16. K8S_Linux-k8s控制器-Replicaset高可用配置指南
发布时间: 2024-02-27 07:06:03 阅读量: 32 订阅数: 23 

镜像 k8s.gcr.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2
# 1. K8S简介
Kubernetes(简称K8S)是用于自动部署、扩展和管理容器化应用程序的开源平台。它最初由Google设计,现已捐赠给了Cloud Native Computing Foundation。Kubernetes提供了一个可预测的容器编排环境,可以自动化部署、扩展和管理容器化应用程序,从而帮助用户轻松地构建容器化的云原生应用。
### 1.1 什么是Kubernetes
Kubernetes是一个开源的容器编排引擎,它可以自动部署、扩展和管理容器化的应用程序。Kubernetes的设计目标是实现容器集群的自动化部署、扩展和运维,能够帮助用户更轻松地管理容器化的应用,提高容器集群的稳定性和可靠性。
### 1.2 Kubernetes的基本概念
Kubernetes包含了一些核心概念,如Pod、Replicaset、Service、Volume等。其中,Pod是Kubernetes中最小的调度单位,可以包含一个或多个容器;Replicaset可以确保指定数量的Pod副本始终在运行;Service定义了一组Pod的访问规则,提供统一的访问入口;Volume用于在Pod中存储数据等。
### 1.3 Kubernetes在容器编排中的作用
在容器编排中,Kubernetes扮演着调度器和编排器的角色,它可以根据用户的需求自动地将容器部署到集群中的节点,并通过各种控制器保证其持续运行和自愈能力。Kubernetes的出现大大简化了容器化应用的部署与管理,并成为云原生应用的标准编排平台。
接下来,我们将深入探讨在Linux系统下如何安装和部署Kubernetes。
# 2. Linux下的Kubernetes安装与部署
Kubernetes的安装部署是使用Kubernetes的第一步,只有正确安装和配置好Kubernetes集群,才能让容器化应用在集群中高效运行。在本章中,我们将介绍如何在Linux系统下安装和部署Kubernetes集群。
### 2.1 准备工作及环境要求
在开始安装Kubernetes之前,需要进行一些准备工作和满足一定的环境要求。这包括:
- 操作系统要求:Kubernetes支持的操作系统版本;
- 硬件要求:节点的硬件配置;
- 安装工具:安装Kubernetes所需的工具;
- 网络配置:集群中节点间的通信和网络配置。
### 2.2 使用kubeadm安装Kubernetes集群
[kubeadm](https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/)是Kubernetes官方推荐的安装工具,可以快速部署一个符合生产环境标准的Kubernetes集群。以下是使用kubeadm安装Kubernetes集群的步骤概述:
1. 安装Docker和kubectl工具;
2. 配置Docker Cgroup Driver为systemd;
3. 初始化Master节点;
4. 加入Worker节点。
### 2.3 验证集群是否正常运行
安装完Kubernetes集群后,需要验证集群是否正常运行。可以通过以下方式验证:
- 使用kubectl工具查看集群节点状态;
- 部署一个简单的Pod查看是否正常运行;
- 部署一个Service测试Pod间的通信。
通过验证集群的正常运行,可以确保Kubernetes集群已经安装成功并可以正常工作。
# 3. Kubernetes控制器介绍与原理
Kubernetes中的控制器是用来维护系统状态的核心组件之一,负责管理和控制集群中的各种资源对象。在这一章节中,我们将深入探讨Kubernetes控制器的相关概念和原理。
#### 3.1 控制器的概念
Kubernetes中的控制器是一种控制循环(cycle control)。它不断地调节系统状态,使实际状态达到用户所期望的状态。控制器实现了对资源对象的自动化管理,确保集群中的应用程序能够按照用户期望的状态来运行。
#### 3.2 Replicaset控制器的作用与特点
Replicaset是Kubernetes中的一种控制器,用于确保指定数量的Pod实例副本在任何给定时间内都在运行。Replicaset的主要作用是实现Pod的水平扩展和高可用性。它通过监控Pod数量,并根据用户定义的副本数量来自动调节Pod的数量。
#### 3.3 Replicaset与ReplicationController的区别
Replicaset与ReplicationController都是用来确保Pod实例数量的控制器,但二者之间存在一些不同之处。ReplicationController只能基于Pod数量进行匹配,而Replicaset可以支持更丰富的selector匹配模式;此外,Replicaset还可以与Deployment等其他资源对象进行关联,实现更高级的应用管理功能。Replicaset是ReplicationController的升级版本,建议在新的部署中使用Replicaset来代替ReplicationController。
以上便是关于Kubernetes控制器的介绍与原理部分内容,接下来我们将深入探讨Replicaset的高可用配置指南。
# 4. Replicaset高可用配置指南
在本章中,我们将深入探讨Replicaset的高可用配置指南,包括Replicaset的工作原理、如何创建和管理Replicaset以及针对高可用场景的Replicaset配置推荐。
#### 4.1 Replicaset的工作原理
Replicaset是Kubernetes中用于确保副本数量的控制器,在实现高可用性方面起到了关键作用。它通过定义一个期望的Pod副本数量来确保这个数量的Pod一直处于运行状态。
Replicaset的工作原理可以简单概括为:当某个Pod的副本数量与Replicaset定义的期望数量不一致时,Replicaset会自动调节Pod的数量,以使其达到期望的状态。
#### 4.2 如何创建和管理Replicaset
创建和管理Replicaset通常需要以下几个步骤:
1. 编写Replicaset的YAML配置文件,定义Pod的模板和副本数量。
2. 使用kubectl命令将该YAML文件提交给Kubernetes API服务器,创建Replicaset。
3. 可以使用kubectl命令来对Replicaset进行扩缩容、滚动更新等操作。
举个例子,以下是一个简单的Replicaset的YAML配置文件示例:
```yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: my-replicaset
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-container
image: my-image
ports:
- containerPort: 80
```
在这个示例中,我们定义了一个名为`my-replicaset`的Replicaset,包含了3个副本,使用了一个标签选择器来匹配该Replicaset所控制的Pod,并指定了Pod的模板。
#### 4.3 针对高可用场景的Replicaset配置推荐
针对高可用场景,我们可以通过以下方式配置Replicaset以提高可靠性:
- 使用健康检查:通过设置Pod的健康检查机制,及时发现并替换不健康的Pod,确保整体可用性。
- 跨可用区部署:将Replicaset的副本部署到不同的可用区,以防止某个可用区发生故障影响整体服务。
- Pod亲和性和反亲和性调度:通过设置Pod的亲和性和反亲和性,将相关的Pod调度到同一节点或者不同节点,以提高容错能力。
通过以上配置推荐,可以使Replicaset在面对各种故障和异常情况时能够保持高可用性和稳定性。
希望通过本章的内容,读者们能够全面了解Replicaset的高可用配置指南,以及在实际场景中如何使用和管理Replicaset。
# 5. Replicaset故障处理与监控
在本章中,我们将深入探讨Replicaset的故障处理和监控方法,确保集群的稳定性和可靠性。
#### 5.1 Replicaset故障排查与处理方法
当Replicaset出现故障时,我们需要迅速进行排查和处理,以下是一些常见的故障排查方法:
```python
# 代码示例
import kubernetes.client
# 创建一个API客户端实例
config = kubernetes.client.Configuration()
api_instance = kubernetes.client.CoreV1Api(kubernetes.client.ApiClient(config))
# 获取故障的Replicaset信息
def get_faulty_replicaset(namespace, replicaset_name):
try:
api_response = api_instance.read_namespaced_replica_set(replicaset_name, namespace)
return api_response
except kubernetes.client.exceptions.ApiException as e:
print("Exception when calling CoreV1Api->read_namespaced_replica_set: %s\n" % e)
# 执行故障排查
faulty_replicaset = get_faulty_replicaset("default", "my-replicaset")
if faulty_replicaset:
print("发现故障的Replicaset:%s" % faulty_replicaset.metadata.name)
# 进一步处理故障的Replicaset
```
#### 5.2 使用Prometheus和Grafana监控Replicaset
监控是保证系统正常运行的关键,Prometheus和Grafana是常用的监控工具组合,用于实时监控Replicaset的状态和性能指标。
```java
// 代码示例
// 在Prometheus中配置Replicaset监控指标
// 配置文件示例:replicaset_metrics.yaml
- job_name: 'replicaset'
metrics_path: /metrics
static_configs:
- targets: ['replicaset-controller:8080']
// 在Grafana中创建Replicaset的监控仪表盘
// 通过Prometheus数据源获取Replicaset的监控指标,并绘制可视化图表
```
#### 5.3 如何实现Replicaset的自动恢复
当Replicaset发生故障导致部分Pod不可用时,我们可以通过自动化措施实现Replicaset的自动恢复,确保服务的高可用性。
```go
// 代码示例
// 监控Replicaset中Pod的健康状态
// 自动检测并替换不健康的Pod
func auto_recovery(replicaset_name string) {
// 实现自动恢复的逻辑
// 监控Pod状态,自动替换故障Pod
}
// 调用自动恢复函数来处理Replicaset故障
auto_recovery("my-replicaset")
```
通过本章的内容,我们深入了解了Replicaset的故障处理和监控方法,以及如何实现Replicaset的自动恢复,帮助您更好地管理和维护Kubernetes集群中的Replicaset。
# 6. 实战案例分享与总结
在本章中,将分享两个实战案例,展示如何在实际应用中使用Replicaset,并对Kubernetes控制器进行总结和展望。
#### 6.1 案例一:实现Replicaset的自动水平扩展
##### 场景描述:
假设我们有一个 web 应用部署在 Kubernetes 集群上,该应用是一个简单的静态网站。由于流量的增加,我们需要实现Replicaset的自动水平扩展,以保证应用的稳定性和高可用性。
##### 代码实现(Python):
```python
# 在Deployment yaml文件中添加autoscale配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app
spec:
replicas: 3
template:
metadata:
labels:
app: web-app
spec:
containers:
- name: web-server
image: nginx
ports:
- containerPort: 80
autoscale:
maxReplicas: 5
minReplicas: 2
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
```
##### 代码总结:
以上代码通过在Deployment yaml文件中添加autoscale配置,实现了根据CPU利用率自动调整Replicaset的副本数量。
##### 结果说明:
当应用的CPU利用率超过50%时,Replicaset会自动扩展副本数量,最大不超过5个,保证了应用的性能和可用性。
#### 6.2 案例二:Replicaset的滚动更新操作
##### 场景描述:
假设我们需要更新应用的镜像版本,同时要避免引起服务中断。这时候就需要使用Replicaset的滚动更新功能,逐步替换旧版本的Pod。
##### 代码实现(Java):
```java
// 通过 kubectl 命令进行滚动更新
kubectl set image deployment/web-app web-server=nginx:new-version
// 监控更新状态
kubectl rollout status deployment/web-app
```
##### 代码总结:
通过kubectl命令设置新的镜像版本,然后使用rollout status命令监控更新状态,实现了Replicaset的滚动更新操作。
##### 结果说明:
在滚动更新过程中,Kubernetes会逐步替换旧版本的Pod,保证了服务的稳定性和可用性,避免了全部Pod同时更新导致的服务中断。
#### 6.3 结语与对Kubernetes控制器的展望
通过以上两个实战案例,我们深入了解了Replicaset在Kubernetes集群中的应用场景和作用,掌握了如何利用Replicaset实现自动扩展和滚动更新。在未来,随着Kubernetes生态的不断完善,控制器系统将会更加智能和强大,为容器编排和管理带来更多便利。
在实际应用中,合理使用Kubernetes控制器,可以提高集群的稳定性和弹性,为微服务架构的部署和维护带来便利。期待未来Kubernetes在容器编排领域的更多创新和突破!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Kubernetes中Replicaset和Deployment的相关概念、功能和最佳实践。从Deployment的详解、部署指南、策略解析,到高可用配置指南、故障排查和恢复,以及安全性配置,提供了全面的指导和解决方案。同时,专栏还涵盖了Replicaset的策略解析、高可用配置指南、滚动升级和回滚,以及多集群部署实践和安全性配置等内容。无论是初学者还是有经验的用户,都能从中获得实用的知识和技巧,帮助他们更好地理解和应用这些关键的Kubernetes控制器,提升容器化应用的管理水平和安全性。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
93K缓存策略详解:内存管理与优化,提升性能的秘诀

# 摘要
93K缓存策略作为一种内存管理技术,对提升系统性能具有重要作用。本文首先介绍了93K缓存策略的基础知识和应用原理,阐述了缓存的作用、定义和内存层级结构。随后,文章聚焦于优化93K缓存策略以提升系统性能的实践,包括评估和监控93K缓存效果的工具和方法,以及不同环境下93K缓存的应用案例。最后,本文展望了93K缓存
Masm32与Windows API交互实战:打造个性化的图形界面
# 摘要
本文旨在介绍基于Masm32和Windows API的程序开发,从基础概念到环境搭建,再到程序设计与用户界面定制,最后通过综合案例分析展示了从理论到实践的完整开发过程。文章首先对Masm32环境进行安装和配置,并详细解释了Masm编译器及其他开发工具的使用方法。接着,介绍了Windows API的基础知识,包括API的分类、作用以及调用机制,并对关键的API函数进行了基础讲解。在图形用户界面(GUI)的实现章节中,本文深入
数学模型大揭秘:探索作物种植结构优化的深层原理
# 摘要
本文系统地探讨了作物种植结构优化的概念、理论基础以及优化算法的应用。首先,概述了作物种植结构优化的重要性及其数学模型的分类。接着,详细分析了作物生长模型的数学描述,包括生长速率与环境因素的关系,以及光合作用与生物量积累模型。本文还介绍了优化算法,包括传统算法和智能优化算法,以及它们在作物种植结构优化中的比较与选择。实践案例分析部分通过具体案例展示了如何建立优化模型,求解并分析结果。
S7-1200 1500 SCL指令性能优化:提升程序效率的5大策略

# 摘要
本论文深入探讨了S7-1200/1500系列PLC的SCL编程语言在性能优化方面的应用。首先概述了SCL指令性能优化的重要性,随后分析了影响SCL编程性能的基础因素,包括编程习惯、数据结构选择以及硬件配置的作用。接着,文章详细介绍了针对SCL代码的优化策略,如代码重构、内存管理和访问优化,以及数据结构和并行处理的结构优化。
泛微E9流程自定义功能扩展:满足企业特定需求

# 摘要
本文深入探讨了泛微E9平台的流程自定义功能及其重要性,重点阐述了流程自定义的理论基础、实践操作、功能扩展案例以及未来的发展展望。通过对流程自定义的概念、组件、设计与建模、配置与优化等方面的分析,本文揭示了流程自定义在提高企业工作效率、满足特定行业需求和促进流程自动化方面的重要作用。同时,本文提供了丰富的实践案例,演示了如何在泛微E9平台上配置流程、开发自定义节点、集成外部系统,
KST Ethernet KRL 22中文版:硬件安装全攻略,避免这些常见陷阱

# 摘要
本文详细介绍了KST Ethernet KRL 22中文版硬件的安装和配置流程,涵盖了从硬件概述到系统验证的每一个步骤。文章首先提供了硬件的详细概述,接着深入探讨了安装前的准备工作,包括系统检查、必需工具和配件的准备,以及
约束理论与实践:转化理论知识为实际应用
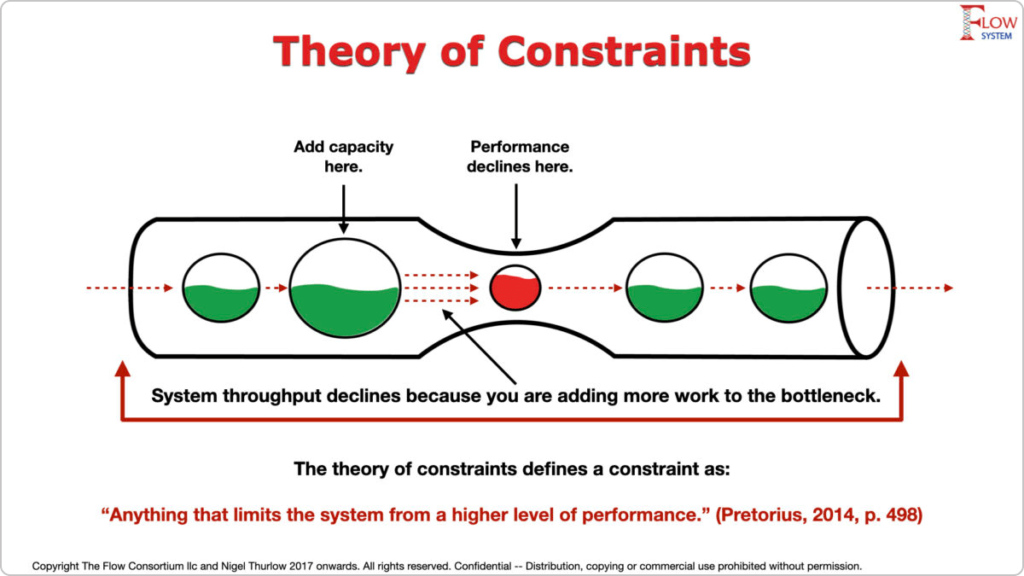
# 摘要
约束理论是一种系统性的管理原则,旨在通过识别和利用系统中的限制因素来提高生产效率和管理决策。本文全面概述了约束理论的基本概念、理论基础和模型构建方法。通过深入分析理论与实践的转化策略,探讨了约束理论在不同行业,如制造业和服务行业中应用的案例,揭示了其在实际操作中的有效性和潜在问题。最后,文章探讨了约束理论的优化与创新,以及其未来的发展趋势,旨在为理论研究和实际应用提供更广阔的
FANUC-0i-MC参数与伺服系统深度互动分析:实现最佳协同效果
# 摘要
本文深入探讨了FANUC 0i-MC数控系统的参数配置及其在伺服系统中的应用。首先介绍了FANUC 0i-MC参数的基本概念和理论基础,阐述了参数如何影响伺服控制和机床的整体性能。随后,文章详述了伺服系统的结构、功能及调试方法,包括参数设定和故障诊断。在第三章中,重点分析了如何通过参数优化提升伺服性能,并讨论了伺服系统与机械结构的匹配问题。最后,本文着重于故障预防和维护策略,提
ABAP流水号安全性分析:避免重复与欺诈的策略
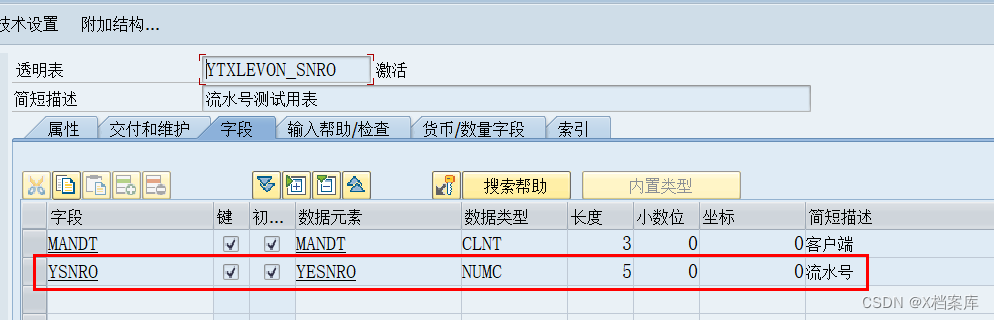
# 摘要
本文全面探讨了ABAP流水号的概述、生成机制、安全性实践技巧以及在ABAP环境下的安全性增强。通过分析流水号生成的基本原理与方法,本文强调了哈希与加密技术在保障流水号安全中的重要性,并详述了安全性考量因素及性能影响。同时,文中提供了避免重复流水号设计的策略、防范欺诈的流水号策略以及流水号安全的监控与分析方法。针对ABAP环境,本文论述了流水号生成的特殊性、集成安全机制的实现,以及安全问题的ABAP代
Windows服务器加密秘籍:避免陷阱,确保TLS 1.2的顺利部署
# 摘要
本文提供了在Windows服务器上配置TLS 1.2的全面指南,涵盖了从基本概念到实际部署和管理的各个方面。首先,文章介绍了TLS协议的基础知识和其在加密通信中的作用。其次,详细阐述了TLS版本的演进、加密过程以及重要的安全实践,这
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )