【MySQL数据库性能提升秘籍】:揭秘性能下降幕后真凶及解决策略
发布时间: 2024-07-02 17:09:46 阅读量: 57 订阅数: 26 

(179979052)基于MATLAB车牌识别系统【带界面GUI】.zip

# 1. MySQL数据库性能下降的根源**
MySQL数据库性能下降的原因多种多样,主要可以归纳为以下几个方面:
- **数据量增长:**随着数据量的不断增加,数据库的查询和更新操作都会变得更加耗时。
- **索引不合理:**索引是提高查询效率的关键,但如果索引设计不合理,反而会降低性能。
- **查询不优化:**复杂的查询语句、不必要的连接和子查询都会导致查询时间过长。
- **架构不合理:**单一的数据库架构无法满足高并发、高负载的场景,需要考虑分库分表、读写分离等优化方案。
- **硬件瓶颈:**CPU、内存、存储等硬件资源不足,也会导致数据库性能下降。
# 2. MySQL数据库性能优化实践
### 2.1 索引优化
索引是加快查询速度的重要工具。合理使用索引可以大大提高查询效率。
#### 2.1.1 创建合理索引
在创建索引时,需要考虑以下原则:
- **选择合适的数据类型:**索引列应选择合适的数据类型,如整数、字符串或日期。
- **选择唯一值或低基数列:**索引列应选择唯一值或低基数列,以避免索引膨胀和查询效率降低。
- **创建复合索引:**对于经常一起查询的列,可以创建复合索引,以提高查询速度。
- **避免创建冗余索引:**如果已存在覆盖查询的索引,则无需创建其他索引。
#### 2.1.2 删除冗余索引
冗余索引会增加数据库的存储空间和维护开销,还会降低查询效率。因此,需要定期检查并删除冗余索引。
### 2.2 查询优化
查询优化是提高数据库性能的另一重要方面。通过优化查询语句,可以减少查询时间和资源消耗。
#### 2.2.1 分析慢查询日志
慢查询日志记录了执行时间超过指定阈值的查询。分析慢查询日志可以帮助识别需要优化的查询。
#### 2.2.2 使用EXPLAIN命令
EXPLAIN命令可以显示查询执行计划,包括查询使用的索引、连接类型和执行时间。通过分析EXPLAIN输出,可以了解查询的执行过程并发现优化点。
#### 2.2.3 优化查询语句
优化查询语句可以从以下几个方面入手:
- **使用适当的连接类型:**根据查询条件选择合适的连接类型,如INNER JOIN、LEFT JOIN或RIGHT JOIN。
- **避免使用子查询:**子查询会降低查询效率,应尽可能将其转换为JOIN语句。
- **使用索引:**确保查询语句使用了合适的索引。
- **减少不必要的列:**只选择查询所需的列,避免返回不必要的列。
### 2.3 架构优化
数据库架构设计对性能也有很大影响。合理的设计可以提高查询效率和可扩展性。
#### 2.3.1 数据库分库分表
当数据量过大时,可以将数据库拆分为多个分库分表,以减轻单库的压力和提高查询效率。
#### 2.3.2 读写分离
读写分离是指将数据库分为读库和写库,读库负责处理查询请求,写库负责处理更新请求。这样可以避免读写冲突,提高查询效率。
# 3. MySQL数据库性能监控
### 3.1 性能指标监控
数据库性能监控是确保MySQL数据库稳定运行的关键环节。通过监控关键性能指标,可以及时发现性能瓶颈,并采取相应的优化措施。常见的性能指标包括:
**3.1.1 CPU和内存使用率**
CPU和内存使用率反映了数据库服务器的资源消耗情况。高CPU使用率可能表明数据库正在处理大量查询或后台任务。高内存使用率则可能表明存在内存泄漏或缓冲池大小设置不当。
**监控方法:**
- 使用 `top` 或 `ps` 命令查看CPU使用率。
- 使用 `free` 或 `vmstat` 命令查看内存使用率。
**3.1.2 查询响应时间**
查询响应时间衡量数据库处理查询的速度。慢查询会影响用户体验并降低数据库的整体性能。
**监控方法:**
- 使用 `EXPLAIN` 命令分析查询语句的执行计划,并找出慢查询。
- 使用 `pt-query-digest` 等工具记录和分析慢查询日志。
**3.1.3 连接数**
连接数反映了同时连接到数据库服务器的客户端数量。过多的连接数可能导致资源争用和性能下降。
**监控方法:**
- 使用 `SHOW PROCESSLIST` 命令查看当前连接数。
- 使用 `netstat` 或 `ss` 命令查看网络连接数。
### 3.2 慢查询日志分析
慢查询日志记录了执行时间超过指定阈值的查询语句。分析慢查询日志可以帮助找出性能瓶颈并优化查询语句。
**3.2.1 慢查询日志的配置**
在MySQL配置文件中启用慢查询日志:
```
slow_query_log=1
slow_query_log_file=/var/log/mysql/slow.log
long_query_time=1
```
**3.2.2 慢查询日志的分析工具**
使用以下工具分析慢查询日志:
- `pt-query-digest`:强大的慢查询分析工具,可以聚合和分析慢查询日志。
- `mysqltuner`:全面的数据库性能分析工具,包括慢查询分析功能。
- `mysqldumpslow`:命令行工具,用于分析和格式化慢查询日志。
# 4. MySQL数据库性能调优
### 4.1 参数调优
#### 4.1.1 缓冲池大小优化
**参数名称:** innodb_buffer_pool_size
**参数说明:** 设置 InnoDB 缓冲池的大小,用于缓存经常访问的数据页。
**优化方式:**
1. **确定当前缓冲池大小:** 使用以下命令查看当前缓冲池大小:
```
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
```
2. **评估缓冲池命中率:** 使用以下命令查看缓冲池命中率:
```
SHOW INNODB STATUS\G
```
在输出中找到 "Buffer pool hit rate" 行,该值表示缓冲池命中率。
3. **调整缓冲池大小:** 如果缓冲池命中率较低(低于 90%),则可以增加缓冲池大小。如果缓冲池命中率较高(高于 95%),则可以减少缓冲池大小。
**示例代码:**
```
SET GLOBAL innodb_buffer_pool_size = 128M;
```
**逻辑分析:**
此代码将 InnoDB 缓冲池大小设置为 128MB。
#### 4.1.2 连接池大小优化
**参数名称:** max_connections
**参数说明:** 设置 MySQL 服务器可以同时处理的最大连接数。
**优化方式:**
1. **确定当前连接池大小:** 使用以下命令查看当前连接池大小:
```
SHOW VARIABLES LIKE 'max_connections';
```
2. **评估连接数:** 使用以下命令查看当前连接数:
```
SHOW PROCESSLIST;
```
3. **调整连接池大小:** 如果当前连接数经常接近或超过连接池大小,则可以增加连接池大小。如果当前连接数远低于连接池大小,则可以减少连接池大小。
**示例代码:**
```
SET GLOBAL max_connections = 200;
```
**逻辑分析:**
此代码将 MySQL 服务器的最大连接数设置为 200。
### 4.2 硬件调优
#### 4.2.1 CPU和内存升级
**优化方式:**
1. **增加 CPU 核心数:** 更多 CPU 核心可以并行处理更多查询,从而提高性能。
2. **增加内存容量:** 更多的内存可以容纳更大的缓冲池和连接池,从而减少磁盘 I/O 操作并提高性能。
**示例代码:**
```
// 升级 CPU 核心数
sudo lscpu | grep "CPU(s):"
sudo taskset -p 0-3 <command>
// 升级内存容量
sudo free -m
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get install linux-headers-$(uname -r)
sudo apt-get install linux-image-$(uname -r)
```
**逻辑分析:**
此代码示例演示了如何升级 CPU 核心数和内存容量。
#### 4.2.2 存储设备优化
**优化方式:**
1. **使用 SSD 硬盘:** SSD 硬盘比传统硬盘速度更快,可以显著提高数据库性能。
2. **创建 RAID 阵列:** RAID 阵列可以提高磁盘 I/O 性能和数据可靠性。
**示例代码:**
```
// 创建 RAID 阵列
sudo mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sd[a-b]
// 查看 RAID 阵列状态
sudo cat /proc/mdstat
```
**逻辑分析:**
此代码示例演示了如何创建 RAID 1 阵列。
# 5.1 备份和恢复
### 5.1.1 备份策略
**全量备份**
全量备份是将数据库中所有数据全部备份到一个文件中。优点是恢复速度快,缺点是备份时间长,占用存储空间大。
```
mysqldump -u root -p --all-databases > all_databases.sql
```
**增量备份**
增量备份是只备份上次备份后发生变化的数据。优点是备份时间短,占用存储空间小,缺点是恢复速度慢。
```
mysqldump -u root -p --incremental --master-data=2 > incremental_backup.sql
```
**二进制日志备份**
二进制日志备份是记录数据库中所有修改操作的日志文件。优点是恢复速度快,缺点是需要额外的存储空间。
```
mysqlbinlog -u root -p mysql-bin.000001 > binary_log_backup.sql
```
### 5.1.2 恢复操作
**全量恢复**
全量恢复是从全量备份文件中恢复数据库。
```
mysql -u root -p < all_databases.sql
```
**增量恢复**
增量恢复是从增量备份文件中恢复数据库。
```
mysql -u root -p < incremental_backup.sql
```
**二进制日志恢复**
二进制日志恢复是从二进制日志备份文件中恢复数据库。
```
mysqlbinlog -u root -p binary_log_backup.sql | mysql -u root -p
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
"创驰蓝天"专栏致力于提升数据库、缓存、搜索引擎、消息队列、容器技术、云计算、微服务、人工智能等技术领域的知识和技能。通过深入浅出的文章,专栏揭秘了数据库性能下降、死锁问题、索引失效等常见问题的幕后真凶和解决策略。同时,还提供了MySQL数据库优化器、事务隔离级别、高可用架构、监控与告警、运维最佳实践等方面的实战指南。此外,专栏还涵盖了Redis、MongoDB、Elasticsearch、Kafka、Kubernetes、Docker、DevOps等热门技术的原理与应用。通过阅读本专栏,读者可以全面掌握这些技术的核心概念、最佳实践和实战经验,从而提升系统性能、稳定性和开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【材料选择专家指南】:如何用最低成本升级漫步者R1000TC北美版音箱
# 摘要
本文旨在深入探讨漫步者R1000TC北美版音箱的升级理论与实践操作指南。首先分析了音箱升级的重要性、音质构成要素,以及如何评估升级对音质的影响。接着介绍了音箱组件工作原理,特别是扬声器单元和分频器的作用及其选择原则。第三章着重于实践操作,提供扬声器单元、分频器和线材的升级步骤与技巧。第四章讨论了升级效果的评估方法,包括使用音频测试软件和主观听感分析。最后,第五章探讨了进阶升级方案,如音频接口和蓝牙模块的扩展,以及个性化定制声音风格的策略。通过本文,读者可以全面了解音箱升级的理论基础、操作技巧以及如何实现个性化的声音定制。
# 关键字
音箱升级;音质提升;扬声器单元;分频器;调音技巧
【PyQt5控件进阶】:日期选择器、列表框和文本编辑器深入使用

# 摘要
PyQt5是一个功能强大的跨平台GUI框架,它提供了丰富的控件用于构建复杂的应用程序。本文从PyQt5的基础回顾和控件概述开始,逐步深入探讨了日期选择器、列表框和文本编辑器等控件的高级应用和技巧。通过对控件属性、方法和信号与槽机制的详细分析,结合具体的实践项目,本文展示了如何实现复杂日期逻辑、动态列表数据管理和高级文本编辑功能。此外,本文还探讨了控件的高级布局和样式设计
MAXHUB后台管理新手速成:界面概览至高级功能,全方位操作教程

# 摘要
MAXHUB后台管理平台作为企业级管理解决方案,为用户提供了一个集成的环境,涵盖了用户界面布局、操作概览、核心管理功能、数据分析与报告,以及高级功能的深度应用。本论文详细介绍了平台的登录、账号管理、系统界面布局和常用工具。进一步探讨了用户与权限管理、内容管理与发布、设备管理与监控的核心功能,以及如何通过数据分析和报告制作提供决策支持。最后,论述了平台的高
深入解析MapSource地图数据管理:存储与检索优化之法
# 摘要
本文对MapSource地图数据管理系统进行了全面的分析与探讨,涵盖了数据存储机制、高效检索技术、数据压缩与缓存策略,以及系统架构设计和安全性考量。通过对地图数据存储原理、格式解析、存储介质选择以及检索算法的比较和优化,本文揭示了提升地图数据管理效率和检索性能的关键技术。同时,文章深入探讨了地图数据压缩与缓存对系统性能的正面影响,以及系统架构在确保数据一致性
【结果与讨论的正确打开方式】:展示发现并分析意义

# 摘要
本文深入探讨了撰写研究论文时结果与讨论的重要性,分析了不同结果呈现技巧对于理解数据和传达研究发现的作用。通过对结果的可视化表达、比较分析以及逻辑结构的组织,本文强调了清晰呈现数据和结论的方法。在讨论部分,提出了如何有效地将讨论与结果相结合、如何拓宽讨论的深度与广度以及如何提炼创新点。文章还对分析方法的科学性、结果分析的深入挖掘以及案例分析的启示进行了评价和解读。最后
药店管理系统全攻略:UML设计到实现的秘籍(含15个实用案例分析)
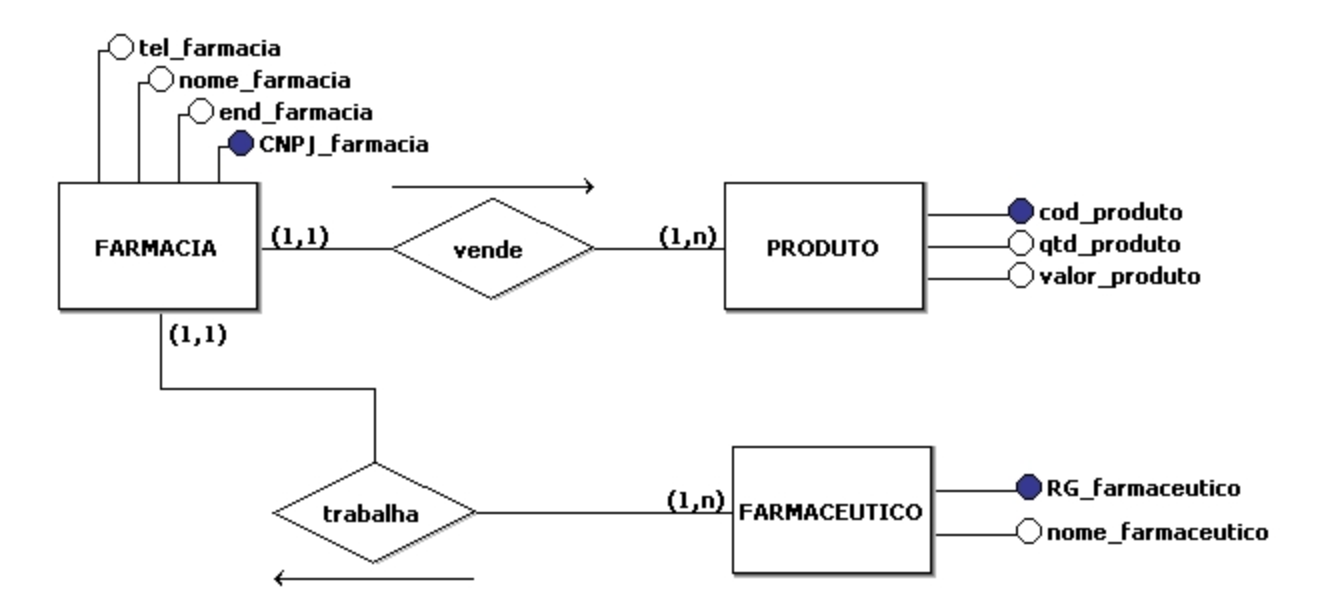
# 摘要
本论文首先概述了药店管理系统的基本结构和功能,接着介绍了UML理论在系统设计中的应用,详细阐述了用例图、类图的设计原则与实践。文章第三章转向系统的开发与实现,涉及开发环境选择、数据库设计、核心功能编码以及系统集成与测试。第四章通过实践案例深入探讨了UML在药店管理系统中的应用,包括序列图、活动图、状态图及组件图的绘制和案例分析。最后,论文对药店管理系统的优化与维护进行了讨论,提
【555定时器全解析】:掌握方波发生器搭建的五大秘籍与实战技巧
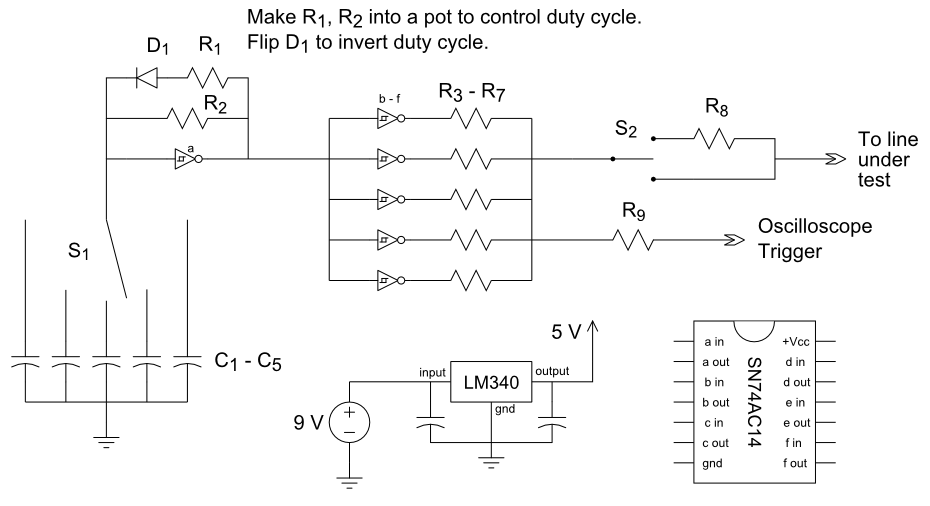
# 摘要
本文详细介绍了555定时器的工作原理、关键参数、电路搭建基础及其在方波发生器、实战应用案例以及高级应用中的具体运用。首先,概述了555定时器的基本功能和工作模式,然后深入探讨了其在方波发生器设计中的应用,包括频率和占空比的控制,以及实际实验技巧。接着,通过多个实战案例,如简易报警器和脉冲发生器的制作,展示了555定时器在日常项目中的多样化运用。最后,分析了555定时器的多用途扩展应用,探讨了其替代技术,
【Allegro Gerber导出深度优化技巧】:提升设计效率与质量的秘诀

# 摘要
本文全面介绍了Allegro Gerber导出技术,阐述了Gerber格式的基础理论,如其历史演化、
Profinet通讯优化:7大策略快速提升1500编码器响应速度
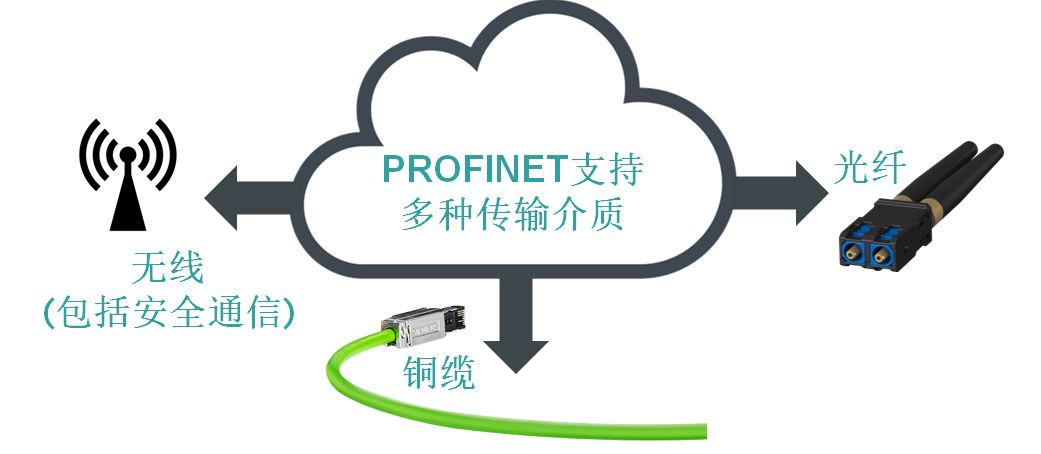
# 摘要
Profinet作为一种工业以太网通讯技术,其通讯性能和编码器的响应速度对工业自动化系统至关重要。本文首先概述了Profinet通讯与编码器响应速度的基础知识,随后深入分析了影响Profinet通讯性能的关键因素,包括网络结构、数据交换模式及编码器配置。通过优化网络和编码器配置,本文提出了一系列提升Profinet通讯性能的实践策略。进一步,本文探讨了利用实时性能监控、网络通讯协议优化以及预
【时间戳转换秘籍】:将S5Time转换为整数的高效算法与陷阱分析

# 摘要
时间戳转换在计算机科学与信息技术领域扮演着重要角色,它涉及到日志分析、系统监控以及跨系统时间同步等多个方面。本文首先介绍了时间戳转换的基本概念和重要性,随后深入探讨了S5Time与整数时间戳的理论基础,包括它们的格式解析、定义以及时间单位对转换算法的影响。本文重点分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )