




Cassandra数据建模:优化支付系统的性能与扩展性


02-使用Apache-Cassandra进行数据建模:02-使用Apache-Cassandra进行数据建模
摘要
本文针对Apache Cassandra的数据建模进行了深入探讨,涵盖了从基础概念到高级应用的各个方面。首先介绍了Cassandra数据模型的核心概念,包括列族与超列族的理解,以及分布式设计原则和CAP理论。接着,文章深入探讨了支付系统中数据建模的实践,包括系统需求分析、设计和性能测试。此外,本文还探讨了Cassandra数据建模的扩展性优化策略,包括扩展性设计原则、高可用性和水平扩展的数据建模。最后,文章介绍了Cassandra数据建模的高级特性应用,如集合数据类型、MapReduce、触发器、存储过程和用户定义函数,以及索引的深入运用。本文旨在为数据库开发者和架构师提供全面的Cassandra数据建模指南,以优化其在支付系统中的性能和可扩展性。
关键字
Cassandra数据建模;列族;CAP理论;扩展性优化;高可用性;水平扩展;MapReduce;用户定义函数;索引应用;支付系统
参考资源链接:电子商务安全协议详解:电子支付与标准
1. Cassandra数据建模简介
1.1 Cassandra数据建模概述
Cassandra 数据建模是一个为 Apache Cassandra 数据库优化数据结构和查询性能的过程。考虑到其分布式和无共享架构,数据建模在 Cassandra 中与传统的关系型数据库模型截然不同。理解 Cassandra 的数据模型是实现高效、可扩展应用的关键。
1.2 数据建模的重要性
在Cassandra中,数据模型对应用的读写性能和可扩展性有着决定性影响。一个合理设计的数据模型能够确保数据的快速访问,并且能随着数据量的增加而轻松扩展。由于没有固定的模式,Cassandra的灵活性要求开发者深入理解其数据模型。
1.3 数据建模的挑战
Cassandra的数据建模不同于传统关系数据库,需要考虑如何在没有固定模式的情况下表示数据。同时,要综合考虑读写操作、数据分布、以及如何通过分区键和集群策略来优化性能。因此,数据建模在Cassandra中是一项挑战性的任务,但也是实现应用性能和可维护性的关键。
通过接下来的章节,我们将进一步探讨Cassandra数据模型的基础、操作和优化策略,以帮助IT从业者更好地掌握数据建模的艺术。
2. Cassandra数据模型基础
2.1 Cassandra数据模型核心概念
2.1.1 列族与超列族的理解
Cassandra 数据库的存储模型与传统的关系型数据库有所不同。核心数据结构是列族(Column Family),它代表了一组相关的列,它们共同描述了某一种类型的实体。一个表可以有多个列族,每个列族下的列可以是动态添加的,这赋予了 Cassandra 非常高的灵活性。
在理解列族时,超列族(Super Column Family)也是一个需要掌握的概念。超列族可以被看作是列族的一个特例,其内部的列由子列(Sub-columns)组成,从而支持更深层次的数据嵌套。这对于数据模型中层次化关系较为复杂的情况非常有用。
- CREATE TABLE users (
- user_id uuid,
- name text,
- preferences map<text, text>,
- PRIMARY KEY (user_id)
- );
在上述示例中,preferences 就是一个典型的超列族的例子,它允许你存储并检索一系列键值对,其中每个键(key)都是一个字符串,每个值(value)也是一个字符串。
2.1.2 分布式设计原则与CAP理论
Cassandra 是一个分布式数据库,其设计遵循了一些关键的分布式原则,其中最重要的是 CAP 理论。CAP 理论指出,在一个分布式系统中,以下三个特性不可能同时完全满足:
- 一致性(Consistency):每次读取都会返回最新写入的数据。
- 可用性(Availability):每个请求都能得到一个响应,无论该响应是成功还是失败。
- 分区容忍性(Partition tolerance):系统即使在网络分区发生时也能继续运行。
Cassandra 选择了 AP(可用性和分区容忍性)作为主要特性,并通过最终一致性来实现。
- SELECT * FROM users WHERE user_id=123;
一个简单的查询操作,体现了 Cassandra 在可用性上的优势,即便是在网络分区发生后,查询操作仍能正常响应,返回最新的结果或错误信息。
2.2 数据建模基础操作
2.2.1 表的创建与数据类型
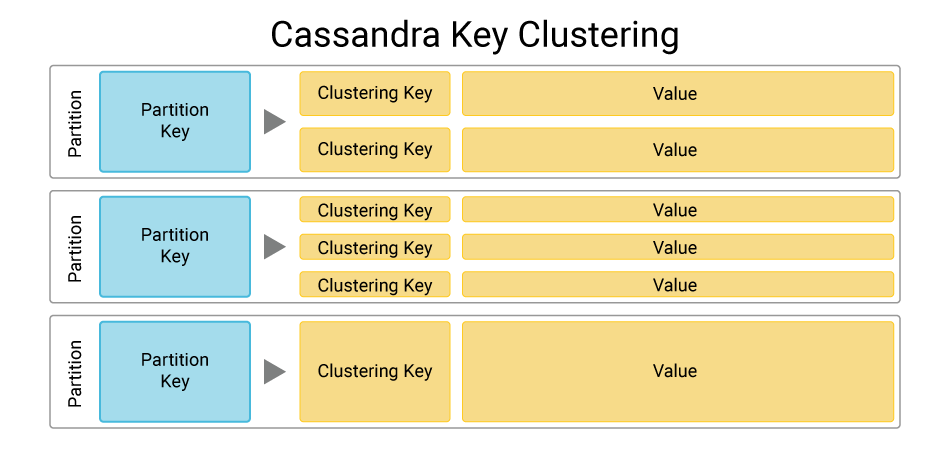
在 Cassandra 中,创建表(CREATE TABLE)是数据建模中的一项基础操作。表是按照主键(PRIMARY KEY)组织的,而主键通常包括一个分区键(Partition Key)和可选的多个集群键(Clustering Columns)。
Cassandra 支持多种数据类型,包括简单的数据类型(如 text, int, float 等),以及集合类型(如 list, set, map)和用户定义的类型(UDT)。这些数据类型为表中的每个列提供了丰富的选择。
- CREATE TABLE user_posts (
- user_id uuid,
- post_time timestamp,
- post_text text,
- likes counter,
- PRIMARY KEY ((user_id), post_time)
- ) WITH CLUSTERING ORDER BY (post_time DESC);
上述例子中的表结构展示了如何结合使用分区键和集群键来构建一个包含时间序列数据的表。
2.2.2 索引的使用与限制
索引在 Cassandra 中是一种增强查询性能的工具,它允许对表中的列或列组合进行优化的查询。然而,索引也有其限制,例如不支持二级索引(Secondary Index)上的排序和范围查询。另外,索引的创建和维护都会带来额外的写操作开销,因此在设计数据模型时需要权衡是否使用索引。
- CREATE INDEX ON user_posts (post_text);
该索引操作允许用户根据 post_text 来进行快速查询,但需要注意的是,它可能影响数据插入和更新的性能。
2.3 高效数据建模的关键因素
2.3.1 读写性能优化
在 Cassandra 中,优化读写性能是设计高效数据模型的关键。读写性能的优化可以通过调整分区键和集群键的策略来实现。例如,通过合理设计分区键,可以确保数据均匀地分布在集群的所有节点上,避免热节点问题。
集群键的选择和排序也会影响查询性能,因此需要根据查询模式来确定。例如,如果查询通常按照时间顺序进行,则应将时间戳作为集群键,并且按照时间戳降序排列。
- SELECT * FROM user_posts WHERE user_id=123 AND post_time >=

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
【精准测试】:确保分层数据流图准确性的完整测试方法
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
Cygwin系统监控指南:性能监控与资源管理的7大要点
【T-Box能源管理】:智能化节电解决方案详解


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















