Linux内核锁高级技巧:RCU与顺序锁的应用指南


内核的rcu锁移植到就应用层的实现
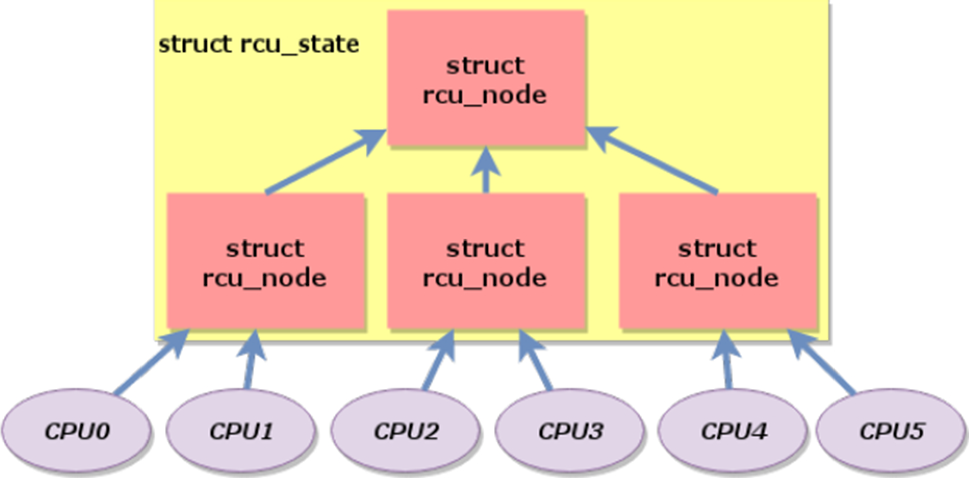
1. Linux内核锁机制概述
Linux操作系统作为开源界的巨擘,其内核锁机制是保障系统稳定性与性能的核心技术之一。在多核处理器的背景下,各种锁机制应运而生,它们协调着并发访问共享资源的复杂场景。理解Linux内核锁机制的原理和实现,不仅对于系统编程至关重要,也对于性能优化、故障排查和系统架构设计有着深远的意义。
本章将带领读者进入Linux内核锁机制的世界,从最基本的锁概念开始,逐步深入到更复杂的锁技术。我们将重点介绍互斥锁(mutex)、自旋锁(spinlock)以及顺序锁(seqlock)等基础锁类型,并简要概述RCU(Read-Copy Update)等先进的无锁编程技术。为后续章节对RCU和顺序锁深入分析打下坚实基础。通过本章的学习,读者将能够理解各种锁机制的设计哲学、优缺点以及适用场景,为进一步掌握Linux内核锁技术奠定基础。
2. RCU(Read-Copy Update)原理及实践
2.1 RCU基础理论
2.1.1 RCU的设计初衷与优势
RCU(Read-Copy Update)是一种广泛应用于现代多核处理器的并发控制机制,其核心设计目标是优化读多写少的数据结构的并发访问。RCU的设计初衷是提供一种读取操作不需要加锁的并发控制方法,使得读操作可以与写操作以及其它读操作并行执行。在传统的锁机制中,读写操作通常需要获取锁,这会导致写操作阻塞读操作,甚至在高竞争的环境下造成性能瓶颈。
RCU的优势在于:
- 读写分离:读操作与写操作互不干扰,读操作无需锁定,且可以同时执行。
- 低延迟:在没有写操作发生的情况下,读操作几乎没有延迟。
- 扩展性:随着系统中处理器数量的增加,RCU的性能通常会相应提高。
2.1.2 RCU的核心概念解读
RCU的核心概念包括:
- 读者(Readers):执行读操作的线程或进程。
- 写者(Writers):执行写操作的线程或进程。
- 保护区域(Protected Region):需要被RCU保护的数据结构和相关操作。
- 更新(Update):写者对受保护数据结构的修改过程。
- 延迟释放(Grace Period):系统确保所有旧版本数据引用结束的时间段。
在RCU机制中,写者在更新数据前需要复制一份数据结构的副本,并在该副本上进行修改。修改完成后,通过回调函数将旧版本的数据结构释放。由于写操作不会阻塞读操作,所以写者需要等待一段时间(延迟释放),确保在此期间的读操作都能安全完成,即在数据结构被更新前,已经没有读者正在使用旧的数据版本。
2.2 RCU在内核中的应用
2.2.1 RCU的应用场景分析
RCU特别适合用在如下场景:
- 树形结构的并发读写:例如文件系统和网络路由表。
- 链表的并发读写:例如用户管理、模块管理等。
- 热点缓存的并发读写:如目录项缓存。
在这些场景中,RCU能够提供低延迟的读操作和非阻塞的写操作,从而提高系统整体的并发性能。
2.2.2 RCU同步机制的实现细节
RCU同步机制的实现细节主要包括以下几个方面:
- 读侧API:
rcu_read_lock()和rcu_read_unlock()分别用于标记读操作的开始和结束。这两个函数使读者可以安全地访问受保护的数据结构。 - 写侧API:
call_rcu()允许写者异步地注册一个回调函数,该函数将在未来的某个时刻(即延迟释放期间)被系统调用,以完成数据结构的释放。 - rcu_assign_pointer() 和
rcu_dereference():用于在写侧和读侧之间安全地进行指针的赋值和解引用操作。
2.3 RCU的性能优化与最佳实践
2.3.1 RCU性能调优技巧
RCU的性能调优通常关注以下几个方面:
- 合理选择数据结构:根据使用场景选择最合适的内核数据结构,并应用RCU保护。
- 最小化延迟释放:延迟释放的最小化可以减少系统中未使用的旧数据的存活时间,从而释放更多内存和处理能力。
- 限制回调函数的执行时间:回调函数应当短小精悍,避免在延迟释放期间执行耗时操作。
2.3.2 RCU常见问题解答与调试技巧
在实际使用RCU时,常见问题包括:
- 内存泄漏:长时间未完成的延迟释放可能会导致内存泄漏。
- 竞态条件:不恰当的RCU API使用可能导致竞态条件。
调试RCU相关问题时,可以使用以下技巧:
- 静态分析:利用静态代码分析工具检查RCU API的使用是否正确。
- 动态检测:使用内核提供的动态检测工具,如
CONFIG_RCU_EQS_DEBUG,帮助发现潜在的RCU问题。
在接下来的章节中,我们将深入了解顺序锁(seqlock)的原理与应用,探讨如何在实际场景中选择合适的锁机制,并展示高级应用技巧,以及对Linux内核锁机制未来的发展方向进行展望。
3. 顺序锁(seqlock)的原理与应用
在高性能计算和多核处理器的普及下,顺序锁(seqlock)作为一种轻量级的同步机制,在内核编程中扮演着重要的角色。它旨在提供一种读取操作几乎不受锁影响,而写入操作会阻止读取的机制。本章节将深入探索顺序锁的设计目的、工作原理、代码实现以及性能评估与优化。
3.1 顺序锁的理论基础
3.1.1 顺序锁的设计目的
顺序锁旨在解决并发系统中的读写问题,它允许读操作几乎无锁地进行,同时确保数据的一致性和完整性。这种锁特别适合读多写少的场景,因为它允许多个读操作并发进行,而写操作则独占锁资源。与传统的读写锁相比,顺序锁的写入开销较小,因为它不阻塞读操作(除非有写操作正在进行),但是它对读操作有一定的限制,特别是在写入期间。
3.1.2 顺序锁的内部工作机制
顺序锁通过两部分来实现其机制:一个是原子变量,用来记录顺序锁的状态;另一个是数据本身。原子变量通常包含一个序列号,用于追踪对数据的写操作次数。读操作在开始之前会读取这个序列号,并在读取数据后再次检查序列号。如果序列号未发生变化,读操作可以安全地返回数据。如果序列号发生变化,说明有写入操作正在发生或已完成,读操作需要重新开始以确保数据的一致性。
3.2 顺序锁的代码实现分析
3.2.1 顺序锁API的使用方法
在Linux内核中,顺序锁的API相对简单。主要包括以下几种操作:
write_seqlock()和write_sequnlock():分别用于开始和结束写操作。read_seqbegin()和read_seqretry():分别用于开始和结束读操作。
在写入数据前,调用write_seqlock(),完成数据修改后,调用write_sequnlock()。而读取数据时,首先通过read_seqbegin()开始读取,如果在读取结束前发现数据的序列号改变了,就通过read_seqretry()重新尝试读取。
3.2.2 顺序锁的实例解析
- #include <linux/seqlock.h>
- static DEFINE_SEQLOCK(my_seqlock);
- void read_data(void)
- {
- unsigned int seq;
- int da

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
【T-Box能源管理】:智能化节电解决方案详解
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
Cygwin系统监控指南:性能监控与资源管理的7大要点
【精准测试】:确保分层数据流图准确性的完整测试方法


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )










