关联数组科学研究应用:数据分析、建模和模拟的秘密武器
发布时间: 2024-08-24 08:25:45 阅读量: 33 订阅数: 25 

与上一个博客相关联,所提供的数据

# 1. 关联数组基础理论
关联数组是一种数据结构,它将键映射到值。与普通数组不同,关联数组的键可以是任何类型,而不仅仅是整数。这使得关联数组非常适合存储和检索复杂数据结构,例如对象和哈希表。
关联数组在许多不同的编程语言中实现,并且有许多不同的实现。最常见的实现是哈希表,它使用哈希函数将键映射到值。哈希函数是一个将输入映射到固定大小输出的函数。这使得在关联数组中查找值非常高效,因为哈希函数可以快速计算出键的值。
# 2. 关联数组在数据分析中的实践
关联数组在数据分析领域发挥着至关重要的作用,为数据预处理、特征提取、数据建模和分析提供了强大的工具。
### 2.1 数据预处理和特征提取
#### 2.1.1 数据清洗和转换
数据清洗和转换是数据分析的关键步骤,关联数组可以有效地执行这些任务。
- **清洗:**关联数组可以用来识别和删除缺失值、重复值和异常值。例如,以下代码使用关联数组 `data` 清洗数据:
```python
import numpy as np
data = {'name': ['John', 'Jane', 'Mark', 'Mary'],
'age': [25, 23, 30, 28],
'city': ['New York', 'London', 'Paris', 'Berlin']}
# 查找并删除缺失值
for key in data:
for i in range(len(data[key])):
if data[key][i] == np.nan:
data[key].pop(i)
# 查找并删除重复值
for key in data:
data[key] = list(set(data[key]))
```
- **转换:**关联数组可以将数据转换为不同的格式,以满足分析需求。例如,以下代码使用关联数组 `data` 将数据转换为字典:
```python
data_dict = {}
for key in data:
data_dict[key] = dict(zip(data['name'], data[key]))
```
#### 2.1.2 特征选择和降维
特征选择和降维是减少数据复杂性并提高分析效率的重要技术。关联数组可以用于这些任务:
- **特征选择:**关联数组可以根据与目标变量的相关性对特征进行排序,从而识别出最重要的特征。例如,以下代码使用关联数组 `data` 根据与 `age` 的相关性对 `name` 和 `city` 特征进行排序:
```python
import pandas as pd
data = pd.DataFrame(data)
corr = data.corr()
corr.sort_values('age', ascending=False, inplace=True)
```
- **降维:**关联数组可以用于执行主成分分析 (PCA) 和奇异值分解 (SVD) 等降维技术。例如,以下代码使用关联数组 `data` 执行 PCA:
```python
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
data_pca = pca.fit_transform(data)
```
### 2.2 数据建模和分析
#### 2.2.1 关联规则挖掘
关联规则挖掘是一种发现数据集中频繁模式的技术。关联数组可以有效地执行关联规则挖掘。
- **Apriori 算法:**Apriori 算法是一种用于关联规则挖掘的经典算法。它使用关联数组来存储候选频繁项集,并通过迭代过程生成关联规则。例如,以下代码使用关联数组 `candidates` 实现 Apriori 算法:
```python
candidates = {}
for item in data:
candidates[item] = 1
while candidates:
new_candidates = {}
for item1 in candidates:
for item2 in candidates:
if item1 != item2 and item1 + item2 not in candidates:
new_candidates[item1 + item2] = 0
candidates = new_candidates
```
#### 2.2.2 聚类分析
聚类分析是一种将数据点分组到不同簇的技术。关联数组可以用于聚类分析。
- **K-Means 算法:**K-Means 算法是一种用于聚类分析的流行算法。它使用关联数组来存储聚类中心,并通过迭代过程将数据点分配到聚类中。例如,以下代码使用关联数组 `clusters` 实现 K-Means 算法:
```python
import numpy as np
clusters = {}
for i in range(k):
clusters[i] = []
for data_point in data:
distances = []
for cluster in clusters:
distances.append(np.linalg.norm(data_point - clusters[cluster]))
cluster_index = np.argmin(distances)
clusters[cluster_index].append(data_point)
```
#### 2.2.3 分类和回归
分类和回归是预测建模的两种主要技术。关联数组可以用于分类和回归。
- **逻辑回归:**逻辑回归是一种用于二分类的分类算法。它使用关联数组来存储模型参数,并通过最大似然估计进行训练。例如,以下代码使用关联数组 `params` 实现逻辑回归:
```python
import numpy as np
params = {'w': np.zeros(data.shape[1]), 'b': 0}
for epoch in range(max_epochs):
for data_point, label in zip(data, labels):
y_pred = 1 / (1 + np.exp(-(np.dot(params['w'], data_point) + params['b'])))
params['w'] += learning_rate * (label - y_pred) * data_point
params['b'] += learning_rate * (label - y_pred)
```
- **线性回归:**线性回归是一种用于回归分析的回归算法。它使用关联数组来存储模型参数,并通过最小二乘法进行训练。例如,以下代码使用关联数组 `params` 实现线性回归:
```python
import numpy as np
params = {'w': np.zeros(data.shape[1]), 'b': 0}
for epoch in range(max_epochs):
for data_point, label in zip(data, labels):
y_pred = np.dot(params['w'], data_point) + params['b']
params['w'] += learning_rate * (label - y_pred) * data_point
params['b'] += learning_rate * (label - y_pred)
```
# 3.1 物理建模和仿真
关联数组在物理建模和仿真中扮演着至关重要的角色,使研究人员能够创建逼真的模型来模拟物理现象。
#### 3.1.1 粒子系统模拟
粒子系统模拟涉及到大量粒子在力场作用下的运动。关联数组用于存储每个粒子的位置、速度和加速度等属性。通过更新这些属性,模拟器可以计算粒子的运动轨迹,从而创建逼真的流体、烟雾和灰尘等效果。
```python
import numpy as np
# 创建一个粒子系统
particles = np.empty((1000, 3)) # 粒子位置 (x, y, z)
# 初始化粒子属性
particles[:, 0] = np.random.uniform(-1, 1, 1000) # x 坐标
particles[:, 1] = np.random.uniform(-1, 1, 1000) # y 坐标
particles[:, 2] = np.random.uniform(-1, 1, 1000) # z 坐标
# 设置重力加速度
g = np.array([0, -9.81, 0])
# 模拟时间步长
dt = 0.01
# 循环更新粒子属性
for i in range(1000):
# 计算粒子加速度
a = g
# 更新粒子速度
particles[:, 0] += particles[:, 1] * dt
particles[:, 1] += particles[:, 2] * dt
particles[:, 2] += a[2] * dt
# 更新粒子位置
particles[:, 0] += particles[:, 1] * dt
particles[:, 1] += particles[:, 2] * dt
particles[:, 2] += a[2] * dt
```
#### 3.1.2 流体动力学建模
流体动力学建模涉及到模拟流体(如液体或气体)的流动。关联数组用于存储流体网格中每个网格单元的属性,如速度、压力和密度。通过求解流体动力学方程,模拟器可以计算流体的运动和相互作用。
```python
import numpy as np
# 创建流体网格
grid = np.empty((100, 100, 3)) # 网格单元速度 (u, v, w)
# 初始化流体属性
grid[:, :, 0] = np.zeros((100, 100)) # x 方向速度
grid[:, :, 1] = np.zeros((100, 100)) # y 方向速度
grid[:, :, 2] = np.zeros((100, 100)) # z 方向速度
# 设置边界条件
grid[0, :, :] = np.array([1, 0, 0]) # 左边界速度
grid[-1, :, :] = np.array([-1, 0, 0]) # 右边界速度
grid[:, 0, :] = np.array([0, 1, 0]) # 底边界速度
grid[:, -1, :] = np.array([0, -1, 0]) # 顶边界速度
# 模拟时间步长
dt = 0.01
# 循环更新流体属性
for i in range(1000):
# 求解流体动力学方程
# ...
# 更新流体速度
grid[:, :, 0] += grid[:, :, 1] * dt
grid[:, :, 1] += grid[:, :, 2] * dt
grid[:, :, 2] += grid[:, :, 3] * dt
```
# 4.1 计算机图形学和动画
关联数组在计算机图形学和动画领域扮演着至关重要的角色,为逼真的场景创建、流畅的动画和交互式体验提供了基础。
### 4.1.1 场景建模和渲染
在场景建模中,关联数组用于存储场景中的对象及其属性,例如位置、旋转、缩放和材质。通过将对象及其属性存储在关联数组中,可以轻松地管理和操纵场景,并实现复杂的对象层次结构。
在渲染过程中,关联数组用于存储光源、纹理和着色器等渲染参数。通过调整这些参数,可以控制场景的照明、纹理和表面特性,从而生成逼真的图像。
```python
# 场景建模
objects = {
"cube": {
"position": [0, 0, 0],
"rotation": [0, 0, 0],
"scale": [1, 1, 1],
"material": "wood"
},
"sphere": {
"position": [1, 0, 0],
"rotation": [0, 0, 0],
"scale": [1, 1, 1],
"material": "metal"
}
}
# 渲染
lights = {
"light1": {
"position": [0, 10, 0],
"color": [1, 1, 1]
},
"light2": {
"position": [10, 0, 0],
"color": [1, 1, 1]
}
}
textures = {
"wood": {
"image": "wood.png",
"wrap": "repeat"
},
"metal": {
"image": "metal.png",
"wrap": "clamp"
}
}
shaders = {
"phong": {
"vertex_shader": "phong.vert",
"fragment_shader": "phong.frag"
}
}
```
### 4.1.2 物理引擎和碰撞检测
在物理引擎中,关联数组用于存储物理对象及其属性,例如质量、速度、加速度和碰撞体积。通过将对象及其属性存储在关联数组中,可以模拟对象的物理行为,并实现逼真的碰撞检测和交互。
在碰撞检测中,关联数组用于存储碰撞体积的边界和法线。通过比较碰撞体积的边界,可以快速检测对象之间的碰撞,并计算碰撞点和碰撞力。
```python
# 物理引擎
objects = {
"cube": {
"mass": 1,
"velocity": [0, 0, 0],
"acceleration": [0, -9.8, 0],
"collision_volume": "cube"
},
"sphere": {
"mass": 1,
"velocity": [0, 0, 0],
"acceleration": [0, -9.8, 0],
"collision_volume": "sphere"
}
}
# 碰撞检测
collision_volumes = {
"cube": {
"bounds": [[-1, -1, -1], [1, 1, 1]],
"normals": [[1, 0, 0], [0, 1, 0], [0, 0, 1]]
},
"sphere": {
"bounds": [[-1, -1, -1], [1, 1, 1]],
"normals": [[1, 0, 0], [0, 1, 0], [0, 0, 1]]
}
}
```
# 5.1 生物信息学和基因组学
### 5.1.1 基因组序列分析
关联数组在基因组序列分析中扮演着至关重要的角色。基因组是生物体所有遗传信息的集合,由数百万个碱基对组成。为了理解基因组的功能,研究人员需要分析这些序列并识别模式和突变。
关联数组提供了高效存储和检索基因组数据的结构。例如,一个关联数组可以将每个碱基对映射到其位置。这使得研究人员能够快速定位特定序列,进行比较并识别突变。
此外,关联数组还用于构建基因组索引。索引是预先计算的数据结构,可以加快对基因组数据的查询。通过使用关联数组,研究人员可以创建高效的索引,允许他们快速搜索基因组中的特定序列或模式。
### 5.1.2 蛋白质结构预测
蛋白质是执行生物体功能的基本分子。蛋白质的结构决定了其功能,因此预测蛋白质结构对于理解其作用至关重要。
关联数组在蛋白质结构预测中被用来存储和检索原子坐标。蛋白质结构可以通过X射线晶体学或核磁共振(NMR)光谱学等技术确定。这些技术产生大量原子坐标数据,需要有效地存储和处理。
关联数组提供了高效存储和检索原子坐标的结构。通过使用关联数组,研究人员可以快速定位特定原子,计算距离和角度,并可视化蛋白质结构。
此外,关联数组还用于构建蛋白质结构数据库。这些数据库存储了大量已知蛋白质结构,研究人员可以用来比较新预测的结构或进行其他分析。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《关联数组的实现与应用实战》专栏深入探讨了关联数组的数据结构、性能、应用和算法,涵盖了编程语言、数据结构、数据库优化、Web 开发、机器学习、分布式系统、移动开发、云计算、游戏开发、金融科技、医疗保健、制造业、教育、科学研究、社交媒体、电子商务、物联网和人工智能等领域。专栏通过揭秘关联数组的底层秘密、比较不同语言的实现、提供应用秘籍、介绍算法利器、优化数据库查询、提升Web开发效率、赋能机器学习、解决分布式系统问题、简化移动开发、构建云计算基础、增强游戏开发体验、助力金融科技创新、优化医疗保健应用、提升制造业效率、管理教育数据、推动科学研究、构建社交媒体应用、促进电子商务发展、连接物联网设备、推动人工智能进步等内容,全面展示了关联数组在各个领域的应用价值。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PPPoE会话管理详解:会话建立、维护与终止策略

# 摘要
PPPoE(Point-to-Point Protocol over Ethernet)是一种广泛使用的网络协议,用于实现宽带网络上的点对点连接。本文从PPPoE协议的基础知识和应用场景入手,详细探讨了PPPoE会话的建立、维护、终止过程及其相关技术细节。文章分析了PPPoE会话建立过程中的封装机制、认证协议和常见问题解决策略。在会话维护方面,本文讨论了Keepalive消息处理、QoS配置和网络管理
【故障速查】:爱普生打印机ESC指令错误快速诊断与解决方案

# 摘要
本论文对打印机中ESC指令错误的诊断和解决方法进行了系统性研究。文章首先介绍了故障速查的概览和打印机的基础知识,然后深入探讨了ESC指令错误的基本原理与分类,包括硬件、软件和环境因素导致的错误。接着,本论文提供了详细的ESC指令错误诊断流程,包括诊断前的准备、诊断工具与方法,以及错误代码的解读与分析。第四章针对常见ESC指令错误提供了硬件、软件和环境因素导致问题的解决方法。最后,第五章提出了一系列预防措施与维护建议,旨在帮助用户
【思科NVRAM与IOS备份的终极解密】:备份模式的秘密一览无余

# 摘要
本文旨在系统介绍思科网络设备的NVRAM与IOS备份机制,提供了关于NVRAM作用与功能的深入理解,并探讨了IOS操作系统备份的重要性及其基本原理。文章详细阐述了备份模式与方法论,包括不同备份模式的对比、选择及备份方法的实施步骤。通过实践操作章节,本文详解了NVRAM配置文件和IOS映像文件的备份与恢复流程,并提供了处理备份过程中常见问题的
君正T40EVB原理图案例全解析:解决实际开发难题的秘诀
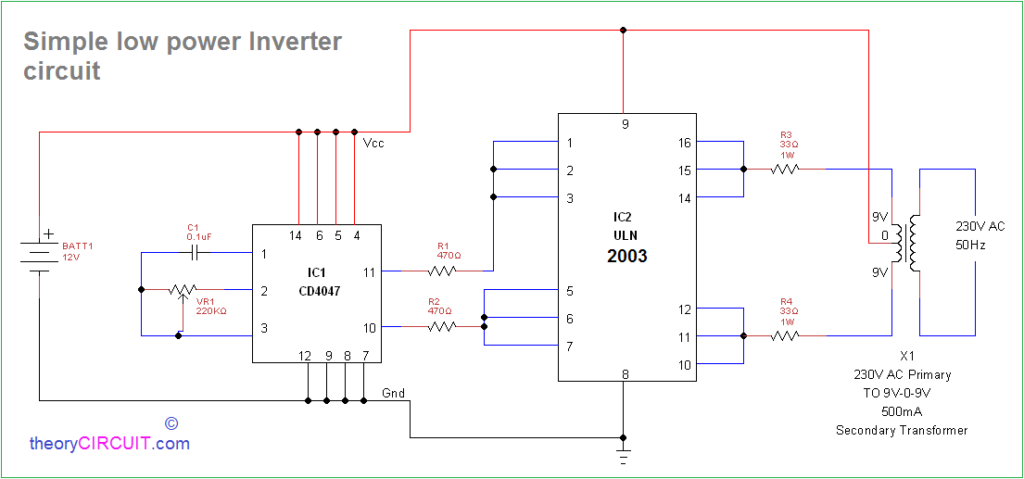
# 摘要
本文全面介绍了君正T40EVB的硬件原理、开发环境搭建、软件开发实践以及性能优化和问题诊断方法。首先概述了君正T40EVB的硬件架构,包括核心组件、电源管理和信号路径。接着详细阐述了软件开发环境的配置、操作系统移植以及应用层开发的关键技术。之后,文章探讨了性能优化与问题诊断的技术,包括性能监控、调试技巧和案例研究。最后,
AP6256与物联网的完美结合:智能设备集成与性能优化技巧

# 摘要
AP6256芯片作为一款专为物联网设计的解决方案,具备先进的硬件架构、无线连接能力和软件集成特性。本文详细介绍了AP6256芯片的技术规格、软件集成以及网络协议支持,进而探讨了在智能设备中集成AP6256芯片的实践,并提出了性能优化和功耗管理的技巧。此外,文章重点分析了物联网设备面临的安全与隐私保护挑战,并探讨了相应的加密技术和隐私保护策略。案例研究展示了AP6256
深入剖析SystemView:揭秘监控工具的8个定制化数据追踪秘诀
# 摘要
SystemView监控工具是一种先进的系统监控解决方案,它提供了定制化数据追踪的功能,帮助用户深入理解系统行为和性能调优。本文首先概述了SystemView的基础知识和重要性,接着深入探讨了定制化数据追踪的理论基础、高级配置技巧和实际应用案例分析。本文详细阐述了
Java 8特性深度解析:IKM测试题中的新特性应用
# 摘要
本文旨在详细探讨Java 8引入的新特性及其在现代应用开发中的应用。首先概述了Java 8的更新亮点,随后深入分析了函数式编程的核心概念,包括Lambda表达式和Stream API的语法结构与使用场景,以及函数式接口的定义与实例应用。文章还探讨了Java 8在时间日期API方面的更新,包括LocalDate、LocalTime、Duration、Period以及新的日期时间格式化工具。此外,本文研究了Ja
【遵循ISO 15288标准的系统集成】:测试流程与质量保障策略
# 摘要
本文详细介绍了ISO 15288标准在系统集成中的应用,特别强调了测试流程和质量保障策略的重要性。通过阐述ISO 15288标准的理论框架和实践应用,本文分析了测试用例的编写、测试活动的组织、以及测试结果的分析与记录。同时,本文也探讨了质量保障的理论基础、实施技术和持续改进方法,并提供了基于ISO 15288标准的实际项目案例分析,包括项目选定、测试流程应用、遇
【ParaView入门速成课】:5步带你从新手到数据可视化专家
# 摘要
本文旨在为读者提供一个全面了解ParaView工具的指南,从基本概念到高级功能,再到实际应用案例。首先介绍了ParaView的基本概念和安装流程,随后解释了数据可视化的基础知识,并深入探讨了ParaView中的数据模型、用户界面布局。重点章节详细说明了如何通过ParaView进行数据的导入、管理和可视化效果的创建。接着,文章探索了ParaView的高级功能,包括时间序
驱动开发新手起步:全志Tina Linux入门指南

# 摘要
本文旨在深入介绍全志Tina Linux操作系统的基础操作、命令使用、驱动开发以及实践应用。首先,对全志Tina Linux进行简介,并详细说明了开发环境的搭建过程。接着,探讨了Linux系统的基本操作、软件安装与管理以及内核与设备驱动基础概念。之后,针对驱动开
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )