SQL Server 2005数据库事务管理:确保数据一致性和完整性的关键策略
发布时间: 2024-07-24 14:08:07 阅读量: 28 订阅数: 32 
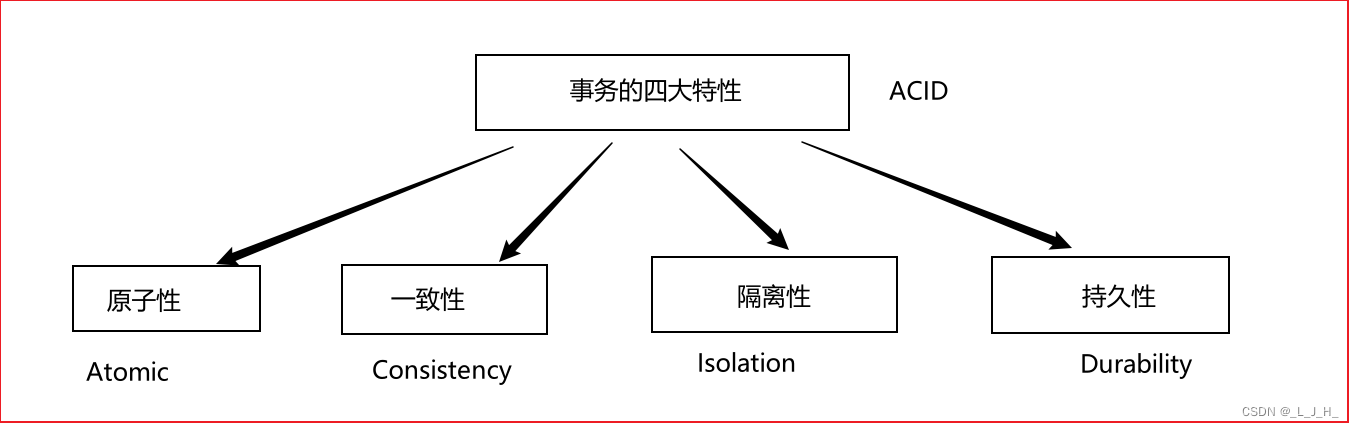
# 1. SQL Server 2005数据库事务简介**
事务是数据库中的一组操作,这些操作要么全部成功,要么全部失败。事务保证了数据库数据的完整性和一致性。在SQL Server 2005中,事务通过BEGIN TRANSACTION和COMMIT TRANSACTION语句开始和结束。
事务具有ACID特性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。原子性保证事务中的所有操作要么全部执行,要么全部回滚;一致性保证事务执行后数据库的状态仍然是有效的;隔离性保证事务在执行过程中不受其他事务的影响;持久性保证事务提交后对数据库的更改是永久性的。
# 2. 事务的理论基础
### 2.1 事务的定义和特性
**2.1.1 ACID原则**
事务是数据库操作的一个逻辑单元,它满足ACID原则:
- **原子性(Atomicity):**事务中的所有操作要么全部成功,要么全部失败,不会出现部分成功的情况。
- **一致性(Consistency):**事务执行前后的数据库状态都满足业务规则和约束条件。
- **隔离性(Isolation):**并发执行的事务彼此独立,不受其他事务的影响。
- **持久性(Durability):**一旦事务提交,其对数据库所做的更改将永久保存,即使系统发生故障。
### 2.1.2 隔离级别
隔离级别控制着并发事务之间的可见性,有以下几种级别:
| 隔离级别 | 描述 |
|---|---|
| **未提交读(Read Uncommitted)** | 事务可以读取其他未提交事务的修改。 |
| **已提交读(Read Committed)** | 事务只能读取已提交事务的修改。 |
| **可重复读(Repeatable Read)** | 事务可以读取事务开始时数据库的状态,并且在事务期间不会被其他事务修改。 |
| **串行化(Serializable)** | 事务按照顺序执行,完全隔离。 |
### 2.2 事务的并发控制
并发控制机制确保并发执行的事务不会相互干扰。
### 2.2.1 锁机制
锁机制通过对数据库对象(如表、行)加锁,防止其他事务同时访问或修改这些对象。锁的类型包括:
- **共享锁(S锁):**允许其他事务读取被锁对象,但不能修改。
- **排他锁(X锁):**允许事务独占访问被锁对象,其他事务不能读取或修改。
### 2.2.2 死锁处理
当两个或多个事务互相等待对方释放锁时,就会发生死锁。死锁处理机制包括:
- **死锁检测:**检测死锁并将其报告给数据库引擎。
- **死锁超时:**当死锁发生时,等待时间最长的事务被回滚。
- **死锁预防:**通过强制事务按照一定的顺序访问对象来防止死锁。
# 3.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 SQL Server 2005 数据库的各个方面,旨在帮助数据库管理员和开发人员优化数据库性能、解决死锁和表锁问题,并确保数据安全和完整性。专栏涵盖了广泛的主题,包括优化技巧、索引管理、事务管理、日志分析、安全配置、数据库设计最佳实践、迁移指南、维护和管理策略、性能监控和分析、连接管理、查询优化、存储过程和函数,以及用户管理。通过提供实用技巧、案例分析和专家建议,本专栏旨在帮助读者充分利用 SQL Server 2005 数据库,提高其性能、可靠性和安全性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
555定时器进阶应用:如何设计并实现稳定的1Hz脉冲源
参考资源链接:[使用555定时器创建1Hz脉冲方波发生器](https://wenku.csdn.net/doc/6401ad28cce7214c316ee808?spm=1055.2635.3001.10343)
# 1. 定时器基础知识与555定时器概述
## 1.1 定时器的作用与分类
定时器是电子电路中的一种常见组件,它的主要功能是控制事件发生的时间间隔。定时器的应用范围非常广泛,从简
Abaqus独家揭秘:重力载荷与温度场耦合的仿真案例
参考资源链接:[Abaqus CAE教程:施加重力载荷步骤详解](https://wenku.csdn.net/doc/2rn8c98egs?spm=1055.2635.3001.10343)
# 1. Abaqus仿真软件与耦合分析简介
在现代工程设计和科研中,仿真分析已成为不可或缺的一环,尤其是对于那些涉及到多个物理场相互作用的复杂系统。Abaqus仿真软件是由Dassault Systèmes公司开发的一款功能强大的有
【调试技巧揭秘】:Star CCM+场函数命令规则的错误诊断与解决方案

参考资源链接:[STAR-CCM+场函数详解与自定义实例](https://wenku.csdn.net/doc/758tv4p6go?spm=1055.2635.3001.10343)
# 1. Star CCM+场函数命令规则概述
## 1.1 Star CCM+场函数命令规则简介
性能提升秘籍:GreenHills编译器性能调优全攻略
参考资源链接:[GreenHills 2017.7 编译器使用手册](https://wenku.csdn.net/doc/6412b714be7fbd1778d49052?spm=1055.2635.3001.10343)
# 1. GreenHills编译器概述
在信息技术飞速发展的今天,编译器作为将源代码转化为机器代码的关键工具,扮演着不可或缺的角色
ICC平台入门必读:7步快速精通操作指南

参考资源链接:[大华ICC平台V1.2.0使用手册:智能物联管理](https://wenku.csdn.net/doc/5b2ai5kr8o?spm=1055.2635.3001.10343)
# 1. ICC平台概述
在数字时代,企业越来越依赖于集成协作平台(ICC)以提高工作效率和团队协作。ICC平台概述为用户提供了对ICC系统全面的理解,包
Ubuntu 20.04显卡驱动兼容性测试:理论与实践的完美结合

参考资源链接:[Ubuntu20.04 NVIDIA 显卡驱动与 CUDA、cudnn 安装指南](https://wenku.csdn.net/doc/3n29mzafk8?spm=1055.2635.3001.10343)
# 1. Ubuntu 20.04显卡驱动概述
## 显卡驱动的重要性
在U
CRSF协议真相大揭秘:走出误区,认识真实面貌

参考资源链接:[CRSF数据协议详解:遥控器与ELRS通信的核心技术](https://wenku.csdn.net/doc/3zeya6e17v?spm=1055.2635.3001.10343)
# 1. CRSF协议概述
跨站请求伪造(Cross-Site Request Forgery,简称CSRF)是一种常见的网络安全威胁,它利用了网站对用户浏览器的信任,诱使用户在不知情的情况下执行非预期的操作。CRSF协
ibaAnalyzer日志管理策略:维护日志秩序与合规性的智慧选择
参考资源链接:[ibaAnalyzer手册(中文).pdf](https://wenku.csdn.net/doc/6401abadcce7214c316e9190?spm=1055.2635.3001.10343)
# 1. ibaAnalyzer日志管理概述
## 1.1 日志管理在IT系统中的作用
日志管理是IT系统运行不可或缺的组成部分,它记录了系统运行的状态和用户行
数控机床编程高级技巧:进阶之路全解析
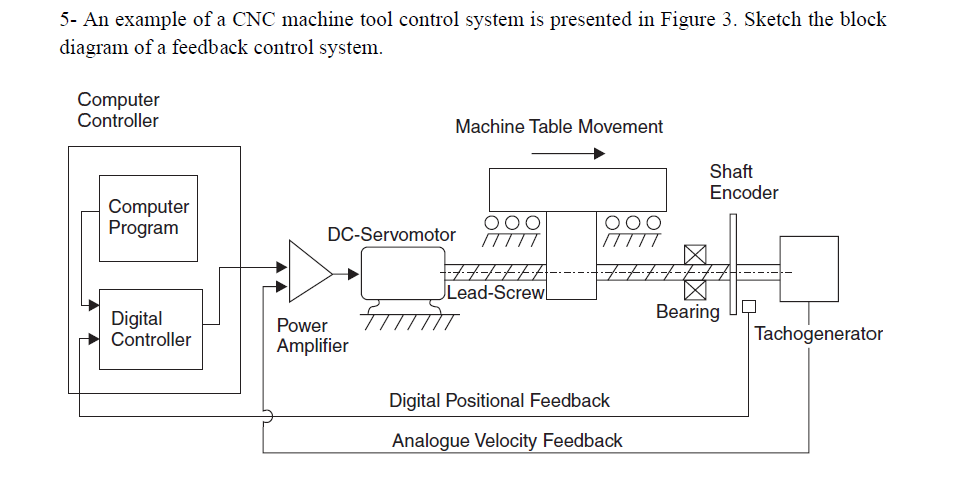
参考资源链接:[宝元数控系统操作与编程手册](https://wenku.csdn.net/doc/52g0s1dmof?spm=1055.2635.3001.10343)
# 1. 数控机床编程概述
数控机床编程是制造业中的核心技术之一,它允许我们通过精确的代码指令控制机床的加工过程。本章将简要介绍数控编程的相关概念和基础知识,为深入学习后续章节打下坚实的基础。
## 1.1 数控编程的含义与重要性
Kraken框架自定义指令与过滤器:提升开发效率的扩展功能(自定义指令与过滤器)

参考资源链接:[KRAKEN程序详解:简正波声场计算与应用](https://wenku.csdn.net/doc/6412b724be7fbd1778d493e3?spm=1055.2635.3001.10343)
# 1. Kraken框架简介与自定义指令与过滤器的概念
## 1.1 Kraken框架简介
Kraken 是一个基于 Node.js 的高效 Web 开发框架,它以灵活和
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )