深入理解Python HTTPServer模块:工作原理与实践技巧
发布时间: 2024-10-14 13:18:55 阅读量: 43 订阅数: 30 

HTTP Server
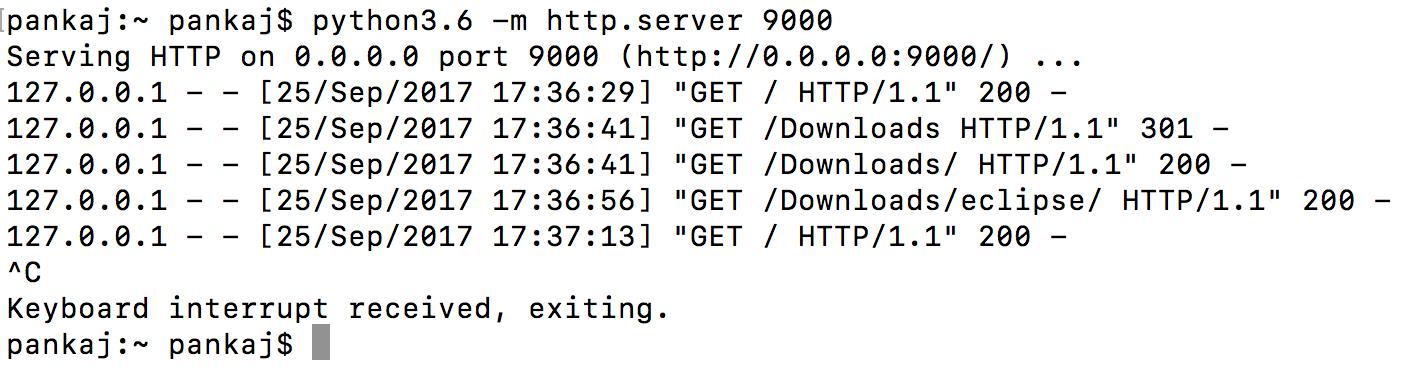
# 1. Python HTTPServer模块概述
## 1.1 HTTPServer模块简介
Python的`http.server`模块提供了一个简单的HTTP服务器实现,它适用于学习、测试和快速原型开发。这个模块能够让你在几分钟内创建一个基本的Web服务器,无需依赖第三方库。
## 1.2 模块的组成
该模块包含两个主要的类:`HTTPServer`和`BaseHTTPRequestHandler`。`HTTPServer`类负责监听端口并接受客户端请求,而`BaseHTTPRequestHandler`类用于处理请求和生成响应。
## 1.3 基本用法示例
下面是一个简单的HTTP服务器示例代码:
```python
from http.server import HTTPServer, BaseHTTPRequestHandler
class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b'Hello, World!')
if __name__ == '__main__':
server_address = ('', 8000)
httpd = HTTPServer(server_address, SimpleHTTPRequestHandler)
print("Server running on port 8000...")
httpd.serve_forever()
```
运行上述代码将启动一个监听在8000端口的HTTP服务器,当你访问`***`时,它将响应一个简单的文本消息“Hello, World!”。
# 2. HTTPServer模块的工作原理
## 2.1 HTTP协议基础
### 2.1.1 请求/响应模型
在深入了解Python的HTTPServer模块之前,我们首先需要理解HTTP协议的基础知识。HTTP协议,即超文本传输协议(Hypertext Transfer Protocol),是互联网上应用最为广泛的一种网络协议。它定义了客户端和服务器之间交互的消息格式,以及客户端和服务器如何进行交互。
HTTP协议采用的是请求/响应模型。在这种模型中,客户端(通常是Web浏览器)向服务器发送一个HTTP请求消息,服务器接收到请求后,处理并返回一个HTTP响应消息。这个响应通常包含了请求的数据或错误信息。请求和响应都包含了一系列的头部信息,这些头部信息描述了消息的内容类型、长度、编码方式等信息。
下面是一个简单的HTTP请求和响应的例子:
```http
GET /index.html HTTP/1.1
Host: ***
User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:76.0) Gecko/*** Firefox/76.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
```
```http
HTTP/1.1 200 OK
Date: Mon, 23 May 2022 09:52:17 GMT
Server: Apache/2.4.1 (Unix)
Last-Modified: Sat, 29 Jan 2022 16:45:20 GMT
ETag: "123456-123456-123456"
Content-Type: text/html
Content-Length: 12345
Connection: close
<html>
<head>
<title>***!</title>
</head>
<body>
<h1>Hello, World!</h1>
</body>
</html>
```
在这个例子中,客户端发送了一个GET请求,请求`***`网站的`index.html`页面。服务器接收到请求后,返回了一个HTTP状态码为200的响应,表示请求成功,并返回了请求的HTML内容。
### 2.1.2 HTTP方法和状态码
HTTP协议定义了一系列的方法来表示客户端的意图,这些方法通常被称为HTTP动词。最常用的方法包括:
- `GET`:请求服务器发送特定资源。
- `POST`:向服务器提交数据,通常用于表单提交。
- `PUT`:请求服务器存储或更新资源。
- `DELETE`:请求服务器删除资源。
服务器在响应中返回一个状态码,表明请求的结果。一些常见的状态码包括:
- `200 OK`:请求成功。
- `404 Not Found`:请求的资源不存在。
- `500 Internal Server Error`:服务器内部错误。
理解这些基本的HTTP方法和状态码对于使用HTTPServer模块至关重要,因为它们是构建Web应用的基础。
## 2.2 Python HTTPServer的工作机制
### 2.2.1 请求处理流程
Python的HTTPServer模块是一个简单的HTTP服务器实现,它能够处理客户端的请求并返回响应。服务器的工作流程大致如下:
1. 监听指定的端口。
2. 接收客户端请求。
3. 解析HTTP请求消息。
4. 根据请求的路径查找对应的处理程序。
5. 调用处理程序,生成HTTP响应消息。
6. 发送HTTP响应消息给客户端。
在这个过程中,服务器可以处理静态文件服务、CGI脚本执行等多种类型的请求。
### 2.2.2 多线程和多进程支持
HTTPServer模块提供了多线程和多进程的支持,这使得服务器能够同时处理多个客户端的请求。多线程模型适用于I/O密集型任务,因为它可以让CPU在等待网络I/O操作时处理其他线程的任务。多进程模型则适用于CPU密集型任务,因为每个进程都有自己的内存空间,不会因为某个进程的计算密集型任务而阻塞其他进程。
服务器默认使用多线程模型,但也可以配置为多进程模型。多进程模型可以通过设置`ThreadingMixIn`或`ForkingMixIn`来实现。选择哪种模型取决于服务器的负载特点和应用需求。
```python
from http.server import HTTPServer, BaseHTTPRequestHandler
from socketserver import ThreadingMixIn
class ThreadedHTTPServer(ThreadingMixIn, HTTPServer):
"""Handle requests in a separate thread."""
# 使用多线程HTTP服务器
server = ThreadedHTTPServer(('localhost', 8000), BaseHTTPRequestHandler)
server.serve_forever()
```
在这个例子中,我们通过继承`ThreadingMixIn`和`HTTPServer`类来创建一个多线程的HTTP服务器。
## 2.3 自定义HTTPServer
### 2.3.1 继承HTTPServer类
为了实现自定义的HTTP服务器,我们可以通过继承`HTTPServer`类来创建一个服务器实例,并且在子类中重写`handle_request`或`handle_request_default`方法来自定义请求处理逻辑。
```python
from http.server import HTTPServer, BaseHTTPRequestHandler
class CustomHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
self.wfile.write(b'Hello, world!')
class CustomHTTPServer(HTTPServer):
pass
server = CustomHTTPServer(('localhost', 8000), CustomHTTPRequestHandler)
server.serve_forever()
```
在这个例子中,我们创建了一个自定义的`CustomHTTPRequestHandler`类,它继承自`BaseHTTPRequestHandler`。我们在`do_GET`方法中重写了处理GET请求的逻辑,并且返回了一个简单的响应。
### 2.3.2 覆盖默认行为
除了重写请求处理方法外,我们还可以通过覆盖其他`BaseHTTPRequestHandler`类中的方法来自定义服务器的行为,例如自定义日志记录、错误处理等。例如,我们可以覆盖`log_message`方法来自定义日志记录的行为。
```python
class CustomHTTPRequestHandler(BaseHTTPRequestHandler):
def log_message(self, format, *args):
# 自定义日志记录
print(f"{self.address_string()} - [{self.log_date_time_string()}] {format % args}")
server = CustomHTTPServer(('localhost', 8000), CustomHTTPRequestHandler)
server.serve_forever()
```
在这个例子中,我们覆盖了`log_message`方法,将其替换为自定义的日志记录函数。
通过这些自定义操作,我们可以根据自己的需求构建一个更加灵活和强大的HTTP服务器。在下一章节中,我们将详细介绍如何使用HTTPServer模块处理静态文件服务,以及如何构建动态内容。
# 3. HTTPServer模块的实践技巧
在本章节中,我们将深入探讨Python HTTPServer模块的实际应用技巧,包括处理静态文件服务、构建动态内容、错误处理和日志记录。这些技巧将帮助你更好地理解和使用HTTPServer模块,以构建高效、可靠的网络服务。
## 3.1 处理静态文件服务
### 3.1.1 配置静态文件路径
静态文件服务是HTTPServer模块最基本的功能之一。要配置静态文件路径,你需要使用`http.server`模块中的`SimpleHTTPRequestHandler`类。以下是一个简单的示例代码,展示了如何设置HTTPServer来服务当前目录下的静态文件:
```python
from http.server import HTTPServer, SimpleHTTPRequestHandler
class CustomHTTPRequestHandler(SimpleHTTPRequestHandler):
# 可以在这里覆盖SimpleHTTPRequestHandler的默认行为
# 设置服务器的主机和端口
server_address = ('', 8000)
# 创建HTTPServer实例
httpd = HTTPServer(server_address, CustomHTTPRequestHandler)
# 启动服务器
httpd.serve_forever()
```
在这个例子中,`CustomHTTPRequestHandler`类继承自`SimpleHTTPRequestHandler`,你可以在这个类中覆写默认行为来改变静态文件服务的行为。
### 3.1.2 静态资源优化
为了提高静态资源的服务性能,你可以采取以下优化措施:
1. **压缩资源**:使用工具如`gzip`压缩静态文件,减少传输数据量。
2. **缓存控制**:通过设置HTTP头部来控制客户端缓存,减少不必要的资源下载。
3. **合并文件**:将多个CSS或JavaScript文件合并为一个文件,减少HTTP请求次数。
下面是一个使用`gzip`模块来压缩响应的示例:
```python
import gzip
import http.server
import socketserver
class GzipHTTPRequestHandler(http.server.SimpleHTTPRequestHandler):
def end_headers(self):
self.send_header('Content-Encoding', 'gzip')
http.server.SimpleHTTPRequestHandler.end_headers(self)
def _write(self, data):
self.wfile.write(***press(data))
# 服务器设置
server_address = ('', 8000)
httpd = socketserver.TCPServer(server_address, GzipHTTPRequestHandler)
# 启动服务器
httpd.serve_forever()
```
在这个例子中,`GzipHTTPRequestHandler`类覆写了`end_headers`方法来添加`Content-Encoding`头部,并且使用`gzip`模块压缩了响应数据。
## 3.2 构建动态内容
### 3.2.1 CGI和WSGI简介
CGI(Common Gateway Interface)和WSGI(Web Server Gateway Interface)是Python中用于构建动态Web内容的接口标准。WSGI是CGI的升级版,提供了更高效的Web服务和应用之间的通信方式。
#### CGI工作原理
CGI通过HTTP请求参数和环境变量与Web服务器交互。Web服务器接收客户端请求,启动CGI脚本,并将请求信息传递给脚本。脚本处理后,将结果返回给Web服务器,服务器再将结果发送给客户端。
#### WSGI工作原理
WSGI定义了一个简单的API,用于Web服务器和Python Web应用程序之间的通信。它通过一个可调用对象(应用程序对象)来处理请求,该对象接收环境信息并返回响应。
### 3.2.2 动态内容生成示例
下面是一个简单的WSGI应用程序示例,它根据请求路径返回不同的响应:
```python
from wsgiref.simple_server import make_server
def simple_app(environ, start_response):
path = environ.get('PATH_INFO', '')
if path == '/':
status = '200 OK'
headers = [('Content-type', 'text/plain; charset=utf-8')]
start_response(status, headers)
return [b'Hello, World!']
else:
status = '404 Not Found'
headers = [('Content-type', 'text/plain; charset=utf-8')]
start_response(status, headers)
return [b'Not Found']
httpd = make_server('', 8000, simple_app)
httpd.serve_forever()
```
在这个例子中,`simple_app`函数是一个WSGI应用程序,它检查请求的路径,并返回相应的响应。
## 3.3 错误处理和日志记录
### 3.3.1 自定义错误页面
HTTPServer模块允许你自定义错误处理。你可以通过覆写`error_message_format`属性来自定义错误页面。
```python
from http.server import HTTPServer, BaseHTTPRequestHandler, SimpleHTTPRequestHandler
class CustomHTTPRequestHandler(SimpleHTTPRequestHandler):
error_message_format = """\
<html>
<head><title>Error</title></head>
<body>
<h1>%s</h1>
<p>%s</p>
<hr>
<p>Request Method: %s</p>
<p>Request URI: %s</p>
<p>Server Time: %s</p>
</body>
</html>
"""
# 服务器设置
server_address = ('', 8000)
httpd = HTTPServer(server_address, CustomHTTPRequestHandler)
# 启动服务器
httpd.serve_forever()
```
在这个例子中,`error_message_format`属性被覆写以提供一个自定义的错误页面格式。
### 3.3.2 日志记录配置和分析
日志记录是Web服务器管理的重要部分。你可以使用Python的标准库`logging`模块来配置和记录HTTPServer的日志。
```python
import logging
from http.server import HTTPServer, BaseHTTPRequestHandler
# 配置日志
logging.basicConfig(level=***)
class LoggingHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
***('Request received: %s', self.path)
# 调用父类的do_GET方法处理请求
super().do_GET()
# 服务器设置
server_address = ('', 8000)
httpd = HTTPServer(server_address, LoggingHTTPRequestHandler)
# 启动服务器
httpd.serve_forever()
```
在这个例子中,我们在`LoggingHTTPRequestHandler`类中覆写了`do_GET`方法,并添加了日志记录。这样,每当有GET请求到达时,都会记录一条日志信息。
通过本章节的介绍,我们可以看到,Python HTTPServer模块提供了强大的工具来处理静态文件服务、构建动态内容以及进行错误处理和日志记录。这些技巧对于构建高效和可靠的网络服务至关重要。在下一章节中,我们将进一步探讨HTTPServer模块的高级应用技巧。
# 4. HTTPServer模块的进阶应用
## 4.1 高级请求处理
### 4.1.1 请求分发机制
在构建复杂的Web应用时,请求分发机制是一个核心概念。它负责将客户端的请求路由到正确的处理函数或者服务。在Python的HTTPServer模块中,可以通过覆写`handle_request`方法来实现自定义的请求分发逻辑。
#### *.*.*.* 自定义请求处理逻辑
```python
from http.server import BaseHTTPRequestHandler, HTTPServer
class CustomHTTPRequestHandler(BaseHTTPRequestHandler):
def handle_request(self):
if self.path.startswith('/api'):
# 处理API请求
self.handle_api()
else:
# 默认静态文件处理
BaseHTTPRequestHandler.handle_request(self)
def handle_api(self):
# 这里实现API的请求处理逻辑
pass
# ...
server = HTTPServer(('localhost', 8000), CustomHTTPRequestHandler)
server.serve_forever()
```
在这个例子中,我们通过检查请求的路径来决定是否是API请求,并将其分发到不同的处理函数中。这样可以更好地组织代码,并将不同类型的请求分离处理。
### 4.1.2 URL映射和路由
在实际的Web应用中,通常需要将URL映射到具体的处理函数或者视图。这可以通过路由表来实现。
#### *.*.*.* 使用路由表映射URL
```python
from http.server import BaseHTTPRequestHandler, HTTPServer
import urllib.parse as urlparse
class RouterHTTPRequestHandler(BaseHTTPRequestHandler):
routes = {
'/': 'index',
'/api/items': 'get_items',
'/api/items/<item_id>': 'get_item'
}
def handle_request(self):
parsed_path = urlparse.urlparse(self.path)
route = self.routes.get(parsed_path.path, 'not_found')
getattr(self, f'_{route}')(self)
def _index(self):
# 处理首页请求
pass
def _get_items(self):
# 处理获取多个项目的请求
pass
def _get_item(self, item_id):
# 处理获取单个项目请求
pass
def _not_found(self):
# 处理404请求
pass
# ...
server = HTTPServer(('localhost', 8000), RouterHTTPRequestHandler)
server.serve_forever()
```
在这个例子中,我们定义了一个路由表`routes`,它将URL路径映射到处理函数。`handle_request`方法会根据请求的路径找到对应的处理函数并调用。
## 4.2 安全性增强
### 4.2.1 HTTPS支持
为了增强Web应用的安全性,可以使用HTTPS协议代替HTTP。在Python中,可以通过安装`ssl`模块的`wrap_socket`方法来实现HTTPS支持。
#### *.*.*.* 实现HTTPS支持的HTTPServer
```python
from http.server import HTTPServer, BaseHTTPRequestHandler
import socketserver
import ssl
class SecureHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
# 处理GET请求
self.send_response(200)
self.end_headers()
self.wfile.write(b"Secure content")
class SecureHTTPServer(socketserver.ThreadingMixIn, HTTPServer):
allow_reuse_address = True
def __init__(self, server_address, HandlerClass, keyfile=None, certfile=None):
HTTPServer.__init__(self, server_address, HandlerClass)
self.socket = ssl.wrap_socket(self.socket, keyfile=keyfile, certfile=certfile, server_side=True)
# ...
server = SecureHTTPServer(('localhost', 443), SecureHTTPRequestHandler)
server.serve_forever()
```
在这个例子中,我们创建了一个`SecureHTTPServer`类,它在初始化时使用`ssl.wrap_socket`来将HTTP连接转换为HTTPS连接。
### 4.2.2 身份验证和授权
为了控制对敏感资源的访问,可以在HTTPServer中实现身份验证和授权机制。
#### *.*.*.* 实现基本的身份验证
```python
import base64
class AuthHTTPRequestHandler(BaseHTTPRequestHandler):
BASIC_AUTH_USER = "user"
BASIC_AUTH_PASS = "pass"
def _http_auth_required(self, auth_fail=False):
# 检查是否提供用户名和密码
if not self.headers.get('Authorization'):
self._send_unauthorized()
return True
# 解码Base64编码的用户名和密码
auth = self.headers.get('Authorization').split()
if len(auth) != 2 or auth[0] != 'Basic':
self._send_unauthorized()
return True
# 验证用户名和密码
username, password = base64.b64decode(auth[1]).decode().split(':')
if username != self.BASIC_AUTH_USER or password != self.BASIC_AUTH_PASS:
self._send_unauthorized()
return True
return False
def _send_unauthorized(self):
# 发送401未授权响应
self.send_response(401)
self.send_header('WWW-Authenticate', 'Basic realm="My Realm"')
self.end_headers()
def do_GET(self):
if self._http_auth_required():
return
# 处理授权后的GET请求
pass
# ...
server = HTTPServer(('localhost', 8000), AuthHTTPRequestHandler)
server.serve_forever()
```
在这个例子中,我们定义了一个`AuthHTTPRequestHandler`类,它在`do_GET`方法中实现了基本的身份验证。如果请求没有提供有效的用户名和密码,服务器将发送一个401未授权响应。
## 4.3 性能优化
### 4.3.1 异步IO支持
为了提高HTTPServer的性能,特别是在处理大量并发连接时,可以引入异步IO支持。
#### *.*.*.* 使用异步库重构HTTPServer
```python
import asyncio
from aiohttp.web import Response, RequestHandler
from aiohttp.server import Server
class AsyncHTTPRequestHandler(RequestHandler):
async def get(self, request):
# 异步处理GET请求
return Response(text="Hello, world")
async def main():
# 创建异步HTTPServer
app = Server(AsyncHTTPRequestHandler)
await app.start_server(host='localhost', port=8000)
# 运行事件循环
await asyncio.sleep(3600)
if __name__ == '__main__':
asyncio.run(main())
```
在这个例子中,我们使用了`aiohttp`库来创建一个异步的HTTPServer。`AsyncHTTPRequestHandler`类继承自`RequestHandler`,并实现了异步的`get`方法来处理GET请求。
### 4.3.2 缓存策略和负载均衡
为了进一步提高性能,可以实现缓存策略和负载均衡。
#### *.*.*.* 实现简单的缓存策略
```python
import functools
cache = {}
class CachingHTTPRequestHandler(BaseHTTPRequestHandler):
def do_GET(self):
# 使用缓存来处理GET请求
path = self.path
if path in cache:
self.send_response(200)
self.send_header('Content-Type', 'text/html')
self.end_headers()
self.wfile.write(cache[path])
return
# 缓存未命中,正常处理请求
BaseHTTPRequestHandler.do_GET(self)
# 将响应内容缓存起来
cache[path] = self.wfile.getvalue()
# ...
server = HTTPServer(('localhost', 8000), CachingHTTPRequestHandler)
server.serve_forever()
```
在这个例子中,我们定义了一个`CachingHTTPRequestHandler`类,它在`do_GET`方法中实现了简单的缓存策略。如果请求的路径已经在缓存中,就直接返回缓存的内容,否则正常处理请求并将响应内容加入缓存。
请注意,这里的代码示例是为了说明如何在Python的HTTPServer模块中实现进阶应用。在实际的生产环境中,还需要考虑更多的因素,例如安全性、异常处理、资源管理和监控等。
# 5. 案例分析:构建RESTful API服务
## 5.1 RESTful API设计原则
RESTful API的设计原则基于网络架构的无状态原则,它通过使用HTTP协议的标准方法来实现资源的CRUD(创建、读取、更新、删除)操作。RESTful API的关键设计原则包括:
### 5.1.1 资源的表示
在RESTful API中,资源是通过URI(统一资源标识符)来表示的。每个URI代表一种特定的资源,例如一个用户、一篇文章或一个订单。资源通常以名词形式出现,并且可以嵌套来表示更复杂的实体关系。
```mermaid
graph LR
A[用户] -->|包含| B[订单]
A -->|拥有| C[个人资料]
```
### 5.1.2 API的版本控制
随着API的发展,可能会出现新的版本。为了避免客户端和服务器之间的不兼容问题,API应该进行版本控制。通常,版本信息会包含在URL中,例如 `/api/v1/users`。
## 5.2 使用HTTPServer开发RESTful服务
### 5.2.1 设计路由和资源
在使用HTTPServer开发RESTful服务时,首先需要设计路由和资源的结构。这里是一个简单的例子,展示了如何设计用户资源的路由:
```python
from http.server import BaseHTTPRequestHandler, HTTPServer
import json
class RESTfulAPIHandler(BaseHTTPRequestHandler):
def _set_headers(self, status=200):
self.send_response(status)
self.send_header('Content-type', 'application/json')
self.end_headers()
def do_GET(self):
self._set_headers()
self.wfile.write(json.dumps({"message": "Hello, World!"}).encode())
def do_POST(self):
content_length = int(self.headers.get('Content-Length', 0))
post_data = self.rfile.read(content_length)
# 解析POST数据,例如JSON
# 处理请求,例如创建资源
self._set_headers(201)
self.wfile.write(json.dumps({"message": "Resource created"}).encode())
# 设置服务器监听本地主机的8000端口
server_address = ('', 8000)
httpd = HTTPServer(server_address, RESTfulAPIHandler)
httpd.serve_forever()
```
### 5.2.2 数据序列化和API文档
数据序列化通常是API交互的核心部分。在RESTful API中,JSON是最常用的数据序列化格式。API文档是帮助开发者理解和使用API的关键,应该提供清晰的接口描述、请求和响应示例。
```json
{
"users": [
{
"id": 1,
"name": "John Doe",
"email": "john.***"
},
{
"id": 2,
"name": "Jane Doe",
"email": "jane.***"
}
]
}
```
## 5.3 部署和维护
### 5.3.1 部署到生产环境
在部署RESTful服务到生产环境时,应该考虑使用更健壮的服务器软件,如Gunicorn或uWSGI,并且部署在专业的Web服务器上,例如Nginx或Apache。同时,应该使用HTTPS来保证数据的安全性。
### 5.3.2 监控和维护策略
API服务的监控和维护是确保服务稳定运行的关键。应该实施日志记录、错误监控和性能监控等策略。此外,还应该定期更新API文档,以反映最新的API变更。
通过以上步骤,我们可以使用Python的HTTPServer模块构建一个基本的RESTful API服务,并将其部署到生产环境中。随着服务的增长,还可以考虑引入更多的高级特性和维护策略,以确保服务的可扩展性和可靠性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中强大的 HTTPServer 模块,从基础概念到高级应用。涵盖了从零构建 HTTP 服务器、自定义请求处理逻辑、创建静态文件服务器到构建动态内容处理的 Web 服务器等主题。还介绍了性能优化、安全实践、故障排查、多线程处理、异步 I/O 实践、SSL/TLS 加密集成、与 Web 框架整合、测试与调试、部署、企业级应用、监控与日志、负载均衡和 WebSocket 集成等高级技术。通过深入的代码示例和清晰的解释,本专栏旨在帮助开发者充分利用 HTTPServer 模块,构建强大且可扩展的 Web 服务。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【集群故障不再怕】:使用ClusterEngine浪潮平台进行高效监控与诊断
# 摘要
本文重点介绍了集群监控与诊断在现代IT运维管理中的重要性,并详细解读了ClusterEngine浪潮平台的基础架构、设计理念及其关键功能组件。文章阐述了如何安装和配置ClusterEngine,以实现集群资源的高效注册与管理,并深入探讨了用户界面设计,确保了管理的便捷性。在监控实践章节,本文通过节点监控、服务监控以及性能分析,提供了全面的资源监控实践案例。针对集群故障,本文提出了一套高效的诊断流程,并
动态表头渲染:Vue中的优雅解决方案揭秘

# 摘要
本文深入探讨了Vue框架中动态表头渲染的技术与实践。首先,文章奠定了动态表头渲染的理论基础,介绍了实现该技术的基础组件、插槽和渲染函数的高级运用。随后,通过场景实战部分,展示了如何在Vue应用中实现表头的自定义、动态更新及响应式数据变化。进阶应用章节进一步分析了性能优化、懒加载以及可
MySQL高级特性全解析:存储过程和触发器的精进之路

# 摘要
本文系统地介绍了MySQL存储过程与触发器的基础知识、高级应用和最佳实践。首先概述了存储过程与触发器的概念、定义、优势及创建语法。接着深入探讨了存储过程的参数、变量、控制结构及优化技巧,以及触发器的类型、编写、触发时机和实战应用。文章还包含了存储过程与触发器的案例分析,涵盖数据处理、业务逻辑实现和性能优化。此外,文中探讨了存储过程与触发器的故障排查
IBM Rational DOORS深度剖析:5大技巧打造高效需求管理流程
# 摘要
IBM Rational DOORS作为一种先进的需求管理工具,在软件和系统工程领域发挥着至关重要的作用。本文首先介绍了IBM Rational DOORS的基本概念和需求管理的理论基础,随后深入探讨了其核心功能在需求捕获、管理和验证方面的具体实践。文章还分享了打造高效需
InnoDB数据恢复高级技巧:表空间与数据文件的全面分析

# 摘要
本文对InnoDB存储引擎的数据恢复进行了全面的探讨,涵盖了从基本架构到恢复技术的各个方面。首先介绍了InnoDB的基本架构和逻辑结构,重点分析了数据文件和表空间的特性,事务与锁定机制的实现。随后深入分析了数据文件的内部结构,表空间文件操作以及页故障的检测和修复策略。接着详细阐述了物理恢复和逻辑恢复的技术原理和实践方法
【确保光模块性能,关键在于测试与验证】:实战技巧大公开
# 摘要
光模块作为光通信系统的核心组件,其性能直接影响整个网络的质量。本文全面介绍了光模块性能测试的基础理论、测试设备与工具的选择与校准、性能参数测试实践、故障诊断与验证技巧,以及测试案例分析和优化建议。通过对光模块测试流程的深入探讨,本文旨在提高光模块测试的准确性与效率,确保光通信系统的可靠性和稳定性。文章综合分析了多种测试方法和工具,并提供了案例分析以及应对策略,为光模块测试提供了完整的解决方案。同时
XJC-CF3600-F故障诊断速成:专家级问题排查与解决攻略
# 摘要
本文针对XJC-CF3600-F的故障诊断进行了全面概述,从理论基础到实际操作,详细探讨了其工作原理、故障分类、诊断流程,以及专用诊断软件和常规诊断工具的应用。在实践中,针对硬件故障、软件问题以及网络故障的排查方法和解决策略进行了分析。同时,文章还强调了定期维护、故障预防措施和应急预案的重要性,并通过案例研究分享了故障排查的经验。本文旨在为技术人员提供实用的故障诊断知识和维护策略,帮助他们提升故障排除能力,优化设备性能,确保系统的稳定运行。
# 关键字
故障诊断;XJC-CF3600-F;诊断流程;维护策略;硬件故障;软件问题
参考资源链接:[XJC-CF3600-F操作手册:功
【SIM卡无法识别?】:更新系统驱动快速解决

# 摘要
本文系统性地探讨了SIM卡识别问题及其解决方案,重点分析了系统驱动的基本知识和SIM卡驱动的重要作用。文章详细阐述了更新SIM卡驱动的理论基础和实践操作步骤,同时讨论了更新后驱动的调试与优化流程。此外,本文还提供了一系列预防措施和最佳维护实践,以帮助用户安全、有效地管理SIM卡驱动更新,确保设备的稳定运行和安全性。最后,本文强调了
Kafka与微服务完美结合:无缝集成的5个关键步骤
# 摘要
随着微服务架构在企业中的广泛应用,集成高效的消息队列系统如Kafka对于现代分布式系统的设计变得至关重要。本文详细探讨了Kafka与微服务的集成基础、高级特性及实践步骤,并分析了集成过程中的常见问题与解决方案,以及集成后的性能优化与监控。文章旨在为读者提供一个系统的指南,帮助他们理解和实现Kafka与微服务的深度融合,同时提供了优化策略和监控工具来提高系统的可靠性和性能。
# 关键字
Kafka;微服务架构;
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )