数据库嵌套JSON查询优化:掌握优化查询性能的秘诀,提升数据查询效率
发布时间: 2024-07-29 14:34:09 阅读量: 44 订阅数: 42 

数据库的查询优化
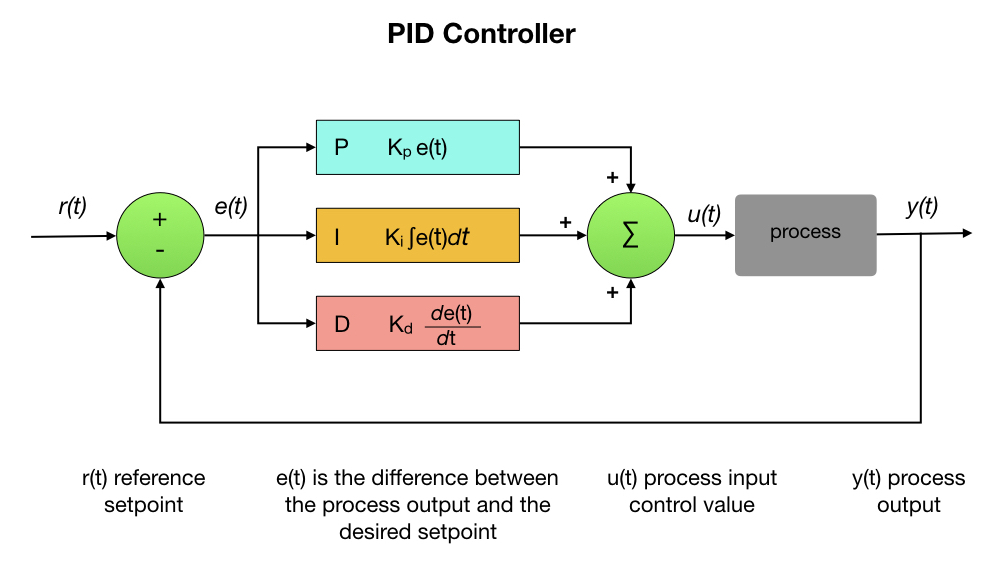
# 1. 数据库嵌套JSON查询简介**
嵌套JSON查询是一种强大的技术,用于从数据库中提取和分析复杂嵌套的JSON数据。它允许开发人员从嵌套结构中提取特定信息,从而简化数据处理并提高查询效率。
嵌套JSON查询通常使用点表示法(`.`)来遍历JSON文档的层次结构。例如,要从嵌套JSON文档中提取名为“name”的字段,可以使用以下查询:
```sql
SELECT json_value(data, '$.name')
FROM table_name;
```
# 2. 嵌套JSON查询的优化技巧
### 2.1 索引优化
#### 2.1.1 创建适当的索引
在嵌套JSON数据中创建适当的索引可以显著提高查询性能。索引是数据库中的一种数据结构,它允许数据库快速查找特定值。对于嵌套JSON数据,可以使用以下类型的索引:
- **复合索引:**复合索引是在多个字段上创建的索引。对于嵌套JSON数据,可以使用复合索引来索引嵌套字段。例如,如果有一个名为 `address` 的嵌套字段,其中包含 `street` 和 `city` 字段,则可以创建复合索引 `address.street, address.city`。
- **稀疏索引:**稀疏索引只为包含特定值的行创建索引条目。对于嵌套JSON数据,可以使用稀疏索引来索引可能仅存在于少数行中的嵌套字段。例如,如果有一个名为 `metadata` 的嵌套字段,其中包含 `tags` 字段,则可以创建稀疏索引 `metadata.tags`。
**代码块:**
```sql
CREATE INDEX idx_address ON table_name(address.street, address.city);
CREATE INDEX idx_metadata_tags ON table_name(metadata.tags) SPARSE;
```
**逻辑分析:**
这些索引将允许数据库快速查找特定值,而无需扫描整个表。
#### 2.1.2 避免不必要的索引
虽然索引可以提高查询性能,但创建不必要的索引可能会降低性能。不必要的索引会增加数据库的维护开销,并可能导致查询计划不佳。以下是一些避免不必要的索引的准则:
- **仅索引经常查询的字段:**只为经常查询的字段创建索引。避免为很少查询的字段创建索引。
- **避免索引大字段:**避免为大字段创建索引。大字段索引可能占用大量空间,并且可能导致查询性能下降。
- **避免索引重复字段:**避免为重复字段创建索引。重复字段索引可能导致查询计划不佳。
### 2.2 查询优化
#### 2.2.1 使用适当的查询语句
使用适当的查询语句可以显著提高嵌套JSON查询的性能。以下是一些使用适当查询语句的准则:
- **使用适当的运算符:**使用适当的运算符来过滤和查询嵌套JSON数据。例如,使用 `$elemMatch` 运算符来匹配数组中的元素,使用 `$exists` 运算符来检查字段是否存在。
- **使用投影:**使用投影来限制查询返回的字段。只返回必要的字段,可以减少网络流量和数据库负载。
- **使用限制:**使用限制来限制查询返回的行数。这可以防止查询返回大量不必要的数据。
**代码块:**
```sql
SELECT address.street, address.city
FROM table_name
WHERE address.street = 'Main Street';
SELECT metadata.tags
FROM table_name
WHERE metadata.tags EXISTS;
SELECT *
FROM table_name
LIMIT 10;
```
**逻辑分析:**
这些查询语句使用适当的运算符、投影和限制来优化性能。
#### 2.2.2 避免不必要的子查询
不必要的子查询可能会降低嵌套JSON查询的性能。子查询是嵌套在另一个查询中的查询。以下是一些避免不必要的子查询的准则:
- **使用连接:**使用连接来连接表,而不是使用子查询。连接通常比子查询更有效。
- **使用派生表:**使用派生表来存储子查询的结果。这可以防止子查询多次执行。
- **使用 CTE:**使用公共表表达式 (CTE) 来存储子查询的结果。CTE 与派生表类似,但语法更简洁。
**代码块:**
```sql
SELECT *
FROM table_name
JOIN subquery_table ON table_name.id = subquery_table.id;
WITH subquery AS (
SELECT id, name FROM subquery_table
)
SELECT *
FROM table_name
JOIN subquery ON table_name.id = subquery.id;
```
**逻辑分析:**
这些查询使用连接和 CTE 来避免不必要的子查询。
# 3. 嵌套JSON查询的实践应用
### 3.1 数据分析
#### 3.1.1 提取嵌套JSON数据中的关键信息
嵌套JSON数据中可能包含大量关键信息,需要将其提取出来进行分析。可以使用JSON解析器或查询语言(如SQL)来提取特定字段或值。
```sql
SELECT value
FROM json_table(json_column, '$[*]')
WHERE key = 'name';
```
**代码逻辑分析:**
* `json_table` 函数将 JSON 列转换为表格式,其中每一行代表一个 JSON 对象。
* `$[*]` 通配符匹配所有 JSON 对象中的所有键。
* `WHERE` 子句过滤出具有特定键(例如 `name`)的行。
#### 3.1.2 聚合和分析嵌套JSON数据
嵌套JSON数据可以进行聚合和分析,以获取有意义的见解。可以使用聚合函数(如 `SUM`、`COUNT`)对嵌套字段进行计算。
```sql
SELECT SUM(value)
FROM json_table(json_column, '$[*]')
WHERE key = 'price';
```
**代码逻辑分析:**
* `SUM` 函数对具有特定键(例如 `price`)的字段进行求和。
* `WHERE` 子句过滤出具有特定键的行。
### 3.2 数据管理
#### 3.2.1 更新和删除嵌套JSON数据
嵌套JSON数据可以进行更新和删除操作。可以使用 `JSON_SET` 和 `JSON_REMOVE` 函数来修改 JSON 值。
```sql
UPDATE table_name
SET json_column = JSON_SET(json_column, '$.name', 'New Name')
WHERE id = 1;
```
**代码逻辑分析:**
* `JSON_SET` 函数将 JSON 列中的 `name` 键的值更新为 `New Name`。
* `WHERE` 子句指定要更新的行。
#### 3.2.2 插入和合并嵌套JSON数据
可以将新的嵌套JSON数据插入到现有表中,也可以将其与现有数据合并。可以使用 `JSON_INSERT` 和 `JSON_MERGE` 函数来实现此目的。
```sql
INSERT INTO table_name (json_column)
VALUES (JSON_INSERT(DEFAULT, '$.name', 'New Name'));
```
**代码逻辑分析:**
* `JSON_INSERT` 函数创建一个新的 JSON 对象,并将 `name` 键的值设置为 `New Name`。
* `DEFAULT` 关键字用于插入其他字段的默认值。
# 4.1 分片和并行查询
### 4.1.1 分片大数据集
当处理大数据集时,将数据集分片可以显著提高查询性能。分片涉及将数据集拆分为更小的、可管理的块,每个块存储在不同的服务器或节点上。
```
# 分片数据集的示例代码
import pymongo
# 连接到 MongoDB 数据库
client = pymongo.MongoClient("mongodb://localhost:27017")
# 获取要分片的数据集
collection = client.test.collection
# 定义分片键
shard_key = pymongo.HASHED
# 分片数据集
collection.create_index(shard_key, background=True)
```
### 4.1.2 并行执行查询
并行执行查询可以进一步提高性能,尤其是对于复杂查询。并行查询涉及将查询拆分为多个子查询,并在不同的服务器或节点上同时执行这些子查询。
```
# 并行执行查询的示例代码
import pymongo
# 连接到 MongoDB 数据库
client = pymongo.MongoClient("mongodb://localhost:27017")
# 获取要并行执行的查询
query = {"field": {"$gt": 10}}
# 并行执行查询
cursor = collection.find(query, max_time_ms=30000)
# 迭代查询结果
for document in cursor:
print(document)
```
# 5. 嵌套JSON查询的性能监控和故障排除
### 5.1 性能监控
**5.1.1 识别查询瓶颈**
* **使用查询分析器:**如MongoDB的explain()或MySQL的EXPLAIN,分析查询执行计划,识别消耗大量资源的查询操作。
* **查看系统指标:**监控CPU、内存和I/O利用率,识别查询执行期间的资源争用。
* **使用性能分析工具:**如New Relic或AppDynamics,获取有关查询执行时间、资源消耗和数据库操作的详细信息。
**5.1.2 跟踪查询执行时间**
* **使用日志记录:**在数据库配置中启用查询日志记录,记录每个查询的执行时间和相关信息。
* **使用性能分析工具:**跟踪查询执行时间,并生成查询执行时间分布图,识别执行时间异常的查询。
* **使用数据库监控系统:**监控数据库查询执行时间,并设置阈值以触发警报,当查询执行时间超过阈值时。
### 5.2 故障排除
**5.2.1 分析查询错误**
* **检查语法错误:**确保查询语法正确,没有语法错误或拼写错误。
* **查看错误消息:**数据库错误消息通常包含有关错误原因的信息,仔细阅读错误消息并尝试理解根本原因。
* **使用调试工具:**如MongoDB的db.printCollectionStats()或MySQL的SHOW PROCESSLIST,获取有关查询执行的详细信息,帮助诊断错误。
**5.2.2 解决查询性能问题**
* **优化索引:**创建适当的索引,以提高查询性能。
* **优化查询:**使用适当的查询语句,避免不必要的子查询和复杂连接。
* **调整数据结构:**规范化数据结构,避免冗余数据,以减少查询复杂度。
* **分片和并行查询:**对于大数据集,考虑分片和并行查询,以提高查询吞吐量。
* **缓存和预计算:**缓存查询结果或预计算中间结果,以减少查询执行时间。
# 6. 嵌套JSON查询的最佳实践和未来趋势**
**6.1 最佳实践**
* **遵循索引和查询优化准则:**使用适当的索引,避免不必要的索引,并使用适当的查询语句和避免不必要的子查询。
* **考虑数据结构和查询复杂度:**规范化数据结构,避免冗余数据,并考虑查询的复杂度和数据大小。
**6.2 未来趋势**
* **新型数据库引擎和查询优化器:**新一代数据库引擎和查询优化器不断涌现,提供更好的嵌套JSON查询性能。
* **云计算和分布式查询:**云计算平台和分布式查询技术使大规模嵌套JSON查询成为可能,提高了可扩展性和性能。
**示例代码:**
```sql
-- 创建适当的索引
CREATE INDEX idx_json_path ON table_name(json_column->>'$.path');
-- 使用适当的查询语句
SELECT json_column->>'$.name' FROM table_name WHERE json_column->>'$.type' = 'user';
-- 避免不必要的子查询
SELECT json_column->>'$.name' FROM table_name WHERE json_column->>'$.type' IN ('user', 'admin');
```
**参数说明:**
* `table_name`:要查询的表名
* `json_column`:包含嵌套JSON数据的列名
* `$.path`:要查询的JSON路径
* `$.name`:要提取的JSON属性名称
* `$.type`:要过滤的JSON属性值
**代码解释:**
* 第一行代码创建了一个索引,以优化对 `json_column` 列中 `$.path` JSON路径的查询。
* 第二行代码使用适当的查询语句来提取 `$.name` 属性的值,并过滤 `$.type` 属性值为 `user` 的行。
* 第三行代码通过使用 `IN` 操作符避免不必要的子查询,提高查询性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探究数据库中嵌套 JSON 数据的奥秘,涵盖从数据结构和查询技巧到性能优化和数据安全等各个方面。它提供了一系列全面的文章,包括:
* 揭秘嵌套 JSON 数据的奥秘,深入理解其数据结构和查询技巧。
* 优化嵌套 JSON 数据建模,探讨数据结构和关系优化,提升数据存储和查询效率。
* 掌握嵌套 JSON 数据查询优化,优化查询性能,提升数据查询效率。
* 探索 JSON 数据存储与索引策略,优化存储和查询性能,提升数据访问速度。
* 分析嵌套 JSON 数据索引失效原因,并提供解决方案,保障数据查询性能。
* 掌握嵌套 JSON 数据聚合和分组技巧,快速获取数据洞察。
* 理解嵌套 JSON 数据事务处理中的挑战和解决方案,确保数据完整性。
* 探索嵌套 JSON 数据并发控制机制和最佳实践,保障数据并发访问的安全性。
* 制定嵌套 JSON 数据安全策略,防止数据泄露和篡改。
* 了解嵌套 JSON 数据迁移的最佳实践,保障数据完整性和一致性。
* 探索嵌套 JSON 数据分析的可能性,从数据中获取有价值的洞察。
* 提供数据库嵌套 JSON 数据性能调优秘诀,优化数据访问效率。
* 探讨嵌套 JSON 数据可扩展性策略,应对大规模数据增长和高并发挑战。
* 了解嵌套 JSON 数据备份与恢复策略,确保数据安全和灾难恢复。
* 探索嵌套 JSON 数据在 NoSQL 数据库、大数据分析、人工智能、物联网、云计算和分布式系统中的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
DevExpress网格控件高级应用:揭秘自定义行选择行为背后的秘密
# 摘要
DevExpress网格控件作为一款功能强大的用户界面组件,广泛应用于软件开发中以实现复杂的数据展示和用户交互。本文首先概述了DevExpress网格控件的基本概念和定制化理论基础,然后深入探讨了自定义行选择行为的实践技巧,包括行为的编写、数据交互处理和用户体验提升。进一步地,文章通过高级应用案例分析,展示了多选与单选行为的实现、基于上下文的动态行选择以及行选择行为与外部系统集
Qt企业级项目实战秘籍:打造云对象存储浏览器(7步实现高效前端设计)

# 摘要
本文综合探讨了Qt框架在企业级项目中的应用,特别是前端界面设计、云对象存储浏览器功能开发以及性能优化。首先,概述了Qt框架与云对象存储的基本概念,并详细介绍了Qt前端界面设计的基础、响应式设计和高效代码组织。接着,深入到云对象存
【C#编程秘籍】:从入门到精通,彻底掌握C#类库查询手册
# 摘要
C#作为一种流行的编程语言,在开发领域中扮演着重要的角色。本文旨在为读者提供一个全面的C#编程指南,从基础语法到高级特性,再到实际应用和性能优化。首先,文章介绍了C#编程基础和开发环境的搭建,接着深入探讨了C#的核心特性,包括数据类型、控制流、面向对象编程以及异常处理。随后,文章聚焦于高级编程技巧,如泛型编程、LINQ查询、并发编程,以及C#类库在文件操作、网络编程和图形界面编程中的应用。在实战项目开发章节中,文章着重讨论了需求分析、编码实践、调试、测试和部署的全流程。最后,文章讨论了性能优化和最佳实践,强调了性能分析工具的使用和编程规范的重要性,并展望了C#语言的新技术趋势。
#
VisionMasterV3.0.0故障快速诊断手册:一步到位解决常见问题

# 摘要
本文作为VisionMasterV3.0.0的故障快速诊断手册,详细介绍了故障诊断的理论基础、实践方法以及诊断工具和技术。首先概述了故障的基本原理和系统架构的相关性,随后深入探讨了故障模式与影响分析(FMEA),并提供了实际的案例研究。在诊断实践部分,本文涵盖了日志分析、性能监控、故障预防策略,以及常见故障场景的模拟和恢复流程。此外
【WebSphere中间件深入解析】:架构原理与高级特性的权威指南
# 摘要
本文全面探讨了WebSphere中间件的架构原理、高级特性和企业级应用实践。首先,文章概述了WebSphere的基本概念和核心组件,随后深入分析了事务处理、并发管理以及消息传递与服务集成的关键机制。在高级特性方面,着重讨论了集群、负载均衡、安全性和性能监控等方面的策略与技术实践
【组合逻辑电路故障快速诊断】:5大方法彻底解决

# 摘要
组合逻辑电路故障诊断是确保电路正常工作的关键步骤,涉及理论基础、故障类型识别、逻辑分析技术、自动化工具和智能诊断系统的应用。本文综合介绍了组合逻辑电路的工作原理、故障诊断的初步方法和基于逻辑分析的故障诊断技术,并探讨了自动化故障诊断工具与方法的重要性。通过对真实案例的分析,本文旨在展示故障诊断的实践应用,并提出针对性的挑战解决方案,以提高故障诊断的效率和准确性。
# 关键字
组合逻辑电路;故障诊断;逻辑分析器;真值表;自
饼图深度解读:PyEcharts如何让数据比较变得直观

# 摘要
本文主要介绍了PyEcharts的使用方法和高级功能,重点讲解了基础饼图的绘制和定制、复杂数据的可视化处理,以及如何将PyEcharts集成到Web应用中。文章首先对PyEcharts进行了简要介绍,并指导读者进行安装。接下来,详细阐述了如何通过定制元素构
【继电器可靠性提升攻略】:电路稳定性关键因素与维护技巧

# 摘要
继电器作为一种重要的电路元件,在电气系统中起着至关重要的作用。本文首先探讨了继电器的工作原理及其在电路中的重要性,随后深入分析了影响继电器可靠性的因素,包括设计、材料选择和环境条件。接着,文章提供了提升继电器可靠性的多种理论方法和实践应用测试,包括选择指南、性能测试和故障诊断技术。第四章专注于继电器的维护和可靠性提
【数据预处理进阶】:RapidMiner中的数据转换与规范化技巧全解析

# 摘要
数据预处理是数据挖掘和机器学习中的关键步骤,尤其在使用RapidMiner这类数据分析工具时尤为重要。本文详细探讨了Rapid
【单片机温度计数据采集与处理】:深度解析技术难题及实用技巧

# 摘要
本文系统地探讨了基于单片机的温度测量系统的设计、实现及其高级编程技巧。从温度传感器的选择、数据采集电路的搭建、数据处理与显示技术,到编程高级技巧、系统测试与优化,本文对相关技术进行了深入解析。重点论述了在温度数据采集过程中,如何通过优化传感器接口、编程和数据处理算法来提高温度计的测量精度和系统稳定性。最后,通过对实际案例的分析,探讨了多功能拓展应用及技术创新的潜力,为未来温度测量技术的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )