【Mplus 8缺失数据处理】:全方位指导与案例分析,确保分析准确性
发布时间: 2024-12-02 19:16:56 阅读量: 2 订阅数: 7 

参考资源链接:[Mplus 8用户手册:输出、保存与绘图命令详解](https://wenku.csdn.net/doc/64603ee0543f8444888d8bfb?spm=1055.2635.3001.10343)
# 1. Mplus 8缺失数据概述
数据分析的完整性和准确性对于任何研究来说都是至关重要的。然而,研究过程中不可避免地会遇到数据缺失的问题。Mplus 8,作为一款功能强大的统计软件,提供了多种处理缺失数据的方法。在Mplus中处理缺失数据不仅可以提高数据分析的精确度,还能够帮助研究者更好地理解数据背后的信息。本章旨在提供Mplus 8处理缺失数据的基础知识,为后续章节的深入探讨和应用案例打下坚实的基础。我们将从缺失数据的类型和机制讲起,逐步深入到Mplus的具体处理方法,最终通过案例分析展示这些方法在实际研究中的应用。
# 2. 缺失数据的理论基础
## 2.1 缺失数据类型和机制
### 2.1.1 完全随机缺失(MCAR)
完全随机缺失(Missing Completely At Random, MCAR)是缺失数据中最简单也是最理想的情况。在MCAR的假设下,数据缺失的机制并不依赖于可观测的变量和不可观测的变量。换句话说,缺失数据发生与否与任何变量的值无关。数学上,如果我们将数据集中的观测值表示为\(Y\),缺失指示变量表示为\(R\),那么在MCAR的条件下,缺失数据的概率\(P(R_{ij}=1)\)与\(Y\)和\(R\)本身无关。
理解MCAR对于选择适当的缺失数据处理方法至关重要。当数据确实符合MCAR时,许多处理方法(如列删法和多重插补)能够有效减少偏差。然而,实际应用中,验证数据是否确实符合MCAR假设是具有挑战性的。一些统计检验可以用来辅助判断MCAR假设,但没有绝对的判断标准。因此,研究者需要仔细评估其数据的性质,如果可以合理地假设MCAR,那么可以采用更简单直接的处理方法。
### 2.1.2 随机缺失(MAR)
随机缺失(Missing At Random, MAR)发生在缺失数据的概率仅依赖于可观测变量,而不依赖于缺失值本身。在 MAR 的情况下,即使缺失数据与某些可观测的变量有关,只要缺失值的模式可以用已观测到的数据来解释,那么就可以认为是 MAR。更形式化的描述是,在MAR条件下,对于任何缺失数据点\(Y_{\text{miss}}\),缺失的概率\(P(R_{ij}=1|Y)\)不依赖于\(Y_{\text{miss}}\),但是可以依赖于\(Y_{\text{obs}}\),即观测到的数据。
与MCAR相比,MAR更为常见,但对处理方法的选择也更为复杂。在MAR条件下,如果使用了列删法,可能会引入选择性偏差。因此,推荐使用更复杂的多重插补或者模型直接估计方法。值得注意的是,在实际研究中,研究者需要通过模型诊断来检查数据是否可能为 MAR,或者在模型中对可能与数据缺失有关的变量进行控制。
### 2.1.3 非随机缺失(NMAR)
非随机缺失(Not Missing At Random, NMAR),也被称为非随机丢失或非随机缺失,是缺失数据处理中最为复杂的情况。在NMAR情况下,缺失的概率既依赖于缺失值本身,也可能依赖于未观测到的变量。对于一个特定的数据点\(Y_{\text{miss}}\),其缺失的概率\(P(R_{ij}=1|Y)\)可能依赖于\(Y_{\text{miss}}\)或未观测的变量,即使控制了所有可观测的变量\(Y_{\text{obs}}\)也无法解释这种缺失。
NMAR 的存在使得数据缺失处理变得相当困难,因为缺失机制不能仅仅通过观测数据来建模。处理NMAR的常用策略包括敏感性分析,即检查缺失数据对研究结论的影响程度。模型需要明确包含缺失数据的概率模型,或使用一些特定的统计方法,例如选择模型(Selection Models)或混合模型(Mixture Models),这些方法尝试直接对缺失数据的概率建模,而不仅仅是简单地插补缺失值。
## 2.2 缺失数据的统计影响
### 2.2.1 参数估计偏差
当缺失数据在数据集中存在时,最直接的统计影响就是参数估计偏差。由于缺失数据,分析可能未能包括所有样本点,导致估计的参数不能代表整个总体。在不恰当的处理缺失数据的情况下,这会直接影响参数估计的准确性。
参数估计偏差的程度取决于缺失数据的类型和量。对于MCAR,如果数据丢失机制确实和数据值无关,那么在一些情况下(如数据量大),可以使用列删法处理而不会产生大的偏差。然而,对于MAR或NMAR,简单的列删法往往会导致偏差。这种偏差会影响模型的解释力和预测准确性,进而可能导致错误的结论和推断。
### 2.2.2 标准误的影响
缺失数据还会对估计量的标准误差产生显著影响。标准误差衡量了估计量的变异性,反映了估计量在重复抽样下可能的变化范围。当数据缺失发生时,标准误差可能会被低估或高估,这取决于所采用的处理方法和缺失数据的机制。
在MCAR的情况下,如果使用了多重插补或模型直接估计法,标准误差通常会得到更准确的估计。但在MAR和NMAR的情况下,处理方法的选择就更加关键,因为不恰当的处理可能会导致标准误差的失真。标准误差的失真可能会进一步影响统计推断,如置信区间和假设检验的有效性。
### 2.2.3 假设检验的准确性
缺失数据会对统计检验的准确性产生负面影响,因为缺失数据会影响样本统计量的分布。当使用传统的方法进行假设检验时,如果数据是不完整的,那么检验的结论(如拒绝或不拒绝零假设)的可靠性就会受到影响。
例如,在存在大量缺失数据的情况下,进行t检验或卡方检验可能会得出错误的结论,因为这些检验假设了完整的数据集。在实际研究中,使用适当的缺失数据处理方法(如多重插补或模型直接估计法)可以提供更加准确的假设检验结果。这些方法能够通过适当的统计推断来考虑缺失数据的存在,从而减少由于数据缺失对假设检验准确性的影响。
# 3. Mplus 8中的缺失数据处理方法
### 3.1 列删法(Listwise Deletion)
#### 3.1.1 列删法的原理与应用
列删法,亦称为个案删除法,是一种直观的缺失数据处理技术。它通过简单地从分析中剔除含有缺失值的观测个体来实现。具体而言,当分析数据集中某个变量存在缺失值时,整个观测个案都会被移除,仅使用完整个案进行后续统计分析。
在统计软件中,比如Mplus 8,列删法通常是默认的处理缺失数据的方式,尤其适用于缺失数据为完全随机缺失(MCAR)时。由于它的操作简便,它成为了处理缺失数据的初步策略。
#### 3.1.2 列删法的优缺点分析
*优点*:
- 简单易行:在各种软件包中,列删法是默认或最简单的选项。
- 不涉及复杂假设:不需要对数据缺失模式做过多的假设。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ArcGIS图像叠加技术】:图片与指北针整合的终极指南
参考资源链接:[ArcGIS中使用风玫瑰图片自定义指北针教程](https://wenku.csdn.net/doc/6401ac11cce7214c316ea83e?spm=1055.2635.3001.10343)
# 1. ArcGIS图像叠加技术概述
## 1.1 图像叠加技术的重要性
图像叠加是地理信息系统(GIS)中常用的一种技术,它能够将不同来源和不同时间的图像数据进行有效的结合和分析。通过图像叠加,GIS专业人员可以更好地展示和分析地表覆盖、城市规划、环境监测以及灾害评估等多种复杂场景。这项技术在提高数据利用效率、增强视觉表现力和辅助决策支持方面发挥着重要作用。
## 1.
KISSsoft与CAE工具整合术:跨平台设计协同的终极方案
参考资源链接:[KISSsoft 2013全实例中文教程详解:齿轮计算与应用](https://wenku.csdn.net/doc/6x83e0misy?spm
【PowerBI数据流转】:高效导入导出方法的完全教程
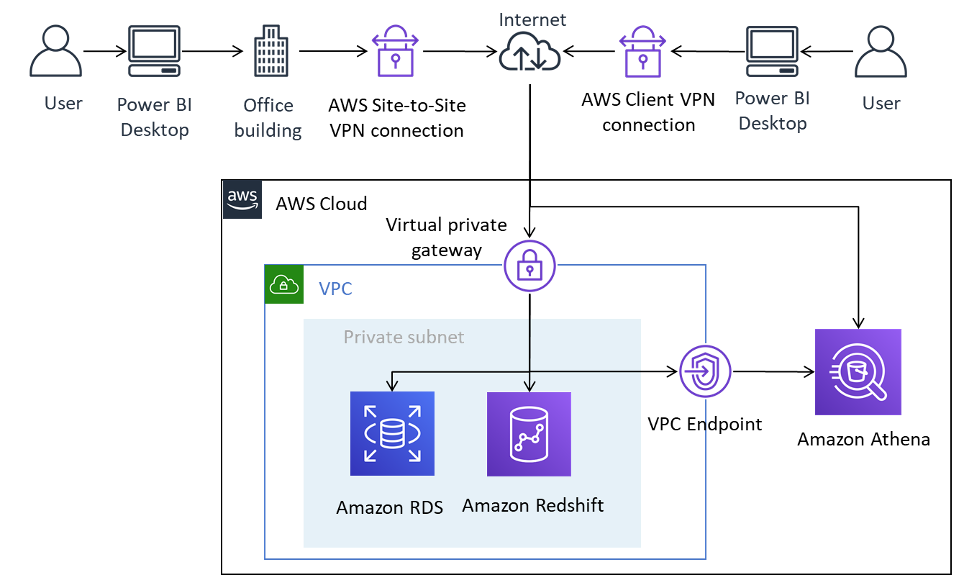
参考资源链接:[PowerBI使用指南:从入门到精通](https://wenku.csdn.net/doc/6401abd8cce7214c316e9b55?spm=1055.2635.3001.10343)
# 1. PowerBI数据流转概述
在信息技术不断发展的今天,数据已经成为了企业宝贵的资产之一。在各类业务决策
VW 80000中文版维护与更新:流程与最佳实践详解

参考资源链接:[汽车电气电子零部件试验标准(VW 80000 中文版)](https://wenku.csdn.net/doc/6401ad01cce7214c316edee8?spm=1055.2635.3001.10343)
# 1. VW 80000中文版维护与更新概述
随着信息技术的飞速发展,VW 80000中文版作为一款广泛应
SCL脚本的文档编写:提高代码可读性的最佳策略

参考资源链接:[西门子PLC SCL编程指南:指令与应用解析](https://wenku.csdn.net/doc/6401abbacce7214c316e9485?spm=1055.2635.3001.10343)
# 1. SCL脚本的基本概念与重要性
SCL(Structured Control Language)是一种高级编程语言,主要用于可编程逻辑控制器(PLC)和工业自动化环境中。它结合了高级
【Mplus 8潜在类别分析】:LCA的深入探讨与实际应用案例解析
参考资源链接:[Mplus 8用户手册:输出、保存与绘图命令详解](https://wenku.csdn.net/doc/64603ee0543f8444888d8bfb?spm=1055.2635.3001.10343)
# 1. Mplus 8潜在类别分析简介
## 潜在类别分析的概念
潜在类别分析(Latent Class Analysis, LCA)是一种用于揭示未观测(潜在)分类的统计方法。这种分析能够识别数据中的潜在模式和结构,尤其适用于研究对象无法直接测量的分类变量。Mplus 8作为一个强大的统计软件,提供了进行此类分析的工具和功能。
## LCA在Mplus 8中的重要性
【Search-MatchX数据备份与恢复策略】:确保数据安全无忧的4大方法

参考资源链接:[使用教程:Search-Match X射线衍射数据分析与物相鉴定](https://wenku.csdn.net/doc/8aj4395hsj?spm=1055.2635.3001.10343)
# 1. 数据备份与恢复的基本概念
在数字时代,数据是企业最宝贵的资产之一。数据备份与恢复是保障企业数据安全、维护业务连续性的核心技术
【Halcon C++数据结构与算法优化策略】:图像处理中提升效率的秘诀(专家分析)

参考资源链接:[Halcon C++中Hobject与HTuple数据结构详解及转换](https://wenku.csdn.net/doc/6412b78abe7fbd1778d4aaab?spm=1055.2635.3001.10343)
# 1. Halcon C++概述与应用背景
在现代工业自动化与
【APDL参数化模型建立】:掌握快速迭代与设计探索,加速产品开发进程
参考资源链接:[Ansys_Mechanical_APDL_Command_Reference.pdf](https://wenku.csdn.net/doc/4k4p7vu1um?spm=1055.2635.3001.10343)
# 1. APDL参数化模型建立概述
在现代工程设计领域,参数化模型已成为高效应对设计需求变化的重要手段。APDL(ANSYS Parametric Design Language)作为ANSYS软件的重要组成部分,提供了一种强大的参数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )