掌握Python中的时间序列分析技术
发布时间: 2024-03-28 06:36:48 阅读量: 38 订阅数: 15 

如何利用python进行时间序列分析
# 1. 时间序列分析简介
- 1.1 什么是时间序列数据
- 1.2 时间序列分析的重要性
- 1.3 Python在时间序列分析中的应用
在本章中,我们将介绍时间序列分析的基础知识,包括时间序列数据的定义和特点,以及时间序列分析在实际中的重要性。我们还将探讨Python在时间序列分析中的应用,为后续更深入的学习做好准备。
# 2. 准备工作
- 2.1 安装Python及相关库
- 2.2 导入数据与数据预处理
- 2.3 时间序列数据可视化
在进行时间序列分析之前,首先需要进行一些准备工作,包括安装必要的Python环境和相关库,导入数据并进行数据预处理,以及对时间序列数据进行可视化展示。让我们逐步进行以下操作。
# 3. 时间序列预处理
在时间序列分析中,预处理是非常重要的一步,它可以帮助我们更好地理解数据的特征并提升模型的准确性。在这一章节中,我们将讨论时间序列预处理的几个关键步骤。
- **3.1 缺失值处理**
缺失值是时间序列数据中常见的问题,我们需要采取合适的方法处理这些缺失值,常见的方法包括插值法、向前填充、向后填充等。下面是一个示例代码,演示如何使用向前填充的方式处理时间序列数据中的缺失值:
```python
# 导入 pandas 库
import pandas as pd
# 创建包含缺失值的时间序列数据
data = {'date': ['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-06'],
'value': [10, 15, None, 20]}
df = pd.DataFrame(data)
# 使用向前填充的方法填补缺失值
df['value'].fillna(method='ffill', inplace=True)
print(df)
```
在上述代码中,我们创建了一个包含缺失值的时间序列数据,并使用向前填充的方法填补了缺失值。
- **3.2 平稳性检验**
时间序列数据的平稳性是很多时间序列模型的基本假设,通过平稳性检验可以判断数据是否平稳。常用的平稳性检验方法包括ADF单位根检验和KPSS检验。下面是一个示例代码,演示如何对时间序列数据进行ADF单位根检验:
```python
from statsmodels.tsa.stattools import adfuller
import numpy as np
# 创建示例数据
data = np.random.randn(100)
result = adfuller(data)
print('ADF统计量:%f' % result[0])
print('P值:%f' % result[1])
```
在上面的代码中,我们使用了ADF单位根检验对随机生成的时间序列数据进行平稳性检验。
- **3.3 季节性调整**
时间序列数据中常常存在季节性变化,为了更好地预测和建模,我们需要对数据进行季节性调整。常见的方法包括差分法和季节性分解法。下面是一个示例代码,演示如何使用季节性分解法对时间序列数据进行季节性调整:
```python
from statsmodels.tsa.seasonal import seasonal_decompose
# 创建示例数据
data = [10, 20, 15, 25, 30, 35, 40, 45, 50, 55, 60]
result = seasonal_decompose(data, model='additive', period=4)
trend = result.trend
seasonal = result.seasonal
residual = result.resid
print('趋势部分:', trend)
print('季节性部分:', seasonal)
print('残差部分:', residual)
```
在上述代码中,我们使用季节性分解方法对示例数据进行了季节性调整,并分别输出了趋势部分、季节性部分和残差部分。
- **3.4 数据拆分与训练集/测试集划分**
在进行时间序列分析时,为了评估模型的性能,我们通常将数据集划分为训练集和测试集。下面是一个示例代码,演示如何将数据集按照时间顺序划分为训练集和测试集:
```python
data = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
train_size = int(len(data) * 0.7)
train_data, test_data = data[:train_size], data[train_size:]
print('训练集数据:', train_data)
print('测试集数据:', test_data)
```
通过以上这些时间序列预处理的步骤,我们可以更好地处理时间序列数据,为接下来的建模和分析奠定基础。
# 4. 时间序列模型
时间序列模型是时间序列分析的核心部分,帮助我们对数据进行预测和分析。在Python中,有几种常见的时间序列模型可以使用,包括移动平均模型(MA)、自回归模型(AR)、自回归移动平均模型(ARIMA)和季节性自回归集成移动平均模型(SARIMA)。
#### 4.1 移动平均模型(MA)
移动平均模型是一种基本的时间序列模型,它利用过去一定时间内的残差数据来预测未来的数据。在Python中,我们可以使用`statsmodels`库来构建MA模型。
```python
# 导入相关库
import pandas as pd
from statsmodels.tsa.arima_model import ARMA
# 创建MA模型并拟合数据
model = ARMA(data, order=(0, 1))
result = model.fit()
# 预测未来数据
forecast = result.predict(start=start_date, end=end_date)
```
#### 4.2 自回归模型(AR)
自回归模型是利用时间序列自身的历史数据来预测未来数据的模型。在Python中,可以使用`statsmodels`库构建AR模型。
```python
# 导入相关库
import pandas as pd
from statsmodels.tsa.arima_model import ARMA
# 创建AR模型并拟合数据
model = ARMA(data, order=(1, 0))
result = model.fit()
# 预测未来数据
forecast = result.predict(start=start_date, end=end_date)
```
#### 4.3 自回归移动平均模型(ARIMA)
自回归移动平均模型结合了AR和MA模型,适用于非平稳时间序列数据的建模。在Python中,可以使用`statsmodels`库构建ARIMA模型。
```python
# 导入相关库
import pandas as pd
from statsmodels.tsa.arima_model import ARIMA
# 创建ARIMA模型并拟合数据
model = ARIMA(data, order=(1, 1, 1))
result = model.fit()
# 预测未来数据
forecast = result.predict(start=start_date, end=end_date, typ='levels')
```
#### 4.4 季节性自回归集成移动平均模型(SARIMA)
SARIMA模型是在ARIMA模型的基础上考虑季节性因素的模型,能更准确地捕捉数据的季节性特征。在Python中,也可以使用`statsmodels`库构建SARIMA模型。
```python
# 导入相关库
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
# 创建SARIMA模型并拟合数据
model = SARIMAX(data, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
result = model.fit()
# 预测未来数据
forecast = result.predict(start=start_date, end=end_date, dynamic=True)
```
以上是一些常见的时间序列模型及其在Python中的应用。在实际应用中,需要根据数据的特点和需求选择合适的模型,并对模型进行适当的调参和优化,以提高预测准确度。
# 5. 时间序列模型评估与调参
在时间序列分析中,对建立的模型进行评估和调参是非常重要的。本章将介绍时间序列模型的评估指标、参数调优技术以及模型诊断与改进方法。
#### 5.1 模型评估指标
在评估时间序列模型时,我们通常会使用以下指标来衡量模型的表现:
- **均方根误差(RMSE)**:用于测量观测值与预测值之间的误差,数值越小表示模型预测越准确。
- **平均绝对误差(MAE)**:表示预测误差的平均绝对值,同样数值越小表示模型表现越好。
- **平均绝对百分比误差(MAPE)**:用于衡量模型的百分比预测误差,可以更好地评估模型的准确性。
- **残差自相关性(ACF)**:通过残差的自相关图可以了解模型中是否存在未捕捉到的信息。
- **残差正态性检验(Normality Test)**:检验模型残差是否符合正态分布,从而验证模型的合理性。
#### 5.2 参数调优技术
在时间序列模型中,一些参数的选择对模型的性能有着重要的影响。以下是一些常用的参数调优技术:
- **网格搜索调参(Grid Search)**:通过遍历给定参数的组合来确定最优参数。
- **贝叶斯优化调参(Bayesian Optimization)**:基于贝叶斯方法不断调整参数来最小化目标函数。
- **交叉验证(Cross Validation)**:通过将数据集分为训练集和验证集,来评估模型的泛化能力并选择最佳参数。
#### 5.3 模型诊断与改进
在建立时间序列模型后,我们需要对模型进行诊断并进一步改进,以提高模型的准确性和稳定性。常用的方法包括:
- **残差分析(Residual Analysis)**:通过分析模型残差的分布情况,来评估模型的拟合程度。
- **模型优化(Model Optimization)**:根据模型评估结果和调参技术的反馈,对模型结构和参数进行调整,以获得更好的预测效果。
- **集成模型(Ensemble Models)**:将多个基础模型组合起来,以期望提高整体的预测性能。
通过以上内容,我们可以更好地理解如何对时间序列模型进行评估和调参,并且对模型诊断与改进有一定的指导意义。在实际应用中,结合具体情况选择合适的评估指标和调参技术,将有助于提升时间序列分析的效果和准确性。
# 6. 高级时间序列分析技术
在这一章中,我们将介绍一些高级的时间序列分析技术,帮助读者更深入地理解和应用时间序列模型。
### 6.1 长短期记忆网络(LSTM)模型
长短期记忆网络是一种特殊的循环神经网络,广泛应用于时间序列数据的建模和预测中。其主要特点是能够捕捉数据中的长期依赖关系,适合处理具有长期记忆特性的时间序列数据。
```python
# 示例代码:使用LSTM模型对时间序列数据进行预测
import numpy as np
from keras.models import Sequential
from keras.layers import LSTM, Dense
# 构造时间序列数据
data = np.array([10, 20, 30, 40, 50, 60, 70, 80, 90])
# 将时间序列数据转换为适合LSTM模型输入的格式
def create_dataset(data, time_steps):
X, y = [], []
for i in range(len(data) - time_steps):
X.append(data[i:i + time_steps])
y.append(data[i + time_steps])
return np.array(X), np.array(y)
time_steps = 3
X, y = create_dataset(data, time_steps)
# 构建LSTM模型
model = Sequential()
model.add(LSTM(units=50, activation='relu', input_shape=(time_steps, 1)))
model.add(Dense(units=1))
model.compile(optimizer='adam', loss='mse')
# 训练模型
model.fit(X.reshape((-1, time_steps, 1)), y, epochs=100, verbose=0)
# 预测未来的时间序列值
future_data = np.array([70, 80, 90]) # 假设的未来数据
future_input = future_data.reshape((1, time_steps, 1))
prediction = model.predict(future_input)
print("预测值为:", prediction)
```
通过上述代码,读者可以了解如何使用LSTM模型对时间序列数据进行预测,其中包括数据的准备、模型的构建、训练和预测过程。
### 6.2 季节性分解模型(STL)
季节性分解模型是一种经典的时间序列分析方法,能够将时间序列数据分解为趋势、季节性和残差三个部分,从而更好地理解数据的特征和规律。
```python
# 示例代码:使用STL模型对时间序列数据进行季节性分解
import pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
# 创建示例时间序列数据
date_rng = pd.date_range(start='2022-01-01', end='2022-12-31', freq='D')
data = np.sin(np.arange(len(date_rng)) * 2 * np.pi / 365)
ts = pd.Series(data, index=date_rng)
# 进行季节性分解
result = seasonal_decompose(ts, model='additive')
# 可视化分解结果
plt.figure(figsize=(12, 6))
plt.subplot(411)
plt.plot(ts, label='Original')
plt.legend()
plt.subplot(412)
plt.plot(result.trend, label='Trend')
plt.legend()
plt.subplot(413)
plt.plot(result.seasonal, label='Seasonal')
plt.legend()
plt.subplot(414)
plt.plot(result.resid, label='Residual')
plt.legend()
plt.tight_layout()
plt.show()
```
上述代码展示了如何使用季节性分解模型(STL)对时间序列数据进行季节性分解,并通过可视化展示了分解结果中的趋势、季节性和残差部分。
### 6.3 自适应滤波方法
自适应滤波是一种能够根据数据特点自动调整滤波参数的技术,对于处理时间序列数据中的噪声和异常值具有很好的效果,有助于提高数据的质量和准确性。
```python
# 示例代码:使用自适应滤波方法对时间序列数据进行平滑处理
from scipy.signal import savgol_filter
# 创建示例时间序列数据
np.random.seed(0)
data = np.random.random(100) * 10 + np.sin(2 * np.pi * np.linspace(0, 1, 100) * 5)
# 应用Savitzky-Golay滤波器进行平滑处理
smooth_data = savgol_filter(data, window_length=15, polyorder=2)
# 可视化处理前后的数据对比
plt.figure(figsize=(12, 6))
plt.plot(data, label='Original Data')
plt.plot(smooth_data, label='Smoothed Data', linestyle='--')
plt.legend()
plt.show()
```
通过上述代码,读者可以学习如何使用自适应滤波方法(这里以Savitzky-Golay滤波器为例)对时间序列数据进行平滑处理,减少噪声对数据分析的影响。
### 6.4 实战案例分享与总结
在这一部分,我们将分享一个实战案例,展示如何结合前面介绍的时间序列分析技术,应用于真实数据,并对全文进行总结和回顾,帮助读者更好地掌握时间序列分析技术。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这篇专栏以Python为工具,主要介绍了股票交易模型的应用。首先,讲解如何利用Python进行股票数据的实时监控,帮助投资者及时获取市场信息。其次,深入探讨了Python中的时间序列分析技术,帮助读者更好地理解股票数据的特点与规律。接着,介绍了Python中的大数据处理技术在股票交易模型中的应用,帮助读者构建更加精准的交易策略。最后,重点讲解了Python中的高频交易策略的设计与实现,帮助读者更好地应对市场波动。通过本专栏的学习,读者将掌握Python在股票交易领域的应用技巧,为提高交易效率和成功率提供有效的参考和指导。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【VC709开发板原理图进阶】:深度剖析FPGA核心组件与性能优化(专家视角)

# 摘要
本论文首先对VC709开发板进行了全面概述,并详细解析了其核心组件。接着,深入探讨了FPGA的基础理论及其架构,包括关键技术和设计工具链。文章进一步分析了VC709开发板核心组件,着重于FPGA芯片特性、高速接口技术、热管理和电源设计。此外,本文提出了针对VC709性能优化
IP5306 I2C同步通信:打造高效稳定的通信机制

# 摘要
本文系统地阐述了I2C同步通信的基础原理及其在现代嵌入式系统中的应用。首先,我们介绍了IP5306芯片的功能和其在同步通信中的关键作用,随后详细分析了实现高效稳定I2C通信机制的关键技术,包括通信协议解析、同步通信的优化策略以及IP5306与I2C的集成实践。文章接着深入探讨了IP5306 I2C通信的软件实现,涵盖软件架
Oracle数据库新手指南:DBF数据导入前的准备工作
# 摘要
本文旨在详细介绍Oracle数据库的基础知识,并深入解析DBF数据格式及其结构,包括文件发展历程、基本结构、数据类型和字段定义,以及索引和记录机制。同时,本文指导读者进行环境搭建和配置,包括Oracle数据库软件安装、网络设置、用户账户和权限管理。此外,本文还探讨了数据导入工具的选择与使用方法,介绍了SQL
FSIM对比分析:图像相似度算法的终极对决
# 摘要
本文首先概述了图像相似度算法的发展历程,重点介绍了FSIM算法的理论基础及其核心原理,包括相位一致性模型和FSIM的计算方法。文章进一步阐述了FSIM算法的实践操作,包括实现步骤和性能测试,并探讨了针对特定应用场景的优化技巧。在第四章中,作者对比分析了FSIM与
应用场景全透视:4除4加减交替法在实验报告中的深度分析
# 摘要
本文综合介绍了4除4加减交替法的理论和实践应用。首先,文章概述了该方法的基础理论和数学原理,包括加减法的基本概念及其性质,以及4除4加减交替法的数学模型和理论依据。接着,文章详细阐述了该方法在实验环境中的应用,包括环境设置、操作步骤和结果分析。本文还探讨了撰写实验报告的技巧,包括报告的结构布局、数据展示和结论撰写。最后,通过案例分析展示了该方法在不同领域的应用,并对实验报告的评价标准与质量提升建议进行了讨论。本文旨在
电子设备冲击测试必读:IEC 60068-2-31标准的实战准备指南
# 摘要
IEC 60068-2-31标准为冲击测试提供了详细的指导和要求,涵盖了测试的理论基础、准备策划、实施操作、标准解读与应用、以及提升测试质量的策略。本文通过对冲击测试科学原理的探讨,分类和方法的分析,以及测试设备和工具的选择,明确了测试的执行流程。同时,强调了在测试前进行详尽策划的重要性,包括样品准备、测试计划的制定以及测试人员的培训。在实际操作中,本
【神经网络】:高级深度学习技术提高煤炭价格预测精度

# 摘要
随着深度学习技术的飞速发展,该技术已成为预测煤炭价格等复杂时间序列数据的重要工具。本文首先介绍了深度学习与煤炭价格预测的基本概念和理论基础,包括神经网络、损失函数、优化器和正则化技术。随后,文章详细探讨了深度学习技术在煤炭价格预测中的具体应用,如数据预处理、模型构建与训练、评估和调优策略。进一步,本文深入分析了高级深度学习技术,包括卷积神经网络(CNN)、循环神经网络(RNN)和长
电子元器件寿命预测:JESD22-A104D温度循环测试的权威解读
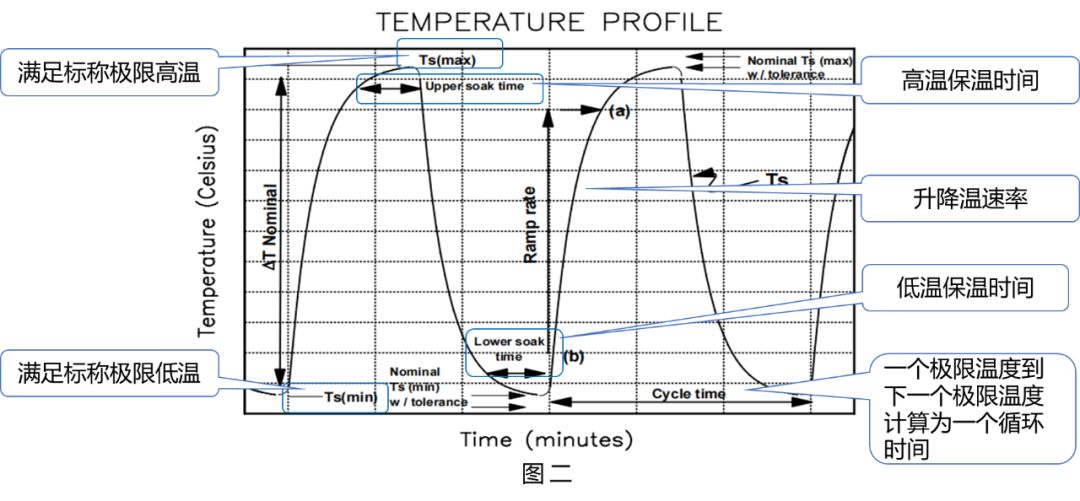
# 摘要
电子元器件在各种电子设备中扮演着至关重要的角色,其寿命预测对于保证产品质量和可靠性至关重要。本文首先概述了电子元器件寿命预测的基本概念,随后详细探讨了JESD22-A104D标准及其测试原理,特别是温度循环测试的理论基础和实际操作方法。文章还介绍了其他加速老化测试方法和寿命预测模型的优化,以及机器学习技术在预测中的应用。通过实际案例分析,本文深入讨论了预测模型的建立与验证。最后,文章展望了未来技术创新、行
【数据库连接池详解】:高效配置Oracle 11gR2客户端,32位与64位策略对比
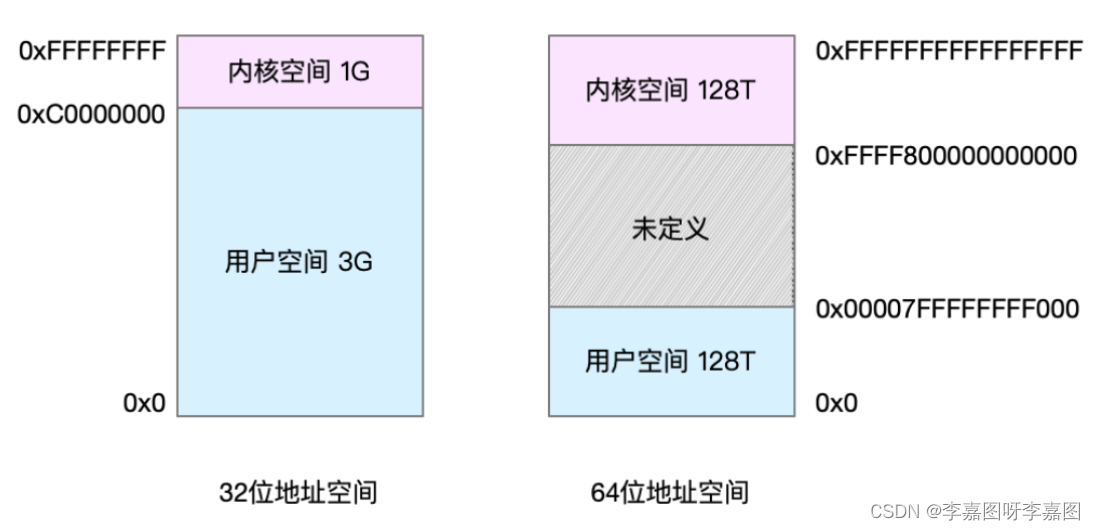
# 摘要
本文对Oracle 11gR2数据库连接池的概念、技术原理、高效配置、不同位数客户端策略对比,以及实践应用案例进行了系统的阐述。首先介绍了连接池的基本概念和Oracle 11gR2连接池的技术原理,包括其架构、工作机制、会话管理、关键技术如连接复用、负载均衡策略和失效处理机制。然后,文章转向如何高效配置Oracle 11gR2连接池,涵盖环境准备、安装步骤、参数
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )