SQL Server AlwaysOn集群概述与架构解析
发布时间: 2024-02-21 05:42:55 阅读量: 199 订阅数: 43 
# 1. SQL Server AlwaysOn集群简介
## 1.1 理解SQL Server AlwaysOn集群的概念
SQL Server AlwaysOn集群是SQL Server的一项高可用性和灾难恢复解决方案,它通过将多个数据库实例连接在一起,提供了数据库级别的故障转移功能。这意味着即使一个数据库实例发生故障,其他实例也可以接管其工作,确保业务的持续运行。
## 1.2 AlwaysOn集群的优势和应用场景
SQL Server AlwaysOn集群的优势包括:实现了数据库级别的故障转移和自动切换、提高了数据库的可用性和容错性、支持跨数据中心的异地容灾等。常见的应用场景包括关键业务系统、在线交易处理、大型门户网站等对高可用性和灾难恢复有较高要求的系统。
## 1.3 AlwaysOn集群与传统数据库冗余方案的对比
传统的数据库冗余方案通常采用主备制、数据库镜像等方式实现故障转移和容灾,而SQL Server AlwaysOn集群则提供了更灵活、更自动化、更完整的高可用性解决方案。AlwaysOn集群还支持多个备用节点,可以满足更复杂的业务需求。
接下来,我们将深入了解SQL Server AlwaysOn集群的架构和原理。
# 2. SQL Server AlwaysOn集群架构解析
在本章中,我们将深入探讨SQL Server AlwaysOn集群的架构,包括其基本组成和角色,数据同步机制以及故障切换原理。
### 2.1 AlwaysOn集群的基本架构
SQL Server AlwaysOn集群基本架构主要包括以下组件:
- **AlwaysOn可用性组**:是一组关联的数据库,以确保在发生故障时数据的高可用性和灾难恢复能力。
- **AlwaysOn监听器**:提供虚拟网络名称和静态IP地址,用于客户端连接,实现透明的故障转移。
- **AlwaysOn辅助复制**:辅助数据复制技术,用于在异地数据中心复制数据。
### 2.2 主要组件和角色的介绍
在AlwaysOn集群中,主要有以下角色和组件:
- **主服务器**:负责实时处理读写请求的主数据库服务器。
- **从服务器**:作为主服务器的备份,负责实现数据同步和发生故障时的接管。
- **辅助服务器**:提供辅助复制以实现数据异地复制。
- **WSFC群集**:Windows Server故障转移集群,负责管理服务器节点的故障切换。
### 2.3 数据同步和故障切换原理
数据同步是AlwaysOn集群的核心功能,采用同步复制机制确保主从服务器之间数据的实时性和一致性。故障切换原理是主服务器发生故障时,WSFC群集会自动将从服务器提升为新的主服务器,确保服务的持续可用性。
总结:本章详细介绍了SQL Server AlwaysOn集群的架构和关键组件,解释了数据同步和故障切换的原理,为部署和管理AlwaysOn集群提供了基础理论支持。
# 3. 部署SQL Server AlwaysOn集群
在部署SQL Server AlwaysOn集群之前,需要确保已经完成了Windows Server故障转移集群(WSFC)的配置。接下来我们将逐步进行AlwaysOn集群节点的配置和创建AlwaysOn可用性组。
#### 3.1 配置Windows Server故障转移集群(WSFC)
在Windows Server上配置故障转移集群是SQL Server AlwaysOn集群部署的基础。以下是配置WSFC的简要步骤:
1. 使用Server Manager启动故障转移集群管理器。
2. 在管理器中,选择“创建新的故障转移集群”。
3. 依次输入集群名称、IP地址、验证配置等信息,完成集群的创建。
4. 将所有参与AlwaysOn集群的节点添加到WSFC中。
#### 3.2 配置AlwaysOn集群节点
在配置WSFC后,需要将SQL Server节点添加到WSFC中,并安装AlwaysOn功能。以下是配置AlwaysOn集群节点的简要步骤:
1. 在每个SQL Server节点上安装相同版本的SQL Server,并确保安装的时候选择AlwaysOn高可用性选项。
2. 将SQL Server节点添加到WSFC中,确保节点状态为“Up”并且可以相互通信。
3. 在SQL Server Management Studio中启用AlwaysOn功能,并配置节点间的数据同步设置。
#### 3.3 创建AlwaysOn可用性组
一旦节点配置完成,接下来就是创建AlwaysOn可用性组,用于实现数据库的高可用性和灾难恢复。以下是创建AlwaysOn可用性组的简要步骤:
1. 在SQL Server Management Studio中,右键单击“可用性组”并选择“新建可用性组向导”。
2. 依次输入可用性组名称、选择要保护的数据库、添加同步副本等信息。
3. 配置监听器,用于客户端连接和故障切换。
4. 完成向导后,等待数据库同步完成,AlwaysOn可用性组即创建成功。
通过以上步骤,您已成功部署了SQL Server AlwaysOn集群,并创建了可用性组,实现了数据库的高可用性和灾难恢复功能。在实际部署过程中,可以根据具体情况进行调整和优化。
# 4. SQL Server AlwaysOn集群的管理和监控
在本章中,我们将深入探讨SQL Server AlwaysOn集群的管理和监控方法,包括如何监控集群的健康状态、管理可用性组和监听器以及常见故障排查和解决方法。
### 4.1 监控AlwaysOn集群的健康状态
在部署SQL Server AlwaysOn集群后,监控集群的健康状态是至关重要的。可以利用SQL Server Management Studio(SSMS)或者T-SQL语句来监控集群。以下是一些常用的监控方法:
- **SSMS监控:** 在SSMS中,通过展开AlwaysOn高可用性节点,可以查看每个副本的同步状态、健康状态和故障转移状态。
- **T-SQL监控:** 使用系统视图和动态管理视图,如sys.dm_hadr_availability_group_states、sys.dm_hadr_availability_replica_states等,可以编写T-SQL查询来监控AlwaysOn集群的状态并定期运行这些查询以获取最新状态信息。
```sql
SELECT ag.name AS 'AvailabilityGroup',
ar.replica_server_name AS 'ReplicaServer',
adc.database_name AS 'DatabaseName',
drs.synchronization_state_desc AS 'SyncState'
FROM sys.dm_hadr_availability_group_states ags
INNER JOIN sys.availability_replicas ar ON ags.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states drs ON ar.replica_id = drs.replica_id
INNER JOIN sys.availability_databases_cluster adc ON ags.group_id = adc.group_id
```
### 4.2 管理AlwaysOn可用性组和监听器
管理AlwaysOn可用性组和监听器是日常运维中常见的任务。在SSMS中,可以执行如下任务:
- **创建和修改可用性组:** 通过向导式界面或者T-SQL脚本来创建和修改可用性组,包括添加或移除数据库、更改故障转移模式等。
- **配置监听器:** 可以在SSMS中配置AlwaysOn监听器的名称、IP地址和端口,也可以使用T-SQL来完成这些配置。
- **监控和切换故障转移:** 可以手动或自动发起故障转移以切换主副本和次要副本,从而确保业务的持续可用。
### 4.3 常见故障排查和解决方法
在实际运维中,AlwaysOn集群可能会遇到各种故障,如数据同步延迟、连接问题、故障转移失败等。以下是一些常见故障的排查和解决方法:
- **数据同步延迟排查:** 使用SSMS或T-SQL查询来查看数据同步状态和延迟,并排查网络、I/O等方面的问题。
- **连接问题排查:** 检查应用程序连接字符串、监听器配置、Windows防火墙等,确保网络通畅并且能够正确连接到可用性组。
- **故障转移失败排查:** 查看Windows事件日志、SQL Server错误日志以及AlwaysOn系统视图,找出故障转移失败的原因并采取相应措施解决问题。
通过以上方法,有效地监控、管理和排查故障可帮助维护AlwaysOn集群的稳定性和可靠性。
本章内容涵盖了SQL Server AlwaysOn集群的管理和监控方面,能够帮助DBA更好地维护和提升AlwaysOn集群的可用性和性能。
# 5. SQL Server AlwaysOn集群的性能优化
在SQL Server AlwaysOn集群中,性能优化是非常重要的一环,可以有效提升系统的响应速度和稳定性。以下是关于SQL Server AlwaysOn集群性能优化的几项关键内容:
#### 5.1 优化数据同步和故障切换性能
在配置SQL Server AlwaysOn集群时,数据同步和故障切换的性能直接影响整个集群的稳定性。以下是一些建议的优化方法:
```sql
-- 设置合适的数据同步频率
ALTER AVAILABILITY GROUP [MyAvailabilityGroup]
MODIFY REPLICA ON 'NODE2' WITH (SECONDS_TO_COMMIT = 1)
-- 增加数据同步缓冲池大小
ALTER DATABASE [MyDatabase] SET HADR_SYNC_COMMIT [ALL]
-- 预分配数据传输缓存空间
ALTER DATABASE [MyDatabase] SET HADR_FORCE_FAILOVER_ALLOW_DATA_LOSS OFF
```
**代码总结**:
通过调整数据同步频率、增加数据同步缓冲池大小和预分配数据传输缓存空间,可以提升数据同步和故障切换的性能。
**结果说明**:
这些优化措施可以减少数据同步延迟,提高数据一致性,并且保证在故障发生时快速有效地切换到备用节点。
#### 5.2 优化读写分布和负载均衡
合理优化读写分布和负载均衡可以充分利用资源,提高系统整体性能。以下是一些常见的优化方法:
```sql
-- 使用读写分离技术,将读写操作分流到不同节点
ALTER AVAILABILITY GROUP [MyAvailabilityGroup]
MODIFY REPLICA ON 'NODE2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT)
-- 配置负载均衡器,根据实际负载情况调整路由策略
```
**代码总结**:
通过合理配置读写分布和负载均衡,可以提高系统的并发处理能力,降低响应延迟,实现更好的性能优化。
**结果说明**:
优化读写分布和负载均衡可以实现资源最大化利用,避免因节点负载不均衡而导致性能瓶颈,提升系统整体的性能表现。
#### 5.3 使用适当的硬件和网络配置提升性能
优化SQL Server AlwaysOn集群的性能还需要考虑硬件和网络配置的因素,包括但不限于:
- 硬盘读写速度
- 内存容量
- CPU性能
- 网络带宽和稳定性等
选择合适的硬件设备和网络设施,可以有效提升SQL Server AlwaysOn集群的整体性能表现,保证系统稳定运行。
通过对性能优化的综合考虑和合理实施,SQL Server AlwaysOn集群可以更好地满足生产环境的需求,提供高可用性和高性能的数据服务。
# 6. SQL Server AlwaysOn集群最佳实践和安全防护
在部署SQL Server AlwaysOn集群时,采用最佳实践和强化安全防护是至关重要的。本章将介绍一些最佳实践和安全防护措施,以确保集群的稳定性和数据的安全性。
### 6.1 实施最佳实践以确保集群稳定性
#### 使用最新版本的SQL Server和Windows Server
始终使用最新版本的SQL Server和Windows Server操作系统,这样可以获得最新的功能和安全补丁,提高整个集群的稳定性和安全性。
```sql
-- 示例代码
-- 查询SQL Server版本信息
SELECT @@VERSION
```
#### 定期备份和恢复测试
定期对数据库进行备份,并进行恢复测试以确保备份的可靠性和可恢复性。这可以最大程度地减少数据丢失的风险,并确保在故障发生时能够及时恢复数据库。
```sql
-- 示例代码
-- 备份数据库
BACKUP DATABASE YourDatabase TO DISK = 'D:\Backup\YourDatabase.bak'
-- 恢复数据库(测试)
RESTORE DATABASE YourDatabase FROM DISK = 'D:\Backup\YourDatabase.bak' WITH VERIFYONLY
```
#### 定期监控和性能优化
建立完善的监控机制,定期对集群的性能进行分析和优化,及时发现潜在问题并加以解决,以提高整个集群的稳定性和性能。
```sql
-- 示例代码
-- 监控集群健康状态
SELECT * FROM sys.dm_hadr_availability_group_states
```
### 6.2 数据备份与恢复策略
#### 设计合理的备份方案
针对不同类型的数据和业务需求,设计合理的备份策略,包括完整备份、差异备份和日志备份,以确保数据的全面保护和快速恢复。
```sql
-- 示例代码
-- 创建完整备份
BACKUP DATABASE YourDatabase TO DISK = 'D:\Backup\YourDatabase_Full.bak'
-- 创建日志备份
BACKUP LOG YourDatabase TO DISK = 'D:\Backup\YourDatabase_Log.trn'
```
#### 灾难恢复计划
制定完善的灾难恢复计划,包括数据中心间的数据复制和异地备份,以应对重大灾难事件,并确保业务连续性。
```sql
-- 示例代码
-- 设置异地备份
BACKUP DATABASE YourDatabase TO DISK = '\\RemoteServer\Backup\YourDatabase.bak'
```
### 6.3 AlwaysOn集群的安全配置和防护措施
#### 强化安全设置
采用安全认证机制,限制用户权限,加密敏感数据,并定期进行安全审计,以保护数据库免受未经授权的访问和恶意攻击。
```sql
-- 示例代码
-- 创建受限用户
CREATE LOGIN RestrictedUser WITH PASSWORD = 'StrongPassword'
```
#### 防范常见安全威胁
加强网络安全防护,防范常见的安全威胁,如SQL注入、跨站脚本攻击等,避免数据库遭受恶意攻击和数据泄露。
```sql
-- 示例代码
-- 设置网络安全规则
ALTER DATABASE YourDatabase SET TRUSTWORTHY OFF
```
通过实施上述最佳实践和安全防护措施,可以提高SQL Server AlwaysOn集群的稳定性和安全性,确保数据的可靠性和保密性。当然,实际环境中还需要根据具体情况进行定制化的安全策略和措施。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《SQL Server AlwaysOn集群日常运维与管理》专栏深入探讨了SQL Server AlwaysOn集群的各个方面,包括概述与架构解析、部署步骤详解、读写分离配置方法、数据同步机制、数据库水平分区、日志传输流程、缓存策略优化、性能瓶颈攻克、安全加固与权限管理、自动故障转移原理、故障检测与恢复机制优化以及读写分离的负载均衡优化等内容。读者将通过本专栏全面了解SQL Server AlwaysOn集群的管理与运维技巧,从而更好地实现高可用、高性能的数据库系统运行。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【软件支持】AG3335A芯片操作系统与API详解

# 摘要
本文对AG3335A芯片进行了全面介绍,涵盖了操作系统部署与管理、芯片API的使用方法及高级应用开发。首先,概述了AG3335A芯片,并详述了操作系统的安装、配置、维护与更新。其次,文中深入探讨了如何使用AG3335A芯片的API,包括基础理论、开发环境搭建及编程实战。第三部分则集中于AG3335A芯片的高级应用,包括硬件接口编程控制、软件性能调优及
编译原理精髓提炼:陈意云课程的思维导图笔记(掌握学习重点与难点)
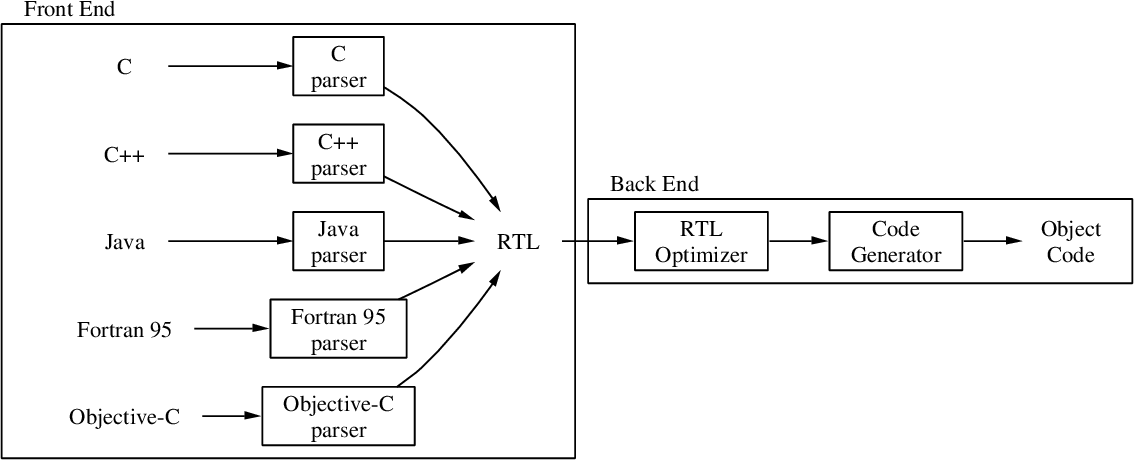
# 摘要
编译原理是计算机科学中的基础领域之一,涉及从源代码到可执行程序的转换过程。本文系统地介绍了编译原理的核心概念、流程及其关键阶段。首先阐述了词法分析阶段,包括词法分析器的角色、正则表达式与有限自动机的应用,以及词法分析器的实现技术。接着深入探讨了语法分析阶段,重点讲解了上下文无关文法、语法分析算法的选择与比较,以及语法分析器
【黑金Spartan-6性能测试】:评估与优化Verilog设计的黄金法则
# 摘要
本文对FPGA Spartan-6系列的硬件性能测试进行全面分析,涵盖了测试基础、原理、实践和优化策略。首先介绍了性能测试的基本概念和Spartan-6的概述,然后详细阐述了硬件性能测试的原理,包括测试工具的选择、测试环境的配置、性能评估标准,以及测试方法论。第三章基于测试实践,展示了如何通过功能测试、性能瓶颈分析和优化策略的实施来提升硬件性能。第四章进一步探讨了在Verilog设计中如何实现代码级、架构级和系统
Swatcup版本控制整合术:Git_SVN完美集成之道

# 摘要
版本控制系统对于软件开发至关重要,特别是Git和SVN作为行业标准工具,它们在不同的项目需求下各自拥有优势和局限。本文首先介绍Git与SVN的基础知识,再深入探讨两者间的差
【LS-DYNA材料编程精要】:编写高效材料子程序的秘诀大公开

# 摘要
LS-DYNA作为一款广泛应用的非线性有限元分析软件,其材料编程能力对于复杂材料行为的模拟至关重要。本文首先概述了LS-DYNA材料编程的原理和重要性,进而深入探讨了材料模型理论基础,包括材料模型的重要性、分类与选择,以及参数的定义和影响。接着,本文详细介绍了LS-DYNA材料子程序的结构、编程语言和开发环境,以及如何通过子程
构建最优资产配置模型:投资组合优化与Lingo的结合
# 摘要
本文旨在探讨投资组合优化的基础理论,并详细介绍Lingo软件在投资组合优化中的应用。文章首先回顾了投资组合优化的核心概念,随后介绍了Lingo软件的特性和在构建优化模型前的准备工作。通过实例演示,本文展示了如何应用Lingo构建包含线性、非线性以及整数规划的投资组合模型,并详细讨论了使用Lingo求解这些模型的方法。此外,本文还进一步探索了投资组合优化的进阶策略,包括风险与收益的权衡、多目标优化的实现以及适应市场动态变化的优化模型。通过敏感性分析和经济意义的解读,文章提供了对模型结果深入的分析与解释,为投资决策提供了有力支持。
# 关键字
投资组合优化;Lingo软件;线性规划;非
揭秘PUBG:罗技鼠标宏的性能与稳定性优化术

# 摘要
罗技鼠标宏作为提升游戏操作效率的工具,在《绝地求生》(PUBG)等游戏中广泛应用。本文首先介绍了罗技鼠标宏的基本概念及在PUBG中的应用和优势。随后探讨了宏与Pergamon软件交互机制及其潜在对游戏性能的影响。第三部分聚焦于宏性能优化实践,包括编写、调试、代码优化及环境影响分析。第四章提出了提升宏稳定性的策略,如异常处理机制和兼容性测试。第五章讨论了
揭秘低压开关设备核心标准IEC 60947-1:专业解读与应用指南(全面解析低压开关设备行业标准及安全应用)
# 摘要
本文全面概述了低压开关设备及其相关的IEC 60947-1国际标准。从标准的理论基础、技术要求到安全应用实践,文章详细解读了低压开关设备的分类、定义、安全要求、试验方法以及标记说明。通过案例分析,探讨了IEC 60947-1标准在不同行业中的应用及其重要性,尤其是在工业自动化和建筑电气领域。最后,文章展望了该标准的未来发展趋势,讨论了其在全球化市场和新兴技术影响下面临的挑战,并
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )