JSON数据库入门指南:解析JSON数据结构与操作基础,开启你的JSON之旅
发布时间: 2024-07-29 10:06:35 阅读量: 40 订阅数: 48 

Python中处理JSON数据:解析与生成指南
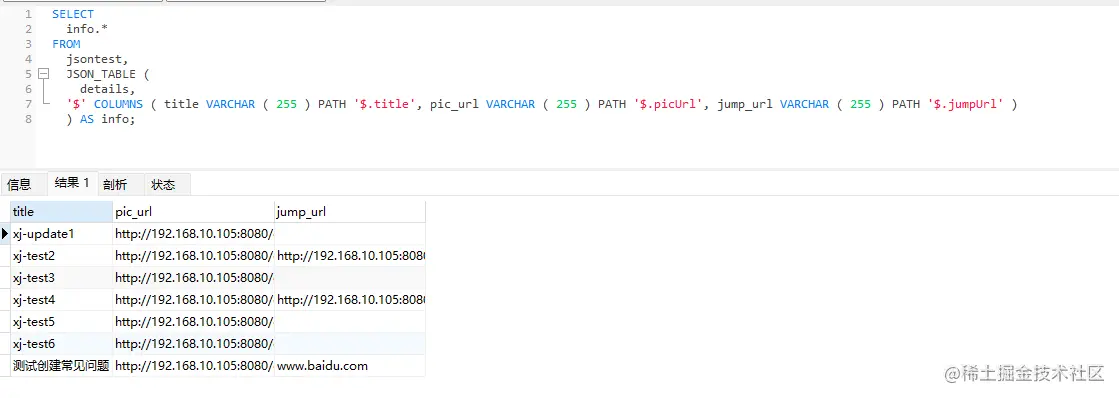
# 1. JSON数据库概述**
JSON数据库是一种以JSON(JavaScript Object Notation)格式存储和管理数据的数据库。它具有轻量级、灵活性和可扩展性等优点,适用于存储半结构化或非结构化数据。
JSON数据库使用JSON格式来表示数据,该格式是一种基于文本的、轻量级的、可读性高的数据交换格式。它使用键值对的形式来组织数据,键是字符串,值可以是字符串、数字、布尔值、数组或其他JSON对象。
JSON数据库的结构灵活,可以根据数据的实际情况进行调整。它支持嵌套数据结构,允许在单个文档中存储复杂的数据关系。这种灵活性使得JSON数据库特别适合于存储和管理不断变化或未知结构的数据。
# 2. JSON数据结构与操作基础
### 2.1 JSON数据结构解析
#### 2.1.1 JSON对象与数组
JSON数据结构主要由两种基本类型组成:对象和数组。
- **对象:**由键值对组成的无序集合,键为字符串,值可以是任意数据类型。
- **数组:**由元素组成的有序集合,元素可以是任意数据类型。
**代码块:**
```json
{
"name": "John Doe",
"age": 30,
"occupation": "Software Engineer"
}
```
**代码逻辑解读:**
这是一个JSON对象,包含三个键值对:`name`、`age`和`occupation`。
#### 2.1.2 JSON数据的层级结构
JSON数据可以具有复杂的层级结构,其中对象和数组可以嵌套在其他对象或数组中。
**代码块:**
```json
{
"name": "John Doe",
"address": {
"street": "123 Main Street",
"city": "Anytown",
"state": "CA",
"zip": "12345"
}
}
```
**代码逻辑解读:**
这是一个JSON对象,包含一个名为`address`的嵌套对象。`address`对象又包含四个键值对,表示用户的地址信息。
### 2.2 JSON数据操作
#### 2.2.1 数据的读取与解析
在JavaScript中,可以使用`JSON.parse()`方法将JSON字符串解析为JavaScript对象。
**代码块:**
```javascript
const jsonStr = '{"name": "John Doe", "age": 30}';
const jsonObject = JSON.parse(jsonStr);
```
**代码逻辑解读:**
`JSON.parse()`方法将`jsonStr`中的JSON字符串解析为一个JavaScript对象`jsonObject`。
#### 2.2.2 数据的增删改查
**插入:**使用`Object.assign()`方法或直接赋值来插入新键值对。
**代码块:**
```javascript
jsonObject.occupation = "Software Engineer";
```
**删除:**使用`delete`操作符来删除键值对。
**代码块:**
```javascript
delete jsonObject.age;
```
**修改:**直接修改键值对的值。
**代码块:**
```javascript
jsonObject.name = "Jane Doe";
```
**查询:**使用点号或方括号语法访问键值对。
**代码块:**
```javascript
const name = jsonObject.name;
const age = jsonObject["age"];
```
# 3.1 JSON数据库的搭建
#### 3.1.1 选择合适的JSON数据库引擎
选择合适的JSON数据库引擎是搭建JSON数据库的关键一步。目前市面上主流的JSON数据库引擎包括MongoDB、CouchDB和ArangoDB等。
**MongoDB**:MongoDB是一个文档型数据库,具有高性能、高可扩展性和丰富的查询功能。它支持JSON数据模型,并提供灵活的查询语言,可以方便地对JSON数据进行操作。
**CouchDB**:CouchDB是一个面向文档的NoSQL数据库,支持JSON数据模型。它具有分布式、容错和多主复制等特性,适合于需要高可用性和数据一致性的应用场景。
**ArangoDB**:ArangoDB是一个多模型数据库,支持JSON、键值对和图形等多种数据模型。它具有高性能、高可扩展性和丰富的查询功能,可以满足各种应用场景的需求。
在选择JSON数据库引擎时,需要考虑以下因素:
- **性能:**数据库的读写性能是否满足应用需求。
- **可扩展性:**数据库是否能够随着数据量的增长而平滑扩展。
- **查询功能:**数据库是否提供丰富的查询功能,以满足应用的查询需求。
- **可靠性:**数据库是否具有高可用性和数据一致性保障。
- **社区支持:**数据库是否拥有活跃的社区和丰富的技术文档。
#### 3.1.2 数据库的创建与配置
创建JSON数据库需要根据所选的数据库引擎进行具体操作。以MongoDB为例,创建数据库的步骤如下:
1. 安装MongoDB:下载并安装MongoDB社区版或企业版。
2. 启动MongoDB服务:在终端中输入`mongod`命令启动MongoDB服务。
3. 创建数据库:在终端中输入`mongo`命令进入MongoDB shell,然后输入`use mydb`命令创建名为`mydb`的数据库。
数据库创建完成后,可以对数据库进行配置,例如设置用户权限、启用认证、配置复制等。具体配置方法可以参考数据库引擎的官方文档。
# 4.1 JSON数据库的索引与优化
### 4.1.1 索引的类型与创建
索引是数据库中一种重要的数据结构,它可以加快数据的查询速度。JSON数据库中支持多种类型的索引,包括:
- **单字段索引:**对单个字段创建索引。
- **复合索引:**对多个字段创建索引。
- **全文索引:**对文本字段创建索引,支持全文搜索。
创建索引的语法如下:
```
db.collection.createIndex({ field1: 1, field2: -1 })
```
其中:
- `db`:数据库名称。
- `collection`:集合名称。
- `field1`、`field2`:要创建索引的字段。
- `1`:升序索引。
- `-1`:降序索引。
例如,创建一个对 `name` 字段升序索引的单字段索引:
```
db.users.createIndex({ name: 1 })
```
### 4.1.2 索引的优化与维护
创建索引后,需要对其进行优化和维护,以确保索引的有效性。
**索引优化**
- **选择合适的索引类型:**根据查询模式选择合适的索引类型。
- **避免创建不必要的索引:**只创建必要的索引,避免索引冗余。
- **定期检查索引使用情况:**使用 `db.collection.stats()` 命令检查索引的使用情况,并删除不常用的索引。
**索引维护**
- **重建索引:**当数据发生大量变更时,需要重建索引以保持索引的最新性。
- **删除不必要的索引:**当索引不再使用时,应将其删除以释放资源。
### 代码示例
以下代码示例演示了如何创建索引并检查索引使用情况:
```javascript
// 创建索引
db.users.createIndex({ name: 1 })
// 检查索引使用情况
const stats = db.users.stats()
console.log(stats.indexSizes)
```
输出:
```
{
"name_1": {
"size": 1024
}
}
```
该输出显示了 `name` 字段索引的大小为 1024 字节。
# 5. JSON数据库与其他技术集成
### 5.1 JSON数据库与Web服务的集成
#### 5.1.1 JSON API的设计与实现
JSON API是一种用于定义和使用HTTP API的规范,它基于JSON数据格式。通过遵循JSON API规范,开发者可以创建可互操作且易于使用的API。
**JSON API的设计原则:**
- **资源导向:**API以资源为中心,每个资源都有一个唯一的标识符和一组属性。
- **统一接口:**所有资源都使用相同的HTTP方法(GET、POST、PUT、DELETE)和URL结构进行操作。
- **数据格式化:**所有数据都使用JSON格式传输,这确保了数据的一致性和可读性。
**实现JSON API:**
可以使用各种框架和工具来实现JSON API,例如:
- **Flask-RESTful:**用于Python的流行RESTful API框架。
- **Django REST Framework:**用于Django的RESTful API框架。
- **Node.js Express:**用于Node.js的Web应用程序框架,支持JSON API。
#### 5.1.2 JSON数据的传输与处理
在Web服务中,JSON数据通常通过HTTP请求和响应传输。
**请求:**
- **Content-Type:**设置为"application/json",表示请求体包含JSON数据。
- **请求体:**包含JSON格式的数据,用于创建或更新资源。
**响应:**
- **Content-Type:**设置为"application/json",表示响应体包含JSON数据。
- **响应体:**包含JSON格式的数据,用于返回资源信息或错误消息。
**处理JSON数据:**
在Web服务中,可以使用各种语言和库来处理JSON数据,例如:
- **Python:**使用json模块。
- **JavaScript:**使用JSON.parse()和JSON.stringify()方法。
- **Java:**使用Jackson库。
### 5.2 JSON数据库与大数据分析的集成
#### 5.2.1 JSON数据的预处理与转换
在进行大数据分析之前,通常需要对JSON数据进行预处理和转换,以使其适合分析工具。
**预处理步骤:**
- **数据清洗:**删除或修复无效或不完整的数据。
- **数据标准化:**将数据转换为一致的格式,例如将日期转换为时间戳。
- **数据转换:**将数据转换为分析工具所需的格式,例如将JSON转换为CSV或Parquet。
**转换工具:**
可以使用各种工具来预处理和转换JSON数据,例如:
- **Apache Spark:**一个分布式数据处理框架,支持JSON数据的处理。
- **Pandas:**一个用于Python的数据分析库,支持JSON数据的读取和转换。
- **jq:**一个命令行工具,用于处理和转换JSON数据。
#### 5.2.2 大数据分析工具的应用
一旦JSON数据被预处理和转换,就可以使用大数据分析工具进行分析。
**分析工具:**
- **Apache Hadoop:**一个分布式文件系统和数据处理框架。
- **Apache Hive:**一个用于大数据仓库的SQL引擎。
- **Apache Spark:**一个分布式数据处理框架,支持机器学习和流处理。
**分析技术:**
可以使用各种分析技术来分析JSON数据,例如:
- **聚合:**计算数据的总和、平均值或其他统计信息。
- **分组:**将数据分组并根据组进行分析。
- **机器学习:**使用算法从数据中学习模式和预测结果。
# 6. JSON数据库的未来趋势与展望
### 6.1 JSON数据库的最新发展
#### 6.1.1 新特性与功能
- **JSON Schema支持:**JSON Schema是一种定义JSON数据结构和约束的标准,有助于提高数据一致性和验证。
- **全文搜索:**支持对JSON文档中的文本内容进行全文搜索,增强了数据检索的灵活性。
- **地理空间查询:**支持对JSON文档中包含地理空间数据的查询,满足地理信息系统(GIS)应用的需求。
- **事务支持:**提供事务支持,确保数据操作的原子性和一致性,提高数据可靠性。
#### 6.1.2 社区与生态系统
JSON数据库社区近年来不断壮大,活跃的开发者和用户群体促进了技术的创新和发展。
- **开源项目:**MongoDB、CouchDB等开源JSON数据库项目吸引了大量的贡献者,不断完善和扩展功能。
- **社区论坛和会议:**社区论坛和会议提供了交流和学习的平台,促进技术分享和问题解决。
- **第三方工具:**涌现出各种第三方工具,例如JSON编辑器、查询语言和数据可视化工具,丰富了JSON数据库的使用场景。
### 6.2 JSON数据库的未来展望
#### 6.2.1 性能优化与可扩展性
- **分布式架构:**采用分布式架构,将数据分布在多个节点上,提高可扩展性和容错性。
- **内存优化:**优化内存管理,减少数据访问的延迟,提高查询性能。
- **并行处理:**支持并行处理,充分利用多核CPU的优势,加快数据处理速度。
#### 6.2.2 数据安全与隐私保护
- **数据加密:**支持数据加密,保护敏感数据的安全,防止未经授权的访问。
- **访问控制:**提供细粒度的访问控制机制,控制不同用户对数据的访问权限。
- **数据审计:**记录和审计数据操作,确保数据安全和合规性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 JSON 数据库专栏,这里将深入探讨 JSON 数据库的方方面面。从入门指南到数据处理技巧,从索引优化到管理指南,我们为您提供全面的知识,帮助您充分利用 JSON 数据库的强大功能。
此外,我们还深入研究了 JSON 数据库在 NoSQL 和物联网中的应用,展示了其在处理海量异构数据和赋能万物互联方面的独特优势。通过识别和解决性能瓶颈,预防和恢复数据丢失,以及遵循最佳实践和性能调优指南,您可以确保您的 JSON 数据库稳定高效地运行。
我们还提供了大型电商平台和社交媒体平台的应用案例,展示了 JSON 数据库如何应对海量数据挑战并提升用户体验。通过我们的灾难恢复计划,您可以保障数据安全和业务连续性,让您的数据无惧灾难。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Vue Select选择框数据监听秘籍:掌握数据流与$emit通信机制

# 摘要
本文深入探讨了Vue框架中Select组件的数据绑定和通信机制。从Vue Select组件与数据绑定的基础开始,文章逐步深入到Vue的数据响应机制,详细解析了响应式数据的初始化、依赖追踪,以及父子组件间的数据传递。第三章着重于Vue Select选择框的动态数据绑定,涵盖了高级用法、计算属性的优化,以及数据变化监听策略。第四章则专注于实现Vue Se
【操作秘籍】:施耐德APC GALAXY5000 UPS开关机与故障处理手册
# 摘要
本文对施耐德APC GALAXY5000 UPS进行全面介绍,涵盖了设备的概述、基本操作、故障诊断与处理、深入应用与高级管理,以及案例分析与用户经验分享。文章详细说明了UPS的开机、关机、常规检查、维护步骤及监控报警处理流程,同时提供了故障诊断基础、常见故障排除技巧和预防措施。此外,探讨了高级开关机功能、与其他系统的集成以及高级故障处理技术。最后,通过实际案例和用户经验交流,强调了该UPS在不同应用环境中的实用性和性能优化。
# 关键字
UPS;施耐德APC;基本操作;故障诊断;系统集成;案例分析
参考资源链接:[施耐德APC GALAXY5000 / 5500 UPS开关机步骤
wget自动化管理:编写脚本实现Linux软件包的批量下载与安装
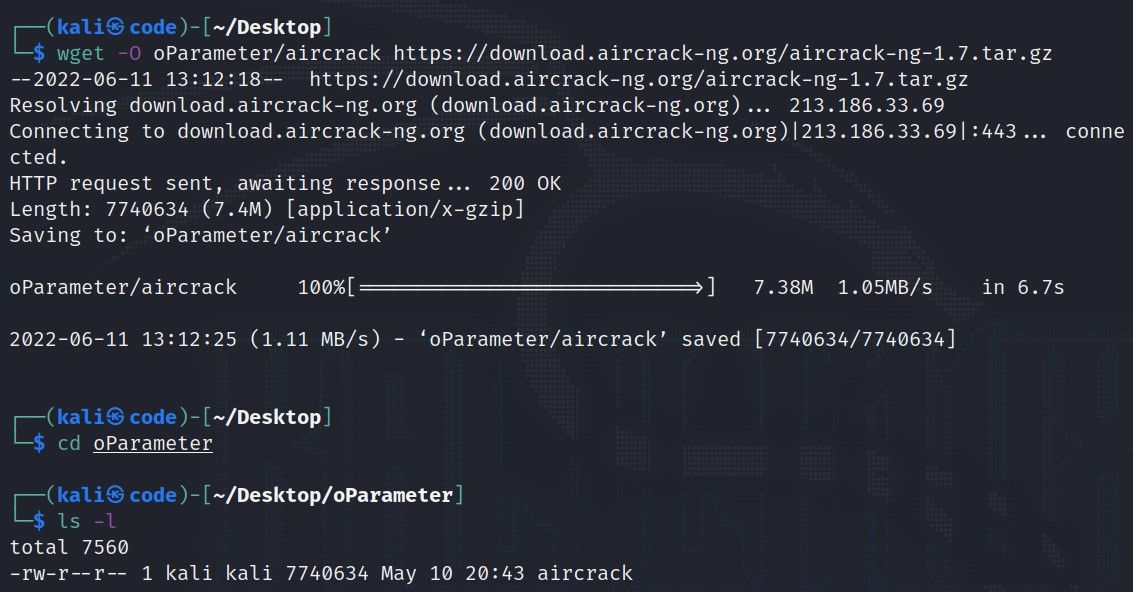
# 摘要
本文对wget工具的自动化管理进行了系统性论述,涵盖了wget的基本使用、工作原理、高级功能以及自动化脚本的编写、安装、优化和安全策略。首先介绍了wget的命令结构、选项参数和工作原理,包括支持的协议及重试机制。接着深入探讨了如何编写高效的自动化下载脚本,包括脚本结构设计、软件包信息解析、批量下载管理和错误
Java中数据结构的应用实例:深度解析与性能优化
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
SPiiPlus ACSPL+变量管理实战:提升效率的最佳实践案例分析

# 摘要
SPiiPlus ACSPL+是一种先进的控制系统编程语言,广泛应用于自动化和运动控制领域。本文首先概述了SPiiPlus ACSPL+的基本概念与变量管理基础,随后深入分析了变量类型与数据结构,并探讨了实现高效变量管理的策略。文章还通过实战技巧,讲解了变量监控、调试、性能优化和案例分析,同时涉及了高级应用,如动态内存管理、多线程变量同步以及面向对象的变
DVE基础入门:中文版用户手册的全面概览与实战技巧

# 摘要
本文旨在为初学者提供DVE(文档可视化编辑器)的入门指导和深入了解其高级功能。首先,概述了DVE的基础知识,包括用户界面布局和基本编辑操作,如文档的创建、保存、文本处理和格式排版。接着,本文探讨了DVE的高级功能,如图像处理、高级文本编辑技巧和特殊功能的使用。此外,还介绍了DVE的跨平台使用和协作功能,包括多用户协作编辑、跨平台兼容性以及与其他工具的整合。最后,通过
【Origin图表专业解析】:权威指南,坐标轴与图例隐藏_显示的实战技巧

# 摘要
本文系统地介绍了Origin软件中图表的创建、定制、交互功能以及性能优化,并通过多个案例分析展示了其在不同领域中的应用。首先,文章对Origin图表的基本概念、坐标轴和图例的显示与隐藏技巧进行了详细介绍,接着探讨了图表高级定制与性能优化的方法。文章第四章结合实战案例,深入分析了O
EPLAN Fluid团队协作利器:使用EPLAN Fluid提高设计与协作效率
# 摘要
EPLAN Fluid是一款专门针对流体工程设计的软件,它能够提供全面的设计解决方案,涵盖从基础概念到复杂项目的整个设计工作流程。本文从EPLAN Fluid的概述与基础讲起,详细阐述了设计工作流程中的配置优化、绘图工具使用、实时协作以及高级应用技巧,如自定义元件管理和自动化设计。第三章探讨了项目协作机制,包括数据管理、权限控制、跨部门沟通和工作流自定义。通过案例分析,文章深入讨论
【数据迁移无压力】:SGP.22_v2.0(RSP)中文版的平滑过渡策略

# 摘要
本文深入探讨了数据迁移的基础知识及其在实施SGP.22_v2.0(RSP)迁移时的关键实践。首先,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )