Jupyter实战:数据清洗与预处理
发布时间: 2024-05-02 21:18:29 阅读量: 662 订阅数: 58 

一个基于Qt Creator(qt,C++)实现中国象棋人机对战
# 1. Jupyter简介**
Jupyter Notebook 是一个交互式计算环境,专为数据科学和机器学习而设计。它允许用户创建和共享文档,其中包含代码、文本、方程式和可视化效果。
Jupyter Notebook 的主要特点包括:
* **交互性:**用户可以逐行运行代码,并立即查看结果。
* **文档化:**Notebook 可以包含代码、文本和可视化效果,从而为项目提供完整的文档。
* **可共享性:**Notebook 可以轻松地与他人共享,促进协作和知识共享。
* **丰富的扩展性:**Jupyter Notebook 支持多种语言和库,使其适用于广泛的数据科学和机器学习任务。
# 2. 数据清洗基础
### 2.1 数据清洗的概念和目的
数据清洗是数据预处理过程中的重要步骤,旨在识别并纠正数据中的错误、缺失值和不一致性,以确保数据的准确性和完整性。数据清洗的目的是:
- **提高数据质量:**消除数据中的错误和不一致性,提高数据的可信度和可靠性。
- **提高数据分析效率:**干净的数据可以简化数据分析过程,减少因数据质量问题而导致的错误和偏差。
- **支持决策制定:**准确可靠的数据是决策制定和业务规划的基础,数据清洗可以确保决策基于高质量的信息。
### 2.2 数据清洗的步骤和方法
数据清洗是一个多步骤的过程,通常包括以下步骤:
1. **数据探索:**了解数据的结构、类型和分布,识别潜在的数据质量问题。
2. **数据清洗:**使用各种技术和方法纠正数据中的错误和不一致性。
3. **数据验证:**验证数据清洗的结果,确保数据质量已得到改善。
数据清洗的方法包括:
- **手动清洗:**使用数据编辑工具或电子表格手动识别和纠正错误。
- **自动清洗:**使用算法和工具自动检测和纠正数据中的错误。
- **规则清洗:**定义规则来识别和处理数据中的异常值或不一致性。
- **统计清洗:**使用统计技术识别数据中的异常值或缺失值。
# 3. 数据清洗实践
### 3.1 缺失值处理
#### 3.1.1 缺失值类型
缺失值是指数据集中缺失或未知的值,主要分为以下类型:
- **完全缺失值 (MCAR)**:缺失值是完全随机的,与其他变量无关。
- **随机缺失值 (MAR)**:缺失值是随机的,但与其他变量相关。
- **非随机缺失值 (MNAR)**:缺失值不是随机的,并且与其他变量存在非随机关系。
#### 3.1.2 缺失值处理方法
根据缺失值类型的不同,有以下处理方法:
- **删除缺失值**:适用于完全缺失值或样本量较大的情况。
- **均值/中位数填充**:适用于随机缺失值,用变量的均值或中位数填充缺失值。
- **K-最近邻填充**:适用于非随机缺失值,用与缺失值最相似的K个样本的均值或中位数填充缺失值。
- **多重插补**:适用于非随机缺失值,通过多次随机插补生成多个数据集,然后对结果取平均。
### 3.2 异常值处理
#### 3.2.1 异常值检测
异常值是指与其他数据点明显不同的值,可能由数据错误、测量误差或异常事件引起。检测异常值的方法包括:
- **箱形图**:异常值通常位于箱形图的须须之外。
- **Z-分数**:计算每个数据点的Z-分数,绝对值大于3的点可能为异常值。
- **孤立森林**:一种无监督学习算法,可以识别孤立点和异常值。
#### 3.2.2 异常值处理方法
处理异常值的方法包括:
- **删除异常值**:适用于异常值明显且不代表数据分布的情况。
- **Winsorization**:将异常值截断到指定的分位数,例如5%或95%。
- **替换异常值**:用其他方法(如均值或中位数)替换异常值。
### 3.3 数据标准化
#### 3.3.1 数据标准化的目的
数据标准化旨在消除不同变量之间的单位和尺度差异,使其具有可比性。主要目的是:
- 提高模型训练的效率和准确性。
- 避免某些变量在模型中占据过大权重。
- 促进不同数据集的比较和合并。
#### 3.3.2 数据标准化方法
常用的数据标准化方法包括:
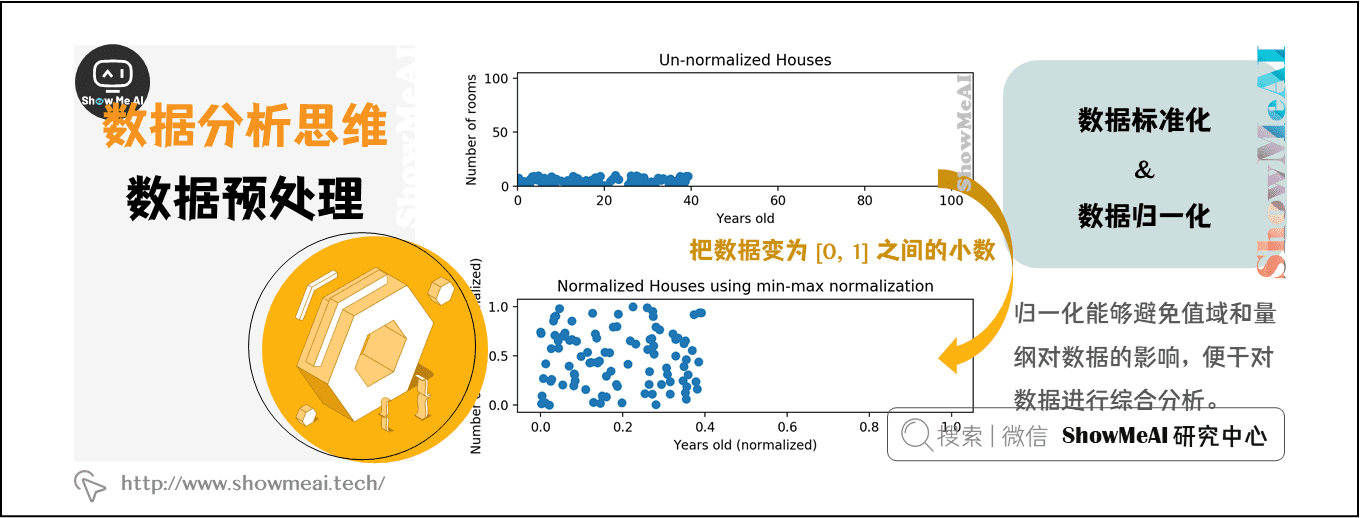
- **最小-最大标准化**:将数据转换到[0, 1]的范围内。
- **Z-分数标准化**:将数据转换为均值为0、标准差为1的分布。
- **小数定标**:将数据除以其最大值或最小值。
```python
import numpy as np
# 最小-最大标准化
data = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
normalized_data = (data - np.min(data)) / (np.max(data) - np.min(data))
# Z-分数标准化
normalized_data = (data - np.mean(data)) / np.std(data)
# 小数定标
normalized_data = data / np.max(data)
```
# 4. 数据预处理**
数据预处理是数据挖掘和机器学习过程中不可或缺的一环,其目的是将原始数据转换为适合建模和分析的格式。本章将深入探讨数据预处理的三个主要方面:数据转换、数据特征工程和数据降维。
**4.1 数据转换**
数据转换是指将数据从一种格式或类型转换为另一种格式或类型。这通常涉及以下两个方面:
**4.1.1 数据类型转换**
数据类型转换是指将数据从一种数据类型转换为另一种数据类型。例如,将字符串转换为数字、将日期转换为时间戳等。Python 中提供了多种函数来执行数据类型转换,例如 `int()`, `float()`, `str()` 等。
```python
# 将字符串转换为数字
age_str = "25"
age_int = int(age_str)
print(age_int) # 输出:25
```
**4.1.2 数据格式转换**
数据格式转换是指将数据从一种格式转换为另一种格式。例如,将 CSV 文件转换为 Excel 文件、将 JSON 文件转换为 DataFrame 等。Python 中提供了多种库来执行数据格式转换,例如 `pandas`, `csv`, `json` 等。
```python
import pandas as pd
# 将 CSV 文件转换为 DataFrame
df = pd.read_csv("data.csv")
print(df.head())
```
**4.2 数据特征工程**
数据特征工程是数据预处理中至关重要的一步,其目的是从原始数据中提取出对建模和分析有用的特征。这通常涉及以下两个方面:
**4.2.1 特征选择**
特征选择是指从原始数据中选择出与目标变量相关性较高的特征。这可以提高模型的性能,减少过拟合的风险。Python 中提供了多种算法来执行特征选择,例如 `SelectKBest`, `SelectPercentile`, `L1FeatureSelector` 等。
```python
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# 使用卡方检验选择前 10 个特征
selector = SelectKBest(chi2, k=10)
selected_features = selector.fit_transform(X, y)
print(selected_features.shape) # 输出:(n_samples, 10)
```
**4.2.2 特征提取**
特征提取是指从原始数据中提取出新的特征,这些特征可能比原始特征更能代表数据的内在结构。这可以提高模型的泛化能力,避免过拟合。Python 中提供了多种算法来执行特征提取,例如 `PCA`, `LDA`, `TfidfVectorizer` 等。
```python
from sklearn.decomposition import PCA
# 使用 PCA 提取 2 个主成分
pca = PCA(n_components=2)
transformed_features = pca.fit_transform(X)
print(transformed_features.shape) # 输出:(n_samples, 2)
```
**4.3 数据降维**
数据降维是指将高维数据转换为低维数据,同时保留原始数据的关键信息。这可以减少计算成本,提高模型的效率。Python 中提供了多种算法来执行数据降维,例如 `PCA`, `LDA`, `t-SNE` 等。
```python
from sklearn.decomposition import PCA
# 使用 PCA 将数据降维到 2 维
pca = PCA(n_components=2)
transformed_features = pca.fit_transform(X)
print(transformed_features.shape) # 输出:(n_samples, 2)
```
**总结**
数据预处理是数据挖掘和机器学习过程中不可或缺的一环,其目的是将原始数据转换为适合建模和分析的格式。本章介绍了数据预处理的三个主要方面:数据转换、数据特征工程和数据降维。通过理解和应用这些技术,可以提高模型的性能,减少过拟合的风险,并提高模型的效率。
# 5. Jupyter实战案例
### 5.1 数据清洗实战
**案例描述:**
我们使用Jupyter来处理一份包含客户信息的CSV文件。该文件包含缺失值、异常值和格式不一致的数据。我们的目标是使用Jupyter中的数据清洗工具来清理数据,以便为后续分析做好准备。
**步骤:**
1. **导入数据:**
```python
import pandas as pd
df = pd.read_csv('customer_data.csv')
```
2. **检查数据:**
```python
df.info()
```
输出:
```
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000 entries, 0 to 999
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 1000 non-null int64
1 name 950 non-null object
2 age 980 non-null float64
3 city 990 non-null object
4 salary 970 non-null float64
dtypes: float64(2), int64(1), object(2)
memory usage: 40.0 KB
```
3. **处理缺失值:**
```python
# 填充缺失的姓名值
df['name'].fillna('Unknown', inplace=True)
# 填充缺失的年龄值
df['age'].fillna(df['age'].mean(), inplace=True)
# 填充缺失的城市值
df['city'].fillna('Unknown', inplace=True)
# 填充缺失的工资值
df['salary'].fillna(df['salary'].median(), inplace=True)
```
4. **处理异常值:**
```python
# 检测年龄异常值
outliers = df['age'] > 100
df.loc[outliers, 'age'] = df['age'].median()
# 检测工资异常值
outliers = df['salary'] > 100000
df.loc[outliers, 'salary'] = df['salary'].median()
```
5. **标准化数据:**
```python
# 将城市列转换为小写
df['city'] = df['city'].str.lower()
# 将工资列转换为整数
df['salary'] = df['salary'].astype(int)
```
### 5.2 数据预处理实战
**案例描述:**
我们使用Jupyter来预处理一份包含客户交易数据的CSV文件。该文件包含大量特征,我们需要选择和提取有价值的特征,并对数据进行降维。
**步骤:**
1. **特征选择:**
```python
# 使用相关性矩阵来识别相关特征
corr = df.corr()
# 根据相关性阈值选择特征
selected_features = corr.loc[:, (corr['target'] > 0.5) & (corr['target'] < 1)].index
```
2. **特征提取:**
```python
# 使用PCA进行特征提取
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
df_pca = pca.fit_transform(df[selected_features])
```
3. **数据降维:**
```python
# 使用t-SNE进行数据降维
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2)
df_tsne = tsne.fit_transform(df_pca)
```
# 6. 总结与展望
### 总结
Jupyter Notebook 作为一种交互式数据分析工具,在数据清洗和预处理方面展现出强大的优势。通过本文的介绍,我们了解了 Jupyter Notebook 的基本概念、数据清洗的基础知识和实践方法,以及数据预处理的常用技术。
### 展望
随着大数据时代的到来,数据清洗和预处理的重要性日益凸显。Jupyter Notebook 作为一种灵活且易于使用的工具,将在未来数据处理领域继续发挥重要作用。以下是一些展望:
* **自动化数据清洗:**开发自动化数据清洗算法,减少人工干预,提高效率。
* **云端数据清洗:**将数据清洗任务迁移到云平台,利用云计算的强大算力,处理海量数据。
* **深度学习辅助数据清洗:**利用深度学习技术,识别和处理复杂异常值和缺失值。
* **数据清洗可视化:**提供交互式数据清洗可视化工具,直观展示数据分布和清洗效果。
### 结束语
Jupyter Notebook 在数据清洗和预处理领域具有广阔的应用前景。随着技术的发展和创新,Jupyter Notebook 将继续为数据科学家和分析师提供强大的工具,帮助他们高效地处理和分析数据,从而获得有价值的见解。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Jupyter Notebook指南》专栏全面介绍了Jupyter Notebook的使用技巧和应用场景。从基础操作到高级应用,涵盖数据清洗、可视化分析、机器学习训练、数据挖掘、文本分析、交互式可视化、大数据处理、实时数据分析、数据异常检测、模型评估、深度学习应用、大数据集成、文本数据挖掘、机器学习部署、图像处理、自然语言处理、实时数据监控等多个方面。该专栏旨在帮助读者充分利用Jupyter Notebook的强大功能,提升数据分析、机器学习和数据挖掘的效率和效果。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【靶机环境侦察艺术】:高效信息搜集与分析技巧

# 摘要
本文深入探讨了靶机环境侦察的艺术与重要性,强调了在信息搜集和分析过程中的理论基础和实战技巧。通过对侦察目标和方法、信息搜集的理论、分析方法与工具选择、以及高级侦察技术等方面的系统阐述,文章提供了一个全面的靶机侦察框架。同时,文章还着重介绍了网络侦察、应用层技巧、数据包分析以及渗透测试前的侦察工作。通过案例分析和实践经验分享,本文旨在为安全专业人员提供实战指导,提升他们在侦察阶段的专业
【避免数据损失的转换技巧】:在ARM平台上DWORD向WORD转换的高效方法

# 摘要
本文对ARM平台下DWORD与WORD数据类型进行了深入探讨,从基本概念到特性差异,再到高效转换方法的理论与实践操作。在基础概述的基础上,文章详细分析了两种数据类型在ARM架构中的表现以及存储差异,特别是大端和小端模式下的存储机制。为了提高数据处理效率,本文提出了一系列转换技巧,并通过不同编程语言实
高速通信协议在FPGA中的实战部署:码流接收器设计与优化
# 摘要
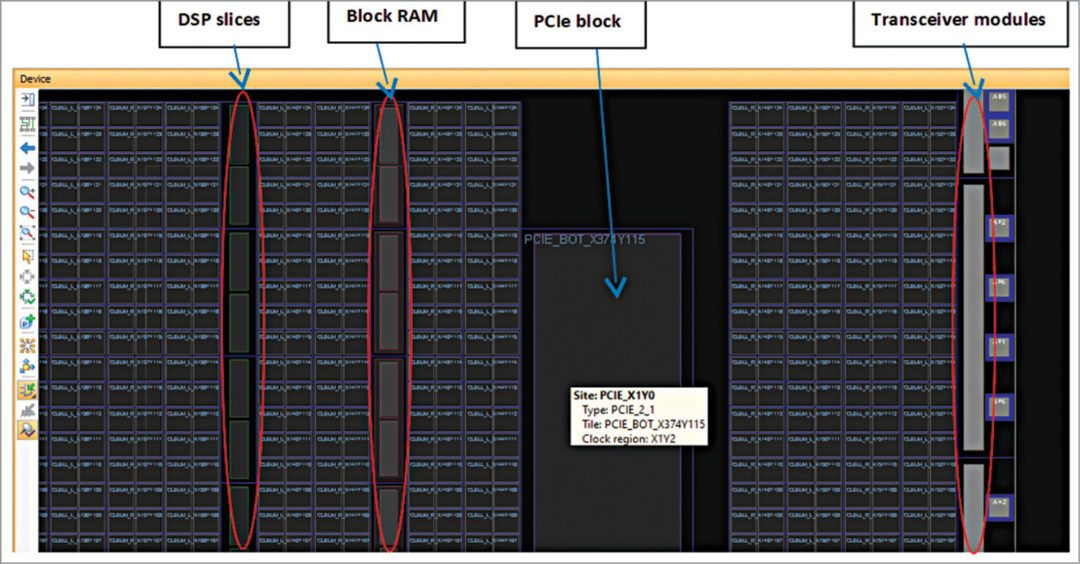
高速通信协议在现代通信系统中扮演着关键角色,本文详细介绍了高速通信协议的基础知识,并重点阐述了FPGA(现场可编程门阵列)中码流接收器的设计与实现。文章首先概述了码流接收器的设计要求与性能指标,然后深入讨论了硬件描述语言(HDL)的基础知识及其在FPGA设计中的应用,并探讨了FPGA资源和接口协议的选择。接着,文章通过码流接收器的硬件设计和软件实现,阐述了实践应用中的关键设计要点和性能优化方法。第
贝塞尔曲线工具与插件使用全攻略:提升设计效率的利器
# 摘要
贝塞尔曲线是图形设计和动画制作中广泛应用的数学工具,用于创建光滑的曲线和形状。本文首先概述了贝塞尔曲线工具与插件的基本概念,随后深入探讨了其理论基础,包括数学原理及在设计中的应用。文章接着介绍了常用贝塞尔曲线工具
CUDA中值滤波秘籍:从入门到性能优化的全攻略(基础概念、实战技巧与优化策略)

# 摘要
本论文旨在探讨CUDA中值滤波技术的入门知识、理论基础、实战技巧以及性能优化,并展望其未来的发展趋势和挑战。第一章介绍CUDA中值滤波的基础知识,第二章深入解析中值滤波的理论和CUDA编程基础,并阐述在CUDA平台上实现中值滤波算法的技术细节。第三章着重讨论CUDA中值滤波的实战技巧,包括图像预处理与后处理
深入解码RP1210A_API:打造高效通信接口的7大绝技

# 摘要
本文系统地介绍了RP1210A_API的架构、核心功能和通信协议。首先概述了RP1210A_API的基本概念及版本兼容性问题,接着详细阐述了其通信协议框架、数据传输机制和错误处理流程。在此基础上,文章转入RP1210A_API在开发实践中的具体应用,包括初始化、配置、数据读写、传输及多线程编程等关键点。文中还提供多个应用案例,涵盖车辆诊断工具开发、嵌入式系统集成以及跨平台通
【终端快捷指令大全】:日常操作速度提升指南
# 摘要
终端快捷指令作为提升工作效率的重要工具,其起源与概念对理解其在不同场景下的应用至关重要。本文详细探讨了终端快捷指令的使用技巧,从基础到高级应用,并提供了一系列实践案例来说明快捷指令在文件处理、系统管理以及网络配置中的便捷性。同时,本文还深入讨论了终端快捷指令的进阶技巧,包括自动化脚本的编写与执行,以及快捷指令的自定义与扩展。通过分析终端快捷指令在不同用户群体中的应用
电子建设工程预算动态管理:案例分析与实践操作指南

# 摘要
电子建设工程预算的动态管理是指在项目全周期内,通过实时监控和调整预算来优化资源分配和控制成本的过程。本文旨在综述动态管理在电子建设工程预算中的概念、理论框架、控制实践、案例分析以及软件应用。文中首先界定了动态管理的定义,阐述了其重要性,并与静态管理进行了比较。随后,本文详细探讨了预算管理的基本原则,并
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )