Python CGI编程:5个实用技巧让你成为Web请求处理大师
发布时间: 2024-10-09 05:21:43 阅读量: 83 订阅数: 34 

Python编程全面介绍:从基础知识到实用技巧

# 1. Python CGI编程概述
CGI,即公共网关接口(Common Gateway Interface),是一种允许Web服务器与外部程序进行通信的协议。Python凭借其简洁的语法和强大的库支持,成为编写CGI脚本的理想选择。在这一章节中,我们将概览CGI在Python中的应用,以及它的基本工作原理。我们会探讨CGI如何成为连接用户与后端服务的桥梁,允许服务器执行特定的任务,并将结果返回给用户端。此外,本章还将介绍CGI对于动态网页生成的重要性,以及它在现代Web开发中的地位。通过理解CGI的工作流程和优势,读者将能够更好地把握在Python环境下开发CGI应用程序的基础知识。
# 2. 搭建CGI环境与基本操作
## 2.1 安装和配置CGI环境
### 2.1.1 选择合适的Web服务器
在搭建CGI环境时,选择一个合适的Web服务器至关重要。Web服务器是托管Web应用、处理用户请求和提供静态内容的基础。对于CGI脚本而言,比较常用的支持CGI的服务器包括Apache和Nginx。
Apache Web服务器因其强大的模块化和广泛的功能支持,一直受到开发者的青睐。它提供了一个名为mod_cgi的模块,可以用来处理CGI脚本。此外,mod_cgi2和mod_cgid等模块提供了额外的功能和性能优化。
Nginx虽然主要以其高效的静态内容处理和反向代理功能而闻名,但是通过FastCGI或者直接使用Nginx的CGI模块也可以支持CGI脚本。
选择哪个Web服务器通常取决于具体的项目需求和开发者的熟悉程度。对于需要高并发处理的场景,Nginx是一个很好的选择。对于功能丰富、需要配置大量CGI选项的应用,Apache可能更加合适。
### 2.1.2 安装Python解释器
CGI脚本可以用多种编程语言编写,其中Python因其简洁易读和丰富的库支持而备受欢迎。在配置Web服务器以支持CGI之前,首先需要安装Python解释器。以下是跨平台安装Python的通用步骤:
在大多数Linux发行版中,你可以使用包管理器来安装Python。例如,在基于Debian的系统中,可以使用以下命令:
```bash
sudo apt-get update
sudo apt-get install python3
```
对于MacOS,可以使用Homebrew进行安装:
```bash
brew install python3
```
在Windows上,可以从Python官方网站下载安装程序并按照说明进行安装。
安装完成后,验证Python是否正确安装,可以通过在命令行中输入`python3 --version`(在某些系统上,命令是`python --version`)。
### 2.1.3 配置Web服务器支持CGI
配置Web服务器以支持CGI,涉及到修改服务器配置文件并指定CGI脚本的运行方式。以Apache服务器为例,配置步骤如下:
1. 确保Apache已经安装并运行。
2. 在Apache的配置文件`httpd.conf`中找到`LoadModule`指令,确保启用了mod_cgi模块:
```apacheconf
LoadModule cgi_module modules/mod_cgi.so
```
3. 接着,指定哪些目录中的文件被视为CGI脚本。例如,你可以将CGI脚本放置在一个名为`cgi-bin`的目录中,并通过以下指令进行配置:
```apacheconf
<Directory "/path/to/cgi-bin">
AllowOverride None
Options +ExecCGI
Order allow,deny
Allow from all
</Directory>
```
4. 重启Apache服务器,以使配置生效。
```bash
sudo systemctl restart apache2
```
对于Nginx,如果要使用内置的CGI模块,通常需要从源代码编译安装Nginx,并在编译时启用CGI模块。如果你选择使用FastCGI,可以通过PHP-FPM等第三方模块来实现。
## 2.2 创建第一个CGI脚本
### 2.2.1 编写Hello World示例
编写第一个CGI脚本是学习CGI编程的起点。在Python中,一个基本的Hello World CGI脚本如下所示:
```python
#!/usr/bin/env python3
print("Content-type: text/html")
print()
print("<h1>Hello, CGI World!</h1>")
```
这个脚本首先输出HTTP响应头,告诉浏览器返回的数据类型为text/html。接着,它输出一个简单的HTML标题。
### 2.2.2 CGI脚本的执行流程
当你在浏览器中请求这个脚本时,Web服务器会执行以下流程:
1. Web服务器接收到HTTP请求。
2. 服务器检查请求的URL是否指向一个配置为可执行的CGI脚本。
3. 如果是,服务器加载指定的解释器(如Python)来执行脚本。
4. 脚本运行后,其输出被发送回Web服务器。
5. Web服务器将输出转发给浏览器。
6. 浏览器解析输出并显示内容。
### 2.2.3 脚本的调试和运行问题
调试CGI脚本时,常见的问题包括权限问题、错误的HTTP头信息输出、脚本无法执行等。以下是解决这些常见问题的步骤:
- 确保脚本文件具有可执行权限。
- 确保脚本输出的HTTP头信息格式正确。
- 在脚本首部,指定解释器的绝对路径以避免系统环境变量导致的问题。
- 查看服务器错误日志,这通常会给出脚本执行失败的详细信息。
以下是确保Python脚本可执行的命令:
```bash
chmod +x my_cgi_script.py
```
如果遇到运行时错误,可以手动通过命令行运行脚本,以查看执行过程中出现的错误信息,例如:
```bash
python3 my_cgi_script.py
```
在Web服务器日志中查找错误信息也是一种常见和有效的调试手段。
通过上述步骤,你可以搭建起CGI环境,并开始编写和调试简单的CGI脚本。这将为深入理解Web编程和CGI机制打下坚实的基础。
# 3. CGI请求处理技巧
## 3.1 获取环境变量
### 3.1.1 理解和使用CGI环境变量
CGI程序运行时,Web服务器会为每个请求创建一个新的环境,并设置一系列环境变量。这些环境变量包含了有关客户端请求的所有信息,比如客户端IP地址、请求方式、浏览器类型等。理解和使用这些环境变量是编写有效CGI程序的关键部分。
要获取环境变量,可以通过Python的`os`模块。例如:
```python
import os
print(os.environ['REQUEST_METHOD'])
```
上述代码会输出客户端请求的方法(如"GET"或"POST")。环境变量列表很长,包括但不限于`QUERY_STRING`、`CONTENT_TYPE`和`REMOTE_ADDR`等,每一种都可能在不同的情况下提供重要信息。
### 3.1.2 处理常见的环境变量
为了处理常见的环境变量,开发者需要理解哪些是关键信息,并知道如何利用这些信息。下面列举了一些常见的环境变量及其用途:
- `REQUEST_METHOD`: 指明请求方法(GET, POST, HEAD等)。
- `QUERY_STRING`: 包含URL的查询字符串部分。
- `CONTENT_LENGTH`: 表明POST请求中传输的数据的字节长度。
- `REMOTE_ADDR`: 发起请求的客户端IP地址。
- `HTTP_USER_AGENT`: 提供发起请求的用户代理字符串。
处理这些变量需要考虑到不同Web服务器对环境变量的支持程度和方式可能略有不同。例如,在Apache服务器中,CGI程序可以通过环境变量访问所有HTTP请求头。如果环境变量不满足需求,还可以通过CGI标准的`STDIN`来直接读取输入数据。
## 3.2 解析和使用表单数据
### 3.2.1 理解POST和GET方法
在Web开发中,最常见的HTTP请求方法是GET和POST。GET请求通常用于从服务器检索数据,而POST请求用于向服务器提交数据以进行处理。
在CGI编程中,识别和区分这两种方法至关重要。GET请求的数据通过URL的查询字符串(即环境变量`QUERY_STRING`)传递,而POST请求的数据通过请求体传递,需要使用输入流`STDIN`进行读取。
### 3.2.2 表单数据的解析方法
处理表单数据通常涉及解析查询字符串(对于GET请求)或处理POST请求的数据流。对于POST请求,数据通常以`application/x-www-form-urlencoded`或`multipart/form-data`格式传输,具体取决于表单的`enctype`属性。
Python CGI脚本中可以使用`cgi`模块来解析POST请求中的数据。下面是一个简单的例子:
```python
import cgi
form = cgi.FieldStorage()
name = form.getvalue('name')
email = form.getvalue('email')
```
在上面的代码中,`cgi.FieldStorage()`解析请求体中的数据,并创建一个类字典对象`form`,允许通过`getvalue()`方法获取字段值。
## 3.3 构建响应消息
### 3.3.1 设置HTTP响应头
构建响应消息时,第一步通常是设置HTTP响应头。这些头信息可以控制如何处理响应,例如指定内容类型、缓存控制等。
```python
print("Content-Type: text/html")
print("Status: 200 OK")
```
在上面的示例中,`Content-Type`头信息指定响应的内容类型为HTML,而`Status`头信息提供了HTTP状态码。
### 3.3.2 编写HTML内容
在发送完HTTP响应头后,接下来是编写响应内容。这通常意味着要创建一些HTML代码来展示给用户。
```html
<html>
<head>
<title>CGI Example</title>
</head>
<body>
<h1>欢迎使用CGI</h1>
<p>您的名字是: %s</p>
</body>
</html>
```
上面的HTML代码在浏览器中展示一个简单的欢迎页面,其中`%s`将被替换为用户的名字。
### 3.3.3 返回JSON数据
随着Web服务的发展,很多时候我们需要向客户端返回JSON格式的数据,而不是HTML页面。可以通过设置适当的`Content-Type`来返回JSON数据,并使用Python的`json`模块来处理数据。
```python
import json
data = {'name': 'Alice', 'email': '***'}
print("Content-Type: application/json")
print(json.dumps(data))
```
在上述代码段中,我们首先创建一个Python字典`data`,然后使用`json.dumps()`方法将其转换为JSON格式的字符串,并通过`print`语句输出。
以上各段落展示了如何在Python CGI脚本中处理请求、获取环境变量、解析表单数据,并构建响应消息。接下来的章节将探讨CGI的高级实践技巧,包括文件上传处理、会话管理与cookie的使用,以及错误处理和日志记录。
# 4. ```
# 第四章:CGI高级实践技巧
## 4.1 文件上传处理
### 4.1.1 设置文件上传表单
文件上传是许多Web应用的核心功能之一。在CGI中处理文件上传需要几个步骤,从用户界面的表单到服务器端的处理。
首先,你需要创建一个HTML表单,该表单指定了`enctype`为`multipart/form-data`,这是文件上传表单的必要条件。以下是设置文件上传表单的基本步骤:
1. 创建一个HTML表单,包含一个`<input type="file">`元素,用户可以通过它选择文件。
2. 设置`<form>`标签的`method`属性为`POST`,并设置`enctype`属性为`multipart/form-data`。
3. 指定`<form>`标签的`action`属性,该属性值应指向处理文件上传的CGI脚本。
一个简单的文件上传表单示例如下:
```html
<!DOCTYPE html>
<html>
<head>
<title>文件上传表单</title>
</head>
<body>
<form action="/cgi-bin/upload.cgi" method="POST" enctype="multipart/form-data">
<input type="file" name="fileToUpload" id="fileToUpload">
<input type="submit" value="上传文件" name="submit">
</form>
</body>
</html>
```
### 4.1.2 读取和保存上传文件
CGI脚本需要解析多部分表单数据以读取上传的文件。Python提供了`cgi`模块,可以帮助处理这种情况。
下面是一个处理上传文件的CGI脚本示例:
```python
import cgi
import os
form = cgi.FieldStorage()
file_item = form['fileToUpload']
if file_item.filename:
filename = os.path.basename(file_item.filename)
try:
with open(filename, 'wb') as fp:
fp.write(file_item.file.read())
except IOError:
print("无法保存文件")
exit()
print("文件上传成功")
else:
print("没有文件被上传")
```
在上述代码中,`cgi.FieldStorage()`解析了表单提交的数据,然后脚本检查是否有文件被上传,并将其保存到服务器上。
### 4.1.3 文件上传的安全性和限制
文件上传功能在提供便利的同时,也可能引入安全风险。以下是需要考虑的一些安全措施:
- **限制上传文件类型**:确保只接受预期的文件类型。
- **检查文件大小**:防止大文件占用服务器过多资源。
- **扫描文件内容**:检查上传的文件是否含有恶意代码或病毒。
- **权限管理**:确保上传的文件不会被访问或执行,除非用户有相应的权限。
## 4.2 会话管理与cookie
### 4.2.1 使用cookie进行会话跟踪
在Web应用中,会话管理允许应用记住用户的状态。Cookie是实现这一功能的一种常见方式。它允许服务器向用户的浏览器发送一小段数据,并且该数据在用户后续访问时可以被浏览器返回到服务器。
在Python中,你可以使用`http.cookies`模块来创建和管理cookie:
```python
from http.cookies import SimpleCookie
def set_cookie():
cookie = SimpleCookie()
cookie['user'] = "value" # 设置cookie
cookie['user']['expires'] = 100 # 设置cookie过期时间
response = 'Set-Cookie: ' + cookie.output(header='').strip()
print(response)
set_cookie()
```
上述代码创建了一个名为`user`的cookie,其值为`value`,并且设置了一个过期时间。
### 4.2.2 使用session模块管理状态
Python的`cgi`模块包含了一个简单的会话管理机制,通过cookie实现。这个`Session`对象可以帮助开发者存储和检索会话数据:
```python
import cgi
import cgitb
cgitb.enable()
form = cgi.FieldStorage()
session = cgitb.html() # 使用session对象
# 检查会话中是否有名字
if 'username' in session:
print(f"欢迎回来, {session['username']}")
else:
# 如果没有,设置一个新的名字
session['username'] = form.getvalue('username', '匿名')
print(f"您好, {session['username']}")
# 注意:在脚本结束时,session对象会自动将cookie写回客户端
```
在这段示例代码中,我们创建了一个会话,用于存储用户输入的用户名。如果用户再次访问此页面,则会自动记住用户名。
## 4.3 错误处理和日志记录
### 4.3.1 编写健壮的错误处理代码
健壮的错误处理对于任何程序都是至关重要的,特别是对于Web应用。在CGI中,你可以使用Python的`try`和`except`语句来捕获和处理可能发生的错误。
```python
try:
# 这里是可能会出错的代码
result = 10 / 0
except ZeroDivisionError:
print("错误:不能除以零。")
except Exception as e:
print(f"发生了一个错误:{str(e)}")
```
在上述代码块中,我们尝试执行了一个除零操作,这会触发`ZeroDivisionError`异常,因此会执行相应的错误处理代码。我们也使用了一个通用的`except`来捕获其他类型的异常。
### 4.3.2 使用日志模块记录CGI活动
Python的`logging`模块是一个强大的日志记录工具。它可以帮助你记录应用运行时的各种信息,包括错误、警告、调试信息等。
```python
import logging
# 配置日志记录器
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)s %(message)s',
filename='/var/log/myapp.log',
filemode='w')
# 记录不同级别的信息
logging.debug('这是一个调试信息')
***('这是一些常规信息')
logging.warning('警告信息')
logging.error('发生了错误')
logging.critical('严重的错误')
```
在上述代码中,我们配置了一个日志记录器,它会将日志信息输出到文件`/var/log/myapp.log`中,并且包含了时间戳、日志级别以及消息内容。
本章节详细介绍了CGI高级实践技巧中的文件上传处理、会话管理与cookie以及错误处理和日志记录。通过深入理解这些内容,你将能够开发更复杂、功能更丰富的Web应用。
```
# 5. 优化和安全的CGI编程
## 5.1 性能优化策略
### 5.1.1 分析CGI脚本性能瓶颈
在处理高流量的Web应用时,CGI脚本的性能瓶颈往往成为限制系统响应速度和吞吐量的罪魁祸首。要提高性能,首先需要对CGI脚本进行性能分析。性能分析主要关注以下几个方面:
- **CPU密集型任务**:检查脚本中是否存在大量的计算,这可能造成CPU资源的大量消耗。
- **I/O操作**:文件读写或网络通信等I/O操作往往比CPU和内存操作慢得多,需要优化。
- **内存管理**:Python虽然有自动内存管理机制,但过度的内存使用或者频繁的内存分配与回收都会影响性能。
- **外部服务调用**:对数据库、外部API等服务的调用可能会成为瓶颈。
性能分析工具如`cProfile`可用于生成脚本的性能报告。通过分析报告,可以识别出执行时间最长的函数,进而对这些函数进行优化。
### 5.1.2 使用缓存提高效率
缓存是提高CGI脚本性能的有效手段之一,特别是对于读取频繁但变化不大的数据。使用缓存可以减少不必要的计算和I/O操作,从而加快响应速度。在Python中,可以使用`cachetools`这样的缓存库来实现高效的缓存管理。
缓存策略包括但不限于:
- **内存缓存**:将数据保存在内存中,适合频繁访问且数据量不大的场景。
- **文件缓存**:将数据序列化后存储在文件系统中,适合内存不足以缓存所有数据的场景。
- **分布式缓存**:如Redis或Memcached,适合需要高速访问且可扩展的大型应用。
```python
import cachetools
# 设置最大缓存项为100
cache = cachetools.TTLCache(maxsize=100, ttl=300)
def get_data_from_cache(key):
# 从缓存获取数据,如果不存在则调用函数计算数据并设置进缓存
return cache.get(key, calculate_data)
```
在上述示例中,`TTLCache` 是具有生存时间限制的缓存类型。它将在设定时间内自动失效,减少因数据陈旧造成的潜在问题。
## 5.2 安全性最佳实践
### 5.2.1 防止常见的CGI安全威胁
CGI编程中常见的安全威胁包括:
- **跨站脚本攻击(XSS)**:通过恶意用户输入,在用户的浏览器中执行任意HTML或JavaScript代码。
- **SQL注入**:利用Web表单中的输入作为SQL查询的一部分,可能会篡改或破坏数据库。
- **路径遍历攻击**:尝试通过Web表单访问服务器上的文件系统。
为了防止这些攻击,开发者必须遵循安全编码的最佳实践,包括:
- **输入验证**:验证所有用户输入,拒绝任何非法输入。
- **输出编码**:对输出内容进行HTML和JavaScript编码,以防止XSS攻击。
- **使用参数化查询**:在与数据库交互时使用参数化查询,防止SQL注入。
- **限制文件访问**:严格控制对文件系统的访问权限,避免路径遍历攻击。
### 5.2.2 使用安全的编码方式避免注入攻击
在CGI脚本中,使用安全的编码方式是防止注入攻击的关键。当Web表单数据被用作数据库查询或系统命令的一部分时,尤其要小心。
#### 使用预处理语句防止SQL注入
使用数据库库的预处理语句功能,可以避免将用户输入直接插入SQL语句中:
```python
import sqlite3
def get_user_by_name(username):
# 创建一个预处理语句
sql = "SELECT * FROM users WHERE username = ?"
conn = sqlite3.connect('example.db')
cursor = conn.cursor()
cursor.execute(sql, (username,))
return cursor.fetchall()
```
在上述代码中,`?` 是一个参数占位符,`username` 作为参数传递给SQL语句,有效防止了SQL注入攻击。
#### 使用参数化命令防止命令注入
执行系统命令时,也应避免直接插入用户输入:
```python
import subprocess
def run_command(command):
# 使用参数列表代替字符串拼接
result = subprocess.run(['ls', '-l', command], capture_output=True, text=True)
return result.stdout
```
通过使用列表的方式定义命令参数,确保用户输入只作为命令的一部分,而非命令的一部分,有效防止了命令注入攻击。
## 5.3 CGI与Web框架
### 5.3.1 选择合适的Web框架
随着CGI的使用变得更加复杂,Web框架逐渐成为开发Web应用的首选。选择合适的Web框架需要考虑以下几个方面:
- **社区支持**:一个活跃的开发社区意味着更多的文档、教程和第三方库。
- **性能**:不同的Web框架在性能上有差异,特别是在处理高并发请求时。
- **开发效率**:框架提供的工具和抽象能减少样板代码,加快开发速度。
- **兼容性**:与操作系统、数据库和其他第三方服务的兼容性。
常见的Python Web框架有Flask、Django、FastAPI等。Flask以其简单和轻量级而受到欢迎,适合快速开发小型项目;Django则是一个全功能的框架,提供了许多内置功能,适合大型项目;FastAPI则以高性能和异步处理著称,适合需要高并发处理的API开发。
### 5.3.2 将CGI脚本迁移到Web框架
迁移旧的CGI脚本到现代的Web框架需要遵循一定的步骤,以确保功能和性能都不受影响:
1. **代码重构**:将脚本中的逻辑分离出来,并转换为框架的控制器(如Flask的视图函数)。
2. **模板迁移**:如果使用了HTML模板,则需要将其转换为框架支持的模板格式(如Jinja2)。
3. **配置调整**:根据框架的要求调整配置,如数据库连接、静态文件路径等。
4. **测试**:编写测试用例并确保迁移后的应用能够正常工作。
```python
from flask import Flask, render_template
app = Flask(__name__)
@app.route('/')
def hello_world():
return render_template('hello.html')
if __name__ == '__main__':
app.run()
```
在此示例中,使用了Flask框架将一个简单的CGI脚本转换为一个Web应用。原有的CGI脚本逻辑被封装进`hello_world`视图函数中,`render_template`函数用于渲染HTML模板。
以上内容涵盖了CGI编程在性能优化、安全性强化方面的核心内容,并讨论了如何将CGI脚本迁移到现代Web框架以进一步提升开发效率和应用性能。
# 6. 实现CGI与数据库的交互
CGI脚本在处理Web请求时,常常需要查询或更新数据库中的信息。本章将探讨如何在CGI脚本中实现与数据库的交互。我们将重点讨论在CGI中使用Python对数据库进行操作的基本原理和方法。
## 6.1 选择合适的数据库
在开始编写代码之前,你需要确定使用哪种数据库。常见的选择包括SQLite、MySQL、PostgreSQL等。每种数据库都有其特点,例如SQLite操作简单,无需安装服务器即可使用,而MySQL和PostgreSQL则适合大规模的数据存储和管理。选择合适的数据库后,需要安装对应的Python数据库驱动库,如`sqlite3`、`pymysql`或`psycopg2`。
## 6.2 数据库连接和查询操作
数据库连接是任何数据库操作的起点。通常,我们需要编写连接数据库、执行查询和处理结果的代码。以下是使用SQLite进行数据库连接和查询的一个示例:
```python
import sqlite3
# 连接到SQLite数据库
# 数据库文件是test.db,如果文件不存在,会自动生成
conn = sqlite3.connect('test.db')
# 创建一个Cursor对象并使用它执行SQL语句
c = conn.cursor()
# 执行查询语句
c.execute('SELECT * FROM users')
# 获取所有查询结果
results = c.fetchall()
# 输出结果
for row in results:
print(row)
# 关闭Cursor和连接
c.close()
conn.close()
```
## 6.3 处理CGI请求中的用户数据
在CGI应用中,用户提交的数据通常通过表单提交。我们需要从CGI环境变量中获取这些数据,并将它们作为SQL语句的参数以防止SQL注入攻击。以下是获取CGI环境中的用户输入并用于SQL查询的示例:
```python
# 获取CGI环境中的用户输入
user_input = request['QUERY_STRING']
user_id = request['REQUEST_METHOD'] == 'POST' and request.POST.get('id')
# 使用参数化查询防止SQL注入
c.execute('SELECT * FROM users WHERE id=?', (user_id,))
```
## 6.4 数据更新和插入操作
不仅能够查询数据库,还需要更新或插入数据以响应用户请求。使用参数化查询同样可以保护你的应用免受SQL注入的威胁。以下是一个插入数据到数据库的示例:
```python
# 插入一条数据到数据库
c.execute('INSERT INTO users (id, name) VALUES (?, ?)', (user_id, 'New Name'))
# 提交事务
***mit()
# 关闭Cursor和连接
c.close()
conn.close()
```
## 6.5 错误处理和异常管理
与数据库交互时,总有可能发生各种异常情况,比如连接失败、查询错误等。应当在脚本中妥善处理这些异常,以保证应用的健壮性:
```python
try:
# 尝试执行可能引发异常的代码
c.execute('SELECT * FROM users')
except sqlite3.Error as error:
print("数据库处理出错:", error)
finally:
# 关闭Cursor和连接
if c:
c.close()
if conn:
conn.close()
```
## 6.6 总结
CGI脚本在与数据库交互时,主要关注点在于安全地处理用户输入和防止SQL注入,以及如何有效地管理数据库连接和异常。通过本章的介绍,你应该能掌握基础的数据库操作和如何将这些操作集成到你的CGI应用中。在下一章,我们将探讨如何将CGI应用迁移到现代的Web框架,以充分利用框架提供的更多功能和更好的性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【LAMMPS初探】:如何快速入门并掌握基本模拟操作

# 摘要
LAMMPS模拟软件因其在分子动力学领域的广泛应用而著称,本文提供了关于如何安装、配置和使用LAMMPS进行基本和高级模拟操作的全面指南。文章首先介绍了LAMMPS的系统环境要求、安装流程以及配置选项,并详细说明了运行环境的设置方法。接着,重点介绍了LAMMPS进行基本模拟操作的核心步骤,包括模拟体系的搭建、势能的选择与计算,以及模拟过程的控制。此外,还探讨了高级模拟技术,如分子动力学进阶应用
安全第一:ELMO驱动器运动控制安全策略详解

# 摘要
ELMO驱动器作为运动控制领域内的关键组件,其安全性能的高低直接影响整个系统的可靠性和安全性。本文首先介绍了ELMO驱动器运动控制的基础知识,进而深入探讨了运动控制系统中的安全理论,包括安全运动控制的定义、原则、硬件组件的作用以及软件层面的安全策略实现。第三章到第五章详细阐述了ELMO驱动器安全功能的实现、案例分析以及实践指导,旨在为技术人
编程新手福音:SGM58031B编程基础与接口介绍

# 摘要
SGM58031B是一款具有广泛编程前景的设备,本文首先对其进行了概述并探讨了其编程的应用前景。接着,详细介绍了SGM58031B的编程基础,包括硬件接口解析、编程语言选择及环境搭建,以及基础编程概念与常用算法的应用。第三章则着重于软件接口和驱动开发,阐述了库文件与API接口、驱动程序的硬件交互原理,及驱动开发的具体流程和技巧。通过实际案例
【流程标准化实战】:构建一致性和可复用性的秘诀

# 摘要
本文系统地探讨了流程标准化的概念、重要性以及在企业级实践中的应用。首先介绍了流程标准化的定义、原则和理论基础,并分析了实现流程标准化所需的方法论和面临的挑战。接着,本文深入讨论了流程标准化的实践工具和技术,包括流程自动化工具的选择、模板设计与应用,以及流程监控和质量保证的策略。进一步地,本文探讨了构建企业级流程标准化体系的策略,涵盖了组织结构的调整、标准化实施
【ER图设计速成课】:从零开始构建保险公司全面数据模型
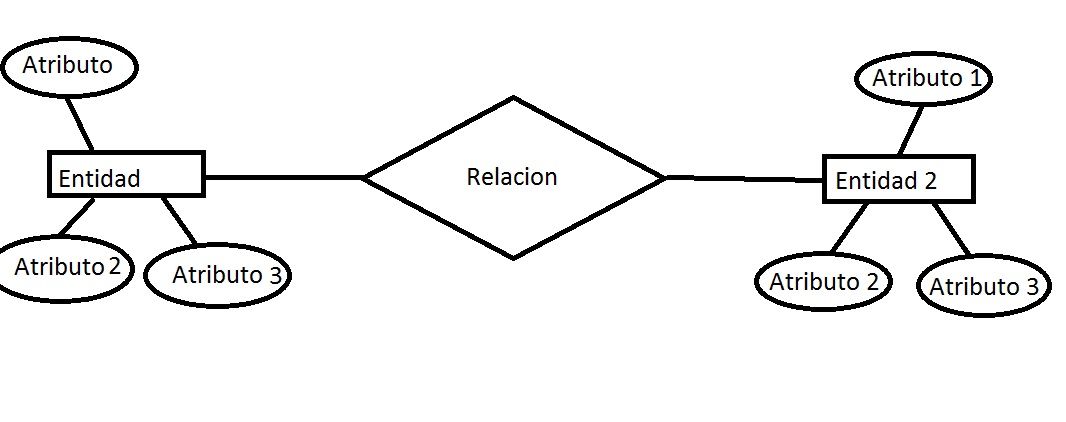
# 摘要
本文详细介绍了实体-关系图(ER图)在保险公司业务流程中的设计和应用。通过理解保险业务流程,识别业务实体与关系,并在此基础上构建全面的数据模型,本文阐述了ER图的基本元素、规范化处理、以及优化调整的策略。文章还讨论了ER图设计实践中的详细实体设计、关系实现和数据模型文档化方法。此外,本文探讨了ER图在数据库设计中的应用,包括ER图到数据库结构的映射、
揭秘Renewal UI:3D技术如何重塑用户体验
![[Renewal UI] Chapter4_3D Inspector.pdf](https://habrastorage.org/getpro/habr/upload_files/bd2/ffc/653/bd2ffc653de64f289cf726ffb19cec69.png)
# 摘要
本文首先介绍了Renewal UI的创新特点及其在三维(3D)技术中的应用。随后,深入探讨了3D技术的基础知识,以及它在用户界面(UI)设计中的作用,包括空间几何、纹理映射、交互式元素设计等。文中分析了Renewal UI在实际应用中的案例,如交互设计实践、用户体验定性分析以及技术实践与项目管理。此外,
【信息化系统建设方案编写入门指南】:从零开始构建你的第一个方案

# 摘要
信息化系统建设是现代企业提升效率和竞争力的关键途径。本文对信息化系统建设进行了全面概述,从需求分析与收集方法开始,详细探讨了如何理解业务需求并确定需求的优先级和范围,以及数据收集的技巧和分析工具。接着,本文深入分析了系统架构设计原则,包括架构类型的确定、设计模式的运用,以及安全性与性能的考量。在实施与部署方面,本文提供了制定实施计划、部署策
【多核与并行构建】:cl.exe并行编译选项及其优化策略,加速构建过程
# 摘要
本文系统地介绍了多核与并行构建的基础知识,重点探讨了cl.exe编译器在多核并行编译中的理论基础和实践
中文版ARINC653:简化开发流程,提升航空系统软件效率

# 摘要
ARINC653标准作为一种航空系统软件架构,提供了模块化设计、时间与空间分区等关键概念,以增强航空系统的安全性和可靠性。本文首先介绍了ARINC653的定义、发展、模块化设计原则及其分区机制的理论基础。接着,探讨了ARINC653的开发流程、所需开发环境和工具,以及实践案例分析。此外,本文还分析了ARINC653在航空系统中的具体应用、软件效率提升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )