【Go:generate高级技巧】:掌握参数化代码生成与环境管理,提升代码质量
发布时间: 2024-10-23 02:23:23 阅读量: 29 订阅数: 17 

代码生成 内容生成 golang代码生成
# 1. Go:generate命令的入门介绍
## 1.1 Go:generate命令基础
Go:generate是一个工具,它允许在构建Go程序之前自动运行用户定义的命令。这个特性非常强大,因为它可以自动生成代码,例如,根据Go结构体字段生成对应的SQL查询。这一章节会带你了解如何使用这个命令,包括其基本语法和作用。
## 1.2 使用Go:generate进行代码生成
我们将一步步介绍如何在Go项目中设置和使用Go:generate命令。我们会通过一个简单的例子,展示如何定义一个结构体,并使用Go:generate生成该结构体的JSON序列化函数。
```go
// example.go
type Person struct {
Name string
Age int
}
//go:generate go run generate.go
```
生成代码的`generate.go`文件可能包含以下内容:
```go
// generate.go
package main
import (
"fmt"
"os"
"text/template"
)
func main() {
templ := template.Must(template.New("person").Parse(`// AUTO-GENERATED CODE - DO NOT EDIT
func (p Person) MarshalJSON() ([]byte, error) {
// Implementation
}
`))
err := templ.Execute(os.Stdout, nil)
if err != nil {
fmt.Println("execution error:", err)
}
}
```
## 1.3 Go:generate的集成与优化
为了最大限度地提高效率,我们会探讨如何将Go:generate命令集成到项目构建流程中,并提出一些优化建议。这包括介绍如何触发代码生成,以及如何在持续集成环境中自动化这一过程。
通过本章,你将学会Go:generate的基本知识,并开始实践代码自动生成的初级技巧。这将为深入理解后续章节的高级技术打下坚实的基础。
# 2. ```
# 第二章:参数化代码生成的高级技巧
Go语言的`go:generate`命令不仅可以在编译前执行自定义的代码生成任务,还可以通过参数化模板的方式使代码生成更加灵活和强大。本章节将详细介绍参数化生成的基本原理,并通过实践应用展示如何使用参数化模板生成代码,同时分析高级参数化场景。
## 2.1 参数化生成的基本原理
参数化生成允许开发者通过参数来控制模板的行为和输出,这使得同一模板可以针对不同的输入数据产生多种不同的输出代码,增强了代码生成的灵活性。
### 2.1.1 了解模板系统
Go语言内置了一个文本模板系统,它允许开发者定义带有占位符的模板,然后将这些占位符替换为实际的数据。在Go的`text/template`包中,开发者可以使用`{{`和`}}`包围的表达式来标记要被替换的变量或函数调用。模板系统支持条件判断和循环控制等结构,可以在模板渲染时根据参数动态地改变输出结果。
### 2.1.2 掌握模板语法
掌握Go模板语法对于编写参数化模板至关重要。模板语法包括变量引用、管道、条件语句、循环控制、预定义函数和自定义函数等。例如:
- 变量引用使用`{{.}}`表示当前对象。
- 管道操作符`|`用于连接函数。
- 条件语句如`{{if}} ... {{else}} ... {{end}}`。
- 循环控制如`{{range}} ... {{end}}`。
## 2.2 参数化的实践应用
在实践中,参数化模板的使用可以极大提升代码生成的效率和质量。下面将探讨如何使用参数化模板生成代码,以及如何处理模板中的变量和函数。
### 2.2.1 使用参数化模板生成代码
假设我们需要为不同的数据结构生成序列化和反序列化的代码,我们可以创建一个参数化模板来完成这项任务。首先,我们定义一个模板文件,比如`serialize.tmpl`:
```
// 代码模板示例
type {{.TypeName}} struct {
{{range .Fields}} {{.Name}} {{.Type}} {{end}}
}
// Serialize serializes the {{.TypeName}} to a string.
func (s *{{.TypeName}}) Serialize() string {
// 序列化逻辑
}
// Deserialize deserializes a string into a {{.TypeName}}.
func (s *{{.TypeName}}) Deserialize(data string) error {
// 反序列化逻辑
}
```
然后,我们可以创建一个Go程序来填充这个模板,并生成对应的Go文件:
```go
package main
import (
"text/template"
"os"
"fmt"
)
type TypeData struct {
TypeName string
Fields []struct {
Name string
Type string
}
}
func main() {
typeData := TypeData{
TypeName: "ExampleType",
Fields: []struct {
Name string
Type string
}{
{"ID", "int"},
{"Name", "string"},
},
}
tmplate := template.Must(template.New("serialize").Parse(`/* 模板内容 */`))
file, err := os.Create("serialize_example.go")
if err != nil {
panic(err)
}
defer file.Close()
tmplate.Execute(file, typeData)
}
```
### 2.2.2 处理模板变量和函数
在模板中,可以使用变量来存储临时数据,也可以定义和使用自定义函数来执行复杂的逻辑。例如,我们可以在模板中定义一个函数来检查字段名称是否符合命名规范:
```go
func checkName(name string) bool {
return name != "" && name[0] == strings.ToUpper(name[0])
}
```
然后在模板中使用该函数:
```
// 使用{{call}}语法调用自定义函数
{{range .Fields}}
{{if call .checkName .Name}}
// 成功通过命名检查的字段
{{else}}
// 不符合命名规范的字段
{{end}}
{{end}}
```
## 2.3 高级参数化场景分析
参数化不仅可以应用于简单的模板替换,还可以处理更复杂的场景,比如条件参数化生成、循环参数化生成和模板嵌套重用策略。
### 2.3.1 条件参数化生成
在模板中,通过条件判断可以根据传入的参数来决定哪些代码段应当被生成。例如,基于输入参数的不同,可以决定生成不同的错误处理代码块:
```
{{if .UseErrorHandling}}
// 错误处理代码
{{else}}
// 忽略错误处理
{{end}}
```
### 2.3.2 循环参数化生成
循环可以用来迭代模板变量中的切片或映射,并生成重复的代码结构。这对于自动化生成结构体的初始化代码或测试用例特别有用:
```
{{range .Items}}
{{.}}
{{end}}
```
### 2.3.3 模板嵌套和重用策略
在参数化模板中,一个模板可以调用另一个模板,从而实现模板的嵌套和重用。这允许将通用的代码片段放在一个单独的模板文件中,并在需要的地方调用它:
```
{{define "myTemplate"}}
// 通用代码片段
{{end}}
{{template "myTemplate"}}
```
通过这些高级技巧,可以显著提高代码生成的质量和效率。开发者可以根据项目的实际需求,设计和实现更加复杂和强大的代码生成逻辑。接下来,我们将探讨如何通过环境管理技巧来进一步提升`go:generate`的效率。
```
在本章节中,我们通过理论与实践相结合的方式,详细介绍了参数化代码生成的高级技巧。我们从参数化模板的基本原理出发,涵盖了模板系统的了解和模板语法的掌握。通过实践应用的例子,演示了如何使用参数化模板来生成代码,并具体分析了如何处理模板中的变量和函数。最后,我们深入探讨了高级参数化场景,包括条件参数化生成、循环参数化生成以及模板嵌套和重用策略,为开发者在不同场景下使用参数化代码生成提供了具体指导。
# 3. 环境管理技巧提升Go:generate效率
## 3.1 环境变量在Go:generate中的应用
### 3.1.1 定义和使用环境变量
在开发过程中,我们经常需要为不同的环境(如开发、测试、生产)配置不同的参数。环境变量是解决这个问题的理想选择。Go:generate 允许你在命令中使用环境变量,通过这种方式,你可以轻松地为不同的环境定制代码生成过程。
假设你有一个 Go:generate 命令用于生成数据库的模型层代码。在生产环境中,你可能需要连接到一个实际的数据库,而在开发环境中,你可能只需要连接到一个测试数据库。这时,你可以使用环境变量来区分这些配置。
```sh
# 在 Unix-like 系统中设置环境变量
export DB_HOST=production-db-host
export DB_USER=production-db-user
export DB_PASS=production-db-pass
# 在 Windows 系统中设置环境变量
set DB_HOST=production-db-host
set DB_USER=production-db-user
set DB_PASS=production-db-pass
```
然后,你的 Go:generate 命令可能是这样的:
```sh
go:generate -db-host=$DB_HOST -db-user=$DB_USER -db-pass=$DB_PASS mymodelgen
```
在 `mymodelgen` 程序中,你可以通过命令行参数或者环境变量获取这些值:
```go
// 获取环境变量
dbHost := os.Getenv("DB_HOST")
dbUser := os.Getenv("DB_USER")
dbPass := os.Getenv("DB_PASS")
```
### 3.1.2 环境变量的动态配置
除了静态设置环境变量之外,你还可以在 Go:generate 命令执行过程中动态配置环境变量。这意味着你可以在生成代码前根据特定条件调整环境变量的值。
下面是一个简单的 Go 代码示例,展示了如何在运行 Go:generate 命令前动态设置和清理环境变量:
```go
package main
import (
"os"
"os/exec"
)
func main() {
// 模拟动态设置环境变量
os.Setenv("DB_HOST", "dynamic-db-host")
os.Setenv("DB_USER", "dynamic-db-user")
os.Setenv("DB_PASS", "dynamic-db-pass")
// 执行 Go:generate 命令
cmd := ***mand("go", "generate", "-run", "Mymodelgen")
cmd.Run()
}
```
在这个场景中,环境变量是临时设置的,仅对当前的 Go:generate 过程有效,不会影响其他程序或会话中的环境变量。
## 3.2 构建环境与依赖管理
### 3.2.1 环境依赖的识别
在使用 Go:generate 的项目中,常常需要对特定的工具或库产生依赖。识别这些依赖是很重要的,它确保在任何环境中执行 Go:generate 时,都能够正确地生成代码。
识别依赖通常涉及以下几个方面:
- **构建工具**: 例如 `make`, `go build`, `go generate` 等。
- **外部命令**: 例如数据库迁移工具、代码生成器等。
- **库**: 在 `go.mod` 文件中声明的依赖。
为了管理这些依赖,开发人员通常使用 `go mod` 命令来管理项目依赖:
```**
***/yourproject
go mod tidy
```
### 3.2.2 使用工具管理依赖
Go 提供了 `go mod` 作为依赖管理工具,它可以跟踪和管理 Go 代码中的依赖项。借助 `go mod`,你可以初始化你的模块、添加依赖项、升级依赖项,以及将依赖项转存到 `go.mod` 文件中。
```sh
# 查看当前模块的依赖项
go list -m all
# 添加一个新的依赖项
***/some/module
# 升级依赖项到特定版本
***/some/module@v1.2.3
# 删除未使用的依赖项
go mod tidy
```
在使用 Go:generate 时,你可能需要指定某些依赖的版本,以确保生成的代码符合特定的 API 或功能。你可以通过 `go get` 指定版本号来满足这个需求。
## 3.3 环境隔离与版本控制
### 3.3.1 环境隔离的策略
为了确保构建的可靠性和一致性,使用环境隔离是一个常见的做法。在 Go:generate 的上下文中,环境隔离意味着为代码生成过程设置一个隔离的环境,这样它就不会受到其他项目或全局系统设置的影响。
环境隔离的策略包括:
- **Docker 容器**:使用 Docker 容器来确保环境的隔离。你可以为 Go:generate 过程创建一个专用的 Docker 容器,其中包含了所有必要的依赖和工具。
- **虚拟环境**:对于像 Python 这样经常使用虚拟环境的语言,Go 可以使用环境变量或工具来模拟类似的行为。
下面是一个使用 Docker 来隔离 Go:generate 环境的示例:
```Dockerfile
# Dockerfile
FROM golang:latest
# 安装额外的依赖
RUN apt-get update && apt-get install -y \
your-external-command
# 设置工作目录
WORKDIR /app
# 其他的 Docker 设置...
```
通过构建一个这样的 Docker 镜像,你可以确保每次 Go:generate 命令执行时都会在一个完全一致的环境中运行。
### 3.3.2 版本控制在环境管理中的角色
版本控制系统(如 Git)不仅是跟踪和管理代码变更的工具,它也可以用来管理环境配置。通过将环境配置文件(如 Dockerfile、`go.mod` 和相关的配置脚本)保存在版本控制系统中,你可以确保整个团队对环境配置有一个共同的理解。
```gitignore
# .gitignore 文件
*.log
*.tmp
# 忽略 Go 模块的缓存文件
# 通常这些缓存文件不需要版本控制
/vendor
```
确保环境配置文件被纳入版本控制,可以让你对环境进行版本化管理。这样,任何时候代码被拉取或检出,相关的环境配置都会一并被重建,从而保证了环境的一致性。
```sh
# 示例 Git 工作流程
git clone <repository-url>
cd <repository-directory>
go mod download
docker build -t mygenerateenv .
```
以上内容展示了如何有效地利用环境管理技巧来提升 Go:generate 命令的效率和可靠性。通过合理配置环境变量、管理构建依赖,以及实施环境隔离策略,可以极大地提高开发效率并减少构建过程中的错误。
# 4. 代码质量与Go:generate的结合
## 4.1 静态代码分析工具集成
静态代码分析工具是提高代码质量的有效方式之一。在Go:generate的场景中,将静态分析工具集成到生成流程中,不仅可以自动化检测生成的代码质量,还可以提前发现潜在的错误和漏洞。
### 4.1.1 静态分析工具的选择
选择合适的静态分析工具是关键。Go语言社区提供了多种静态分析工具,如`staticcheck`、`golint`和`go vet`等。每种工具各有侧重,例如`staticcheck`提供全面的静态分析功能,`golint`侧重于代码风格和规则,而`go vet`专注于发现Go代码中的可疑构造。
- `staticcheck`:提供广泛的检查项,覆盖了代码风格、性能、安全性等方面,适合全面的代码质量审查。
- `golint`:虽然不是官方工具,但非常流行,它基于Google的Go编码标准,用于检测代码风格问题。
- `go vet`:是Go官方提供的工具,可以找到Go代码中的一些不规范或者可疑的结构,虽然它的检查范围没有`staticcheck`广泛。
### 4.1.2 集成静态分析到生成流程
集成静态分析到Go:generate的流程中,可以通过修改`go generate`命令来实现。使用Makefile或者其他构建工具,可以设置一系列预设的静态分析命令,在生成代码后自动执行。
```makefile
generate:
go generate ./...
vet:
go vet ./...
staticcheck:
staticcheck -f build ./...
test:
go test -race ./...
all: generate vet staticcheck test
```
在上述Makefile中,定义了`generate`、`vet`和`staticcheck`等目标,分别对应生成代码、运行`go vet`和`staticcheck`。通过执行`make all`命令,可以依次执行这些检查,确保代码质量。
## 4.* 单元测试与代码生成的协同
在Go语言中,单元测试是保证代码质量不可或缺的一部分。为了保证通过Go:generate生成的代码同样具备高质量,编写和维护相应的单元测试是必要的。
### 4.2.* 单元测试的编写与维护
编写生成代码的单元测试,需要理解生成代码的行为和逻辑,然后针对这些逻辑编写相应的测试用例。
#### 4.2.1 编写单元测试
```go
// example_test.go
package example
import (
"testing"
)
// TestGeneratedCode 测试通过go:generate生成的代码逻辑
func TestGeneratedCode(t *testing.T) {
// 准备测试数据和预期结果
input := "test input"
expectedOutput := "expected output"
// 调用生成代码中的函数
actualOutput := GenerateFunction(input)
// 断言测试结果是否符合预期
if actualOutput != expectedOutput {
t.Errorf("Expected output '%s' but got '%s'", expectedOutput, actualOutput)
}
}
```
在编写测试用例时,要注意以下几点:
- 确保测试用例覆盖到所有可能的路径。
- 使用表驱动测试来处理大量相似的测试场景。
- 注意测试环境和依赖项的隔离,避免测试间的相互干扰。
#### 4.2.2 生成代码的测试覆盖策略
单元测试的覆盖率是衡量代码质量的重要指标。对于生成代码,可以使用`go test -cover`来检测测试覆盖情况。
```bash
$ go test -cover ./...
```
该命令会运行测试,并给出每行代码的执行情况。通常要求覆盖率达到80%以上,以保证足够的代码质量。
## 4.3 性能优化与维护策略
生成代码的性能优化和维护是长期保证项目质量的重要环节。针对生成代码的特定场景进行性能调优,以及建立有效的维护计划,是实现持续集成和持续部署(CI/CD)的关键。
### 4.3.1 代码生成性能优化
性能优化是一个不断迭代的过程,优化生成代码通常涉及减少生成代码的复杂度、减少依赖项和优化内存使用等策略。
### 4.3.2 代码生成的持续维护计划
维护计划应当包括定期的代码审查、性能监控和根据反馈进行调整等环节。通过自动化测试和监控,能够早期发现问题并及时修复。
建立维护计划的流程如下:
- 定期运行静态分析和动态测试。
- 监控生成代码在生产环境中的性能表现。
- 根据监控数据和用户反馈,定期更新模板和生成逻辑。
- 保持文档的更新,让维护者和新成员理解生成代码的逻辑和维护策略。
以上内容为第四章的深入探讨,涵盖了静态代码分析工具的集成、单元测试的编写与维护,以及性能优化与维护策略。下一章将详细介绍Go:generate在未来的发展趋势和最佳实践。
# 5. generate的未来趋势与最佳实践
随着时间的推移,Go 语言的 `go:generate` 命令在项目构建过程中扮演了越来越重要的角色。它的简单性、灵活性和强大的代码生成功能,使其成为 Go 项目中不可或缺的工具。接下来,我们将深入探讨 Go:generate 的发展前景以及一些最佳实践。
## 5.1 Go:generate的发展前景
### 5.1.1 新版本的改进与特性预测
随着 Go 语言的不断演进,`go:generate` 命令也在不断地获得新的改进。我们可能期待未来版本中会出现以下特性:
- **并行执行**:允许 `go:generate` 命令并行运行多个代码生成任务,以提高构建效率。
- **集成更紧密**:与 `go mod` 更好地集成,自动化处理模块依赖,简化环境配置。
- **友好的错误处理**:提供更加详细的错误信息,帮助开发者快速定位问题。
- **更好的跨平台支持**:自动检测不同平台和操作系统,执行相应的代码生成任务。
### 5.1.2 社区动态与实践案例
Go 社区活跃,许多开发者贡献了他们的模板和代码生成实践案例。通过这些案例,我们可以看到 `go:generate` 在实际项目中的多样化应用,如:
- **数据库模型生成**:结合 ORM 工具,生成数据库模型代码。
- **API 客户端库**:自动生成与远程服务交互的代码库,节省大量重复劳动。
- **配置管理代码**:根据配置文件自动生成对应的代码文件,提高配置的灵活性。
## 5.2 最佳实践总结
### 5.2.1 编写清晰的模板代码
编写易于理解和维护的模板代码是至关重要的。为了提高代码的可读性和可维护性,以下是一些最佳实践:
- **遵循编码标准**:模板代码应遵循 Go 语言的编码标准,使用有意义的变量名和注释。
- **模块化设计**:将复杂模板分解为多个小的、可复用的模块。
- **注释和文档**:为模板提供必要的注释和文档,方便其他开发者理解和使用。
### 5.2.2 管理好项目的生成流程
一个项目的成功不仅仅在于编写好的代码,还在于如何组织和管理这些代码。对于使用 `go:generate` 的项目来说:
- **版本控制**:将模板文件纳入版本控制系统,与项目代码一起管理。
- **构建脚本**:创建清晰的构建脚本,详细说明如何运行 `go:generate` 命令。
- **持续集成**:在 CI/CD 流程中集成 `go:generate`,确保每次提交都能生成正确的代码。
### 5.2.3 参与开源贡献与改进
最后,开发者应该积极参与开源社区,通过贡献代码、提交问题报告或提供文档来改进 `go:generate`:
- **报告问题**:如果在使用 `go:generate` 时遇到问题,应该在官方仓库提交 issue。
- **提交改进**:贡献代码补丁,修复已知问题或添加新的功能。
- **分享经验**:在博客、会议或社区分享你在 `go:generate` 使用中的经验,帮助他人成长。
通过不断地学习和实践,我们可以充分利用 `go:generate` 来提高开发效率,使项目结构更清晰,让开发过程更加愉快和高效。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Go 语言的代码生成工具 go:generate,从入门到精通,全面解析其高级应用和最佳实践。专栏还阐述了定制代码生成策略的艺术,指导开发者提高开发效率。此外,专栏强调了 go:generate 安全守则,提供保护生成代码免受注入攻击的安全实践,确保代码的安全性。通过阅读本专栏,开发者可以全面掌握 go:generate 的使用,提高 Go 代码开发的效率和安全性。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32F030C8T6专攻:最小系统扩展与高效通信策略
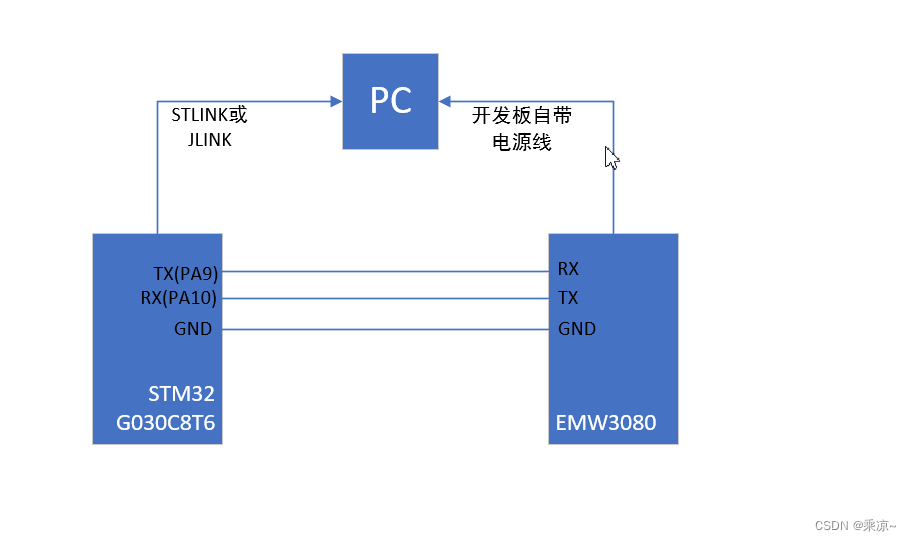
# 摘要
本文首先介绍了STM32F030C8T6微控制器的基础知识和最小系统设计的要点,涵盖硬件设计、软件配置及最小系统扩展应用案例。接着深入探讨了高效通信技术,包括不同通信协议的使用和通信策略的优化。最后,文章通过项目管理与系统集成的实践案例,展示了如何在实际项目中应用这些技术和知识,进行项目规划、系统集成、测试及故障排除,以提高系统的可靠性和效率。
# 关键字
STM32F030C8T6;
【PyCharm专家教程】:如何在PyCharm中实现Excel自动化脚本

# 摘要
本文旨在全面介绍PyCharm集成开发环境以及其在Excel自动化处理中的应用。文章首先概述了PyCharm的基本功能和Python环境配置,进而深入探讨了Python语言基础和PyCharm高级特性。接着,本文详细介绍了Excel自动化操作的基础知识,并着重分析了openpyxl和Pandas两个Python库在自动化任务中的运用。第四章通过实践案
ARM处理器时钟管理精要:工作模式协同策略解析

# 摘要
本文系统性地探讨了ARM处理器的时钟管理基础及其工作模式,包括处理器运行模式、异常模式以及模式间的协同关系。文章深入分析了时钟系统架构、动态电源管理技术(DPM)及协同策略,揭示了时钟管理在提高处理器性能和降低功耗方面的重要性。同时,通过实践应用案例的分析,本文展示了基于ARM的嵌入式系统时钟优化策略及其效果评估,并讨论了时钟管理常见问题的
【提升VMware性能】:虚拟机高级技巧全解析
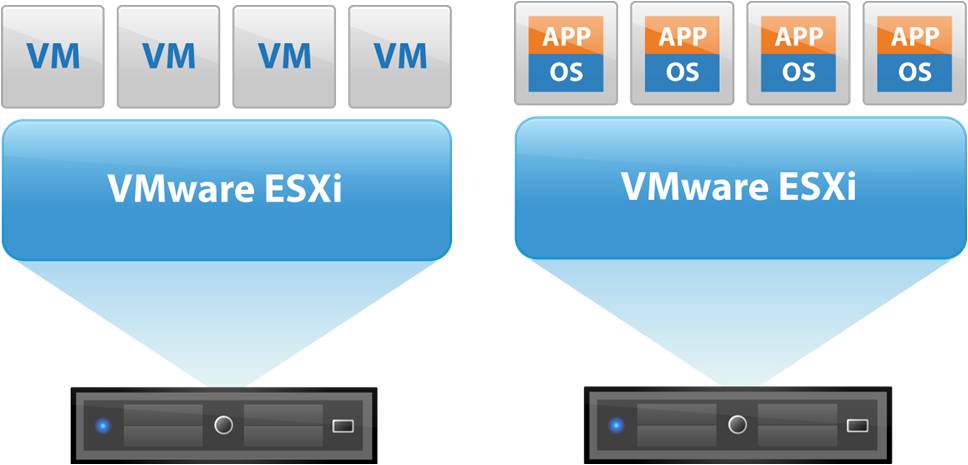
# 摘要
随着虚拟化技术的广泛应用,VMware作为市场主流的虚拟化平台,其性能优化问题备受关注。本文综合探讨了VMware在虚拟硬件配置、网络性能、系统和应用层面以及高可用性和故障转移等方面的优化策略。通过分析CPU资源分配、内存管理、磁盘I/O调整、网络配置和操作系统调优等关键技术点,本文旨在提供一套全面的性能提升方案。此外,文章还介绍了性能监控和分析工具的运用,帮助用户及时发
【CEQW2数据分析艺术】:生成报告与深入挖掘数据洞察
# 摘要
本文全面探讨了数据分析的艺术和技术,从报告生成的基础知识到深入的数据挖掘方法,再到数据分析工具的实际应用和未来趋势。第一章概述了数据分析的重要性,第二章详细介绍了数据报告的设计和高级技术,包括报告类型选择、数据可视化和自动化报告生成。第三章深入探讨了数据分析的方法论,涵盖数据清洗、统计分析和数据挖掘技术。第四章探讨了关联规则、聚类分析和时间序列分析等更高级的数据洞察技术。第五章将
UX设计黄金法则:打造直觉式移动界面的三大核心策略

# 摘要
随着智能移动设备的普及,直觉式移动界面设计成为提升用户体验的关键。本文首先概述移动界面设计,随后深入探讨直觉式设计的理论基础,包括用户体验设计简史、核心设计原则及心理学应用。接着,本文提出打造直觉式移动界面的实践策略,涉及布局、导航、交互元素以及内容呈现的直觉化设计。通过案例分析,文中进一步探讨了直觉式交互设计的成功与失败案例,为设
数字逻辑综合题技巧大公开:第五版习题解答与策略指南

# 摘要
本文旨在回顾数字逻辑基础知识,并详细探讨综合题的解题策略。文章首先分析了理解题干信息的方法,包括题目要求的分析与题型的确定,随后阐述了数字逻辑基础理论的应用,如逻辑运算简化和时序电路分析,并利用图表和波形图辅助解题。第三章通过分类讨论典型题目,逐步分析了解题步骤,并提供了实战演练和案例分析。第四章着重介绍了提高解题效率的技巧和避免常见错误的策略。最后,第五章提供了核心习题的解析和解题参考,旨在帮助读者巩固学习成果并提供额外的习题资源。整体而言,本文为数字逻辑
Zkteco智慧云服务与备份ZKTime5.0:数据安全与连续性的保障
# 摘要
本文全面介绍了Zkteco智慧云服务的系统架构、数据安全机制、云备份解决方案、故障恢复策略以及未来发展趋势。首先,概述了Zkteco智慧云服务的概况和ZKTime5.0系统架构的主要特点,包括核心组件和服务、数据流向及处理机制。接着,深入分析了Zkteco智慧云服务的数据安全机制,重点介绍了加密技术和访问控制方法。进一步,本文探讨了Zkteco云备份解决方案,包括备份策略、数据冗余及云备份服务的实现与优化。第五章讨论了故障恢复与数据连续性保证的方法和策略。最后,展望了Zkteco智慧云服务的未来,提出了智能化、自动化的发展方向以及面临的挑战和应对策略。
# 关键字
智慧云服务;系统
Java安全策略高级优化技巧:local_policy.jar与US_export_policy.jar的性能与安全提升

# 摘要
Java安全模型是Java平台中确保应用程序安全运行的核心机制。本文对Java安全模型进行了全面概述,并深入探讨了安全策略文件的结构、作用以及配置过程。针对性能优化,本文提出了一系列优化技巧和策略文件编写建议,以减少不必要的权限声明,并提高性能。同时,本文还探讨了Java安全策略的安全加固方法,强调了对local_po
海康二次开发实战攻略:打造定制化监控解决方案

# 摘要
海康监控系统作为领先的视频监控产品,其二次开发能力是定制化解决方案的关键。本文从海康监控系统的基本概述与二次开发的基础讲起,深入探讨了SDK与API的架构、组件、使用方法及其功能模块的实现原理。接着,文中详细介绍了二次开发实践,包括实时视频流的获取与处理、录像文件的管理与回放以及报警与事件的管理。此外,本文还探讨了如何通过高级功能定制实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )