【Python代码性能优化指南】:10个提速秘诀,让你的代码飞起来
发布时间: 2024-06-19 00:01:08 阅读量: 14 订阅数: 13 
# 1. Python性能优化概述**
Python性能优化是一项重要的技术,可以显著提高应用程序的执行速度和响应能力。通过优化代码结构、算法、语言特性和使用工具和技术,我们可以有效地减少执行时间和资源消耗。
本章将介绍Python性能优化的基本概念和方法,为后续章节的深入讨论奠定基础。我们将探讨影响Python性能的关键因素,包括代码结构、数据结构选择、算法复杂度以及语言特性。通过理解这些概念,开发人员可以识别和解决代码中的性能瓶颈,从而显著提高应用程序的整体性能。
# 2. 代码结构优化
### 2.1 代码模块化和复用
#### 2.1.1 使用函数和类封装代码
将复杂代码封装在函数或类中可以提高代码的可读性、可维护性和可复用性。函数可以将特定任务或操作抽象成一个独立的单元,而类可以将相关数据和行为组织在一起,形成一个对象。
**代码示例:**
```python
# 定义一个计算斐波那契数列的函数
def fibonacci(n):
if n < 2:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
```
**逻辑分析:**
此函数使用递归算法计算斐波那契数列。它有两个基本情况:当 n 小于 2 时,返回 n;否则,返回 n-1 和 n-2 的斐波那契数之和。
**参数说明:**
* n:要计算的斐波那契数列的索引
#### 2.1.2 避免重复代码
重复代码不仅会降低代码的可读性和可维护性,还会导致错误和冗余。通过使用函数或类,可以将重复代码提取到一个位置,并根据需要多次调用。
**代码示例:**
```python
# 定义一个打印字符串的函数
def print_string(string):
print(string)
# 使用 print_string 函数多次打印字符串
print_string("Hello")
print_string("World")
print_string("Python")
```
**逻辑分析:**
此代码使用 print_string 函数多次打印不同的字符串。通过将打印逻辑封装在函数中,避免了重复代码。
**参数说明:**
* string:要打印的字符串
### 2.2 数据结构选择与优化
#### 2.2.1 选择合适的容器类型
Python 提供了多种容器类型,如列表、元组、字典和集合。选择合适的容器类型对于优化数据访问效率至关重要。
**表格:Python 容器类型比较**
| 容器类型 | 特点 | 访问效率 |
|---|---|---|
| 列表 | 有序、可变 | 随机访问 O(1),插入/删除 O(n) |
| 元组 | 有序、不可变 | 随机访问 O(1) |
| 字典 | 无序、可变 | 根据键查找 O(1) |
| 集合 | 无序、不可变 | 根据元素查找 O(1) |
#### 2.2.2 优化数据结构的访问效率
除了选择合适的容器类型外,还可以通过以下方式优化数据结构的访问效率:
* **使用索引访问元素:**对于列表和元组,使用索引访问元素比遍历要快。
* **使用键访问字典:**对于字典,使用键访问元素比遍历要快。
* **使用集合查找元素:**对于集合,使用元素查找比遍历要快。
* **使用切片操作:**对于列表和元组,使用切片操作可以快速获取子序列。
# 3. 算法优化
### 3.1 时间复杂度分析
#### 3.1.1 理解算法的复杂度
算法的复杂度描述了算法在输入数据规模增加时,其执行时间或空间消耗的增长速度。常见的复杂度表示法有:
- **O(1)**:常数时间复杂度,无论输入数据规模如何,执行时间或空间消耗都保持不变。
- **O(n)**:线性时间复杂度,执行时间或空间消耗与输入数据规模成正比。
- **O(n^2)**:平方时间复杂度,执行时间或空间消耗与输入数据规模的平方成正比。
- **O(log n)**:对数时间复杂度,执行时间或空间消耗与输入数据规模的对数成正比。
#### 3.1.2 选择高效的算法
在选择算法时,需要考虑输入数据规模和算法的复杂度。对于小规模数据,复杂度较高的算法可能不会对性能产生明显影响。但对于大规模数据,选择低复杂度的算法至关重要。
例如,对于查找数组中的元素,线性搜索算法的复杂度为 O(n),而二分查找算法的复杂度为 O(log n)。当数组规模较小时,线性搜索可能更有效率。但当数组规模较大时,二分查找算法的性能优势将非常明显。
### 3.2 空间复杂度优化
#### 3.2.1 减少内存消耗
空间复杂度描述了算法在执行过程中所需的内存空间大小。优化空间复杂度可以减少程序的内存占用,从而提高性能。
以下是一些减少内存消耗的技巧:
- **使用合适的数据结构**:选择空间效率高的数据结构,如哈希表或树,可以减少内存占用。
- **避免不必要的复制**:在传递数据时,尽量通过引用传递,避免创建不必要的副本。
- **释放未使用的资源**:在不再需要时,及时释放内存资源,如关闭文件或释放对象引用。
#### 3.2.2 使用缓存和惰性求值
缓存可以存储经常访问的数据,从而减少对昂贵操作(如数据库查询)的调用次数。惰性求值可以推迟计算,直到需要时才进行,从而节省内存空间。
以下代码示例展示了如何使用缓存优化空间复杂度:
```python
import functools
@functools.lru_cache(maxsize=100)
def expensive_function(arg):
# 昂贵的计算
return result
```
此代码使用 `@functools.lru_cache` 装饰器为 `expensive_function` 函数创建了一个缓存。缓存最多存储 100 个最近计算的结果。当函数再次被调用时,如果参数与缓存中的值匹配,则直接从缓存中返回结果,避免了昂贵的计算。
# 4. 语言特性优化
### 4.1 Python内置优化器
#### 4.1.1 编译器优化
Python编译器在将Python代码转换为字节码时,会进行一系列优化,以提高代码执行效率。这些优化包括:
* **常量折叠:**将常量表达式计算为常量值,避免在运行时重复计算。
* **尾递归消除:**将尾递归函数转换为循环,避免不必要的函数调用开销。
* **循环展开:**将循环体复制为多个副本,以减少循环控制开销。
* **公共子表达式消除:**识别并消除重复计算的子表达式。
#### 4.1.2 运行时优化
Python解释器在执行字节码时,也会进行一些优化,以提高代码执行效率。这些优化包括:
* **字节码缓存:**将编译后的字节码缓存起来,避免重复编译。
* **垃圾回收:**自动释放不再使用的内存,以减少内存消耗。
* **JIT编译:**将某些热点代码块编译为机器码,以提高执行速度。
### 4.2 类型标注和类型检查
#### 4.2.1 使用类型标注提高性能
Python 3.6 引入了类型标注功能,允许开发者为变量和函数参数指定类型。类型标注可以帮助编译器和解释器进行以下优化:
* **静态类型检查:**在运行时之前检查类型不匹配,从而避免运行时错误。
* **更快的代码执行:**编译器可以根据类型标注生成更优化的字节码。
* **更好的代码可读性和可维护性:**类型标注使代码更容易理解和维护。
#### 4.2.2 利用类型检查器优化代码
类型检查器(如 mypy)可以静态分析 Python 代码,检查类型不匹配和潜在错误。利用类型检查器可以帮助开发者:
* **早期发现错误:**在运行时之前发现类型问题,避免代价高昂的调试。
* **提高代码质量:**强制执行类型约束,确保代码的健壮性和可维护性。
* **提高开发效率:**通过自动类型检查,减少手动测试和调试的时间。
# 5. 工具和技术优化**
**5.1 代码分析和性能测试**
**5.1.1 使用性能分析工具**
使用性能分析工具可以帮助识别代码中的性能瓶颈。这些工具通常提供详细的报告,其中包含有关函数执行时间、内存使用和资源消耗的信息。一些流行的性能分析工具包括:
- **cProfile:**用于分析函数执行时间和调用次数。
- **line_profiler:**用于分析代码行执行时间。
- **memory_profiler:**用于分析内存使用情况。
**代码示例:**
```python
import cProfile
def my_function():
# ...
cProfile.run('my_function()')
```
**5.1.2 进行基准测试和性能比较**
基准测试和性能比较是评估代码性能改进的有效方法。通过在不同条件下运行代码并测量其执行时间和资源消耗,可以确定优化措施的有效性。
**代码示例:**
```python
import timeit
def my_function_optimized():
# ...
def my_function_unoptimized():
# ...
setup_code = '''
from __main__ import my_function_optimized, my_function_unoptimized
number = 100000
result_optimized = timeit.timeit('my_function_optimized()', setup=setup_code, number=number)
result_unoptimized = timeit.timeit('my_function_unoptimized()', setup=setup_code, number=number)
print(f'Optimized: {result_optimized} seconds')
print(f'Unoptimized: {result_unoptimized} seconds')
```
**5.2 缓存和并行化**
**5.2.1 使用缓存提高访问速度**
缓存是存储经常访问的数据的临时存储区域。通过将数据存储在缓存中,可以减少从原始数据源(如数据库或文件)检索数据的次数,从而提高访问速度。
**代码示例:**
```python
import functools
@functools.lru_cache(maxsize=100)
def my_cached_function(arg1, arg2):
# ...
my_cached_function(1, 2) # First call will fill the cache
my_cached_function(1, 2) # Second call will retrieve from cache
```
**5.2.2 利用多线程和多进程并行处理**
并行化涉及将任务分配给多个线程或进程同时执行。这可以显著提高计算密集型任务的性能。
**代码示例:**
```python
import threading
def my_threaded_function(arg):
# ...
threads = []
for i in range(10):
thread = threading.Thread(target=my_threaded_function, args=(i,))
threads.append(thread)
for thread in threads:
thread.start()
for thread in threads:
thread.join()
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
本专栏是一份全面的指南,旨在帮助开发者优化 Python 代码的性能。它涵盖了各种优化技术,从代码结构的改进到内存管理的优化。专栏中包含的文章深入探讨了 Python 代码的常见性能问题,并提供了实用的解决方案。此外,它还介绍了并发编程、数据库连接池、异常处理和单元测试等高级主题,帮助开发者提升代码的效率、健壮性和可维护性。通过遵循本专栏中的建议,开发者可以显著提高 Python 代码的性能,使其运行得更快、更有效率。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
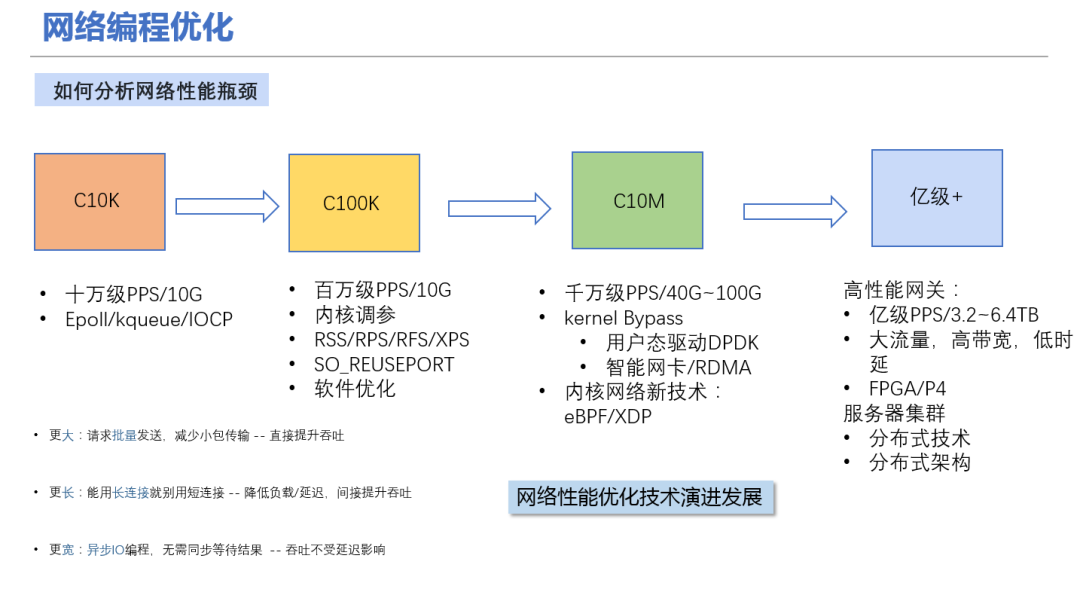
【实战演练】python云数据库部署:从选择到实施
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】通过强化学习优化能源管理系统实战
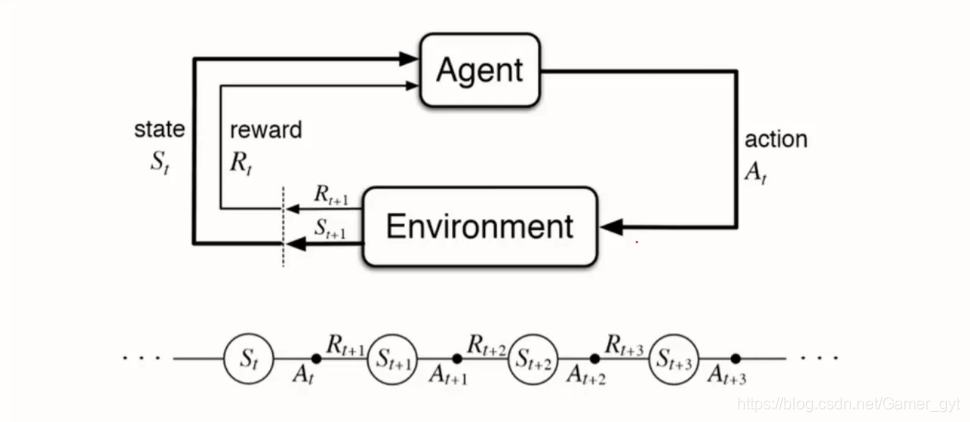
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】使用Docker与Kubernetes进行容器化管理
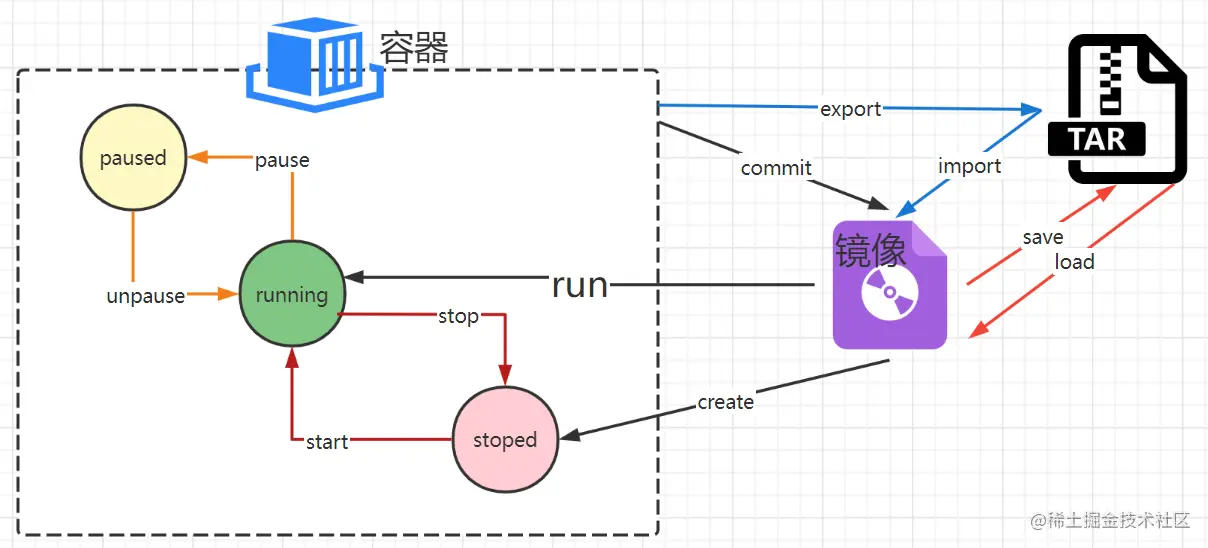
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】python远程工具包paramiko使用
# 1. Python远程工具包Paramiko简介**
Paramiko是一个用于Python的SSH2协议的库,它提供了对远程服务器的连接、命令执行和文件传输等功能。Paramiko可以广泛应用于自动化任务、系统管理和网络安全等领域。
# 2. Paramiko基础
### 2.1 Paramiko的安装和配置
**安装 Paramiko**
```python
pip install
【实战演练】使用Python和Tweepy开发Twitter自动化机器人

# 1. Twitter自动化机器人概述**
Twitter自动化机器人是一种软件程序,可自动执行在Twitter平台上的任务,例如发布推文、回复提及和关注用户。它们被广泛用于营销、客户服务和研究等各种目的。
自动化机器人可以帮助企业和个人节省时间和精力,同时提高其Twitter活动的效率。它们还可以用于执行复杂的任务,例如分析推文情绪或
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )