TSPL指令进阶实战:揭秘高阶编程与性能优化的8大案例
发布时间: 2024-12-14 11:05:44 阅读量: 4 订阅数: 3 

参考资源链接:[TSPL指令详解:打印机驱动编程语言手册](https://wenku.csdn.net/doc/645d8c755928463033a012c4?spm=1055.2635.3001.10343)
# 1. TSPL指令介绍及环境搭建
## 1.1 TSPL指令集概述
TSPL(Text Scripting Programming Language)是一种专为文本处理设计的脚本语言,它提供了丰富的指令用于读取、解析、修改和输出文本数据。TSPL语言的核心设计哲学是简化文本数据的处理流程,使开发者能够以最小的学习曲线快速实现复杂的文本操作任务。
## 1.2 TSPL环境搭建
要开始使用TSPL,首先需要搭建一个适合的开发环境。环境搭建包括以下几个步骤:
1. 下载并安装TSPL解释器。解释器是TSPL代码执行的引擎,通常可以从TSPL官方网站获取最新版本。
2. 配置环境变量,确保在任何目录下都能直接通过命令行运行TSPL指令。
3. 验证安装成功。通过命令行运行 `tspl -v` 检查当前TSPL解释器的版本号。
## 1.3 开发工具和插件
除了TSPL解释器之外,还可以利用一些高级的开发工具和插件提高开发效率。例如:
- 使用TSPL语言支持的文本编辑器或IDE(如Sublime Text,Visual Studio Code等),这些工具提供了语法高亮、代码补全等功能。
- 一些第三方提供的TSPL开发插件可以集成到流行的IDE中,例如IntelliJ IDEA或Eclipse的TSPL插件,这些插件能够进一步提升编码和调试体验。
通过完成以上步骤,您将能够创建和运行TSPL脚本,并利用其强大的文本处理能力开始您的项目。接下来我们将深入探讨TSPL编程基础,包括语法结构、数据处理机制和脚本调试等。
# 2. TSPL编程基础
### 2.1 TSPL语法和基本命令
#### 2.1.1 TSPL指令集概述
TSPL(Technical Scripting Programming Language)是一种专门用于系统级脚本编程的语言。它的设计理念是快速开发、高可读性和灵活性。TSPL指令集广泛应用于数据处理、自动化任务、网络编程等场景。TSPL支持多种数据类型,包括但不限于整数、浮点数、字符串、数组和字典。
一个基本的TSPL脚本通常以`#!/usr/bin/env tsp`开头,这行代码定义了脚本的解释器路径。接下来,脚本会定义变量,执行控制结构,调用函数等。
下面是一个简单的TSPL脚本示例,展示了基本的指令集使用:
```tspl
#!/usr/bin/env tsp
# 定义变量
name = "World"
greeting = "Hello, " + name + "!"
# 控制结构:条件判断
if greeting == "Hello, World!":
print("Variable check passed.")
else:
print("Variable check failed.")
# 函数定义和调用
def say_hello(name):
print("Hello, " + name + "!")
say_hello(name)
```
#### 2.1.2 变量、控制结构和函数
**变量**:在TSPL中,变量是存储数据的容器。变量定义不需要指定类型,因为TSPL是动态类型语言。变量在使用前声明,但不必初始化。
**控制结构**:TSPL支持标准的控制结构,如if-else条件判断、for和while循环。这些结构使得脚本能够处理更复杂的逻辑。
```tspl
# for 循环示例
for i from 1 to 10:
print(i)
# while 循环示例
counter = 0
while counter < 5:
print(counter)
counter = counter + 1
```
**函数**:TSPL函数用于封装代码块以便重复使用。函数可以接受参数并返回值。TSPL支持一等函数和闭包,使得函数编程更加灵活。
```tspl
# 函数定义与调用示例
def add(x, y):
return x + y
result = add(3, 4)
print(result)
```
### 2.2 TSPL数据处理
#### 2.2.1 数据类型和结构
TSPL支持多种基本数据类型,如整数、浮点数、布尔值、字符串等。此外,TSPL还提供复合数据类型,包括数组(list)、字典(dict)和集合(set)。这些复合数据类型允许开发者组织和操作复杂的数据结构。
```tspl
# 数组使用示例
fruits = ["apple", "banana", "cherry"]
print(fruits[1]) # 输出:banana
# 字典使用示例
person = {"name": "Alice", "age": 25}
print(person["name"]) # 输出:Alice
# 集合使用示例
unique_numbers = {1, 2, 3}
print(unique_numbers) # 输出:{1, 2, 3}
```
#### 2.2.2 数据操作与转换
TSPL提供了丰富的数据操作函数,包括数据类型转换、排序、过滤等。例如,`str()`函数可以将非字符串类型转换为字符串,`len()`函数可以获取数组或字典的长度。
```tspl
# 数据类型转换示例
num = 42
num_str = str(num) + " is the answer"
print(num_str) # 输出:42 is the answer
# 排序示例
numbers = [5, 3, 6, 2, 10]
sorted_numbers = sorted(numbers)
print(sorted_numbers) # 输出:[2, 3, 5, 6, 10]
# 过滤示例
even_numbers = filter(lambda x: x % 2 == 0, numbers)
print(list(even_numbers)) # 输出:[2, 6, 10]
```
#### 2.2.3 数据输入输出机制
TSPL提供了灵活的数据输入输出机制。输入可以通过命令行参数、文件、标准输入进行。输出则可通过打印语句直接显示在终端,也可以输出到文件、标准输出等。
```tspl
# 从命令行接收输入并处理
import sys
if len(sys.argv) > 1:
user_input = sys.argv[1]
# 数据处理逻辑...
# 从文件读取数据
with open("data.txt", "r") as file:
content = file.read()
# 数据处理逻辑...
# 输出数据到终端
print("This is a print statement.")
# 输出数据到文件
with open("output.txt", "w") as file:
file.write("This is written to a file.")
```
### 2.3 TSPL脚本调试与错误处理
#### 2.3.1 常用调试技术
调试是编程过程中不可或缺的一部分。TSPL提供了日志记录、断点设置和异常追踪等调试技术。开发者可以使用`print()`函数进行简单的输出调试,或者使用更高级的调试器,如pdb(Python Debugger)。
```tspl
# 使用print()函数进行简单的输出调试
def some_function():
print("Entering some_function...")
# 复杂逻辑代码...
print("Exiting some_function...")
some_function()
# 使用断点进行调试
# 断点调试通常结合调试器使用,例如pdb
import pdb; pdb.set_trace()
```
#### 2.3.2 错误捕获与异常处理策略
TSPL支持异常处理机制,使得脚本在遇到错误时能够优雅地处理而不是直接崩溃。常见的异常处理结构包括`try`、`except`、`else`和`finally`。
```tspl
# 错误捕获与异常处理示例
try:
result = 10 / 0
except ZeroDivisionError:
print("Cannot divide by zero.")
finally:
print("This block always executes.")
```
通过这些错误处理结构,TSPL脚本可以提供更加健壮和可预测的程序执行流程。
# 3. TSPL实战案例解析
## 3.1 高级数据处理
### 3.1.1 复杂数据结构应用
在处理复杂数据时,TSPL提供了一系列高级数据结构,如栈、队列、集合和字典等。TSPL的数据结构设计注重效率,适用于不同的应用场景,能够在处理大量数据时保持高效的运行。
以下是TSPL中集合数据结构的一个应用示例,该示例演示如何对一组数据进行去重处理:
```tspl
// 创建一个包含重复元素的数组
let data = [1, 2, 2, 3, 4, 4, 5];
// 使用集合(Set)进行去重
let uniqueData = new Set(data);
// 输出去重后的数据
print(uniqueData); // 输出结果为 Set { 1, 2, 3, 4, 5 }
```
在上述代码中,我们首先定义了一个包含重复数字的数组。然后利用`Set`这一数据结构来存储数据,`Set`自动处理了数据的唯一性,去除重复项。最后,输出去重后的数据。
### 3.1.2 数据验证与清洗
数据验证和清洗是数据处理中的重要步骤,TSPL通过提供丰富的函数库支持数据的验证和清洗工作。以下是一个简单数据清洗的示例:
```tspl
// 定义一个待清洗的数据数组
let raw_data = ['apple', 'banana', '', 'orange', null, 'peach'];
// 数据清洗函数,去除空值和空字符串
function cleanData(data_array) {
return data_array.filter(item => item && item.trim() !== '');
}
// 调用清洗函数并打印结果
let cleaned_data = cleanData(raw_data);
print(cleaned_data); // 输出结果为 ['apple', 'banana', 'orange', 'peach']
```
在上述代码中,`cleanData`函数利用了数组的`filter`方法,该方法接受一个测试函数,根据测试结果保留或过滤元素。`item && item.trim() !== ''`这一表达式确保了数组中的元素既不是假值(如`null`、`undefined`),也不是空字符串,从而实现了数据的清洗。
## 3.2 系统级操作
### 3.2.1 文件系统交互
TSPL在处理文件系统交互时提供了丰富的API,可以进行文件的读写、目录的创建与删除等操作。以下是一个简单的文件读取示例:
```tspl
// 指定文件路径
const filePath = '/path/to/your/file.txt';
// 读取文件内容
function readFile(filePath) {
// 使用try/catch来处理可能出现的异常
try {
const fileContent = readfile(filePath);
return fileContent;
} catch (error) {
throw new Error(`读取文件失败: ${error}`);
}
}
// 调用函数并打印文件内容
const content = readFile(filePath);
print(content);
```
上述代码展示了如何读取文件系统中的文件。首先定义了文件路径,然后通过`readfile`函数读取文件内容。由于文件读取操作可能会抛出异常,因此使用了`try/catch`结构来捕获和处理这些异常。
### 3.2.2 系统进程管理
TSPL同样可以实现系统进程的管理,例如启动进程、监控进程状态等。以下是一个启动和监控进程的示例:
```tspl
// 启动一个系统进程并获取其ID
function startProcess(command) {
let process = spawn(command);
process.on('exit', code => {
if (code === 0) {
print(`进程正常退出,退出码:${code}`);
} else {
print(`进程异常退出,退出码:${code}`);
}
});
return process.pid;
}
// 启动一个进程并打印其ID
let pid = startProcess('ping localhost');
print(`进程ID:${pid}`);
```
在此示例中,通过`spawn`函数启动了一个`ping`命令的进程,并通过事件监听器捕获了进程的退出事件。`startProcess`函数返回了新启动进程的PID(进程标识符),允许其他进程对其进行进一步管理。
## 3.3 网络功能实现
### 3.3.1 网络协议栈的TSPL实现
TSPL内置了网络协议栈,可支持TCP/IP等协议的通信。这使得开发者能够在TSPL环境中构建客户端和服务器端的应用。以下是TSPL构建一个简单的TCP服务器的示例:
```tspl
// 导入TCP模块
import * as tcp from 'tcp';
// 创建TCP服务器
function createServer(port) {
const server = tcp.createServer(socket => {
print('客户端连接');
socket.on('data', data => {
print(`收到数据:${data}`);
});
socket.on('end', () => {
print('客户端断开连接');
});
});
server.listen(port, () => {
print(`服务器运行在端口:${port}`);
});
}
// 启动服务器
createServer(12345);
```
在此代码中,我们首先导入了`tcp`模块,并创建了一个TCP服务器。服务器监听指定端口(在此示例中为12345)的连接请求,一旦有客户端连接,服务器将打印客户端连接信息,并开始监听来自客户端的数据。
### 3.3.2 网络数据捕获与分析
TSPL还支持底层的网络数据包捕获与分析。这一功能对于网络监控、安全审计等场景非常有用。下面的代码展示如何使用TSPL捕获和分析网络数据包:
```tspl
// 导入抓包模块
import * as packet from 'packet';
// 设置抓包的网卡和过滤规则
const options = {
interface: 'eth0',
filter: 'tcp port 80'
};
// 创建抓包实例并监听数据包
function capturePackets(options) {
const capture = packet.createCapture(options);
capture.on('packet', packet => {
print(`捕获数据包:${packet}`);
// 这里可以添加数据包解析和分析逻辑
});
}
// 开始抓包
capturePackets(options);
```
上述代码中,我们使用了`packet`模块创建了一个网络数据包捕获实例,设置了监听的网络接口和过滤规则(本例中是监控80端口的TCP流量)。通过监听`packet`事件,我们可以在回调函数中进行数据包的处理,例如数据包解析、统计或安全检查。
在本章节中,我们深入探讨了TSPL在高级数据处理、系统级操作以及网络功能实现方面的应用。TSPL不仅在数据处理方面提供了强大的功能,而且在系统和网络层面同样表现出色,这使得它在多个实际应用领域中显得非常实用和灵活。在下一章节中,我们将进一步分析TSPL在性能优化方面的技巧和策略。
# 4. TSPL性能优化技巧
性能优化是任何编程语言和环境下的关键话题。TSPL作为一种强大的脚本语言,同样遵循这一原则。在这一章节中,我们将深入了解性能优化的各个方面,包括代码优化原理、资源管理优化,以及TSPL代码的并行处理等。这些技巧不仅能够让TSPL脚本运行更加高效,还能在处理大型数据集或复杂业务逻辑时,保持系统的稳定性和响应速度。
## 4.1 代码优化原理
### 4.1.1 性能分析工具介绍
性能分析是优化代码的基础。TSPL提供了多种内置工具和命令,帮助开发者检测代码中的性能瓶颈。首先,`profiler`模块可以被用来收集和分析代码执行时的性能数据。它能够提供详细的执行时间报告,显示每个函数调用的次数以及占用的CPU时间。通过这些数据,开发者可以明确知道哪些函数或代码块需要优化。
示例代码:
```python
import profiler
def some_function():
# 长时间运行的代码块
pass
profiler.start()
some_function()
profiler.stop()
print(profiler.get_report())
```
以上代码块中,我们导入了`profiler`模块,开始收集性能数据,执行了目标函数,并最终停止收集,并打印报告。
### 4.1.2 代码执行效率提升策略
提升代码执行效率的关键是减少不必要的计算和I/O操作。为了优化代码,开发者需要遵循一些基本原则:
- **使用合适的数据结构**:选择合适的数据结构可以大幅提高访问和操作数据的效率。
- **减少函数调用**:函数调用会带来额外的开销,尤其是在循环中,尽量减少调用可以提高性能。
- **避免使用全局变量**:全局变量的访问速度比局部变量慢,且容易引起状态不一致。
- **利用缓存**:重复计算的问题可以通过缓存解决,将计算结果存储起来以备后续需要时直接使用。
示例代码:
```python
# 不推荐
def inefficient_example(data):
result = []
for i in range(len(data)):
result.append(data[i] * 2)
return result
# 推荐
def efficient_example(data):
return [x * 2 for x in data] # 列表推导式,更快
```
在上述示例中,推荐的`efficient_example`函数使用了列表推导式来替代循环,这在很多情况下能够带来更好的性能。
## 4.2 资源管理优化
### 4.2.1 内存和CPU资源控制
在资源优化中,内存和CPU的管理尤为关键。TSPL环境提供了多种机制来帮助开发者管理资源:
- **垃圾回收**:TSPL中的垃圾回收(Garbage Collection)能够自动回收不再使用的内存对象,减少内存泄漏的风险。
- **并发执行限制**:在多线程环境中,TSPL允许开发者通过`max_concurrency`参数限制并发执行的任务数量,避免过载CPU资源。
示例代码:
```python
import gc
# 开启垃圾回收
gc.enable()
# 设置最大并发执行任务数
import threadpool
threadpool.set_max_concurrency(4)
```
### 4.2.2 IO资源优化
TSPL脚本往往需要处理大量的I/O操作,例如读写文件和网络请求。优化I/O操作的一个关键策略是使用异步I/O(Async I/O)。TSPL提供了`asyncio`模块,支持异步I/O操作,可以显著提升I/O密集型应用的性能。
示例代码:
```python
import asyncio
async def read_file_async(filename):
with open(filename, 'r') as f:
return await asyncio.get_event_loop().run_in_executor(None, f.read)
async def main():
result = await read_file_async('large_file.txt')
# 处理结果
asyncio.run(main())
```
## 4.3 TSPL代码的并行处理
### 4.3.1 多线程编程模式
TSPL支持多线程编程模式,这允许开发者利用多核CPU的优势,通过并发执行多个任务来提升性能。TSPL的`threading`模块提供了创建和管理线程的接口。
示例代码:
```python
import threading
def thread_function(name):
print(f'Thread {name}: starting')
# 执行线程任务
print(f'Thread {name}: finishing')
x = threading.Thread(target=thread_function, args=(1,))
y = threading.Thread(target=thread_function, args=(2,))
x.start()
y.start()
x.join()
y.join()
```
在该示例中,我们创建了两个线程,分别执行同一个函数但带有不同的参数,展示了如何启动和结束线程。
### 4.3.2 并行算法与数据同步机制
在多线程编程中,数据同步是一个必须考虑的问题。TSPL提供了一些同步原语,如锁(Locks)、信号量(Semaphores)等,以确保数据的一致性。
示例代码:
```python
import threading
lock = threading.Lock()
def thread_function(name):
lock.acquire()
try:
print(f'Thread {name}: has lock')
# 执行需要同步的数据操作
finally:
print(f'Thread {name}: releasing lock')
lock.release()
x = threading.Thread(target=thread_function, args=(1,))
y = threading.Thread(target=thread_function, args=(2,))
x.start()
y.start()
x.join()
y.join()
```
在该示例中,我们创建了两个线程,并使用锁(Lock)来同步它们对共享资源的访问,确保任一时刻只有一个线程可以执行特定的代码块。
以上就是第四章TSPL性能优化技巧的详细内容。通过深入理解并应用这些技巧,开发者可以显著提升TSPL脚本的执行效率和资源管理能力,进而打造更加健壮和高效的系统。
# 5. TSPL高级应用案例
## 5.1 数据库交互实战
数据库是现代IT系统的基础设施,TSPL作为一门功能强大的编程语言,在数据库交互方面也有着出色的表现。在本章节中,我们将深入探讨如何使用TSPL实现高效、安全的数据库交互。
### 5.1.1 数据库连接与查询优化
与数据库的交互首先需要建立连接,TSPL通过提供专门的数据库模块,使得开发者可以轻松地与各种数据库进行交互。数据库连接建立后,如何有效地执行查询就成为了一个关键问题。在TSPL中,我们通常采用以下方法进行查询优化。
#### 准备查询语句
TSPL提供了准备语句(prepared statements)来优化重复的查询操作。准备语句允许我们将SQL语句发送到数据库服务器,并预编译。每次执行时,只需要传递参数即可,这样可以减少SQL解析时间,提高执行效率。
```tspl
// 假设已经建立了与数据库的连接 conn
// 创建准备语句
const stmt = conn.prepare("SELECT * FROM users WHERE id = ?");
// 执行准备语句
const user = stmt.query(1);
```
#### 使用索引
索引对于查询性能的提升至关重要。合理地在数据库表上创建索引可以显著减少查询时的数据检索量。在TSPL中,我们可以通过执行创建索引的SQL语句来为特定的列添加索引。
```tspl
// 创建索引的SQL语句
const createIndexSQL = "CREATE INDEX idx_user_id ON users(id);";
// 执行SQL语句以创建索引
conn.query(createIndexSQL);
```
#### 批量操作
在处理大量数据时,批量操作比单条记录操作要高效得多。TSPL允许我们一次提交多条SQL语句到数据库服务器,以减少网络往返次数。
```tspl
// 批量插入数据的SQL语句
const batchInsertSQL = `
INSERT INTO users(name, email) VALUES ('Alice', 'alice@example.com');
INSERT INTO users(name, email) VALUES ('Bob', 'bob@example.com');
`;
// 执行批量插入
conn.query(batchInsertSQL);
```
#### 事务处理
事务是保证数据库操作的原子性、一致性、隔离性和持久性的重要手段。TSPL通过事务控制语句来管理事务,确保数据的一致性。
```tspl
// 开始事务
conn.beginTransaction();
try {
// 在事务中执行一系列操作
conn.query("UPDATE accounts SET balance = balance - 100 WHERE id = 1");
conn.query("UPDATE accounts SET balance = balance + 100 WHERE id = 2");
// 提交事务
conn.commit();
} catch (e) {
// 回滚事务
conn.rollback();
throw e;
}
```
#### 异常管理
TSPL在执行数据库操作时,可能会遇到各种异常。为了提高代码的健壮性,TSPL提供了异常捕获和处理机制。
```tspl
try {
// 执行可能引发异常的数据库操作
const result = conn.query("SELECT * FROM nonexistent_table");
} catch (e) {
// 输出错误信息,并进行适当的异常处理
print("Error:", e.message);
// 可以在此处添加日志记录、重试逻辑等
}
```
### 5.1.2 事务处理与异常管理
在数据库交互中,事务处理和异常管理是保证数据一致性和应用稳定性的关键环节。TSPL提供了强大的工具和机制来支持这一需求。
#### 事务控制
事务控制是数据库操作中保证数据完整性的基石。在TSPL中,我们可以明确地开始、提交和回滚事务,确保数据的安全和准确。
```tspl
// 假设 conn 已经是一个数据库连接实例
// 开始一个新事务
conn.beginTransaction();
try {
// 执行一系列更新操作
conn.query("UPDATE users SET status = 'active' WHERE id = 1");
conn.query("UPDATE orders SET status = 'shipped' WHERE user_id = 1");
// 事务成功,提交事务
conn.commit();
} catch (e) {
// 事务失败,回滚事务
conn.rollback();
print("Transaction failed:", e.message);
}
```
#### 异常管理
TSPL的异常处理机制通过try-catch块来捕获和处理运行时可能发生的错误。这为开发者提供了处理异常情况的灵活手段。
```tspl
try {
// 尝试执行可能导致异常的代码
const result = conn.query("SELECT * FROM non_existent_table");
} catch (e) {
// 捕获到异常后的处理逻辑
print("An error occurred:", e.message);
// 这里可以添加日志记录、用户提示或其他错误恢复策略
}
```
在实际应用中,事务控制和异常管理经常配合使用。通过合理的设计事务边界和异常处理逻辑,可以构建出健壮且高效的数据库交互程序。
## 5.2 自动化工作流设计
在现代软件开发和运维过程中,自动化工作流的设计变得越来越重要。TSPL提供了强大的语言特性来实现复杂的工作流自动化。
### 5.2.1 工作流的概念与模型
工作流是指一组按照预定顺序执行的任务集合。在TSPL中,可以使用其内置的控制结构来模拟工作流的运行。
#### 工作流的组成元素
- **任务**: 工作流中最基本的单元,可以是简单的脚本命令或者复杂的业务逻辑处理。
- **控制流**: 确定任务执行的顺序和路径,包括条件分支、循环和并行执行等。
- **数据流**: 在任务执行过程中,数据在不同任务之间的传递方式。
- **触发器**: 启动工作流执行的信号,可以是定时任务、外部事件或者手动触发。
#### 工作流模型
在TSPL中,一个简单的工作流模型可以由以下TSPL代码片段表示:
```tspl
// 定义工作流
function workflow() {
if (isTriggered()) {
task1();
if (condition1) {
task2();
} else {
task3();
}
}
task4();
}
// 执行工作流
workflow();
```
在这个模型中,`workflow` 函数代表整个工作流。`isTriggered` 函数用于判断是否满足触发工作流的条件。`task1`, `task2`, `task3`, `task4` 等代表工作流中的任务。
### 5.2.2 实现复杂工作流的TSPL案例
在实际应用中,工作流可能会涉及复杂的逻辑和任务,TSPL通过其灵活的编程模型能够很好地支持这些场景。
#### 案例:部署自动化工作流
假设我们需要设计一个自动部署Web应用程序的工作流,该工作流可能包含以下任务:
- 拉取最新的代码仓库;
- 运行测试套件;
- 构建应用;
- 部署到服务器;
- 启动应用程序。
在TSPL中,我们可以使用如下代码来实现这样一个工作流:
```tspl
function deployApp() {
checkoutCode();
runTests();
buildApp();
deployToServer();
startApp();
}
// 这些函数是工作流的具体任务实现
function checkoutCode() {
// ...执行Git clone操作...
}
function runTests() {
// ...执行测试套件...
}
function buildApp() {
// ...执行构建操作...
}
function deployToServer() {
// ...执行远程部署操作...
}
function startApp() {
// ...启动应用程序...
}
// 启动工作流
deployApp();
```
在这个示例中,每个任务都通过一个函数来实现,并且通过顺序调用来组织整个工作流的执行。TSPL使得这样的工作流实现既清晰又易于维护。
通过以上章节的深入探讨,我们可以看到TSPL在高级应用中的多样性和灵活性。无论是数据库交互还是自动化工作流设计,TSPL都能够提供强大的支持,帮助开发者构建高效、稳定的应用系统。
# 6. TSPL项目实战与未来展望
## 6.1 大型TSPL项目实战经验
### 6.1.1 项目架构设计
在进行大型TSPL项目的架构设计时,通常会遵循“分而治之”的原则,即通过模块化和分层的方式,将复杂系统分解为更小、更易于管理和开发的单元。在设计时,我们强调以下几个方面:
- **模块化**:每个模块负责系统的特定功能,模块之间的交互尽可能减少,以降低耦合度。
- **分层架构**:不同的逻辑层处理系统的不同方面。例如,可以有数据访问层、业务逻辑层、表示层等。
- **组件复用**:设计通用组件以供复用,减少重复代码,提高开发效率和系统维护性。
### 6.1.2 代码版本控制与团队协作
在多开发者参与的项目中,代码版本控制是不可或缺的。TSPL项目中,我们通常采用如Git这样的版本控制系统。Git提供了一个优秀的版本管理框架,便于跟踪代码的变更、合并分支以及进行代码审查。
- **分支管理策略**:例如使用Gitflow工作流程,这样有助于维护稳定性和开发效率。
- **合并请求**:代码审查通常是通过合并请求(Merge Request)来进行的,这有助于确保代码质量。
- **自动化构建与部署**:集成持续集成(CI)和持续部署(CD)工具链来自动化测试和部署流程。
## 6.2 TSPL的发展趋势与挑战
### 6.2.1 新兴技术对TSPL的影响
随着技术的发展,许多新兴的技术趋势开始影响TSPL的发展:
- **云计算**:在云环境中部署TSPL应用程序可以提供更好的可扩展性和弹性。
- **大数据**:TSPL的扩展库可能包含处理大数据集所需的功能,提升数据处理能力。
- **物联网**:TSPL语言需要适应轻量级设备和边缘计算的需求,以便在物联网设备上运行。
### 6.2.2 面向未来的TSPL改进方向
为了适应未来的挑战,TSPL需要在以下几个方面进行改进和发展:
- **性能优化**:持续优化语言内部实现,提供更高的执行效率。
- **安全增强**:提升TSPL语言的安全性,防止诸如代码注入等安全漏洞。
- **社区与生态**:加强社区建设,鼓励开发者贡献,丰富TSPL的生态系统。
总结来说,TSPL项目实战和未来发展充满挑战和机遇。通过不断优化项目管理方法、技术创新以及社区发展,TSPL将能够适应未来的计算需求,满足更广泛的行业应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VSCode与CMake集成:环境变量设置不再难(专业解析,快速上手)

参考资源链接:[VScode+Cmake配置及问题解决:MinGW Makefiles错误与make命令失败](https://wenku.csdn.net/doc/64534aa7fcc53913680432ad?spm=1055.2635.3001.10343)
# 1. VSCode与CMake集成简介
在现代软件开发流程中,集成开发环境(IDE)和构建系统之间的
VMware OVA导入失败?揭秘5大原因及彻底解决方案

参考资源链接:[VMware Workstation Pro 14导入ova报错问题解决方法(Invalid target disk adapter type pvscsi)](https://wenku.csdn.net/doc/64704746d12cbe7ec3f9e816?spm=1055.2635.3001.10343)
# 1. VMwa
SPiiPlus Utilities:掌握控制系统优化的10个秘诀

参考资源链接:[SPiiPlus软件用户指南:2
【ADASIS v2数据封装揭秘】:掌握车载数据流处理的艺术
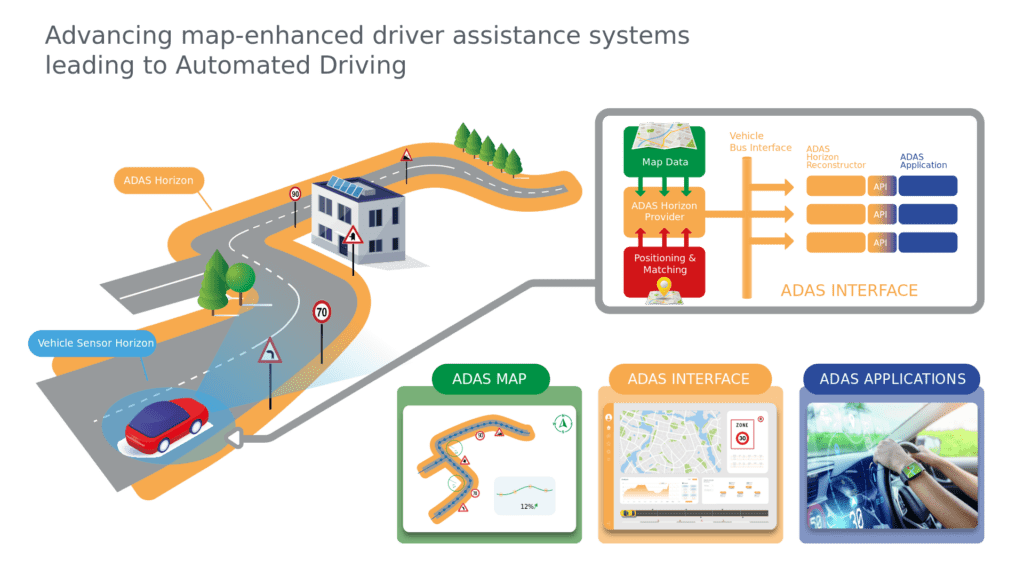
参考资源链接:[ADASIS v2 接口协议详解:汽车导航与ADAS系统的数据交互](https://wenku.csdn.net/doc/6412b4fabe7fbd1778d41825?spm=1055.2635.3001.10343)
# 1. ADASIS v2数据封装概述
ADASIS v2(高级驾驶辅助系统接
瀚高数据库连接优化:提升性能的关键策略
参考资源链接:[瀚高数据库专用连接工具hgdbdeveloper使用教程](https://wenku.csdn.net/doc/2zb4hzgcy4?spm=1055.2635.3001.10343)
# 1. 瀚高数据库连接原理
数据库连接是数据访问的基石,瀚高数据库也不例外。在深入探讨连接优化之前,我们首先需要理解瀚高数据库连接的基本原理。瀚高数据库通过特定的网络协议与客户端建立连接,使得客户端应
腾讯开悟与深度学习:AI模型算法原理大揭秘,专家带你深入解读

参考资源链接:[腾讯开悟模型深度学习实现重返秘境终点](https://wenku.csdn.net/doc/4torv931ie?spm=1055.2635.3001.10343)
# 1. 深度学习与AI模型的基本概念
## 1.1 深度学习的兴起背景
深度学习作为机器学习的一个分支,其兴起源于对传统算法的突破和大数据的普及。随着计算
【PCB可制造性提升】:IPC-7351焊盘设计原则深度解析
参考资源链接:[IPC-7351标准详解:焊盘图形设计与应用](https://wenku.csdn.net/doc/5d37mrs9bx?spm=1055.2635.3001.10343)
# 1. PCB可制造性的重要性
印刷电路板(PCB)是现代电子设备不可或缺的组成部分。其可制造性,即PCB设计对制造过程的适应性,直接决定了产品的最终质量和生产效率。提高PCB的可制造性,可以减少制造过程中的缺陷,降低返工率,节约生产成本,从而加快产品上市时间并提高市场竞争力。
在电子制造领域,焊盘(Pad)是实现元件与电路板电气连接的关键,其设计的合理性对PCB的可制造性起到至关重要的作用。焊盘设
【DataLogic扫码器性能调优秘籍】:扫描效率翻倍的技巧全集

参考资源链接:[DataLogic得利捷扫码器DL.CODE配置与使用指南](https://wenku.csdn.net/doc/i8fmx95ab9?spm=1055.2635.3001.10343)
# 1. DataLogic扫码器性能调优概述
在当今快节奏和效率至上的商业环境中,DataLogic扫码器的性能调优成为确保企业运营顺畅的关键。本章我们将介绍调优的重要性和基本概念,为后续章
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )