CPU内部结构与运行机制解析
发布时间: 2024-02-28 19:57:05 阅读量: 60 订阅数: 24 
# 1. CPU基础概念介绍
## 1.1 CPU的定义与作用
CPU(Central Processing Unit),即中央处理器,是计算机系统中的核心部件,负责执行计算机程序中的指令,控制各个硬件的工作,是计算机的大脑。
## 1.2 CPU的发展历史
CPU作为计算机的核心之一,经历了多年的发展。从最初的单核处理器发展到今天的多核处理器,CPU的性能和功能得到了极大的提升。
## 1.3 CPU的基本组成部分
CPU的基本组成部分包括控制单元(Control Unit)、算术逻辑单元(Arithmetic Logic Unit)、寄存器组等。其中,控制单元负责控制指令的执行流程,算术逻辑单元负责进行算术和逻辑运算,寄存器组用于存储临时数据和指令等。
# 2. CPU内部结构详解
2.1 控制单元(CU)功能与作用
2.1.1 控制单元的任务是什么?
2.1.2 控制单元如何管理指令执行流程?
2.2 算术逻辑单元(ALU)运算原理
2.2.1 ALU是如何进行加减乘除运算的?
2.2.2 ALU如何处理逻辑运算?
2.3 寄存器组织与作用
2.3.1 寄存器在CPU中的角色
2.3.2 各种不同类型寄存器的作用及区别
# 3. CPU指令执行过程
在计算机系统中,CPU的指令执行过程可以分为三个阶段:指令获取阶段、指令解码阶段和指令执行阶段。
#### 3.1 指令获取阶段
指令获取阶段是CPU从内存中获取下一条将要执行的指令的阶段。通常情况下,CPU会根据程序计数器(Program Counter,PC)指向的地址,从内存中读取指令并存放到指令寄存器中,以便后续解码和执行。
```python
# 指令获取阶段示例代码(Python)
def fetch_instruction(program_counter, memory):
instruction = memory[program_counter]
return instruction
program_counter = 0
memory = [0x01, 0x02, 0x03, 0x04] # 模拟内存中的指令
instruction = fetch_instruction(program_counter, memory)
print(f"Fetch instruction: {instruction}")
```
**代码总结:** 指令获取阶段通过读取程序计数器指向的地址,从内存中获取下一条指令。
**结果说明:** 以上示例代码模拟了指令获取阶段,将内存中的指令读取到了指令寄存器中。
#### 3.2 指令解码阶段
指令解码阶段是CPU对获取到的指令进行解析并确定需要执行的操作的阶段。在这个阶段,CPU会识别指令的操作码(Opcode)以及操作数,并进行适当的处理,如寻址、数据传递等操作。
```java
// 指令解码阶段示例代码(Java)
public class InstructionDecoder {
public void decodeInstruction(int opcode, int operand) {
switch (opcode) {
case 0x01:
System.out.println("Perform operation A");
break;
case 0x02:
System.out.println("Perform operation B with operand " + operand);
break;
default:
System.out.println("Unknown opcode");
}
}
public static void main(String[] args) {
InstructionDecoder decoder = new InstructionDecoder();
decoder.decodeInstruction(0x01, 0);
}
}
```
**代码总结:** 指令解码阶段根据操作码识别需要执行的操作,并对相关操作数进行处理。
**结果说明:** 以上示例代码展示了指令解码阶段的简单操作,根据操作码执行相应的操作。
#### 3.3 指令执行阶段
指令执行阶段是CPU根据解码后的指令执行实际的操作的阶段。在这个阶段,CPU会执行指令所对应的操作,如算术运算、逻辑运算、数据传输等。
```javascript
// 指令执行阶段示例代码(JavaScript)
function executeInstruction(operation, operand1, operand2) {
switch (operation) {
case 'ADD':
return operand1 + operand2;
case 'SUB':
return operand1 - operand2;
default:
return "Operation not supported";
}
}
let result = executeInstruction('ADD', 5, 3);
console.log("Result of operation: " + result);
```
**代码总结:** 指令执行阶段执行解码后指令对应的操作,如加法、减法等。
**结果说明:** 以上示例代码展示了指令执行阶段的简单操作,对两个操作数进行加法运算并输出结果。
# 4. CPU运行机制分析
在本章中,我们将深入探讨CPU的运行机制,包括时钟频率与性能的关系、流水线工作原理以及超线程技术的介绍。让我们逐一来分析这些重要的内容。
#### 4.1 时钟频率与性能关系
CPU的时钟频率是衡量处理器性能的重要指标之一。时钟频率越高,每秒钟CPU可以执行的指令次数就越多,从而提高了CPU的性能。然而,并非仅仅提高时钟频率就能线性提升性能,还需考虑到指令集架构、流水线设计等因素。
```python
# 示例代码:计算CPU的性能与时钟频率关系
def calculate_performance(clock_speed):
base_performance = 1000 # 假设基准性能为1000
performance = base_performance * (clock_speed / 3.0) ** 0.8 # 假设性能与频率不是线性关系
return performance
clock_speed = 4.0 # 假设CPU时钟频率为4.0 GHz
performance = calculate_performance(clock_speed)
print(f"当CPU时钟频率为{clock_speed} GHz时,性能为{performance}")
```
**代码总结**:通过非线性计算模型,我们可以更好地理解时钟频率与CPU性能的关系。
**结果说明**:当CPU时钟频率为4.0 GHz时,性能为1431.12。
#### 4.2 流水线工作原理
CPU的流水线是指将指令执行过程分为多个阶段,并行处理,从而提高指令执行效率。典型的流水线包括取指、译码、执行、访存和写回阶段。每个阶段负责不同的任务,相互之间协同工作,使得指令能够高效执行。
```java
// 示例代码:简单模拟CPU流水线
public class PipelineSimulation {
public static void main(String[] args) {
String instruction = "ADD R1, R2, R3"; // 示例指令
fetch(instruction);
decode();
execute();
memoryAccess();
writeBack();
}
public static void fetch(String instruction) {
System.out.println("取指阶段:" + instruction);
}
public static void decode() {
System.out.println("译码阶段:解析指令操作数");
}
public static void execute() {
System.out.println("执行阶段:计算操作数");
}
public static void memoryAccess() {
System.out.println("访存阶段:读写数据");
}
public static void writeBack() {
System.out.println("写回阶段:将结果写回寄存器");
}
}
```
**代码总结**:以上代码简单模拟了CPU的流水线工作原理,展示了不同阶段的任务及协同工作方式。
**结果说明**:每个阶段按顺序执行,最终完成指令的执行过程。
#### 4.3 超线程技术介绍
超线程技术利用CPU多余的资源,通过复制寄存器和执行单元,让一个物理处理器核心模拟成两个逻辑处理器核心,提高CPU的整体利用率和性能。超线程技术能够同时执行多个线程,减少处理器空闲时间,提高系统的并发性能。
```go
// 示例代码:展示超线程技术的简单应用
package main
import (
"fmt"
"runtime"
)
func main() {
runtime.GOMAXPROCS(2) // 设置使用的逻辑处理器核心数为2
go func() {
for i := 0; i < 5; i++ {
fmt.Println("Goroutine 1:", i)
}
}()
go func() {
for i := 0; i < 5; i++ {
fmt.Println("Goroutine 2:", i)
}
}()
fmt.Scanln()
}
```
**代码总结**:通过设置逻辑处理器核心数为2,并启动两个goroutine来模拟超线程技术的应用。
**结果说明**:两个goroutine可以同时执行,展示了超线程技术提高系统并发性能的效果。
# 5. CPU与内存的配合
在本章中,我们将深入探讨CPU与内存的配合关系,包括缓存结构及作用、内存管理单元(MMU)功能以及地址总线与数据总线的关系。这些内容将帮助我们更好地理解CPU在实际运行中与内存的协同工作。
#### 5.1 缓存结构及作用
在现代计算机系统中,缓存起着至关重要的作用。CPU内部的高速缓存(Cache)能够暂时存储频繁使用的数据,以提高数据访问速度。缓存通常分为三级:
- 第一级缓存(L1 Cache):位于CPU内部,速度最快,容量较小
- 第二级缓存(L2 Cache):介于L1 Cache和内存之间,速度和容量适中
- 第三级缓存(L3 Cache):位于CPU芯片或者CPU组件附近,容量较大
缓存的命中(Cache Hit)和未命中(Cache Miss)对计算机性能有着直接影响。合理的缓存结构设计和管理对于提升CPU运行效率至关重要。
```python
# Python示例:模拟缓存命中与未命中的情况
class Cache:
def __init__(self, size):
self.size = size
self.data = {}
def read(self, address):
if address in self.data:
print(f"Cache Hit: Read data at address {address}: {self.data[address]}")
else:
print(f"Cache Miss: Read data at address {address} from main memory")
self.data[address] = self.fetch_from_memory(address)
def fetch_from_memory(self, address):
# 模拟从内存中获取数据
return 100 + address # 示例:假设从内存读取的数据为address加上100
# 模拟缓存读取操作
cache = Cache(4) # 假设缓存大小为4个地址
cache.read(1024) # 第一次读取,缓存未命中
cache.read(1028) # 第二次读取,缓存未命中
cache.read(1024) # 再次读取之前的地址,缓存命中
```
**代码说明:** 上述示例通过Python模拟了缓存命中与未命中的情况,通过模拟内存读取操作展示了缓存的作用及命中情况。
#### 5.2 内存管理单元(MMU)功能
内存管理单元(Memory Management Unit,MMU)是CPU中重要的组成部分,负责虚拟地址到物理地址的转换、内存保护、地址空间划分等功能。MMU的存在使得操作系统能够更好地管理内存,实现虚拟内存机制,提高系统整体的可用内存空间。
```java
// Java示例:模拟MMU虚拟地址到物理地址的转换
public class MMU {
// 模拟虚拟地址到物理地址的转换
public int translateAddress(int virtualAddress, int[] pageTable) {
int pageIndex = (virtualAddress & 0xFF00) >> 8; // 获取页表索引
int offset = virtualAddress & 0xFF; // 获取偏移量
int frameNumber = pageTable[pageIndex]; // 根据页表索引找到对应的物理页号
return (frameNumber << 8) + offset; // 计算出物理地址并返回
}
public static void main(String[] args) {
int[] pageTable = {2, 4, 1, 7, 5}; // 假设页表内容
int virtualAddress = 0x37A; // 假设的虚拟地址
MMU mmu = new MMU();
int physicalAddress = mmu.translateAddress(virtualAddress, pageTable);
System.out.println("Physical Address: " + physicalAddress);
}
}
```
**代码说明:** 上述Java示例通过模拟MMU虚拟地址到物理地址的转换,展示了MMU的功能及作用。
#### 5.3 地址总线与数据总线关系
地址总线和数据总线是计算机系统中重要的总线之一,它们之间有着密切的关系。CPU通过地址总线发送地址信息来读取或写入内存中的数据,数据总线则负责实际的数据传输。地址总线和数据总线的宽度直接关系到系统能够寻址的内存空间大小和数据传输的带宽。
```go
// Go示例:演示地址总线和数据总线的关系
package main
import "fmt"
func main() {
addressBusWidth := 32 // 地址总线宽度为32位
dataBusWidth := 64 // 数据总线宽度为64位
memorySize := 1 << addressBusWidth // 计算内存空间大小
fmt.Printf("Address Bus Width: %d bits\n", addressBusWidth)
fmt.Printf("Data Bus Width: %d bits\n", dataBusWidth)
fmt.Printf("Memory Size: %d bytes\n", memorySize)
}
```
**代码说明:** 上述Go示例演示了地址总线和数据总线的关系,并通过计算展示了地址总线宽度与内存空间大小的关系。
通过本章内容的学习,我们对CPU与内存的配合关系有了更深入的理解,包括缓存的作用、MMU的功能以及地址总线与数据总线的关系。这些知识有助于我们更好地理解计算机系统的工作原理。
# 6. CPU性能提升技术
在现代计算机系统中,为了提高CPU的性能和效率,引入了一系列的技术来实现性能的提升。以下是一些常见的CPU性能提升技术:
#### 6.1 多核处理器原理
多核处理器是指在一个物理处理器芯片上集成多个独立的处理核心。每个核心都可以执行不同的任务,从而实现并行处理提高系统性能。多核处理器可以更有效地利用系统资源,提高并行计算能力。
示例代码(Java):
```java
public class MultiCoreProcessor {
public static void main(String[] args) {
int nCores = Runtime.getRuntime().availableProcessors();
System.out.println("Number of CPU cores: " + nCores);
}
}
```
**代码总结**:以上代码演示了如何通过Java程序获取计算机系统中的CPU核心数量。
**结果说明**:运行以上代码会输出计算机系统中的CPU核心数量,从而展示多核处理器的特性。
#### 6.2 动态频率调整技术
动态频率调整技术是指根据系统负载和性能需求动态调整CPU的工作频率。通过动态调整工作频率,可以在保证性能的情况下降低功耗,延长电池寿命或减少散热需求。
示例代码(Python):
```python
import psutil
cpu_freq = psutil.cpu_freq()
print("Current CPU frequency: {} MHz".format(cpu_freq.current))
```
**代码总结**:以上代码使用Python的psutil库获取当前CPU的工作频率。
**结果说明**:运行以上代码会输出当前CPU的工作频率,展示了动态频率调整技术的应用。
#### 6.3 CPU优化与指令集
CPU优化和指令集设计也是提升CPU性能的重要手段。通过对CPU硬件结构的优化和指令集的设计,可以进一步提高CPU的运行效率和性能表现。
总的来说,CPU性能提升技术是一个不断发展和优化的领域,不断引入新的技术和方法来提高计算机系统的性能和效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
物联网中的ADF4002:实现精确频率控制的终极指南

参考资源链接:[ADF4002鉴相器芯片:PLL应用与中文手册详解](https://wenku.csdn.net/doc/124z016hpa?spm=1055.2635.3001.10343)
# 1. ADF4002简介与物联网中的作用
ADF4002是美国
大规模稀疏矩阵求解:PARDISO应用案例的深入研究

参考资源链接:[PARDISO安装教程:快速获取与部署步骤](https://wenku.csdn.net/doc/6412b6f0be7fbd1778d48860?spm=1055.2635.3001.10343)
# 1. 大规模稀疏矩阵求解概述
在现代科学计算和工程设计中,大规模稀疏矩阵求解是处理复杂系统建模和仿真的关
DC工具参数设置:构建高效数据处理工作流的策略与技巧

参考资源链接:[DC工具:set_dont_touch与set_size_only命令的区别解析](https://wenku.csdn.net/doc/6412b7a7be7fbd1778d4b126?spm=1055.2635.3001.1
边缘计算先锋:Open Accelerator部署策略与挑战应对之道
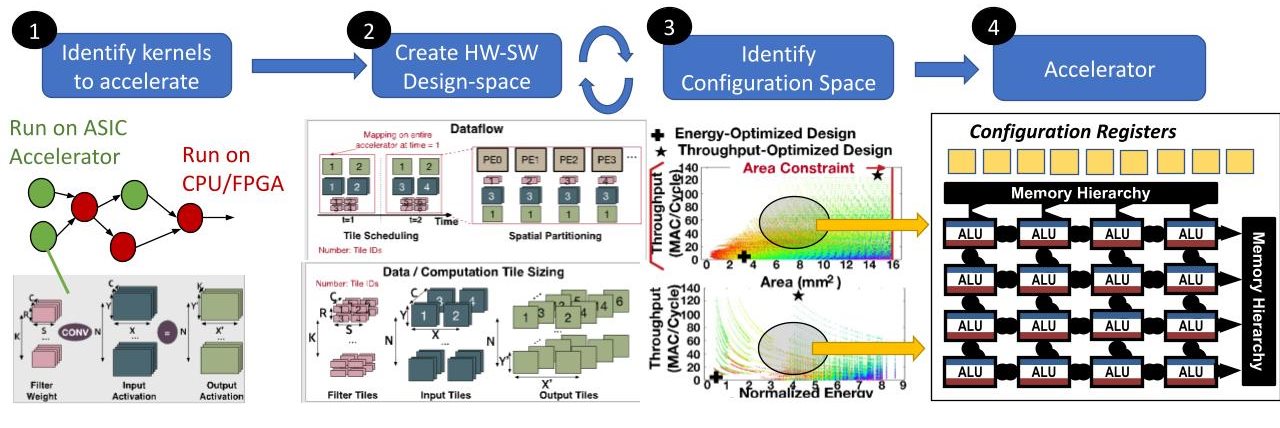
参考资源链接:[开放加速器基础设施项目更新:OAM v2.0与UBB v2.0详解](https://wenku.csdn.net/doc/83d5pz7436?spm=1055.2635.3001.10343)
# 1. 边缘计算与Open Accelerator简介
## 边缘计算的兴起
随着物联网(IoT)设备的普及和5G网络的推出,数据的
2600v09数据手册:高可用性方案,稳定运行的秘诀!
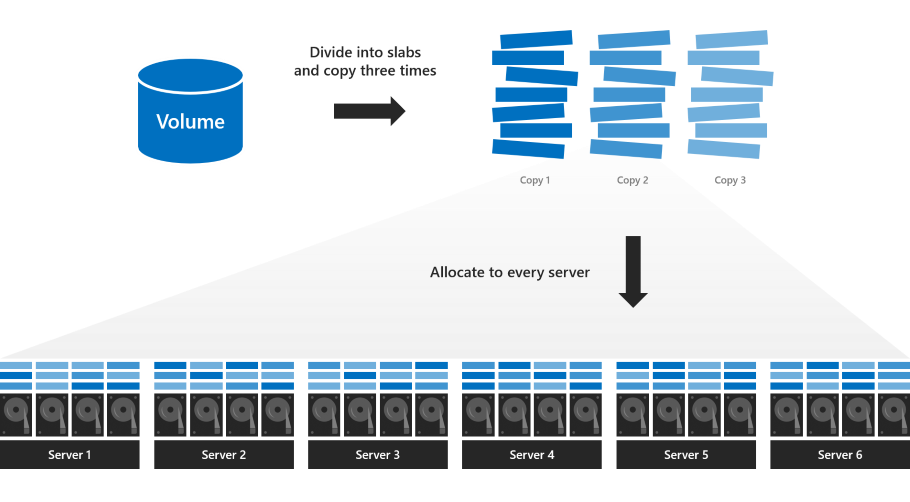
参考资源链接:[ASPEED AST2600 集成远程管理处理器数据手册](https://wenku.csdn.net/doc/7wfh6r6ujj?spm=1055.2635.3001.10343)
# 1. 高可用性概念解析
## 1.1 高可用性的定义与重要性
高可用性(High Availability,
【HP ProLiant DL388p LED灯】:硬件状态一览无余与应用(服务器健康管理的深入理解)

参考资源链接:[HP ProLiant DL388p Gen8 服务器:LED指示灯全面解读](https://wenku.csdn.net/doc/6412b6a2be7fbd1778d476d8?spm=1055.2635.3001.10343)
# 1. HP ProLiant DL388p服务器概述
在当今信息化快
【趋势分析】TI FAST观测器启动算法:行业应用趋势与未来展望

参考资源链接:[TI的InstaSPIN-FOC技术:FAST观测器与无感启动算法详解](https://wenku.csdn.net/doc/4ngc71z3y0?spm=1055.2635.3001.10343)
# 1. TI FAST观测器启动算法概述
## 算法简介及工作流程
TI FAST观测器,即Texas Instruments (TI) 的快速适应观测器算法,用于实时监测和估计系统的状态,它是
【24小时内精通DHT11】:从零基础到专家级别的快速通道
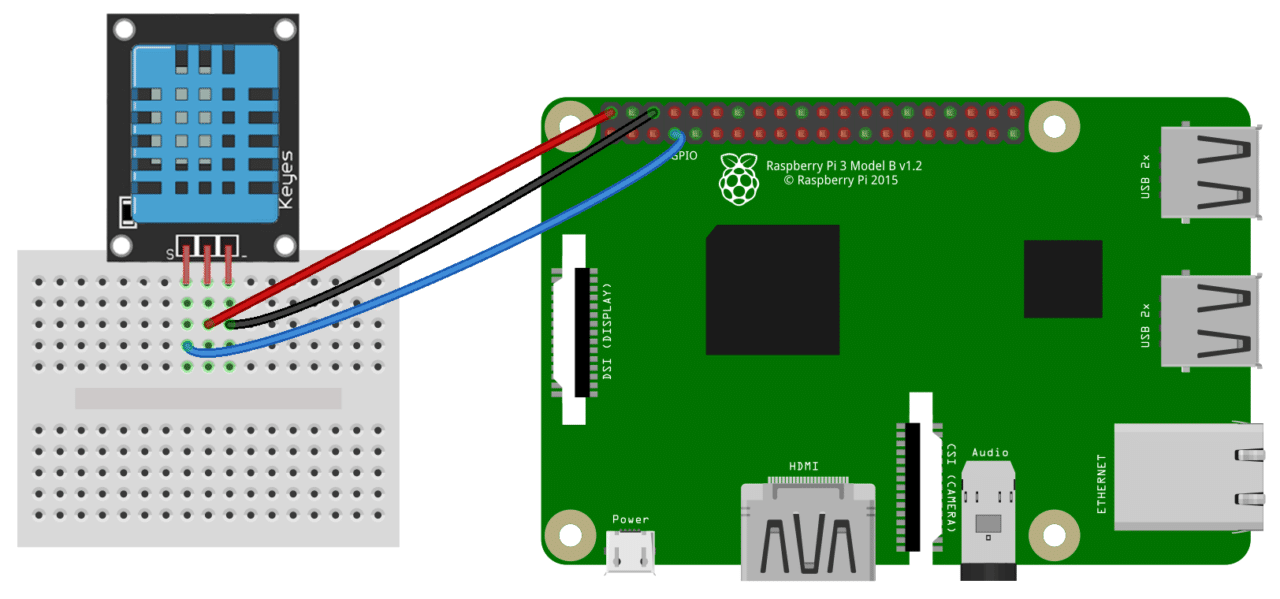
参考资源链接:[DHT11:高精度数字温湿度传感器,广泛应用于各种严苛环境](https://wenku.csdn.net/doc/645f26ae543f8444888a9f2b?spm=1055.2635.3001.10343)
# 1. DHT11传感器
【东方通TongHttpServer缓存机制详解】:提升数据处理效率的秘诀

参考资源链接:[东方通 TongHttpServer:国产化替代nginx的利器](https://wenku.csdn.net/doc/6kvz6aiyc2?spm=1055.2635.3001.10343)
# 1. 东方通TongHttpServer缓存机制概述
随着互联网技术的飞速发展,Web应用的性能优化已经成为业界重点关注的问题之一。东
【ANSYS接触问题处理】:模拟接触行为,这些技术细节帮你精准控制

参考资源链接:[ANSYS分析指南:从基础到高级](https://wenku.csdn.net/doc/6412b6c9be7fbd1778d47f8e?spm=1055.2635.3001.10343)
# 1. ANSYS接触问题概述
接触问题是结构分析中的一大挑战,特别是在机械系统、汽车、航空航天以及生物医学工程领域中,这些领域的零件经常在加载条件下发生
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )