Kettle ETL工具中的数据加密与安全性控制
发布时间: 2023-12-15 09:02:42 阅读量: 78 订阅数: 43 

Kettle ETL 工具
# 章节一:引言
## 1.1 介绍ETL工具在数据处理中的重要性
ETL(Extract-Transform-Load)工具在数据处理中扮演着重要的角色。它们能够从各种数据源中提取数据,并对这些数据进行清洗、转换和加载,以便用于进一步分析和应用。ETL工具的主要目标是高效、准确地将数据从源系统移动到目标系统,并对数据进行必要的加工和处理。这些工具不仅可以提高数据处理的效率和准确性,还可以帮助企业更好地理解和利用数据,从而支持决策和业务发展。
ETL工具的重要性表现在以下几个方面:
1. 数据集成和整合:ETL工具能够从多个数据源中提取数据,并将其合并成为一个完整的数据集。这些数据源可能包括关系型数据库、文件系统、Web服务等。通过数据集成和整合,企业可以获得全面、一致的数据视图,从而支持更好的业务分析和决策。
2. 数据清洗和转换:数据源的数据往往包含了各种不一致和错误,例如重复数据、缺失数据、格式不规范等。ETL工具能够自动化地对这些数据进行清洗和转换,使其符合目标系统的要求和规范。通过数据清洗和转换,企业可以获得高质量、可靠的数据,提升数据分析和决策的准确性。
3. 数据加载和传输:ETL工具能够将经过清洗和转换的数据加载到目标系统中,以供后续的分析和应用。数据加载和传输过程需要考虑数据的安全性、完整性和及时性,ETL工具能够提供相应的机制和控制来保障数据的可靠性和准确性。
## 1.2 概述数据加密和安全性控制在数据处理中的作用和必要性
在数据处理过程中,数据的安全性和保密性是至关重要的。企业拥有大量的敏感数据,如客户信息、财务数据、商业机密等,这些数据如果遭到泄露或滥用,将产生严重的后果,可能导致金融损失、声誉受损甚至法律纠纷。因此,数据加密和安全性控制成为数据处理中不可或缺的环节。
数据加密是一种常用的数据安全技术。它通过将明文数据转换为密文数据,以防止未经授权的访问和使用。数据加密可以保护数据在传输和存储过程中的安全性,即使数据被盗取或篡改,也能保证数据的机密性和完整性。
安全性控制是指在数据处理过程中对数据进行合理的访问控制和权限管理。通过安全性控制,企业可以限制用户对数据的访问权限,确保只有授权的用户才能访问和操作数据。同时,安全性控制还可以监控和记录用户对数据的操作,以便及时检测和应对潜在的安全威胁。
## Chapter 2: Kettle ETL Tool Introduction
Kettle ETL (Extract, Transform, Load) is a powerful open source software tool used for data integration, migration, and transformation. Developed by Pentaho Corporation, Kettle (also known as Pentaho Data Integration) provides a comprehensive set of features and functionalities that make it a popular choice among data professionals and developers.
### 2.1 Overview of Kettle ETL Tool
Kettle ETL tool offers a wide range of capabilities that enable efficient and streamlined data processing. Its primary functions include:
1. **Extraction**: Kettle allows data extraction from various sources such as databases, flat files, XML files, web services, and more. It supports a wide range of data formats and provides connectivity options to extract data from structured and unstructured sources.
2. **Transformation**: Kettle provides a graphical interface to design data transformations, which involve data cleansing, aggregation, filtering, joining, and other operations. It offers a rich library of transformation steps that can be easily configured to process data as required.
3. **Loading**: Kettle supports data loading to multiple targets, including databases, data warehouses, cloud platforms, and file systems. It offers efficient methods for loading large volumes of data with options for batch processing, parallel execution, and error handling.
### 2.2 Application Areas and Advantages of Kettle ETL Tool
Kettle ETL tool finds extensive usage in various data integration scenarios and offers several advantages:
1. **Data Warehousing**: Kettle is commonly used in building and maintaining data warehouses by extracting data from diverse sources, transforming it, and loading it into a structured format suitable for analysis.
2. **Business Intelligence**: Kettle supports the integration of data from different systems and provides the necessary transformations to prepare data for business intelligence and reporting applications.
3. **Data Migration**: Kettle facilitates smooth migration of data between various systems, platforms, or databases with its flexible and scalable architecture.
4. **Process Automation

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏旨在深入介绍和讲解Kettle ETL工具的各个方面,从使用入门到高级技术操作,从数据提取和转换到加载和配置,包括数据清洗、预处理、转换操作的深入解析以及流程控制和条件判断等。同时也介绍了数据集成和多源数据处理的方法和技巧,以及数据的加密和安全性控制。此外,该专栏还包括了数据校验和修正、数据合并与重复记录处理、日期时间处理与格式转换、数据聚合和分组计算、数据分片和分流处理、数据合并与拆分操作、数据缓存与性能优化、数据异常检测和处理、数据编码和解码、数据排序和分页处理、数据备份和恢复策略等内容。通过阅读本专栏,读者可以全面了解和掌握Kettle ETL工具的各种功能和应用,提升数据处理和管理的能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
3D Slicer 快速上手秘籍:掌握界面布局与基础工具的终极指南
# 摘要
本文全面介绍了3D Slicer这一功能强大的医学影像处理软件,从界面布局与导航到基础工具的使用技巧,再到高级功能的深入解析。文章首先概述了3D Slicer的基本功能和用户界面,接着深入讲解了基础工具如图像处理、三维重建以及注释和测量的使用方法。在高级功能部分,本文解析了分割、配准、手术规划和自动化脚本接口。此外,还探讨了3D S
【频率响应测量技巧】:快速提升安捷伦4395A使用效率的5大技巧!

# 摘要
频率响应测量是电子工程领域中的关键技能,涉及到从基础测量到高级技术的多个层面。本文首先介绍了频率响应测量的基础知识,随后深入探讨了安捷伦4395A仪器的设置和使用,包括其功能介绍、仪器配置、校准和基准设置。第三章重点讲解了测量过程中的技巧与实践,如提升测量精度和数据分析方法。第四章介绍了高级频率响应测量技术,包括自动化测试流
【应用洛必达法则解决并发问题】:优化并发算法,效率倍增
# 摘要
本论文深入探讨了并发编程的基础概念、挑战以及洛必达法则在并发控制中的应用。首先,我们回顾了并发编程的基本理论和洛必达法则的数学原理,并分析了该法则在解决并发控制问题中的潜在优势和实际限制。接着,通过具体案例和算法实例,展示了洛必达法则在提升并发算法性能方面的实际应用和优化效果。文章进一步探讨了洛必达法则在分布式系统中的扩展应用,并与其他并发控制方法进行了比较分析。最后,展望了并发控制技术和洛必达法则研究的未来趋势,并提出了对开发者和行业的建议。本文旨在为并发优化领域提供新的视角和工具,为解决并发编程中的性能瓶颈和理论局限提供参考。
# 关键字
并发编程;洛必达法则;理论解读;算法优
SEE软件V8R2实战教程:零基础快速入门与问题速解
# 摘要
本文对SEE软件V8R2版本进行了全面介绍,涵盖了软件的概览与安装、基础操作、进阶技巧以及常见问题解决策略。首先介绍了软件的基本界面布局和配置选项,然后讲解了数据管理、视图和报表的设计与应用。接着,文章深入探讨了高级查询、数据分析、安全性和权限管理,以及定制化开发的可能性。此外,本文还提供了常见运行问题的诊断方法、功能
TEF668XA系统监控:实时性能分析与故障预警
# 摘要
本文介绍了TEF668XA系统的监控机制,并从理论和实践两个维度对其进行全面分析。首先,概述了TEF668XA系统监控的基础理论,包括系统架构分析、实时性能分析原理以及故障预警机制的理论基础。随后,详细探讨了在实际应用中如何部署监控工具、设计预警规则,并对性能优化与故障排除进行了案例分析。
ERP集成新视角:基于ISO 19453-1的最佳实践案例分析
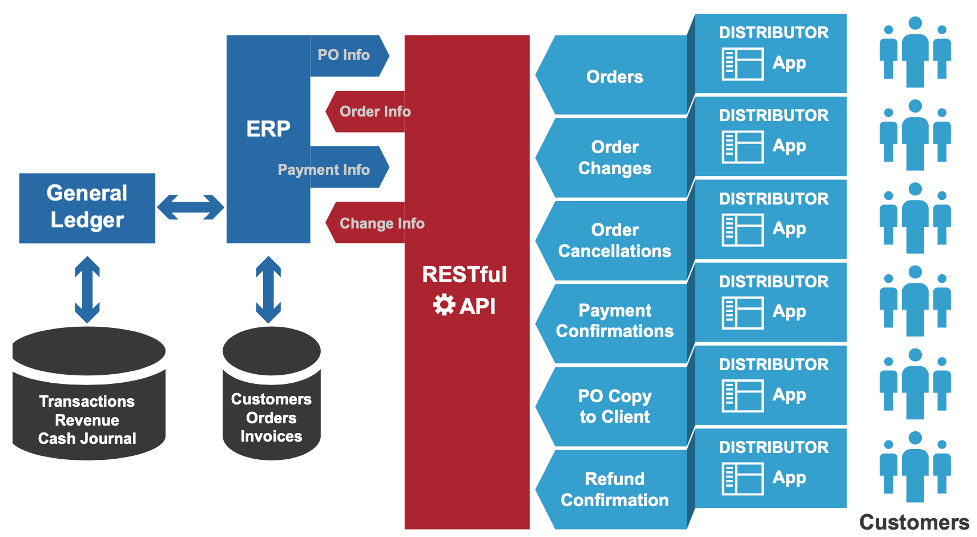
# 摘要
本文全面探讨了ERP集成与ISO 19453-1标准的应用,从理论基础到最佳实践案例,再到实践中遇到的挑战和解决方案。文章详细介绍了ERP系统的核心模块及其集成必要性,阐述了ISO 19453-1标准的框架与关键要求,并对集成策略和方法论进行了深入分析。案例研究部分展示了ERP集成在供应链管理、客户关系管理及财务流程自动化中的实
数据结构精通之道:深度剖析树形结构与图算法

# 摘要
树形结构与图算法是数据结构与算法领域的核心内容,对计算机科学中的多种应用具有重要意义。本文首先概述了树形结构与图算法的基本理论和实践应用,接着深入探讨了树形结构和图论的基础知识、经典算法及其实
跨平台EDEM-Fluent耦合开发:环境配置与调试策略完整指南
# 摘要
跨平台EDEM-Fluent耦合开发涉及将离散元方法(EDEM)和计算流体动力学(Fluent)软件整合,以进行复杂的多物理场分析和仿真。本文首先概述了EDEM-Fluent耦合开发的基本概念,随后详细介绍了软件环境的配置方法,包括系统要求、安装步骤、参数设置与优化以及耦合接口的配置。接着,文章探讨了耦合开发的调试策略,包括调试前的准备工作、调试技巧、性能调优策略。在实践应用方面,通过工程案例分析和代码优化,演示了耦合开发在解决实际问题中的应用。最后,文章展望了未来跨平台EDEM-Fluent耦合开发的趋势,包括软件新版本功能和社区资源分享的未来发展方向。
# 关键字
EDEM-F
JDK 1.8性能优化:掌握这5个实用技巧,立即提升Linux服务器性能
# 摘要
本文针对JDK 1.8版本的Java性能优化进行了全面的探讨,重点关注JVM内存管理、Java代码层面、以及Linux服务器环境下的JVM性能监控与调整。从内存管理优化到代码层面的性能坑、集合和并发处理,再到JMX工具的使用和系统级参数调优,本文详细论述了各种优化技术和策略。特别指出,JDK 1.8引入的新特性和API,例如Lambda表达式、Stream
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )