【BioEdit数据处理秘诀】:高效处理序列数据的实战案例分析
发布时间: 2024-12-13 21:58:21 阅读量: 12 订阅数: 13 

参考资源链接:[BioEdit软件全方位指南:序列分析与编辑](https://wenku.csdn.net/doc/64ab5c2b2d07955edb5d6e4e?spm=1055.2635.3001.10343)
# 1. BioEdit简介与序列数据处理基础
BioEdit是一个广泛应用于分子生物学领域的免费序列编辑软件,它为研究人员提供了一个便捷的平台来处理、分析和编辑序列数据。在本章中,我们将简要介绍BioEdit的基本功能,并带你了解如何处理序列数据,从而为深入学习和使用这个工具打下坚实的基础。
## 1.1 BioEdit概述
BioEdit以用户友好的界面和一系列专业工具著称,它支持多种格式的序列文件,并能够无缝集成多种生物信息学分析功能,如序列比对、进化树构建等。
## 1.2 序列数据处理的重要性
在生物信息学研究中,准确和高效地处理序列数据是至关重要的。这包括数据的导入导出、校对、注释和标记等多个步骤,为后续分析打下坚实的基础。
## 1.3 安装和运行BioEdit
安装BioEdit非常简单,只需下载最新版本,解压并运行安装程序即可。初次运行时,建议熟悉其界面布局和功能菜单,以便快速上手使用。
在后续章节中,我们将逐一深入探讨BioEdit在序列编辑与管理、序列数据分析与比较、以及高级功能实战等方面的详细应用,让你能够更加高效地处理生物信息学数据。
# 2. BioEdit中的序列编辑与管理
## 2.1 序列数据的导入和导出
### 2.1.1 支持的文件格式
BioEdit作为一个强大的序列编辑工具,支持多种格式的生物序列文件导入和导出。它能够读取和保存常见的序列格式,比如FASTA、GENBANK、EMBL等。此外,对于序列和序列相关的注释信息,如GFF、CLUSTAL等格式,它也提供了良好的支持。这些多样化的支持保证了用户可以从各种渠道获取数据,并在BioEdit中方便地处理它们。
### 2.1.2 数据转换与批量处理
在处理大量数据时,数据转换和批量处理显得尤为重要。BioEdit允许用户在导入数据时进行格式转换,还可以批量地对多个文件执行相同的操作。通过“File”菜单下的“Batch”选项,用户可以导入一个文件夹中的所有序列文件,并统一进行格式转换或编辑。例如,用户可以批量地将一系列的`.txt`格式序列文件转换为`.fas`格式,为后续的序列分析做好准备。这个功能极大地提高了工作效率,特别是当面对庞大的基因组或转录组数据时。
```mermaid
flowchart LR
A[开始] --> B[选择文件夹]
B --> C[指定输出格式]
C --> D[批量转换]
D --> E[完成]
```
在这个流程图中,我们可以看到批量处理的步骤被清晰地描绘出来。这个过程不仅简化了操作,也使得对大规模数据集的管理变得更为高效。
## 2.2 序列的校对与编辑
### 2.2.1 校对工具的使用
序列校对是序列编辑的一个重要步骤,目的是确保序列数据的准确性。BioEdit提供了内建的校对工具,可以自动检测并修正错误的碱基。操作过程中,用户可以设置校对的严格程度,并且能够查看每个被修改的位点,从而决定是否接受这些更改。
```mermaid
graph LR
A[开始校对] --> B[检查序列错误]
B --> C[显示修改建议]
C --> D[手动确认或自动修正]
D --> E[完成校对]
```
校对工具的应用不仅仅局限于单一序列,它也适用于批量的序列数据。通过这种方式,即使是数量庞大的序列数据也能得到快速而准确的校对。
### 2.2.2 编辑技巧和快捷操作
BioEdit的编辑功能包括了剪切、复制、粘贴以及插入序列片段等基本操作,同时还包含了一些高级功能,如序列的反向互补转换和序列段的提取。此外,用户还可以自定义快捷键,以加快编辑效率。通过菜单“Edit”可以找到所有编辑相关的操作,而“Tools”菜单下则提供了更多的便捷工具,比如序列查找和替换功能。
为了提高编辑效率,这里提供一个快捷操作的代码示例:
```plaintext
快捷键操作:
Ctrl + C - 复制选中的序列区域
Ctrl + V - 粘贴之前复制的序列区域
Ctrl + F - 打开序列查找窗口
```
这些快捷键可以显著提高编辑操作的速度,特别是当需要对多个序列进行重复操作时。
## 2.3 序列数据的注释与标记
### 2.3.1 注释功能的应用
注释是指在序列数据中标记特定信息的过程,比如基因位置、突变位点或功能区域。BioEdit提供了直观的注释界面,用户可以点击序列上的特定位置来添加注释,还可以为注释添加颜色标签,以便于区分不同类型的注释信息。
```plaintext
操作步骤:
1. 在序列视图中选择需要注释的区域
2. 点击“Annotate”菜单并选择“Add New Annotation”
3. 输入注释信息,并选择注释颜色
4. 点击“OK”确认添加注释
```
利用注释功能,用户可以为特定的序列区域标注详细的信息,这对于后续的序列分析和解释非常有帮助。
### 2.3.2 标记序列的特定区域
在序列编辑的过程中,标记特定区域是一个不可或缺的功能。BioEdit中的标记工具可以用于高亮显示或者标记序列的某些特定部分。例如,在进行序列比对时,可以对那些差异显著的区域使用标记工具进行标记,以便于进行详细的分析。
```plaintext
标记操作:
1. 在序列视图中选择要标记的区域
2. 点击“Tools”菜单并选择“Mark Selected Region”
3. 选择标记类型,如颜色标记或下划线标记
4. 点击“OK”完成标记
```
通过这样的标记操作,用户可以快速地识别出序列中的重要区域,这在分析序列变异或研究特定功能区域时尤为重要。
在本章节中,我们详细探讨了BioEdit在序列数据处理中的关键功能,包括序列数据的导入导出、校对与编辑技巧、以及注释和标记操作。这些功能对于生物信息学研究者来说是基础且必不可少的,能够有效地帮助他们管理和准备用于分析的序列数据。接下来的章节将进一步深入到序列数据分析与比较的策略和应用。
# 3. 序列数据分析与比较
## 3.1 序列比对的策略
### 3.1.1 局部比对与全局比对
序列比对是生物信息学中的一项基本而关键的步骤,它涉及将两条或多条序列按照相似性进行排列对比,以便找出它们之间的共有模式或差异。在BioEdit中进行序列比对,主要分为局部比对(Local Alignment)和全局比对(Global Alignment)两种策略。
局部比对通常用于比对序列中的一段高度相似的区域,而全局比对则尝试对整个序列范围内的相似性进行评估。局部比对特别适用于查找序列中相似性最高的短片段,这在寻找功能域、基因、或特定序列模式时尤为重要。
例如,使用Smith-Waterman算法进行的局部比对,允许在序列之间进行间隙的引入以识别高度相似的区域,而不必考虑两端的序列可能会有大的不匹配。而Needleman-Wunsch算法是全局比对的经典方法,要求在整个序列长度内寻找最优比对,通常在比对全长基因序列时使用。
在实际操作中,用户可以根据自己的需求选择合适的比对策略。例如,进行进化分析时可能更倾向于使用全局比对,而在寻找保守序列或功能域时,局部比对则更为适合。
### 3.1.2 参数设定与调整
进行序列比对时,参数的设定对于结果的准确性和可靠性至关重要。BioEdit为用户提供了一系列的可调节参数,允许用户根据具体情况进行定制化设置。
在局部比对中,用户可以调整的参数包括:匹配得分(match score)、不匹配惩罚(mismatch penalty)、间隙开启惩罚(gap open penalty)、间隙扩展惩罚(gap extension penalty)等。而在全局比对中,虽然可调节的参数与局部比对相似,但是它们的意义和影响略有不同。例如,间隙开启惩罚在全局比对中可能更为重要,因为它影响到整个序列比对的间隙分布。
此外,为了提高比对的灵敏度,BioEdit还提供了一些特殊的选项,例如使用递归算法来处理多个局部相似区域。在调整这些参数时,用户应当根据比对序列的特点以及分析的目的来综合考虑。
接下来的案例分析中,我们将通过实际的序列比对任务,展示如何在BioEdit中进行参数设定和调整,以及这些设置对最终分析结果的影响。
## 3.2 序列相似性分析
### 3.2.1 相似性搜索工具
在生物信息学研究中,相似性搜索(similarity search)是用来发现序列数据库中与目标序列具有相似性的序列。BioEdit提供了一些常用的相似性搜索工具,如BLAST (Basic Local Alignment Search Tool),用于快速地查找序列数据库中的相似序列。
BLAST搜索工作原理是通过查找短序列的近似匹配(称为“单词”或“种子”),然后扩展这些匹配区域,评估它们之间的相似度得分,并以此来预测整个序列的相似性。BioEdit内嵌的BLAST工具支持对各种类型的序列进行快速搜索,包括蛋白质、核苷酸、转录组以及特定的序列数据库等。
### 3.2.2 结果的解读与应用
完成相似性搜索后,得到的结果需要进行详细的解读。BioEdit的BLAST结果界面会展示一系列的比对序列,每个比对序列都附有统计信息,例如E值、得分以及相似性百分比等。E值是判断比对结果的显著性的重要指标,它代表了随机产生这样一个匹配的概率。得分则是衡量序列比对相似程度的量化标准,得分越高表示相似性越高。
在解读这些结果时,需要重点关注E值和得分,以确定找到的序列是否具有生物学意义。E值较低且得分较高的匹配通常被认为是较为可信的,可以作为后续功能研究和进化分析的参考。
除了BLAST之外,BioEdit还支持包括Smith-Waterman算法在内的多种搜索工具,可帮助用户在不同层次和粒度上进行序列的相似性分析。
在本节的后续部分,我们将通过具体操作步骤演示如何使用BioEdit中的BLAST工具进行序列相似性搜索,并对搜索结果进行解读。
## 3.3 多序列比对与进化树构建
### 3.3.1 多序列比对的原理
多序列比对(Multiple Sequence Alignment, MSA)是将三个或三个以上的相关序列进行比对,以便揭示序列之间的一致性和差异性。这在分析蛋白质家族进化、基因组比对以及进化树构建等方面都有重要应用。
MSA通过识别序列间的一致性模式,能够展示出不同序列共享的保守区域,这对于理解基因的进化过程至关重要。MSA的算法通常基于序列间相似性的最大化原则,如通过动态规划算法构建Pile Up矩阵。对于不同长度和相似性的序列,MSA的方法和复杂性也有所不同。
BioEdit通过集成多种先进的MSA工具,如ClustalW,提供了多种序列比对策略,用户可以根据比对序列的特点和研究目标选择最合适的方法。
### 3.3.2 进化树构建的方法和工具
构建进化树是研究物种进化关系和基因变异的重要手段。在进行多序列比对之后,构建进化树可以揭示不同物种或序列之间的亲缘关系,为遗传多样性和进化机制的研究提供基础。
进化树的构建方法主要包括距离法(如Neighbor-Joining,NJ),特征法(如Maximum Parsimony,MP)和似然法(如Maximum Likelihood,ML)。BioEdit提供了对这些方法的支持,用户可以根据数据的特性和研究的需求选择使用不同的进化树构建工具。
进化树构建完毕后,用户通常会对树进行美化和注释,比如调整节点标签、分支长度、树的布局等,以便于后续的分析和展示。BioEdit允许用户直接在软件内进行这些操作,也可以将树导出到其他专业软件中进行进一步的分析和编辑。
接下来的章节,我们会通过实际操作,详细介绍如何在BioEdit中构建多序列比对和进化树,并对这些过程进行深入的解读。
# 4. BioEdit高级功能实战
### 4.1 序列数据的自动化处理
#### 4.1.1 宏命令的录制与使用
在处理大量的序列数据时,手动执行每一个编辑和分析步骤可能会非常耗时。幸运的是,BioEdit 提供了宏命令(Macro)功能,它允许用户录制一系列操作,然后将这些操作保存为一个可重复使用的脚本,之后可以应用到其他序列数据上,极大地提高了工作效率。
要录制宏命令,用户首先需要执行一遍他们想要自动化的一系列操作。在操作过程中,确保每一步都清晰准确。BioEdit 会记录下每一步的操作,然后将这些步骤保存为一个文本文件。这个文本文件可以被编辑,以适应不同的数据集或者进行微调。
使用宏命令的步骤如下:
1. 打开 BioEdit,载入需要处理的序列数据。
2. 执行需要自动化的一系列操作。
3. 在工具栏选择“宏”(Macro)菜单,选择“开始录制”(Start Recording)。
4. 执行你想要保存为宏命令的操作。
5. 再次在“宏”菜单中选择“停止录制”(Stop Recording)。
6. 选择“保存宏”(Save Macro),给你的宏命名,并保存到一个文件中。
宏命令脚本通常包含一系列的命令和操作,下面是一个简单的宏命令例子:
```plaintext
open "C:\sequences\example.fasta"
selectall
copy
粘贴到新文件
保存 "C:\sequences\processed_example.fasta"
```
这个宏会打开一个名为 `example.fasta` 的文件,复制全部内容,并粘贴到一个新的文件中,然后保存为 `processed_example.fasta`。
#### 4.1.2 批量数据处理的策略
批量处理数据是 BioEdit 中一个非常强大的功能,它可以通过简单的脚本实现复杂的序列编辑和分析任务。批量处理可以使用宏命令脚本或者编写特定的批处理文件。在编写批处理文件时,用户需要利用 BioEdit 的脚本语言,通常这些脚本语言能够接受命令行参数,从而实现对不同数据集的自动化处理。
例如,下面的批处理命令将会对一个文件夹中的所有 `.fasta` 文件执行同样的宏命令:
```bash
foreach %i in (*.fasta) do BioEdit.exe -macro "C:\macros\my_macro.txt" -open %i
```
这个命令会打开 `C:\macros\my_macro.txt` 中定义的宏命令,并应用于当前目录下所有的 `.fasta` 文件。
在处理大量数据时,可能需要考虑以下策略:
- **分批处理**: 对数据集进行分批处理,以避免内存溢出或软件崩溃。
- **数据备份**: 在开始批量处理之前,始终做好原始数据的备份,以防操作过程中出现错误。
- **错误检查**: 确保在宏命令中包含检查错误的步骤,并对可能出现的异常情况进行处理。
- **日志记录**: 记录批处理的每一个步骤和结果,以便事后跟踪和分析。
### 4.2 序列数据的可视化展示
#### 4.2.1 图形化编辑功能
BioEdit 提供了图形化编辑功能,允许用户以图形化的方式查看和编辑序列。这一功能尤其在处理DNA序列时非常有用,因为它可以直观地展示出各种序列特征,如启动子、内含子、外显子等。用户可以在图形界面中直接点击并编辑特定区域,这大大简化了序列特征的识别和标注过程。
实现图形化编辑的步骤如下:
1. 打开需要编辑的序列文件。
2. 在菜单栏中选择“视图”(View),然后选择“图形化编辑”(Graphical Editing)。
3. 用户可以看到一个以图形化形式展示的序列。序列中的每个碱基都以不同的颜色表示。
4. 使用工具栏中的选择工具,用户可以选择特定的碱基或区域,并进行编辑、删除或者添加操作。
5. 编辑完成后,用户可以选择“保存”(Save)或者“导出”(Export)以保留更改。
图形化编辑功能不仅限于查看和编辑,它也可以用来帮助用户更好地理解序列数据,并对其进行注释。此外,图形化编辑还支持将序列的特定区域或特征导出为图形文件,方便后续的报告和展示使用。
#### 4.2.2 结果的图形化输出
BioEdit 还支持将分析结果以图形化的方式输出。例如,在多序列比对后,用户可以通过图形化输出来查看比对结果的详细情况,包括保守区域、插入缺失等信息。这种输出形式比纯文本格式更直观,也更易于解读。
输出图形化结果的步骤通常如下:
1. 进行完序列分析或比对后,在结果窗口中,选择“导出”(Export)功能。
2. 在导出菜单中选择合适的图形化输出选项,比如导出为图片格式(如 PNG、JPEG)或矢量图形格式(如 SVG)。
3. 根据需要调整输出的参数,比如图片大小、分辨率、颜色主题等。
4. 点击导出按钮,BioEdit 将会创建一个包含分析结果的图形文件。
导出的图形文件可以用于报告、演示或者进一步的分析。图形化输出不仅提高了分析结果的可读性,也方便与其他研究人员的交流和合作。
### 4.3 生物信息学分析流程整合
#### 4.3.1 第三方工具的集成
BioEdit 的一个显著特点是它能够集成许多第三方的生物信息学工具。这意味着用户可以在 BioEdit 环境中直接调用外部软件来进行更专业的分析,而无需离开 BioEdit 的界面。这种集成不仅提高了分析效率,还能够帮助用户更好地管理整个分析流程。
集成第三方工具通常需要以下步骤:
1. 确保第三方工具已经安装在用户的计算机上,并且可以在命令行中运行。
2. 在 BioEdit 中,通过菜单栏选择“工具”(Tools)>“集成工具”(Integrated Tools),然后选择“安装新工具”(Install New Tool)。
3. 按照提示输入第三方工具的名称、命令行调用格式、必要的参数等信息。
4. BioEdit 将会保存这些设置,并允许用户从 BioEdit 的菜单中直接运行这些工具。
BioEdit 支持通过命令行参数集成工具,例如:
```plaintext
# 假设有一个名为 "blastp" 的工具需要集成
commandline = blastp -query "%s" -db "%d" -out "%o"
```
这里,`%s`、`%d` 和 `%o` 分别代表序列文件、数据库文件和输出文件的路径占位符。
#### 4.3.2 定制化分析流程的创建
BioEdit 允许用户创建定制化的分析流程。这意味着用户可以根据自己的研究需求,将一系列的编辑、分析和第三方工具调用步骤整合到一个流程中。这个流程可以被保存和重复使用,极大地方便了重复性分析任务的处理。
创建定制化分析流程的步骤可能包括:
1. 按照用户的分析需求,规划整个流程的步骤。
2. 使用宏命令录制功能,录制每一步的执行命令。
3. 将录制的宏命令和第三方工具的命令整合到一起,形成一个完整的分析流程。
4. 保存这个流程,以便于将来的使用。
5. 在需要进行相同分析时,只需加载并运行这个流程,BioEdit 将自动执行所有步骤。
通过上述方法,BioEdit 提供了一个高度可定制化且用户友好的环境,使得复杂和重复性的生物信息学分析变得简单和高效。
# 5. 案例研究:从理论到实践的应用
在前四章中,我们深入了解了BioEdit的诸多功能和实用技巧,现在是时候将这些知识运用到实际案例中去,以展示BioEdit在序列数据分析和处理中的实际应用价值。
## 5.1 研究案例的选择与背景
### 5.1.1 案例研究的领域和目标
选择一个合适的研究案例是进行案例研究的第一步。理想的情况是选择一个与你的研究兴趣或实际工作紧密相关的案例。例如,如果你对病毒进化感兴趣,你可能会选择一个关于流感病毒株间变异的研究案例。案例的目标可能是要揭示特定病毒株的演化路径,或评估不同疫苗对病毒变异的影响。
### 5.1.2 数据集的准备和预处理
研究案例的成功在很大程度上取决于数据的质量和相关性。数据集的准备包括收集序列数据、去除低质量序列、过滤噪音、以及填补可能存在的序列间空缺。预处理步骤还可能包括对数据集的标准化处理,确保所有序列都具有相同的起始点和阅读框架。在BioEdit中,可以利用其提供的多种功能来完成上述工作,例如使用“序列排序”、“删除低质量区域”等功能来清洗数据。
## 5.2 BioEdit在案例中的应用
### 5.2.1 序列数据的编辑和比对
在BioEdit中进行序列数据编辑和比对,是数据分析的重要步骤。具体操作可能包括:
- 使用“序列比对”功能,对数据集中的序列进行全局比对。
- 通过“编辑比对”功能,调整序列的错位,以优化比对结果。
- 使用“颜色编码”工具,对特定核苷酸或氨基酸进行标记,这有助于快速识别序列间的相似性和差异性。
### 5.2.2 分析结果的解读与验证
在比对完成后,我们需要解读序列分析结果。BioEdit提供了便捷的“一致性图”和“差异图”视图,帮助我们可视化比对中的高度一致和差异区域。此外,利用内置的“进化树构建”功能,可以进一步验证序列间的亲缘关系,为进化分析提供直观的树状结构图。
## 5.3 案例总结与拓展思考
### 5.3.1 案例中遇到的问题与解决方案
在案例实践中,可能会遇到多种问题,如序列不一致、比对错误、分析工具的限制等。例如,在一个案例研究中,我们可能发现某些序列具有异常的变异率。为了解决这个问题,我们可能会选择使用更加高级的比对算法,或者利用其他专业软件工具进行交叉验证。
### 5.3.2 对未来研究方向的启示
从案例研究中得到的洞察,不仅可以帮助我们解决具体问题,还能指导我们进行更深入的研究探索。例如,案例中发现的特定突变模式可能引导我们进一步研究病毒的宿主范围和致病性。而这样的研究又可能为新药开发或疫苗设计提供重要的科学依据。
通过这个案例研究,我们不仅应用了BioEdit的多种功能,还学会了如何将这些功能与实际研究问题相结合,解决了研究中可能遇到的具体挑战。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《BioEdit 使用说明书(中文版)》专栏是一本全面且深入的 BioEdit 软件使用指南,专为初学者、高级用户和生物信息学专业人士而设计。该专栏涵盖了从基础操作到高级功能和定制化设置的各个方面,并提供了数据处理、自动化流程、文件转换、序列对比、编辑效率提升、数据修剪、数据可视化、分析能力倍增、宏命令编程、BLAST 搜索、蛋白结构预测、序列信息解读、序列模式发现和进化树分析等主题的深入指南。通过阅读本专栏,读者将掌握 BioEdit 的所有功能,并能够高效地处理和分析生物序列数据。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Funcode坦克大战:事件驱动编程模式的C语言实现与图形用户界面(GUI)设计

# 摘要
本文全面探讨了在事件驱动编程模式下使用C语言实现的Funcode坦克大战游戏的开发过程。首先介绍了游戏的基本概念和C语言基础,随后深入讨论了游戏逻辑构建、事件处理机制和动态内存管理
【Arlequin数据清洗艺术】:打造无瑕数据集的12大技巧

# 摘要
本文全面阐述了Arlequin数据清洗的理论与实践应用。首先概述了数据清洗的重要性和基本步骤,强调了数据质量对分析的重要性以及数据清洗在业务决策中的作用。接着,深入探讨了Arlequin数据清洗的核心技术,包括与其它工具的比较、在不同领域的应用以及关键技术如数据分割、合并、转换和规范化。通过实际案例分析,展示了Arlequin在数据清洗前后的效果对比,并针对特定行业挑战提出了
掌握事务管理与数据库优化:蛋糕商城性能调优秘籍

# 摘要
本文详细介绍了数据库事务管理的基础知识,包括事务的ACID属性、隔离级别和并发控制机制,以及数据库查询优化技术和索引策略对性能提升的作用。通过对蛋糕商城的案例分析,本文展示了实际业务场景中应用性能调优的实践,包括性能瓶颈诊断、事务管理调整、查询与索引优化等。本文旨在为数据库管理员和开发人员提供一套完整的理论知识与实践经验,帮助他们更有效地管理和优化数据库性能。
# 关键字
数据库事务管理;ACID
信捷PLC XC系列软件编程:功能块与数据通讯的6项技巧
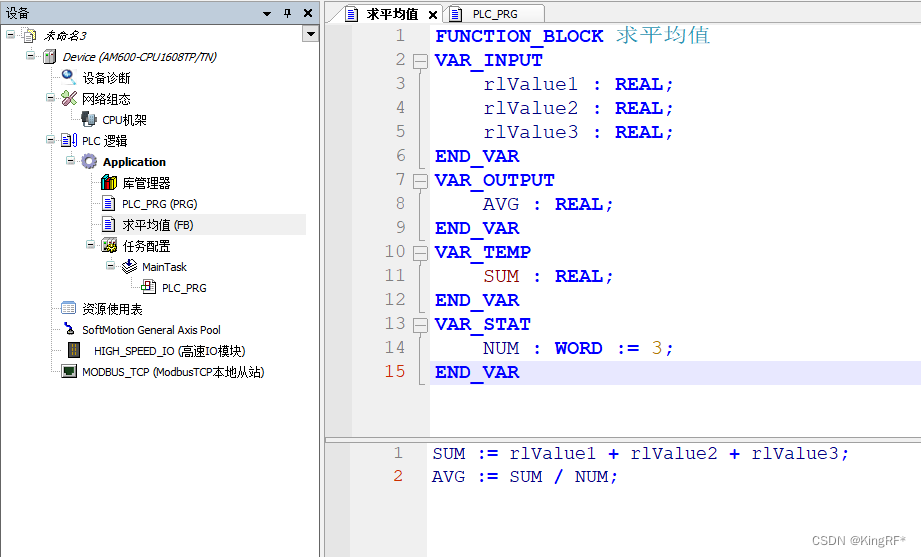
# 摘要
本文全面探讨了信捷PLC XC系列软件编程的核心概念、功能块的使用技巧、数据通讯机制及其在实际中的应用。通过对功能块的基础与高级应用的详细介绍,本文阐述了功能块的定义、分类、创建、管理以及在程序中的实际应用。同时,详细解析了数据通讯机制的原理、类型、配置以及高级应用策略。文章还探讨了功能块与数据通讯集成的技巧,并通过案例研究展示了在实际应用中问题的解决方法。最后,本文展望了新技术在PLC中
【杰理AC695N音频处理秘籍】:高品质音频解决方案揭秘
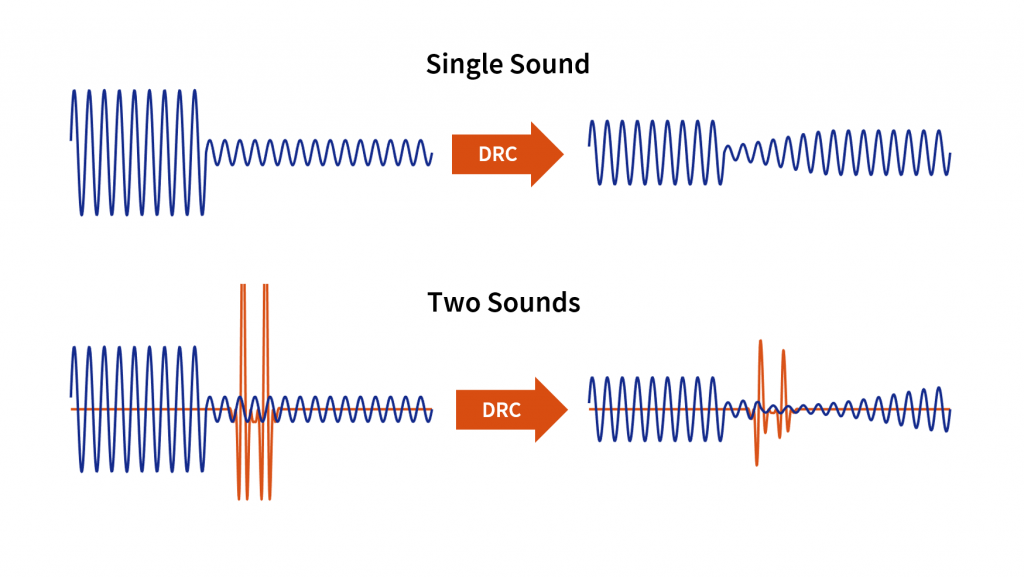
# 摘要
杰理AC695N音频处理器是一个在音频信号处理领域具有重要地位的芯片,它在现代音频设备中扮演着核心角色。本文首先对杰理AC695N音频处理器进行了全面的概述,并介绍了其硬件架构、软件开发环境以及音频处理应用案例。随后,深入探讨了音频处理的理论基础,包括数字信号处理原理、音频信号的增强技术、编码与解码技术,以及高级音频处理技巧,如实时分析与处
【动态状态管理】:用CSS控制复选框的选中与未选中效果

# 摘要
随着Web界面的动态性和交互性日益增强,CSS在动态状态管理中的作用变得愈发重要。本文深入探讨了CSS在复选框选择器的应用,展示了如何利用CSS属性和伪类控制复选框的视觉状态,以及如何通过JavaScript实现状态的动态控制和管理。文章还讨论了跨浏览器兼容性和性能优化的策略,并展望了CSS预
Adex meter AE1152D 编程接口深度剖析:自动化测量的新境界

# 摘要
本文详细介绍了Adex meter AE1152D的编程接口,涵盖了其基础理论、实践应用以及进阶功能开发。首先,概述了编程接口的功能与结构、支持的编程语言以及通信协议,并提供了接口的初始化与配置指南。接着,通过具体实践案例,探讨了数据读取写入操作、错误处理和日志记录,并分享了自动化测试与数据分析的高级应用。此
【Transmate高级使用教程】:Cat软件复杂数据结构转换的艺术
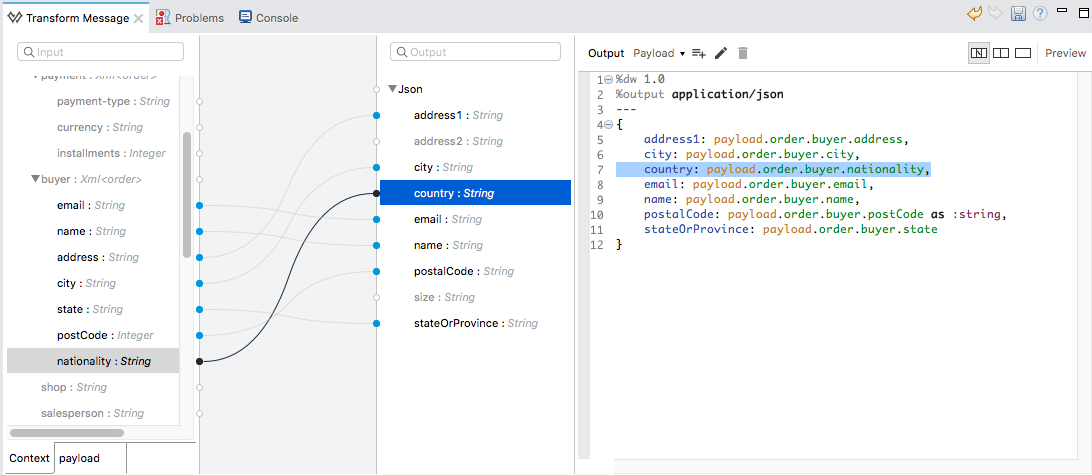
# 摘要
Cat软件作为数据转换领域的创新工具,已成为处理各种数据结构转换的首选解决方案。本文全面解析了Cat软件的核心功能、性能优化以及安全性策略,并深入探讨了其在处理复杂数据结构转换中的实用技巧。同时,本文还分析了Cat软件在多个行业中的实际应用案例,展示了其在项目管理与自定义扩展方面的能力。此外,文章也展望了Cat软件的未来发展,以及行业趋势如何影响其功
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )