【NumPy基础】:新手必备的NumPy配置与使用全攻略
发布时间: 2024-12-07 07:00:31 阅读量: 4 订阅数: 15 

Vue + Vite + iClient3D for Cesium 实现限高分析

# 1. NumPy简介与安装配置
NumPy是Python编程语言的一个扩展库,主要用于对大型多维数组与矩阵进行快速计算。它构成了科学计算的一个关键组件,与Pandas、Matplotlib等库一起广泛应用于数据分析、机器学习等领域。NumPy提供了高性能的数组对象和大量的数学函数库来处理这些数组。
## 1.1 安装NumPy
NumPy的安装过程相对简单,可以通过Python的包管理工具pip来安装。在命令行中输入以下命令即可完成安装:
```bash
pip install numpy
```
此外,对于使用conda环境的用户,也可以通过conda命令快速安装:
```bash
conda install numpy
```
## 1.2 验证安装
安装完成后,打开Python解释器,尝试导入NumPy库,如果未出现错误提示,则表示NumPy已经安装成功:
```python
import numpy
print(numpy.__version__)
```
如果以上步骤执行完毕且没有报错,那么恭喜你,你已经成功地配置好了NumPy的运行环境,可以开始接下来的学习和实践了。在后续章节中,我们将逐步深入了解NumPy的数组创建、索引、运算等核心概念和操作。
# 2. NumPy数组的创建与操作基础
## 2.1 数组的创建和基本属性
NumPy的核心是多维数组对象——ndarray,它对整个库的操作至关重要。在深入讨论数组操作之前,我们需要学习如何创建数组并理解其基本属性。
### 2.1.1 创建NumPy数组的方法
创建NumPy数组的方法多种多样,最直接的方式是使用`numpy.array()`函数,它可以将输入的数据转换为数组。例如:
```python
import numpy as np
# 创建一个简单的数组
array_1d = np.array([1, 2, 3, 4, 5])
print(array_1d)
```
对于多维数组,我们可以这样做:
```python
# 创建一个二维数组
array_2d = np.array([[1, 2], [3, 4]])
print(array_2d)
```
另一个常用的方法是通过`numpy.arange()`和`numpy.linspace()`函数创建数组。前者可以按照指定的步长生成数组,而后者则是在指定区间生成均匀分布的数值数组。
```python
# 使用arange创建数组
arange_array = np.arange(0, 10, 2)
print(arange_array)
# 使用linspace创建数组
linspace_array = np.linspace(0, 1, 5)
print(linspace_array)
```
### 2.1.2 数组的基本属性和索引方式
NumPy数组有许多有用的属性,例如`shape`、`size`和`dtype`。`shape`提供了数组的维度信息,`size`告诉我们数组中元素的总数,而`dtype`则表明了数组中元素的数据类型。
```python
# 获取数组的基本属性
print("Array shape:", array_2d.shape)
print("Array size:", array_2d.size)
print("Array data type:", array_2d.dtype)
```
数组的索引方式则类似于Python的列表索引,支持使用方括号`[]`进行元素的选取。
```python
# 使用索引访问数组元素
print("Element at row 0, column 1:", array_2d[0, 1])
```
这里也支持切片操作,可以提取数组的子集。
```python
# 使用切片访问数组的子集
print("Subarray from row 0 to 1, column 0 to 1:\n", array_2d[0:2, 0:2])
```
## 2.2 数组的数据类型与转换
### 2.2.1 支持的数据类型概览
NumPy支持比Python原生类型更为丰富的数据类型,包括整数、浮点数、复数、字符串和布尔类型等。
下面是一个包含多种数据类型的NumPy数组示例:
```python
# 创建包含不同数据类型的数组
mixed_array = np.array([1, 2.0, 3+4j, 'numpy', True])
print(mixed_array)
print("Data type:", mixed_array.dtype)
```
### 2.2.2 数据类型转换的技巧和方法
当需要对数组中的数据类型进行转换时,可以使用`.astype()`方法。例如,将整数数组转换为浮点数数组:
```python
# 转换数据类型
float_array = array_1d.astype(np.float64)
print("Converted to float64:", float_array)
print("New data type:", float_array.dtype)
```
在处理数据时,正确的数据类型对于性能和精度都是非常关键的。选择适当的数据类型可以显著减少内存使用并提升运算速度。
## 2.3 基本的数组运算
### 2.3.1 数组的数学运算
NumPy的数组支持广泛的基本数学运算。这些操作既可以是元素间的算术运算,也可以是针对整个数组的操作。
```python
# 数组间的算术运算
addition = array_1d + array_1d
multiplication = array_1d * array_1d
print("Addition of array_1d:", addition)
print("Multiplication of array_1d:", multiplication)
```
### 2.3.2 广播机制的理解与应用
当对不同形状的数组进行操作时,NumPy会自动应用广播机制,使得较小的数组可以“扩展”以匹配较大数组的形状。
```python
# 广播机制的应用
bigger_array = np.array([[1, 2, 3], [4, 5, 6]])
scalar = 10
print("Bigger array + scalar:", bigger_array + scalar)
```
理解并正确应用广播机制对于编写高效的数组操作代码至关重要。在不改变原数组形状的情况下,能够对数组进行复杂计算,大大简化了编程工作。
# 3. 高级NumPy数组操作
## 3.1 数组的切片和索引技巧
### 3.1.1 高级索引与切片操作
NumPy数组的切片和索引机制是数据处理中的核心概念之一,它允许用户高效地访问和操作数组的子集。高级索引包括使用整数数组索引、布尔数组索引以及使用切片操作。
#### 整数数组索引
整数数组索引允许我们根据提供的索引数组选择数组中的元素。这在处理非连续数据时非常有用。
```python
import numpy as np
arr = np.arange(0, 20).reshape(4, 5)
index = [0, 2]
selected_rows = arr[index, :]
print(selected_rows)
```
在上述示例中,我们使用整数数组 `index` 选择了一个二维数组 `arr` 的特定行。结果是提取了第一行(索引0)和第三行(索引2)的所有列。
#### 布尔数组索引
布尔数组索引使用布尔值数组来选择数组元素。数组中的每个布尔值对应于原始数组中的位置,True 表示选取该位置的元素。
```python
import numpy as np
arr = np.array([[1, 2], [3, 4], [5, 6]])
bool_idx = arr > 3 # 创建一个布尔索引数组
filtered_arr = arr[bool_idx]
print(filtered_arr)
```
#### 切片操作
NumPy切片操作的灵活性在于它不仅限于单个维度,还可以同时对多个维度进行切片。
```python
import numpy as np
arr = np.arange(0, 100).reshape(10, 10)
sub_arr = arr[1:4, 5:8]
print(sub_arr)
```
在上面的例子中,我们选取了 `arr` 数组中第二行到第四行(索引1到3)和第六列到第八列(索引5到7)的子数组。
### 3.1.2 使用条件索引选取数据
条件索引是基于条件表达式的数组索引。它允许用户基于一个或多个条件过滤数组元素。
```python
import numpy as np
arr = np.array([10, 2, 30, 4, 50])
condition = arr > 15
filtered_arr = arr[condition]
print(filtered_arr)
```
在这个示例中,`condition` 是一个布尔数组,其值取决于 `arr` 中每个元素是否大于15。结果是一个只包含满足条件(大于15)元素的新数组。
接下来的子章节将详细说明数组的合并与分割以及形状操作与变形。
# 4. NumPy在数据分析中的应用
随着数据科学的不断发展,NumPy已成为数据分析不可或缺的工具。这一章节将深入探讨NumPy在统计分析、文件读写与数据处理以及线性代数运算中的应用,展示其强大的数据处理能力。
## 4.1 统计分析功能
### 4.1.1 描述性统计分析函数
在数据分析的初步阶段,描述性统计分析能够提供数据集的概览,包括集中趋势、分散程度等特征。NumPy提供了丰富的描述性统计分析函数,这些函数可以直接应用于数组,快速得到结果。
```python
import numpy as np
# 示例数组
data = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
# 计算均值
mean_value = np.mean(data)
# 计算中位数
median_value = np.median(data)
# 计算标准差
std_dev = np.std(data)
# 计算方差
variance = np.var(data)
# 计算最小值和最大值
min_value = np.min(data)
max_value = np.max(data)
# 计算总和
total_sum = np.sum(data)
# 打印结果
print(f"均值: {mean_value}")
print(f"中位数: {median_value}")
print(f"标准差: {std_dev}")
print(f"方差: {variance}")
print(f"最小值: {min_value}")
print(f"最大值: {max_value}")
print(f"总和: {total_sum}")
```
在上述代码中,我们使用了`np.mean`, `np.median`, `np.std`, `np.var`, `np.min`, `np.max`, `np.sum`等函数来计算数组的均值、中位数、标准差、方差、最小值、最大值以及总和。这些统计值对于理解数据的分布具有重要意义。
### 4.1.2 随机数生成与概率分布
在模拟和统计分析中,生成随机数和了解不同概率分布是常见的需求。NumPy提供了一个强大的随机数生成器,可以用来生成各种分布类型的随机数。
```python
# 生成一组均匀分布的随机数
uniform_random = np.random.uniform(0, 1, 10)
# 生成一组正态分布的随机数
normal_random = np.random.normal(0, 1, 10)
# 生成一组离散均匀分布的随机整数
discrete_random = np.random.randint(0, 10, 10)
# 打印结果
print(f"均匀分布随机数: {uniform_random}")
print(f"正态分布随机数: {normal_random}")
print(f"离散均匀分布随机整数: {discrete_random}")
```
除了上述基础的随机数生成外,NumPy还提供了`np.random.seed`用于设置随机数生成的种子,确保结果的可复现性,这对于数据分析和机器学习中的实验验证非常重要。
## 4.2 文件读写与数据处理
数据往往存储在文件中,数据分析的第一步常常是将数据读入程序中。NumPy提供了读取和写入文件的功能,可以方便地处理数据。
### 4.2.1 从文本文件读取数据到数组
NumPy的`np.loadtxt`和`np.genfromtxt`函数可以用来从文本文件中读取数据到数组。这两者的主要区别在于`np.genfromtxt`提供了更多的功能,比如处理缺失值。
```python
# 从文本文件加载数据
data = np.loadtxt('data.txt', delimiter=' ')
# 打印数据
print(data)
```
在实际应用中,数据文件通常具有复杂的格式,例如含有多行标题、缺失值等。这时`np.genfromtxt`就显得格外有用。
### 4.2.2 使用NumPy进行数据清洗和处理
在读取数据后,可能需要进行清洗,比如去除异常值、填补缺失值等。NumPy能够支持这些操作,并且性能优异。
```python
# 数据清洗示例
# 假设data数组中含有NaN值,我们需要进行处理
data_cleaned = np.where(np.isnan(data), np.mean(data), data)
```
NumPy的数组操作非常灵活,我们可以利用布尔索引、`np.where`函数等来实现复杂的数据清洗逻辑。
## 4.3 线性代数运算
线性代数是数据分析的一个重要分支,尤其在机器学习和统计建模中,涉及到大量的矩阵运算。
### 4.3.1 矩阵运算的基础
NumPy支持标准的矩阵运算,例如矩阵乘法,转置等。其提供了`np.dot`用于矩阵乘法,`np.transpose`用于矩阵转置。
```python
# 矩阵乘法示例
matrix_a = np.array([[1, 2], [3, 4]])
matrix_b = np.array([[5, 6], [7, 8]])
# 计算矩阵乘积
product = np.dot(matrix_a, matrix_b)
# 矩阵转置示例
transpose_a = np.transpose(matrix_a)
# 打印结果
print(f"矩阵乘积: \n{product}")
print(f"矩阵a的转置: \n{transpose_a}")
```
NumPy的矩阵运算不仅限于二维数组,也支持更高维度的数据操作,这使得NumPy成为处理复杂数据结构的有力工具。
### 4.3.2 特殊矩阵操作和应用实例
在数据分析过程中,我们经常遇到特殊的矩阵,如对角矩阵、单位矩阵等。NumPy提供了创建这些特殊矩阵的函数。
```python
# 创建单位矩阵
identity_matrix = np.eye(3)
# 创建对角矩阵
diagonal_matrix = np.diag([1, 2, 3])
# 打印结果
print(f"单位矩阵: \n{identity_matrix}")
print(f"对角矩阵: \n{diagonal_matrix}")
```
通过这些特殊矩阵,我们可以简化计算过程并解决特定的问题。例如,在计算向量的投影时,单位矩阵用于保持向量的长度不变,而对角矩阵可以用于权重的调整。
在本章节中,我们详细探讨了NumPy在数据分析中的具体应用,从基础的统计分析功能到文件读写和数据处理,再到线性代数运算,都展示了NumPy强大的数据处理能力。NumPy作为一个高效的数据处理库,不仅可以处理大规模的数据集,还能提供快速且准确的数值计算功能,对数据科学家和工程师来说是一个不可或缺的工具。
# 5. NumPy与Pandas、Matplotlib的集成
NumPy作为一个强大的数值计算库,为数据分析提供了坚实的基础。但在实际的数据分析工作中,我们常常需要与Pandas和Matplotlib等其他库协同工作,以达成更为复杂的目标。Pandas擅长处理表格数据,而Matplotlib则提供了一个可视化数据的强大工具。本章将探讨如何将NumPy与其他库集成,以实现更高效的分析工作流程。
## 5.1 NumPy与Pandas的互动
### 5.1.1 Pandas的DataFrame与NumPy数组的转换
Pandas的DataFrame是一个二维标签数据结构,它为处理表格型数据提供了方便的接口。在数据处理过程中,我们可能会需要将Pandas的DataFrame与NumPy数组相互转换,以便利用NumPy的高效数值计算功能,或是将NumPy数组的数据导入到Pandas中进行进一步的分析。
#### 转换示例代码:
```python
import pandas as pd
import numpy as np
# 创建一个NumPy数组
np_array = np.array([[1, 2, 3], [4, 5, 6]])
# 将NumPy数组转换成Pandas DataFrame
df = pd.DataFrame(np_array)
# 将Pandas DataFrame转换回NumPy数组
np_array_converted = df.to_numpy()
```
#### 逻辑分析与参数说明:
- 上述代码首先导入了`pandas`和`numpy`模块。
- 然后创建了一个简单的二维NumPy数组。
- 使用`pd.DataFrame()`构造函数将NumPy数组转换为Pandas的DataFrame对象。
- 通过`DataFrame.to_numpy()`方法,可以将DataFrame对象转换回NumPy数组。
- 这种转换对于在NumPy和Pandas之间传输数据非常有用,尤其是在需要利用NumPy进行计算或Pandas进行数据整理时。
### 5.1.2 利用NumPy优化Pandas数据处理
Pandas虽然功能强大,但在处理大规模数据时可能会出现性能瓶颈。这时,我们可以借助NumPy强大的内部优化,将部分Pandas操作用NumPy操作替代,以提高数据处理的效率。
#### 优化操作示例代码:
```python
import pandas as pd
# 创建一个大规模的DataFrame
df_large = pd.DataFrame({
'A': np.random.rand(1000000),
'B': np.random.rand(1000000)
})
# 使用Pandas自带的计算方式
pandas_time = %timeit -o pd.DataFrame({'C': df_large['A'] + df_large['B']})
# 使用NumPy数组计算
np_array = df_large.to_numpy()
numpy_time = %timeit -o np.sum(np_array, axis=1)
# 比较两种方法的执行时间
print(f"Pandas computation time: {pandas_time.average} seconds")
print(f"NumPy computation time: {numpy_time.average} seconds")
```
#### 逻辑分析与参数说明:
- 这段代码首先创建了一个具有100万行数据的Pandas DataFrame。
- 然后,分别使用Pandas和NumPy执行相同的操作:计算两列数据的和,并将其存储在新的DataFrame列中。
- 使用`%timeit`魔术命令来测量每种方法的平均执行时间。
- 通常情况下,NumPy在执行数值计算时会更快,尤其是在处理大规模数据集时。
- 通过这种方式,我们可以评估使用NumPy替代Pandas进行数据处理是否能够带来显著的性能提升。
## 5.2 利用Matplotlib进行数据可视化
Matplotlib是一个非常流行的Python绘图库,它提供了丰富的绘图工具,能够让我们将数据以图形化的方式呈现出来。NumPy的高效数组操作为Matplotlib提供了强大的数据处理支持,使得数据可视化过程更为流畅。
### 5.2.1 基础的图形绘制
使用Matplotlib绘制基础图形时,我们常常需要处理数据并将其转换为适合绘图的格式。NumPy可以在这个过程中发挥作用,帮助我们进行数据转换和处理。
#### 绘制基础图形示例代码:
```python
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 绘制散点图
plt.scatter(x, y, c='r', marker='o')
plt.title('Sin Wave')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
plt.show()
```
#### 逻辑分析与参数说明:
- 在这段代码中,我们首先使用NumPy的`linspace`函数创建了一个等差数列,这可以作为绘图的x轴数据。
- 然后,我们计算了与x轴对应的y轴数据,这里使用了NumPy的三角函数库来生成正弦波数据。
- `plt.scatter`函数用于绘制散点图,我们设置了点的颜色和形状。
- 最后,我们设置了图表的标题和轴标签,并使用`plt.show()`显示图表。
### 5.2.2 高级绘图技巧与自定义图表
在处理更复杂的数据可视化时,Matplotlib提供了许多高级功能,比如堆叠图、热力图、子图绘制等。NumPy可以用于这些高级绘图技巧中的数据预处理,使得数据展示更加直观和易于理解。
#### 高级绘图技巧示例代码:
```python
# 假设我们有一组数据
data = np.random.rand(5, 10)
# 使用Matplotlib创建一个堆叠条形图
fig, ax = plt.subplots()
ax.stackplot(range(data.shape[1]), data.T, labels=['A', 'B', 'C', 'D', 'E'])
ax.legend(loc='upper left')
plt.title('Stacked Bar Chart')
plt.xlabel('Category')
plt.ylabel('Value')
plt.show()
```
#### 逻辑分析与参数说明:
- 这段代码首先创建了一个5行10列的随机数据矩阵,模拟了多组数据。
- `ax.stackplot`函数用于创建堆叠条形图,其中`range(data.shape[1])`确定了x轴的范围,`data.T`将数据进行转置,以便每个条形代表一个数据集。
- `labels`参数用于标记堆叠条形图的不同部分。
- 最后,我们设置了图表的标题、轴标签,并使用`plt.show()`显示了图表。
- 这种高级绘图技巧常用于展示时间序列数据的比较,或者不同类别的数据重叠。
通过这些实例,我们可以看到NumPy与Pandas、Matplotlib集成后,能够为数据处理和可视化提供更加强大和灵活的功能。在实际工作中,熟练地结合这些库,将极大地提高我们的数据分析效率。
# 6. NumPy实践项目:数据分析案例研究
本章将通过一个实际的数据分析案例,展示如何运用NumPy进行项目实战。我们会介绍项目的准备、分析过程,以及最终的成果展示。通过这个案例,读者可以加深对NumPy实际应用的理解,并学习如何将数据分析结果转化为有价值的洞察。
## 6.1 实际数据分析项目的准备
### 6.1.1 项目背景和数据集介绍
我们将要分析的是一个关于零售业销售数据的项目。数据集包含一年内某个零售店铺的所有销售记录,包括每个订单的商品类别、销售数量、销售价格和销售时间等信息。数据集的目的是分析销售趋势,预测未来销售情况,并为库存管理和促销活动提供数据支持。
### 6.1.2 数据探索和预处理
数据探索是数据分析的重要一步。首先,我们需要加载数据集,并使用NumPy进行初步的探索:
```python
import numpy as np
# 加载数据集(这里假设数据集以CSV格式存储)
data = np.loadtxt('sales_data.csv', delimiter=',', skiprows=1, dtype=str)
# 查看数据集的前几行
print(data[:5])
# 查看数据集的维度
print("数据集维度:", data.shape)
# 数据预处理
# 转换数据类型,例如将销售数量和价格转换为数值类型
sales_quantity = data[:, 2].astype(np.float64)
sales_price = data[:, 3].astype(np.float64)
# 过滤掉无效的数据(例如销售数量为0的记录)
valid_sales = sales_quantity > 0
# 对数据进行分组,例如按月分组销售数据
from datetime import datetime
dates = np.array([datetime.strptime(date, '%Y-%m-%d') for date in data[:, 4]])
sales_by_month = np.array([sales_quantity[i] for i, date in enumerate(dates) if valid_sales[i] and date.month == month] for month in range(1, 13))
print("一月份的销售数据:", sales_by_month[0])
```
## 6.2 数据分析与结果解释
### 6.2.1 使用NumPy进行数据计算
接下来,我们将使用NumPy进行一些关键的数据计算,包括销售数据的汇总、平均销售价格以及月销售趋势分析:
```python
# 计算销售总额
total_sales = np.sum(sales_quantity * sales_price)
# 计算平均销售价格
average_price = np.mean(sales_price[valid_sales])
# 使用掩码来过滤特定条件的数据,例如价格大于平均值的销售记录
mask = sales_price > average_price
higher_than_avg = sales_quantity[mask]
# 计算月销售趋势
monthly_trends = np.array([np.sum(sales_by_month[month - 1]) for month in range(1, 13)])
print("月销售趋势:", monthly_trends)
```
### 6.2.2 结果可视化与报告撰写
为了更直观地展示分析结果,我们可以使用Matplotlib来绘制销售趋势图,并撰写报告来解释这些结果:
```python
import matplotlib.pyplot as plt
# 绘制月销售趋势图
plt.plot(range(1, 13), monthly_trends, marker='o')
plt.title('Monthly Sales Trend')
plt.xlabel('Month')
plt.ylabel('Sales')
plt.grid(True)
plt.show()
```
## 6.3 总结与提升
### 6.3.1 项目总结与经验分享
通过这个项目,我们学习了如何使用NumPy处理和分析大规模的销售数据集。重点是数据的清洗、预处理和关键的计算操作。这些技能对于任何数据分析项目都是基础且至关重要的。
### 6.3.2 掌握NumPy的进阶技巧
NumPy提供了许多高级功能,例如线性代数运算、傅里叶变换和随机数生成等。掌握这些进阶技巧可以进一步提高数据分析的效率和深度。例如,使用NumPy进行多元统计分析或时间序列分析,可以帮助我们更好地理解数据的内在模式和关联性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python NumPy 安装与配置指南专栏!本专栏将带你深入了解 NumPy 的安装、配置和应用。从跨平台安装秘籍到性能基准测试,我们涵盖了所有操作系统上的 NumPy 安装方法。此外,我们还提供了 IDE 中的 NumPy 安装和配置指南,帮助你无缝整合 NumPy。
本专栏还探讨了 NumPy 与 Pandas 的整合,以及 NumPy 的内存管理和 C API。对于数据分析人员来说,我们提供了 NumPy 在数据分析中的应用指南,涵盖从新手到专家的各个级别。最后,我们深入探索了 NumPy 的高级特性和技巧,帮助你充分利用 NumPy 的强大功能。无论你是 Python 初学者还是经验丰富的开发者,本专栏都将为你提供全面的 NumPy 指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【UniAccess终极指南】:揭秘15项核心特性与高级应用
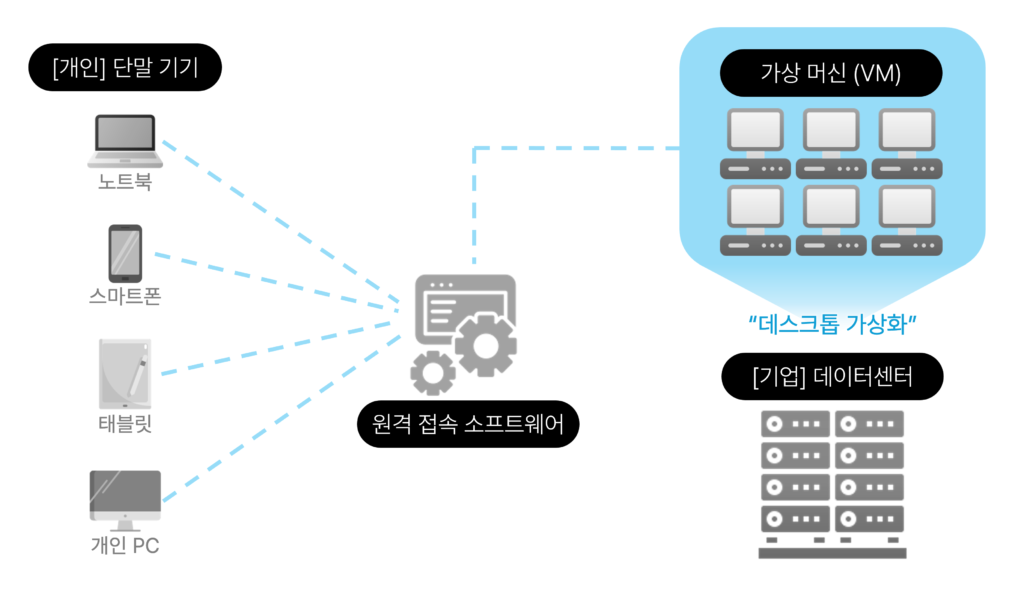
# 摘要
UniAccess是一套先进的访问控制和管理平台,本文对其进行了全面的概述和核心特性的深入分析。重点讨论了UniAccess的安全管理机制,包括认证与授权机制、数据加密与传输安全以及审计与日志记录。进一步探讨了UniAccess的工作流程和应用场景,分析了核心组件如何在动态访问控制流程中交互,以及在不同环境下的高级应用情况。文章还探讨了Uni
【MySQL SELECT INTO语句使用指南】:掌握基础用法与最佳场景
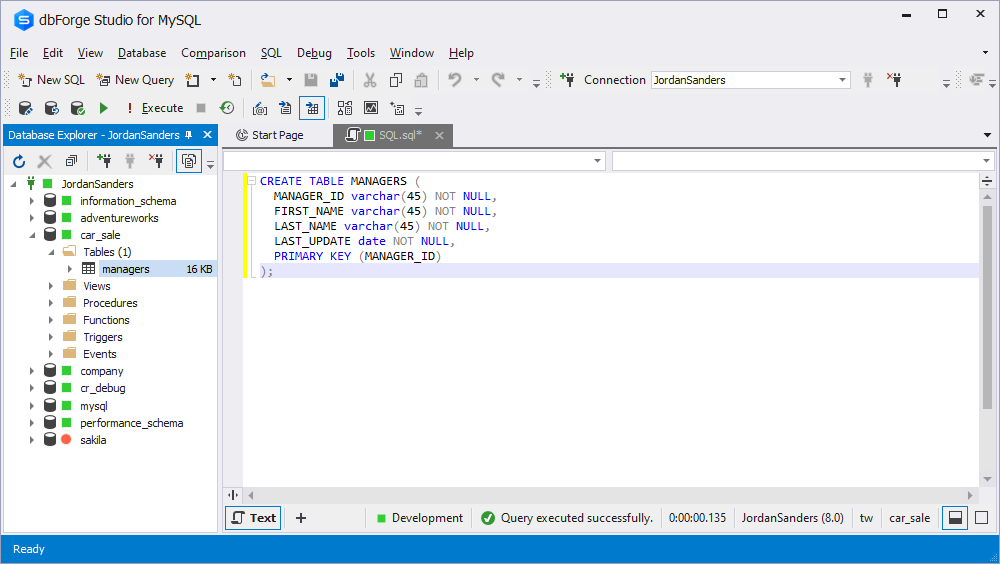
# 摘要
本文全面介绍了MySQL数据库中SELECT INTO语句的基础知识、查询机制、实际应用案例、不同环境下的部署以及最佳实践与安全考虑。首先阐述了SELECT INTO的基本概念及其在数据检索和存储中的应用。随后,深入解析了SELECT INTO的工作原理、高级查询技巧以及性能优化方法。文章通过具体案例,展示了SELECT INTO在数据备份迁移、报表生成及数据库维
【Kingst虚拟仪器深度使用手册】:界面、操作、高级特性一网打尽!
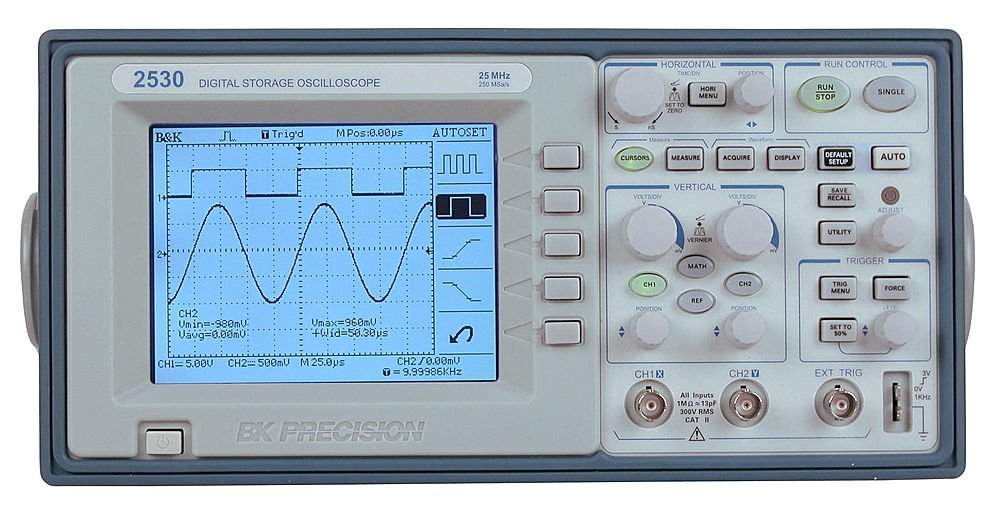
# 摘要
本文全面介绍了Kingst虚拟仪器的功能、操作界面、高级特性以及定制开发与集成,并通过案例分析展示了其在不同行业中的应用和故障排除方法。文章首先概述了虚拟仪器的基本概念和操作界面,详细解析了界面布局、配置选项和高级操作技巧。第二章深入探讨了数据采集、处理、实验测试流程以及报告的输出和自动生成方法。第三章着重于高级功能的探索,包括自动化测试脚本的编写、网络功能的利用、远程控制以及数据分析工具的应用。第四章则
【新手必看】HP iLO4系统安装基础指南
# 摘要
本文旨在详细介绍HP iLO4系统的各个方面,包括系统介绍、硬件需求、安装流程、管理维护以及高级应用和扩展。首先,强调了iLO4系统的重要性及其在硬件环境中的作用。随后,文档提供了全面的安装前准备工作,包括硬件兼容性检查、安装环境搭建以及所需文件和许可的获取。接下来,本文深入阐述了iLO4系统的安装流程,强调了启动引导序列、网络与存储配置以及初始系统设置的必要步骤。此外,本文还探讨了日常管理任务、安全性最佳实践和故障排除方法,确保系统的稳定运行。最后,介绍了如何配置远程管理功能、利用高级特性提升效能,以及集成HP OneView管理平台,以实现更高效的系统管理和监控。
# 关键字
PDL语言从入门到精通:21天掌握编程设计原理与实践技巧

# 摘要
PDL(Process Description Language)语言是一种用于程序设计和描述算法过程的高级语言。本文从PDL语言的概述及编程基础开始,深入探讨了PDL的核心概念、语法结构、数据类型和变量管理、函数定义以及模块化编程。通过实践技巧与案例分析,展示了PDL在数据处理和算法实
【天线原理与设计挑战实战】:华为射频天线笔试题深度解读与实践应用
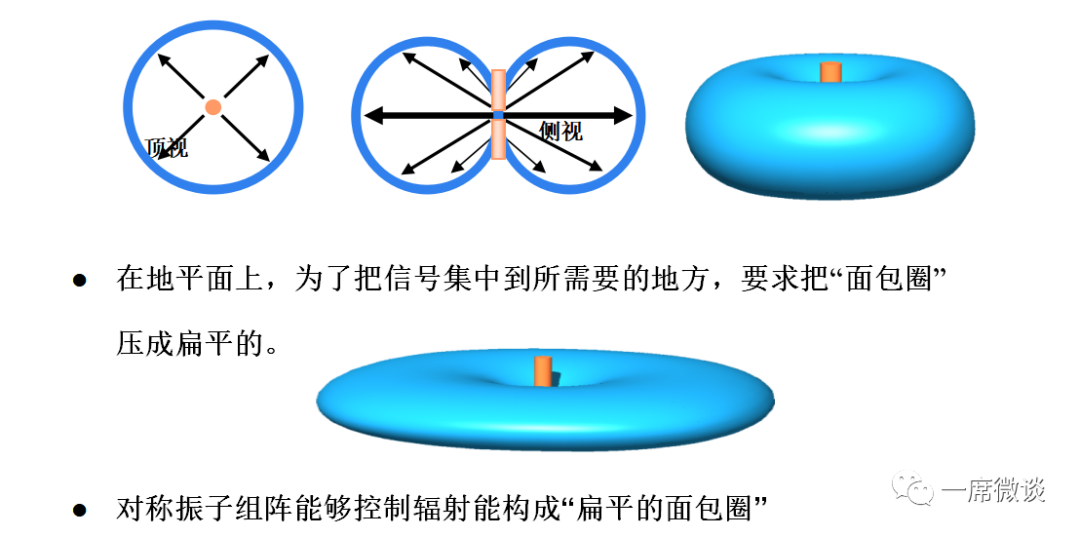
# 摘要
射频天线作为无线通信系统的关键组成部分,其性能直接影响到通信质量和效率。本文首先回顾了天线基础理论,随后深入探讨了射频天线设计的核心概念,包括天线参数、性能指标、馈电技术以及辐射与传播原理。通过分析华为射频天线笔试题,本文进一步解读了试题类型、考核点以及应对策略,为射频天线设计人员提供了实用的分析和应用指导。在实战案例部分,文章详细介绍了天线设计流程和挑战,以及设计工具和软件的实际应用。最后,本文展望了射频天线设
Win7通信工具大比拼:Hyper_Terminal与竞品软件深度对比(选对工具,效率翻倍)
# 摘要
随着Win7时代的结束,用户对于通信工具的需求不断演变,Hyper_Terminal作为一种经典终端仿真软件,其在界面与功能上的特点、性能评估、独特优势的探讨,是本文第一章与第二
B50610-DS07-RDS驱动程序管理黄金法则:维护更新无缝对接
# 摘要
本文全面探讨了RDS驱动程序的管理,强调了理解其重要性、维护策略以及更新实践操作的必要性。通过对驱动程序作用、生命周期管理以及故障诊断基础的分析,揭示了驱动程序如何影响系统性能,并对如何有效更新和维护驱动程序提供了深入的见解。特别关注了自动化管理、云环境下的驱动程序管理和容器化环境下的驱动程序兼容
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )