【Go语言性能优化】:利用Context包,构建可扩展的Web服务
发布时间: 2024-10-19 20:41:18 阅读量: 27 订阅数: 24 

go语言服务器练习项目
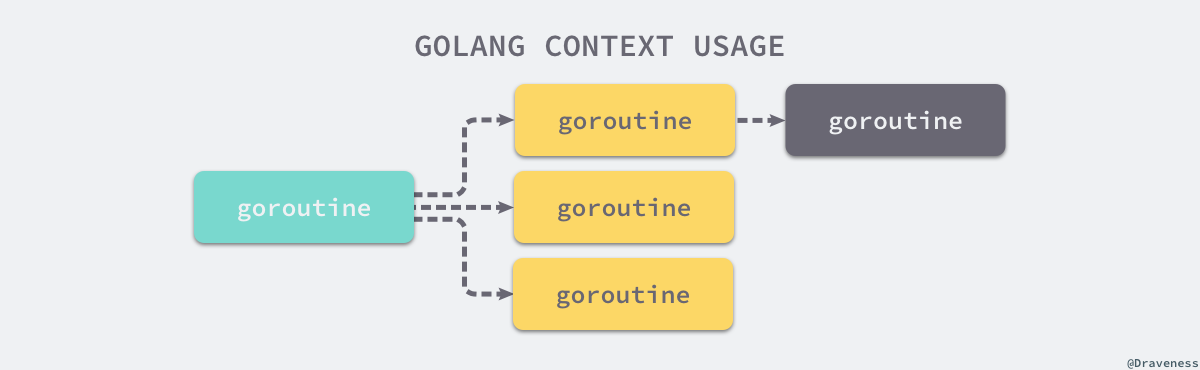
# 1. Go语言与Web服务性能优化基础
## 1.1 Web服务性能优化的重要性
Web服务的性能优化是确保应用响应迅速、资源利用高效的关键。对于使用Go语言构建Web服务的开发者来说,了解性能优化的基本原则是提升服务质量、增强用户体验的重要前提。
## 1.2 Go语言的并发优势
Go语言以其原生支持并发的特性而闻名,这为Web服务的性能优化提供了得天独厚的优势。通过高效地管理和调度goroutines,Go语言能够构建出高性能的Web服务。
## 1.3 性能优化的初步实践
性能优化可以从多个层面展开,例如代码层面的算法优化、数据结构的选择,到系统层面的并发策略和网络通信。在Go语言中,合理的内存管理和并发控制是实现高效Web服务性能优化的基础。
性能优化是持续的过程,需要结合实际应用场景,持续地监控、评估和调整服务性能。本章将为您提供Go语言与Web服务性能优化的基础知识,为深入学习后续章节打下坚实的基础。
# 2. 深入理解Go语言的Context包
Go语言的Context包是用于在goroutine之间传递请求范围的值、取消信号以及处理截止日期的同步原语,它在构建Web服务时起着至关重要的作用。本章将深入剖析Context包的各个方面,以及如何在不同的场景下高效利用Context。
## 2.1 Context包的概念与设计
### 2.1.1 Context的用途与优势
在Web服务中,每个请求都可能产生多个goroutine进行并发处理,而Context正是用来管理这些goroutine中的请求相关值、处理取消信号以及截止日期的机制。使用Context,开发者可以确保请求相关的goroutine在适当的时候能够准确地响应取消信号,同时传递请求相关的值,如认证令牌、请求ID等。
使用Context的优势显而易见:
- **取消信号:** 当一个请求被取消或超时时,所有的goroutine和子goroutine都应该被优雅地停止,以避免资源浪费。
- **传递请求信息:** Context能够传递请求范围内的信息,如身份验证数据、请求特定的配置等,而无需使用全局变量。
- **确保资源清理:** 可以在Context中集成资源清理的逻辑,确保在请求结束时执行。
### 2.1.2 Context接口详解
Context接口提供了一些关键的方法,让我们逐个分析:
- **Done():** 返回一个channel,该channel在接收一个关闭信号时用于通知调用者,或者当context被取消时关闭,用于goroutine同步。
- **Err():** 返回一个错误值,指示Context被取消的原因,如果Context没有被取消,则返回nil。
- **Deadline():** 返回当前Context期望完成的截止日期,有助于设置超时逻辑。
- **Value():** 从Context中检索与key相关联的value,该值可由context.WithValue传递。
代码示例:
```go
package main
import (
"context"
"fmt"
"time"
)
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 100*time.Millisecond)
defer cancel()
select {
case <-ctx.Done():
fmt.Println("time out:", ctx.Err())
}
}
```
本节内容中,我们介绍了Context包的基本概念和优势,接下来将深入探索Context的生命周期管理。
## 2.2 Context的生命周期管理
### 2.2.1 Context的创建与传递
Context的创建通常从context.Background()或context.TODO()开始,这两个函数提供了一个空的Context,适合在程序的顶层开始。对于每个goroutine,应该创建一个派生的Context来跟踪goroutine的取消信号和截止时间。
Context的传递通常通过函数参数进行,对于Web服务,Context通常作为第一个参数传递给每个处理函数:
```go
func myHandler(ctx context.Context, w http.ResponseWriter, r *http.Request) {
// Handler implementation
}
```
### 2.2.2 Context的取消与超时处理
Context支持取消操作,通常这与请求的生命周期相关。如果请求被取消或达到了预设的超时时间,相关的goroutine应该立即停止执行。Context提供了WithCancel和WithTimeout函数来创建可以被取消的子Context。
```go
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
c := newCancelCtx(parent)
propagateCancel(parent, &c)
return &c, func() { c.cancel(true, Canceled) }
}
```
### 2.2.3 Context的超时管理
在Web服务中,处理超时是一个常见的需求。通过WithTimeout函数,我们可以创建一个具有指定超时时间的Context。如果处理函数运行时间超过了超时时间,将会接收一个超时错误。
```go
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
ctx, cancel := context.WithDeadline(parent, time.Now().Add(timeout))
return ctx, cancel
}
```
我们将在后续的小节中深入探讨Context的并发控制。
## 2.3 Context的并发控制
### 2.3.1 使用Context控制goroutine
在Web服务中,常常需要启动多个goroutine来并发处理不同的任务。正确地管理这些goroutine的生命周期和同步对于性能优化至关重要。Context提供了一种优雅的方式来控制goroutine的启动和结束。
当调用Context的Done()方法返回的channel关闭时,goroutine可以结束执行。这使得我们可以在多个goroutine之间共享一个取消信号,从而当一个goroutine决定退出时,可以触发其他goroutine的退出。
示例代码:
```go
func worker(ctx context.Context) {
// Doing some work
}
func runWorkers(ctx context.Context) {
for i := 0; i < 10; i++ {
go worker(ctx)
}
// ...other work
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
go runWorkers(ctx)
// ...after some time, if needed, cancel the context
cancel()
}
```
### 2.3.2 Context与信号处理
Context同样可以与操作系统信号结合使用,以便在接收到如SIGINT、SIGTERM等信号时优雅地关闭程序。例如,可以在接收到终止信号时,创建一个可取消的Context来协调程序的退出。
示例代码:
```go
func signalHandler(ctx context.Context, sigChan <-chan os.Signal) {
select {
case <-ctx.Done():
// The application is shutting down
case sig := <-sigChan:
// Handle the signal
fmt.Println("Received signal", sig)
cancel() // Signal the context to cancel
}
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, syscall.SIGINT, syscall.SIGTERM)
go signalHandler(ctx, sigChan)
// ...main program execution
}
```
在这部分,我们介绍了Context的生命周期管理以及如何利用Context进行并发控制。接下来,我们将继续探讨Context在Web服务性能优化中的具体应用。
# 3. ```
# 第三章:构建高性能Web服务的实践策略
构建高性能的Web服务不仅仅是一个理论问题,它涉及到具体实现的技术和策略。在本章中,我们将深入探讨如何通过性能基准测试和针对性的优化策略来构建高性能的Web服务。同时,我们也将关注如何提高服务的可扩展性,以适应不断增长的负载和用户需求。
## 3.1 Web服务的性能基准测试
在优化Web服务之前,首先需要了解当前服务的性能状况。性能基准测试就是评估Web服务性能的一种方法。它涉及使用各种工具对Web服务在特定条件下的响应时间、吞吐量以及资源消耗等指标进行测试。
### 3.1.1 常用的性能测试工具与方法
在众多性能测试工具中,Apache JMeter和Gatling是两个流行的选择。它们能够模拟多个用户同时向Web服务发起请求,并收集性能数据。
- **Apache JMeter**:是一个开源的性能测试工具,适用于静态和动态资源、Web动态应用程序。它能够测试各种不同负载下的服务器、网络或对象的表现。
- **Gatling**:是一个先进的自动化性能测试工具,特别适合于负载测试,它使用Scala编写,并且可以轻松地集成到持续集成流程中。
这些工具不仅能够帮助我们识别服务在高负载下的性能瓶颈,而且还可以通过模拟真实场景来测试服务的稳定性和可靠性。
### 3.1.2 分析性能瓶颈
性能测试完成后,接下来是分析测试结果,并找到可能的性能瓶颈。这可能涉及到数据库查询优化、缓存策略、服务器资源分配等。
- **数据库查询优化**:通过慢查询日志或性能分析工具来查找执行缓慢的查询,并进行优化。
- **缓存策略**:考虑引入内存缓存(如Redis)来减少数据库访问次数,降低延迟。
- **服务器资源分配**:分析服务器的CPU、内存、网络使用情况,对资源进行合理分配和优化。
## 3.2 利用Context优化Web服务性能
Go语言的`context`包提供了一种控制goroutine和
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Go语言的Context包是一个强大的工具,可用于管理并发、避免goroutine泄漏、优化性能、构建可扩展的Web服务和实现高可用服务。本专栏深入探讨了Context包的各个方面,包括12个实用技巧、6个避免goroutine泄漏的策略、3种高效传递数据的方法、与Channels的对比、工作原理、大型系统中的应用、错误管理技巧、资源释放最佳实践、select和channel的深入解析以及分组请求处理技巧。通过掌握Context包,Go开发人员可以构建健壮、高效和可扩展的并发应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【概率论与数理统计:工程师的实战解题宝典】:揭示习题背后的工程应用秘诀

# 摘要
本文从概率论与数理统计的角度出发,系统地介绍了其基本概念、方法与在工程实践中的应用。首先概述了概率论与数理统计的基础知识,包括随机事件、概率计算以及随机变量的数字特征。随后,重点探讨了概率分布、统计推断、假设检验
【QSPr参数深度解析】:如何精确解读和应用高通校准综测工具

# 摘要
QSPr参数是用于性能评估和优化的关键工具,其概述、理论基础、深度解读、校准实践以及在系统优化中的应用是本文的主题。本文首先介绍了QSPr工具及其参数的重要性,然后详细阐述了参数的类型、分类和校准理论。在深入解析核心参数的同时,也提供了参数应用的实例分析。此外,文章还涵盖了校准实践的全过程,包括工具和设备准备、操作流程以及结果分析与优化。最终探讨了QSPr参数在系统优化中的
探索自动控制原理的创新教学方法

# 摘要
本文深入探讨了自动控制理论在教育领域中的应用,重点关注理论与教学内容的融合、实践教学案例的应用、教学资源与工具的开发、评估与反馈机制的建立以
Ubuntu 18.04图形界面优化:Qt 5.12.8性能调整终极指南

# 摘要
本文全面探讨了Ubuntu 18.04系统中Qt 5.12.8图形框架的应用及其性能调优。首先,概述了Ubuntu 18.04图形界面和Qt 5.12.8核心组件。接着,深入分析了Qt的模块、事件处理机制、渲染技术以及性能优化基
STM32F334节能秘技:提升电源管理的实用策略
# 摘要
本文全面介绍了STM32F334微控制器的电源管理技术,包括基础节能技术、编程实践、硬件优化与节能策略,以及软件与系统级节能方案。文章首先概述了STM32F334及其电源管理模式,随后深入探讨了低功耗设计原则和节能技术的理论基础。第三章详细阐述了RTOS在节能中的应用和中断管理技巧,以及时钟系统的优化。第四章聚焦于硬件层面的节能优化,包括外围设备选型、电源管
【ESP32库文件管理】:Proteus中添加与维护技术的高效策略
# 摘要
本文旨在全面介绍ESP32微控制器的库文件管理,涵盖了从库文件基础到实践应用的各个方面。首先,文章介绍了ESP32库文件的基础知识,包括库文件的来源、分类及其在Proteus平台的添加和配置方法。接着,文章详细探讨了库文件的维护和更新流程,强调了定期检查库文件的重要性和更新过程中的注意事项。文章的第四章和第五章深入探讨了ESP3
【实战案例揭秘】:遥感影像去云的经验分享与技巧总结

# 摘要
遥感影像去云技术是提高影像质量与应用价值的重要手段,本文首先介绍了遥感影像去云的基本概念及其必要性,随后深入探讨了其理论基础,包括影像分类、特性、去云算法原理及评估指标。在实践技巧部分,本文提供了一系列去云操作的实际步骤和常见问题的解决策略。文章通过应用案例分析,展示了遥感影像去云技术在不同领域中的应用效果,并对未来遥感影像去云技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )