech 的各个方面,包括与 ggplot2 的对比、顶尖应用技巧、图形参数详解、交互式图表制作、时间序列分析、机器学习集成、统计分析、教育应用和商业智能中的作用。通过深入浅出的讲解和丰富的案例分析,本专栏旨在帮助数据分析师、数据科学家和研究人员掌握 ggtech 的强大功能,从而有效地探索、可视化和呈现数据,做出明智的决策。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【16位加法器设计秘籍】:全面揭秘高性能计算单元的构建与优化

# 摘要
本文对16位加法器进行了全面的研究和分析。首先回顾了加法器的基础知识,然后深入探讨了16位加法器的设计原理,包括二进制加法基础、组成部分及其高性能设计考量。接着,文章详细阐述
三菱FX3U PLC编程:从入门到高级应用的17个关键技巧

# 摘要
三菱FX3U PLC是工业自动化领域常用的控制器之一,本文全面介绍了其编程技巧和实践应用。文章首先概述了FX3U PLC的基本概念、功能和硬件结构,随后深入探讨了
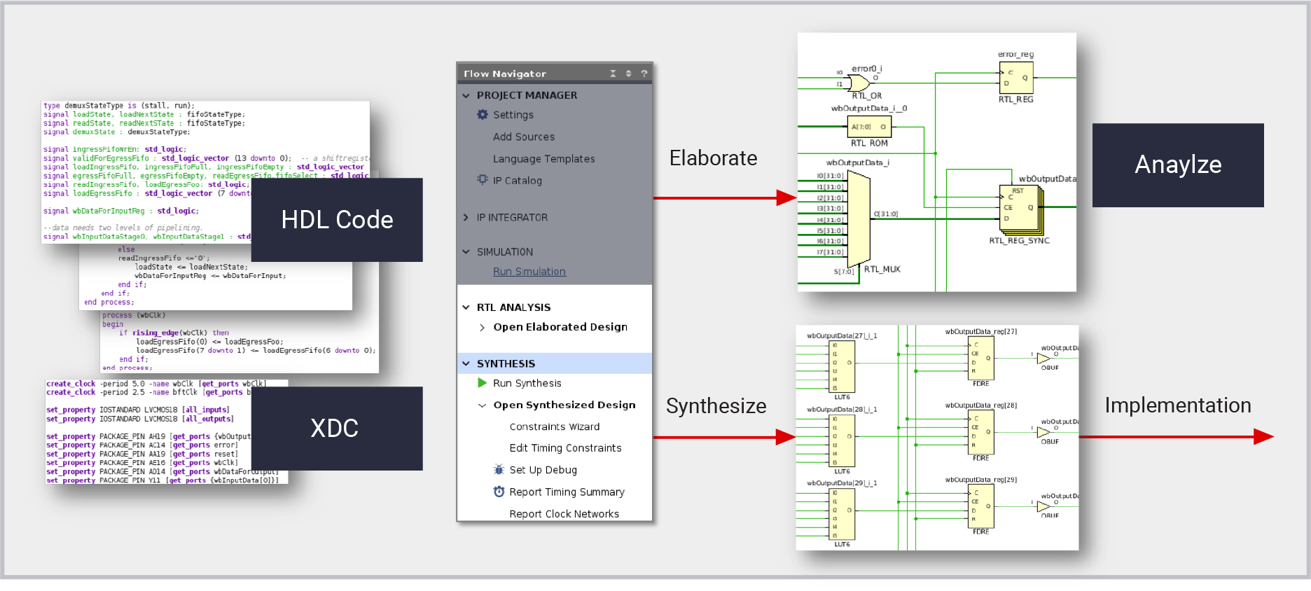
【Xilinx 7系列FPGA深入剖析】:掌握架构精髓与应用秘诀
# 摘要
本文详细介绍了Xilinx 7系列FPGA的关键特性及其在工业应用中的广泛应用。首先概述了7系列FPGA的基本架构,包括其核心的可编程逻辑单元(PL)、集成的块存储器(BRAM)和数字信号处理(DSP)单元。接着,本文探讨了使用Xilinx工具链进行FPGA编程与配置的流程,强调了设计优化和设备配置的重要性。文章进一步分析了7系列FPGA在
【图像技术的深度解析】:Canvas转JPEG透明度保护的终极策略

# 摘要
随着Web技术的不断发展,图像技术在前端开发中扮演着越来越重要的角色。本文首先介绍了图像技术的基础和Canvas绘
【MVC标准化:肌电信号处理的终极指南】:提升数据质量的10大关键步骤与工具
# 摘要
MVC标准化是肌电信号处理中确保数据质量的重要步骤,它对于提高测量结果的准确性和可重复性至关重要。本文首先介绍肌电信号的生理学原理和MVC标准化理论,阐述了数据质量的重要性及影响因素。随后,文章深入探讨了肌电信号预处理的各个环节,包括噪声识别与消除、信号放大与滤波技术、以及基线漂移的校正方法。在提升数据质量的关键步骤部分,本文详细描述了信号特征提取、MVC标准化的实施与评估,并讨论了数据质量评估与优化工具。最后,本文通过实验设计和案例分析,展示了MVC标准化在实践应用中的具
ISA88.01批量控制:电子制造流程优化的5大策略

# 摘要
本文首先概述了ISA88.01批量控制标准,接着深入探讨了电子制造流程的理论基础,包括原材料处理、制造单元和工作站的组成部分,以及流程控制的理论框架和优化的核心原则。进一步地,本文实
【Flutter验证码动画效果】:如何设计提升用户体验的交互

# 摘要
随着移动应用的普及和安全需求的提升,验证码动画作为提高用户体验和安全性的关键技术,正受到越来越多的关注。本文首先介绍Flutter框架下验证码动画的重要性和基本实现原理,涵盖了动画的类型、应用场景、设计原则以及开发工具和库。接着,文章通过实践篇深入探讨了在Flutter环境下如何具体实现验证码动画,包括基础动画的制作、进阶技巧和自定义组件的开发。优化篇
ENVI波谱分类算法:从理论到实践的完整指南
# 摘要
ENVI软件作为遥感数据处理的主流工具之一,提供了多种波谱分类算法用于遥感图像分析。本文首先概述了波谱分类的基本概念及其在遥感领域的重要性,然后介绍了ENVI软件界面和波谱数据预处理的流程。接着,详细探讨了ENVI软件中波谱分类算法的实现方法,通过实践案例演示了像元级和对象级波谱分类算法的操作。最后,文章针对波谱分类的高级应用、挑战及未来发展进行了讨论,重点分析了高光谱数据分类和深度学习在波谱分类中的应用情况,以及波谱分类在土地覆盖制图和农业监测中的实际应用。
# 关键字
ENVI软件;波谱分类;遥感图像;数据预处理;分类算法;高光谱数据
参考资源链接:[使用ENVI进行高光谱分
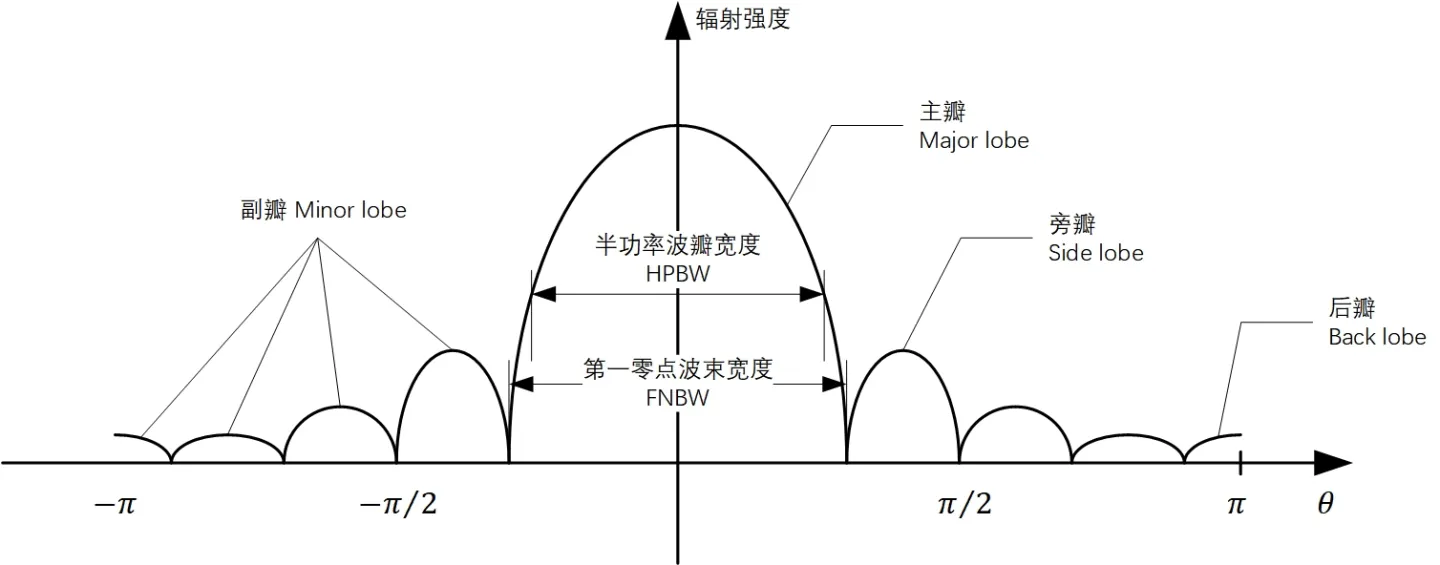
【天线性能提升密籍】:深入探究均匀线阵方向图设计原则及案例分析
# 摘要
本文深入探讨了均匀线阵天线的基础理论及其方向图设计,旨在提升天线系统的性能和应用效能。文章首先介绍了均匀线阵及方向图的基本概念,并阐述了方向图设计的理论基础,包括波束形成与主瓣及副瓣特性的控制。随后,论文通过设计软件工具的应用和实际天线系统调试方法,展示了方向图设计的实践技巧。文中还包含了一系列案例分析,以实证研究验证理论,并探讨了均匀线阵性能
【兼容性问题】快解决:专家教你确保光盘在各设备流畅读取
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/L/w/I3DfXKTAmrqNi0rGtG5A/2014-06-24-cd-dvd-bluray.png)
# 摘要
光盘作为一种传统的数据存储介质,其兼容性问题长
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )