使用Logstash实现日志收集和解析
发布时间: 2024-01-10 17:13:40 阅读量: 43 订阅数: 40 

用Kibana和logstash快速搭建实时日志查询、收集与分析系统
# 1. 介绍
## 1.1 什么是Logstash
Logstash是一个开源的数据处理引擎,用于收集、解析和存储各种日志数据。它可以有效地从不同的数据源收集日志,并对这些日志进行解析、过滤和转换,最后将其存储到指定的目标位置。Logstash支持多种数据源和目标,如文件、网络、数据库等,并提供灵活的配置选项,可根据用户的需求进行定制。
## 1.2 日志收集和解析的重要性
日志是软件系统中记录运行状态、异常信息和用户行为的重要组成部分。通过对日志进行收集和解析,可以及时发现和定位系统的问题,并为系统的性能优化和安全审计提供有力支持。传统的日志收集方式通常是手动收集或使用简单的shell脚本进行定时抓取,但随着业务的增长和规模的扩大,这种方式已经无法满足需求。
Logstash的出现填补了这一空白,它可以实时收集日志数据,解析各种格式的日志,并将其存储到中央存储或数据仓库中。通过Logstash,可以快速、高效地处理海量的日志数据,提供实时监控和分析功能。
## 1.3 Logstash的特点和优势
Logstash具有以下特点和优势:
- 灵活的数据收集:Logstash支持多种数据源和目标,可以从文件、网络、数据库等不同数据源收集日志数据,并将其存储到指定目标位置。
- 强大的数据解析:Logstash拥有丰富的插件和过滤器,可以解析多种格式的日志数据,如JSON、XML、CSV等,从而方便后续处理和分析。
- 实时监控和可视化:Logstash与Elasticsearch和Kibana等工具集成,可以实时监控和展示收集到的日志数据,以便及时发现和处理问题。
- 高性能和可扩展:Logstash采用多线程处理日志数据,通过水平扩展可以处理更大规模的数据,从而提高性能和吞吐量。
- 丰富的社区支持:Logstash是一个开源项目,拥有庞大的社区支持,可以轻松获取各种插件、过滤器和最佳实践。
Logstash的特点和优势使其成为日志处理领域的热门工具,被广泛应用于各种场景,包括大数据分析、系统监控、日志审计等。接下来,我们将介绍如何安装、配置和使用Logstash。
# 2. 安装和配置Logstash
Logstash是一个开源的数据收集引擎,能够实时的获取数据并进行转换。它能够从不同的来源中收集数据,对数据进行格式化,然后将数据发送到指定的地方。Logstash是ELK(Elasticsearch、Logstash、Kibana)堆栈的重要组成部分,用于处理和分析日志数据。
#### 2.1 下载和安装Logstash
在开始安装Logstash之前,确保你的系统满足以下基本要求:
- Java版本7 或以上
- 2GB或以上的内存
可以通过以下步骤安装Logstash:
步骤1: 在官方网站 https://www.elastic.co/downloads/logstash 下载适合你操作系统的Logstash安装包。
步骤2: 解压下载的安装包到指定的目录,例如 `/usr/local/logstash`
步骤3: 运行Logstash,使用以下命令启动Logstash:
```bash
cd /usr/local/logstash
bin/logstash -e 'input { stdin { } } output { stdout {} }'
```
#### 2.2 配置Logstash的基本参数
Logstash的配置文件是一个简单的文本文件,使用YAML格式。你可以通过编辑配置文件来定义Logstash的输入、过滤和输出插件。
下面是一个简单的Logstash配置文件示例,它定义了一个stdin输入插件和一个stdout输出插件:
```yaml
input {
stdin {}
}
output {
stdout {}
}
```
在这个示例中,Logstash通过stdin插件接收输入,然后通过stdout插件将处理后的数据输出到控制台。
#### 2.3 添加日志输入插件
Logstash支持多种输入插件,用于从不同的来源收集日志数据,例如Beats、File、TCP、UDP等。你可以根据需要配置相应的输入插件。
以下是一个File输入插件的示例,用于收集一个特定路径下的日志文件:
```yaml
input {
file {
path => "/var/log/myapp.log"
start_position => "beginning"
}
}
```
在这个示例中,Logstash会监视`/var/log/myapp.log`文件,并从文件的开头开始收集日志数据。
#### 2.4 添加日志输出插件
除了stdout输出插件外,Logstash还支持多种输出插件,用于将处理后的数据发送到不同的目的地,例如Elasticsearch、Kafka、Redis等。你可以根据需要配置相应的输出插件。
以下是一个Elasticsearch输出插件的示例,用于将数据发送到Elasticsearch进行存储:
```yaml
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "myapp-%{+YYYY.MM.dd}"
}
}
```
在这个示例中,Logstash会将处理后的数据发送到本地运行的Elasticsearch实例,并将数据存储在名为`myapp-年月日`格式的索引中。
通过以上步骤,你已经学会了如何安装Logstash,并对其进行基本配置,包括添加输入和输出插件。在接下来的章节中,我们将学习如何使用Logstash实现日志收集和解析。
# 3. 使用Logstash收集日志
在第二章中,我们已经完成了Logstash的安装和配置。接下来,我们将详细介绍如何使用Logstash来收集日志。
#### 3.1 收集本地服务器的日志
为了收集本地服务器的日志,我们首先需要配置Logstash的日志输入插件。Logstash支持多种输入插件,包括文件输入插件、标准输入插件、syslog插件等。这里我们以文件输入插件为例。
首先,进入Logstash的安装目录,在`conf`文件夹中创建一个新的配置文件,例如`input.conf`。在该文件中添加以下内容:
```bash
input {
file {
path => "/var/log/app.log"
start_position => "beginning"
}
}
```
在上述配置中,我们指定了要收集的日志文件路径为`/var/log/app.log`,并设置了日志读取的起始位置为文件的开头。
接下来,我们需要配置日志的输出插件。以输出到Elasticsearch为例,创建一个新的配置文件,例如`output.conf`,添加以下内容:
```bash
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "app-logs"
}
}
```
在上述配置中,我们指定了要将日志输出到Elasticsearch的索引名为`app-logs`,并设置了Elasticsearch的地址为`localhost:9200`。
完成以上配置后,使用以下命令启动Logstash:
```bash
bin/logstash -f input.conf -f output.conf
```
Logstash将开始监视指定的日志文件,并将日志数据发送到Elasticsearch进行存储和索引。
#### 3.2 收集远程服务器的日志
除了收集本地服务器的日志,Logstash还支持收集远程服务器的日志。为了实现这一功能,我们需要在远程服务器上安装和配置Logstash。
首先,下载并安装Logstash到远程服务器上。然后,创建与本地服务器上类似的日志输入和输出配置文件。
在日志输入配置文件中,我们需要指定远程服务器上要收集的日志文件路径。例如:
```bash
input {
file {
path => "/var/log/app.log"
start_position => "beginning"
}
}
```
在日志输出配置文件中,我们需要指定将日志输出到本地服务器的Logstash的地址和端口。例如:
```bash
output {
tcp {
host => "localhost"
port => 5000
}
}
```
然后,在远程服务器上使用以下命令启动Logstash:
```bash
bin/logstash -f input.conf -f output.conf
```
日志数据将通过TCP协议发送到本地服务器的Logstash中。
#### 3.3 配置日志过滤器
除了收集日志,Logstash还提供了强大的日志过滤器功能,用于解析、过滤和修改日志事件。在配置文件中添加适当的过滤器可以对日志事件进行处理和转换。
Logstash提供了多种日志过滤器插件,包括grok、date、mutate等。我们可以根据需求选择适合的插件进行配置。
以使用grok插件解析日志为例,在日志过滤器配置文件中添加以下内容:
```bash
filter {
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:loglevel} \[%{DATA:thread}\] %{JAVACLASS:logger}\s+%{GREEDYDATA:message}" }
}
}
```
在上述配置中,我们使用grok插件解析日志中的时间戳、日志级别、线程、日志器和日志消息等信息。
完成以上配置后,重新启动Logstash,并观察日志解析结果。日志事件将会按照配置的字段进行解析和输出。
# 4. 日志解析和处理
日志解析和处理是Logstash的核心功能之一,通过日志解析器和过滤器,我们可以对原始日志进行结构化处理和筛选,从而提取有用的信息并进行后续的存储和分析。
#### 4.1 日志解析器的作用和原理
日志解析器负责将原始的文本日志数据转换成结构化的事件数据,以便后续能够更方便地进行搜索、过滤和分析。日志解析器的原理是通过定义解析模式,匹配日志中的特定格式,并将其提取为字段,从而形成结构化的事件数据。
#### 4.2 使用grok模式解析日志
Grok是一个强大的模式匹配工具,可以基于正则表达式快速解析日志。下面是一个使用Grok解析Apache日志的示例:
```java
input {
file {
path => "/var/log/apache/access.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "apache_logs"
}
}
```
在上面的例子中,我们使用Grok的预定义模式COMBINEDAPACHELOG来解析Apache的访问日志,将日志数据中的内容按照预定义的字段进行提取并存储到Elasticsearch中。
#### 4.3 过滤和处理日志事件
除了解析日志,Logstash还提供了丰富的过滤器插件,用于对日志事件进行处理、筛选和增强。例如,我们可以使用条件判断来过滤特定条件下的日志事件,也可以对事件中的字段进行处理、合并或拆分等操作。
```java
filter {
if [type] == "apache" {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
}
}
}
```
在上面的例子中,我们根据日志的类型为apache,先使用Grok进行解析,然后使用date插件对timestamp字段进行解析,最后使用geoip插件进行IP地址的地理位置解析。
通过以上实例,我们可以看到Logstash在日志解析和处理方面的强大功能,能够满足各种复杂日志处理的需求。
# 5. 实时监控和可视化
在本章中,我们将介绍如何使用Logstash进行实时监控和日志数据可视化,以便更直观地了解系统运行状态和日志信息。
#### 5.1 使用Elasticsearch存储日志数据
在实时监控和可视化日志数据之前,首先需要将日志数据持久化存储。Elasticsearch作为一个分布式的实时搜索和分析引擎,可以作为Logstash的输出目的地,用于存储日志数据。
```yaml
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
```
上述代码片段是一个Logstash配置文件中的output部分,指定了输出到Elasticsearch的参数。在这里,我们将日志数据输出到本地运行的Elasticsearch实例,并且为每天的日志数据创建一个新的索引。
#### 5.2 使用Kibana实时监控和可视化日志数据
Kibana是Elastic Stack中的数据可视化工具,可以与Elasticsearch配合使用,实时展示日志数据的图表、统计信息和仪表盘。
通过简单的图形化界面,我们可以轻松地创建各种图表来展示日志数据,比如展示日志级别的分布情况、统计请求响应时间的分布等。
#### 5.3 创建仪表盘和图表展示日志信息
在Kibana中,我们可以创建自定义的仪表盘,将多个图表和统计信息组合在一起,实现对日志数据的整体监控和分析。
通过仪表盘,我们可以直观地了解系统的运行状态和潜在的问题,比如实时查看日志事件的数量变化、按照关键词过滤特定类型的日志事件等。这有助于运维人员及时发现并解决系统中的异常情况。
以上是关于使用Logstash、Elasticsearch和Kibana实现日志的实时监控和可视化的介绍,通过整合这些工具,我们能够更加高效地管理和分析系统的日志信息。
# 6. 最佳实践和性能优化
### 6.1 如何优化Logstash性能
在实际应用中,Logstash的性能是一个非常重要的考虑因素。下面将介绍一些优化Logstash性能的方法和建议:
#### 6.1.1 配置多个Logstash实例
如果你的日志量非常大,单个Logstash实例可能无法承受这样的压力。这时可以考虑使用多个Logstash实例,将负载均衡在不同的实例之间,从而提高整体处理能力。
#### 6.1.2 配置并发处理参数
Logstash的配置文件中可以设置一些参数来控制并发处理的程度。例如,可以调整`pipeline.workers`参数来增加并行处理的线程数目,加快日志处理速度。
#### 6.1.3 使用合适的存储方式
Logstash默认使用Elasticsearch作为数据存储方式,但对于某些场景,使用其他存储方式可能更加合适。例如,对于大量写入的场景,可以考虑使用Redis等内存数据库作为中间存储,再将数据定期批量导入Elasticsearch。
### 6.2 日志收集和解析的最佳实践
除了性能优化外,还有一些最佳实践可以帮助我们更好地使用Logstash进行日志收集和解析:
#### 6.2.1 避免过度解析
在设计解析规则时,要尽量避免过度解析。过度解析会导致解析过程变慢,同时也增加了不必要的存储开销。只解析需要的字段,并根据实际需求合理设计解析规则。
#### 6.2.2 使用合适的日志格式
不同的日志格式需要使用不同的解析方式。对于结构化的日志,可以使用JSON格式进行解析,而对于非结构化的日志,可以使用正则表达式或其他解析方式。选择合适的日志格式可以提高解析的准确性和效率。
#### 6.2.3 添加合适的过滤器
Logstash支持多种过滤器,可以帮助我们对日志进行过滤、修改和丰富。根据实际需求添加合适的过滤器可以提高日志信息的质量和完整性,从而提高后续分析和监控的效果。
### 6.3 安全性和权限管理的考虑
在进行日志收集和处理时,安全性和权限管理是非常重要的考虑因素。以下是一些安全性和权限管理的建议:
#### 6.3.1 使用安全传输协议
在Logstash与其他组件之间的通信中,选择安全的传输协议是必要的。例如,使用TLS/SSL加密通信可以确保数据的机密性和完整性。
#### 6.3.2 配置访问控制
根据实际需求,配置访问控制是必要的。可以使用用户名和密码进行身份验证,只允许授权用户进行日志查询和修改操作。
#### 6.3.3 数据加密和脱敏
对于敏感信息,例如用户的个人数据,可以在收集日志时进行加密或脱敏处理,以避免泄露敏感信息的风险。
以上是关于Logstash最佳实践和性能优化的一些建议,希望对您有所帮助。当然,具体的实施方式还需要结合实际场景和业务需求进行调整。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以Java进阶教程elastic stack为主题,旨在帮助读者从入门到实践全面掌握相关知识。专栏包含了诸多主题,涵盖了Java核心知识点以及实际应用场景。通过阅读本专栏,读者将深入理解Java运行时数据区和垃圾回收机制,掌握Java异常处理机制,学会使用Java并发库进行多线程编程,以及探索网络编程、集合框架、IO与NIO等方面的知识。除此之外,本专栏还涵盖了Java注解、Lambda表达式、Web开发、数据库连接池、反射、设计模式、面向切面编程、安全编码等内容,为读者呈现了广泛而深入的Java应用领域。其中还涉及Elastic Stack的实时日志处理、Elasticsearch的文本搜索与分析以及Logstash的日志收集和解析,帮助读者在实践中进一步深化对Java知识的理解和应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【银行系统建模基础】:UML图解入门与实践,专业破解建模难题
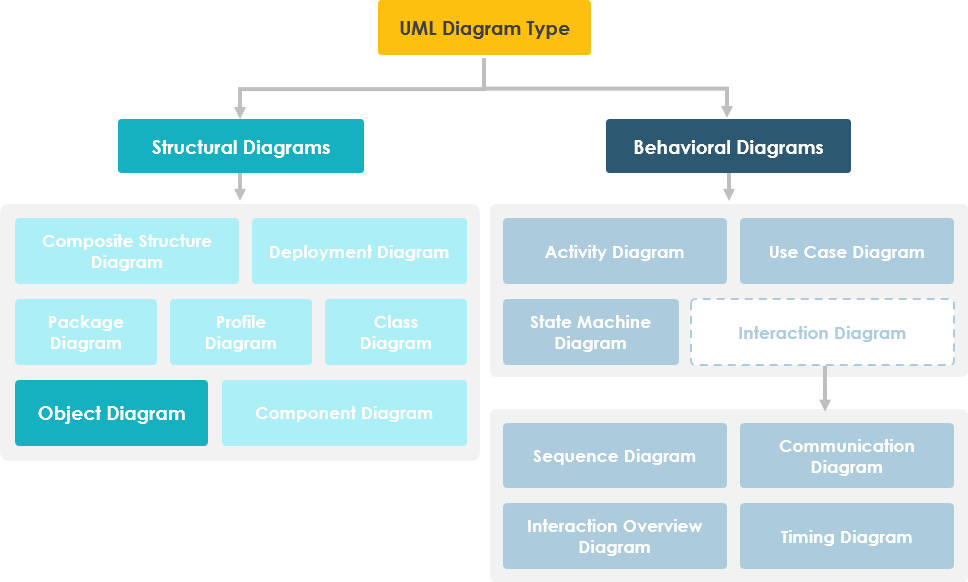
# 摘要
本文系统地介绍了UML在银行系统建模中的应用,从UML基础理论讲起,涵盖了UML图解的基本元素、关系与连接,以及不同UML图的应用场景。接着,本文深入探讨了银行系统用例图、类图的绘制与分析,强调了绘制要点和实践应用。进一步地,文章阐释了交互图与活动图在系统行为和业务流程建模中的设
深度揭秘:VISSIM VAP高级脚本编写与实践秘籍
# 摘要
本文详细探讨了VISSIM VAP脚本的编程基础与高级应用,旨在为读者提供从入门到深入实践的完整指导。首先介绍了VAP脚本语言的基础知识,包括基础语法、变量、数据类型、控制结构、类与对象以及异常处理,为深入编程打下坚实的基础。随后,文章着重阐述了VAP脚本在交通模拟领域的实践应用,包括交通流参数控制、信号动态管理以及自定义交通规则实现等。本文还提供了脚本优化和性能提升的策略,以及高级数据可视化技术和大规模模拟中的应用。最
【软件实施秘籍】:揭秘项目管理与风险控制策略
# 摘要
软件实施项目管理是一个复杂的过程,涉及到项目生命周期、利益相关者的分析与管理、风险管理、监控与控制等多个方面。本文首先介绍了项目管理的基础理论,包括项目定义、利益相关者分析、风险管理框架和方法论。随后,文章深入探讨了软件实施过程中的风险控制实践,强调了风险预防、问题管理以及敏捷开发环境下的风险控制策略。在项目监控与控制方面,本文分析了关键指标、沟通管理与团队协作,以及变
RAW到RGB转换技术全面解析:掌握关键性能优化与跨平台应用策略

# 摘要
本文系统地介绍了RAW与RGB图像格式的基础知识,深入探讨了从RAW到RGB的转换理论和实践应用。文章首先阐述了颜色空间与色彩管理的基本概念,接着分析了RAW
【51单片机信号发生器】:0基础快速搭建首个项目(含教程)
# 摘要
本文系统地介绍了51单片机信号发生器的设计、开发和测试过程。首先,概述了信号发生器项目,并详细介绍了51单片机的基础知识及其开发环境的搭建,包括硬件结构、工作原理、开发工具配置以及信号发生器的功能介绍。随后,文章深入探讨了信号发生器的设计理论、编程实践和功能实现,涵盖了波形产生、频率控制、编程基础和硬件接口等方面。在实践搭建与测试部分,详细说明了硬件连接、程序编写与上传、以
深入揭秘FS_Gateway:架构与关键性能指标分析的五大要点

# 摘要
FS_Gateway作为一种高性能的系统架构,广泛应用于金融服务和电商平台,确保了数据传输的高效率与稳定性。本文首先介绍FS_Gateway的简介与基础架构,然后深入探讨其性能指标,包括吞吐量、延迟、系统稳定性和资源使用率等,并分析了性能测试的多种方法。针对性能优化,本文从硬件和软件优化、负载均衡及分布式部署角度提出策略。接着,文章着重阐述了高可用性架构设计的重要性和实施策略,包括容错机制和故障恢复流程。最后,通过金
ThinkServer RD650故障排除:快速诊断与解决技巧

# 摘要
本文全面介绍了ThinkServer RD650服务器的硬件和软件故障诊断、解决方法及性能优化与维护策略。首先,文章对RD650的硬件组件进行了概览,随后详细阐述了故障诊断的基础知识,包括硬件状态的监测、系统日志分析、故障排除工具的使用。接着,针对操作系统级别的问题、驱动和固件更新以及网络与存储故障提供了具体的排查和处理方法。文章还探讨了性能优化与
CATIA粗糙度参数实践指南:设计师的优化设计必修课
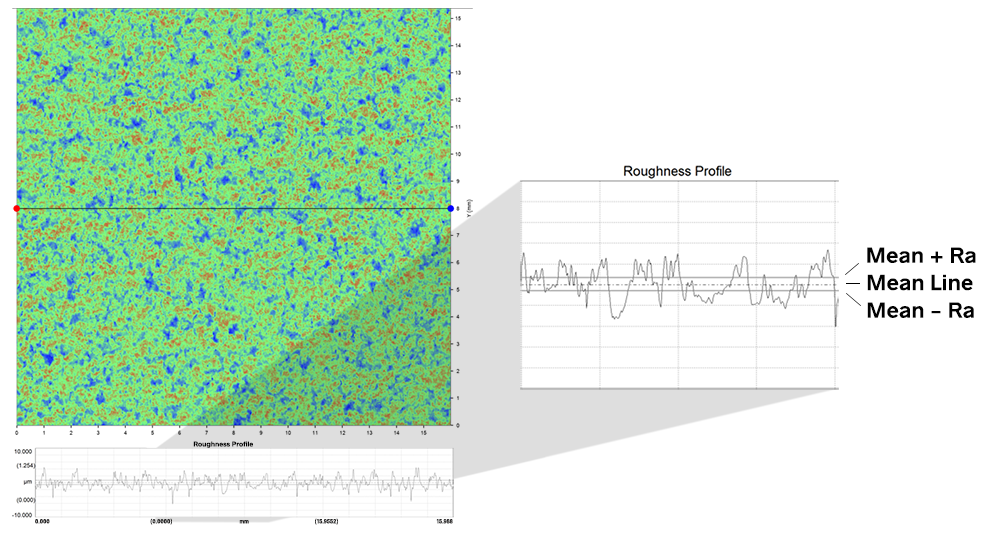
# 摘要
本文详细探讨了CATIA软件中粗糙度参数的基础知识、精确设定及其在产品设计中的综合应用。首先介绍了粗糙度参数的定义、分类、测量方法以及与材料性能的关系。随后,文章深入解析了如何在CATIA中精确设定粗糙度参数,并阐述了这些参数在不同设计阶段的优化作用。最后,本文探讨了粗糙度参数在机械设计、模具设计以及质量控制中的应用,提出了管理粗糙度参数的高级策略,包括优化技术、自动化和智能
TeeChart跨平台部署:6个步骤确保图表控件无兼容问题
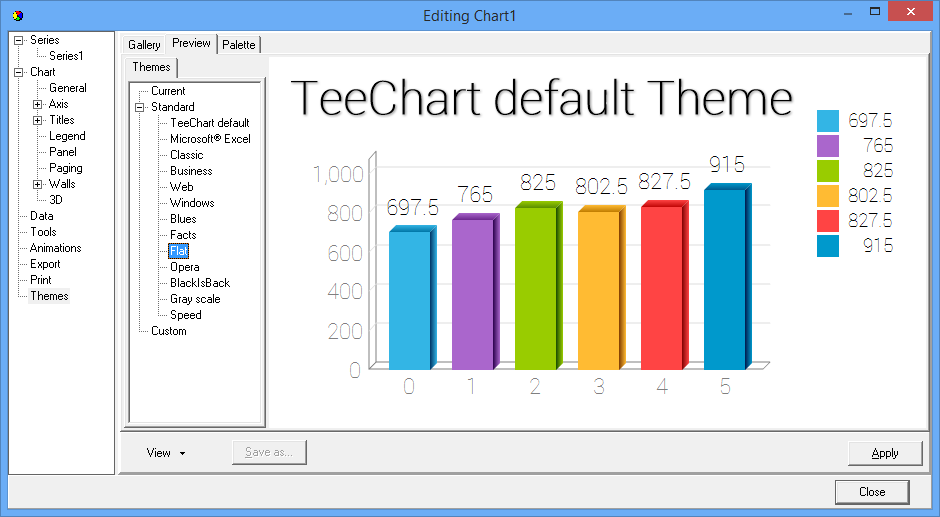
# 摘要
本文介绍TeeChart图表控件的跨平台部署与兼容性分析。首先,概述TeeChart控件的功能、特点及支持的图表类型。接着,深入探讨TeeChart的跨平台能力,包括支持的平台和部署优势。第三章分析兼容性问题及其解决方案,并针对Windows、Linux、macOS和移动平台进行详细分析。第四章详细介绍TeeChart部署的步骤,包括前期准备、实施部署和验证测试。第五
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )