Kubernetes基础概念与集群部署实践
发布时间: 2024-03-11 01:07:12 阅读量: 37 订阅数: 33 
# 1. Kubernetes基础概念介绍
## 1.1 什么是Kubernetes
Kubernetes是一个开源的容器编排引擎,用于自动化部署、扩展和操作应用程序容器。它消除了在部署、维护和扩展容器化应用程序时可能遇到的许多手动步骤。
Kubernetes的主要特点包括:
- 自动装箱(Automated scheduling):基于容器的应用程序可以在集群中自动化部署和复制。
- 自修复(Self-healing):系统能够自我修复,替换出现故障的容器。
- 水平扩展(Horizontal scaling):基于CPU利用率或应用程序负载对容器进行自动伸缩。
- 服务发现与负载均衡(Service discovery and load balancing):Kubernetes可以自动管理容器的网络,并可选地分发容器的流量。
## 1.2 Kubernetes的核心概念和组件
Kubernetes的核心概念包括:
- Pod:Kubernetes中最小的调度单位,包含一个或多个容器。
- Deployment:用于定义Pod的部署方式和更新策略。
- Service:定义一组Pod的访问方式,提供负载均衡和服务发现。
- Ingress:允许对Kubernetes集群中的服务进行公开访问,支持HTTP和HTTPS路由。
Kubernetes的核心组件包括:
- Kube-apiserver:提供Kubernetes API的访问入口,所有操作都通过API Server暴露出来。
- etcd:分布式键值存储,用于存储Kubernetes集群的状态信息。
- Kube-scheduler:负责Pod的调度,选择合适的节点运行Pod。
- Kube-controller-manager:运行一组控制器,用于集群中的资源控制和管理。
- Kubelet:运行在每个节点上,负责Pod的创建、启动、监控和销毁。
- Kube-proxy:负责为Service提供代理服务,实现负载均衡。
## 1.3 基于容器编排的发展背景
Kubernetes的出现是基于容器编排技术的发展趋势。在Kubernetes出现之前,Docker Swarm和Mesos等已经是容器编排领域的热门选择。但Kubernetes的出现使得容器编排技术更加成熟和强大,成为了目前最受欢迎的容器编排引擎之一。
# 2. Kubernetes集群架构与部署规划
在本章中,我们将深入探讨Kubernetes集群的架构和部署规划。首先,我们将介绍Kubernetes集群的基本架构,包括Master节点和Worker节点的角色与功能。然后,我们将探讨如何选择合适的集群部署方案,以及部署Kubernetes集群的最佳实践。
## 2.1 Kubernetes集群架构介绍
Kubernetes集群由多个节点组成,其中包括Master节点和Worker节点。Master节点负责集群的管理和控制,而Worker节点负责承载应用工作负载。在Master节点中,包括以下几个核心组件:
- **kube-apiserver**:Kubernetes API 服务器,提供对集群的操作和控制接口。
- **etcd**:分布式键值存储,用于保存集群的状态数据和元数据。
- **kube-scheduler**:负责调度应用工作负载到Worker节点上运行。
- **kube-controller-manager**:管理控制器,负责维护集群中各种资源的状态。
在Worker节点中,包括以下核心组件:
- **kubelet**:负责与Master节点通信,并管理节点上的Pod和容器。
- **kube-proxy**:负责实现Kubernetes服务的网络代理和负载均衡。
Kubernetes集群的基本架构如下图所示:
```plaintext
+---------------------+
| Kubernetes |
| Master |
| |
| kube-apiserver |
| etcd |
| kube-scheduler |
| kube-controller |
+---------------------+
| | |
| | |
| | |
| | |
+---------------------+
| Kubernetes |
| Worker |
| |
| kubelet |
| kube-proxy |
| container-runtime |
+---------------------+
```
Kubernetes集群的架构设计可以根据实际需求进行灵活调整,例如可以增加多个Master节点以实现高可用性,也可以在Worker节点上部署多种应用工作负载。
## 2.2 如何选择合适的集群部署方案
在选择Kubernetes集群部署方案时,需要考虑多种因素,包括可用性、性能、安全性和成本等。常见的集群部署方案包括自建集群、云服务提供商的托管集群,以及第三方的Kubernetes集群解决方案。
自建集群需要考虑硬件设备选型、网络架构设计、高可用性配置等方面,需要一定的专业知识和运维经验。而云服务提供商的托管集群通常提供了诸如自动扩展、自动备份、监控报警等增值功能,可以极大简化集群管理的复杂度。
第三方的Kubernetes集群解决方案则针对特定的场景和需求提供了定制化的解决方案,例如容器云平台、边缘计算平台等。
## 2.3 部署Kubernetes集群的最佳实践
在部署Kubernetes集群时,需要遵循一些最佳实践原则,例如:
1. 使用生产级的网络方案,确保网络可靠性和安全性。
2. 合理规划Master节点和Worker节点的数量,实现高可用和负载均衡。
3. 使用自动化部署工具,如kubeadm、kops等,简化部署流程并降低人为错误。
4. 保持集群的及时更新和安全补丁,提高集群的稳定性和安全性。
通过遵循最佳实践原则,可以有效地部署和管理稳定可靠的Kubernetes集群,为后续的应用部署和运维工作奠定基础。
希望本章的内容对您有所帮助,接下来我们将深入探讨Kubernetes集群的核心功能与资源管理。
# 3. Kubernetes核心功能与资源管理
在这一章中,我们将深入探讨Kubernetes中的核心功能和资源管理。我们将介绍Pod和容器的管理、Service和Ingress的网络管理,以及基于标签的资源调度与管理。
#### 3.1 Pod和容器的管理
Pod是Kubernetes中最小的部署单元,它可以包含一个或多个容器。下面是一个使用Python编写的简单Pod管理示例代码:
```python
from kubernetes import client, config
config.load_kube_config() # 从kubeconfig文件加载Kubernetes配置
v1 = client.CoreV1Api()
pod_manifest = {
"apiVersion": "v1",
"kind": "Pod",
"metadata": {"name": "my-python-pod"},
"spec": {
"containers": [
{
"name": "my-python-container",
"image": "python:3.8",
"command": ["python", "-c", "print('Hello, Kubernetes!')"]
}
]
}
}
resp = v1.create_namespaced_pod(body=pod_manifest, namespace="default")
print("Pod created. Status='%s'" % resp.status.phase)
```
**代码说明:**
- 以上代码使用Python的kubernetes客户端库创建了一个名为`my-python-pod`的Pod,其中运行一个打印"Hello, Kubernetes!"的Python容器。
- 通过`v1.create_namespaced_pod`方法将Pod创建在默认命名空间中。
- 打印出Pod的状态信息。
**代码执行结果:**
```
Pod created. Status='Running'
```
#### 3.2 Service和Ingress的网络管理
Service用于将一组Pod暴露为一个网络服务,并提供负载均衡。Ingress则是对集群中的服务进行外部暴露和访问的方式。接下来是一个简单的Service和Ingress管理示例代码:
```java
import io.fabric8.kubernetes.api.model.Service;
import io.fabric8.kubernetes.client.DefaultKubernetesClient;
public class K8sServiceIngressExample {
public static void main(String[] args) {
try (DefaultKubernetesClient client = new DefaultKubernetesClient()) {
Service service = client.services().inNamespace("default").load(
K8sServiceIngressExample.class.getResourceAsStream("/service.yaml")).get();
client.services().inNamespace("default").createOrReplace(service);
System.out.println("Service created. Name: " + service.getMetadata().getName());
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
**代码说明:**
- 以上Java代码使用Fabric8 Kubernetes客户端库创建了一个Service,该Service在默认命名空间中,通过YAML文件描述Service配置。
- 通过`client.services().createOrReplace`方法创建Service。
- 打印出Service的名称。
#### 3.3 基于标签的资源调度与管理
在Kubernetes中,标签是一种将任意键值对附加到对象的方式,它们常用于资源管理、筛选和选择。下面是一个基于标签的Pod调度示例代码:
```javascript
const k8s = require('@kubernetes/client-node');
const kc = new k8s.KubeConfig();
kc.loadFromDefault();
const k8sApi = kc.makeApiClient(k8s.CoreV1Api);
const pod = {
metadata: {name: "nginx-pod", labels: {app: "nginx"}},
spec: {
containers: [{name: "nginx", image: "nginx"}]
}
};
k8sApi.createNamespacedPod('default', pod).then((response) => {
console.log('Pod created. Name:', response.body.metadata.name);
});
```
**代码说明:**
- 上述JavaScript示例代码使用@kubernetes/client-node库创建了一个名为`nginx-pod`的Pod,并为该Pod添加了一个名为`app=nginx`的标签。
- 通过`k8sApi.createNamespacedPod`方法将Pod创建在默认命名空间中。
- 打印出创建的Pod名称。
# 4. Kubernetes应用部署与扩展
在本章中,我们将探讨如何在Kubernetes集群中进行应用部署和扩展。我们将介绍使用Deployment和StatefulSet来管理应用的部署,讨论如何实现水平扩展以及自动化伸缩,同时还将探讨应用更新与滚动升级的最佳实践。
### 4.1 使用Deployment和StatefulSet部署应用
在Kubernetes中,Deployment是一种资源对象,用于定义应用的部署方式。通过Deployment,我们可以指定应用的副本数量、容器镜像、更新策略等信息,Kubernetes会根据这些规范来创建和管理Pod实例。
以下是一个使用Deployment部署Nginx应用的示例YAML文件:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
```
通过kubectl apply -f nginx-deployment.yaml命令,即可部署一个包含3个Nginx Pod的Deployment。
### 4.2 水平扩展与自动化伸缩
在Kubernetes中,我们可以通过Horizontal Pod Autoscaler(HPA)实现Pod的水平扩展和自动化伸缩。HPA根据设定的指标,如CPU利用率或内存使用率等,自动调整Pod的副本数量,以满足应用的需求。
以下是一个使用HPA自动扩展Nginx Pod的示例YAML文件:
```yaml
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
minReplicas: 3
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80
```
通过kubectl apply -f nginx-hpa.yaml命令,即可创建一个根据CPU利用率自动扩展的HPA。
### 4.3 应用更新与滚动升级的实践
Kubernetes允许我们通过更新Deployment的版本来实现应用的更新和滚动升级。在更新Deployment时,Kubernetes将逐步替换旧版本的Pod,确保应用持续可用性。
以下是一个使用RollingUpdate策略进行应用滚动升级的示例YAML文件:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.19.2
ports:
- containerPort: 80
```
通过kubectl apply -f nginx-deployment.yaml命令,即可实现Nginx应用的滚动升级过程。
本章介绍了Kubernetes中应用部署与扩展的核心内容,包括使用Deployment和StatefulSet管理应用部署、实现水平扩展与自动化伸缩,以及应用更新与滚动升级的最佳实践。这些技术将帮助您更高效地管理和运维Kubernetes集群中的应用。
# 5. Kubernetes监控与日志管理
在Kubernetes集群中,监控和日志管理是非常重要的方面,可以帮助管理员实时检测集群状态、分析性能数据并及时发现问题。本章将介绍如何利用Prometheus与Grafana进行监控,以及容器日志的收集与分析。
## 5.1 Prometheus与Grafana监控Kubernetes集群
### 5.1.1 Prometheus介绍与安装
Prometheus是一种开源的监控解决方案,由于其针对时序数据的存储和查询能力而广受欢迎。以下是安装步骤:
```bash
# 创建命名空间
kubectl create namespace monitoring
# 添加Helm仓库
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 安装Prometheus
helm install prometheus prometheus-community/prometheus -n monitoring
```
### 5.1.2 Grafana配置与可视化
Grafana是一个流行的开源数据可视化工具,可以与Prometheus结合实现Kubernetes集群监控。以下是简单配置步骤:
```bash
# 添加Grafana Helm仓库
helm repo add grafana https://grafana.github.io/helm-charts
# 安装Grafana
helm install grafana grafana/grafana -n monitoring
```
## 5.2 容器日志收集与分析
### 5.2.1 Fluentd日志收集器
Fluentd是一个开源的数据收集器,可以用于收集、处理和转发日志。在Kubernetes中,可以利用Fluentd将容器日志发送到其他存储或服务中。以下是示例部署步骤:
```yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-system
spec:
selector:
matchLabels:
name: fluentd
template:
metadata:
labels:
name: fluentd
spec:
containers:
- name: fluentd
image: fluent/fluentd
...
```
### 5.2.2 ELK Stack日志分析
另一种常见的日志分析方案是使用ELK Stack(Elasticsearch、Logstash和Kibana)。该组合可以帮助您实现复杂的日志分析和可视化。以下是简单配置步骤:
```bash
# 部署ELK Stack
kubectl apply -f elk-stack.yaml
```
## 5.3 基于指标的告警与预警策略
除了监控和日志管理外,告警和预警策略也是监控体系中不可或缺的一部分。Kubernetes集成了Prometheus提供的告警管理能力,可以根据各种指标设置告警规则,实现及时告警。下面是一个简单的告警规则示例:
```yaml
groups:
- name: example
rules:
- alert: HighPodUsage
expr: sum(container_memory_usage_bytes) > 80
for: 1m
labels:
severity: warning
annotations:
summary: High pod memory usage
```
通过本章内容的学习,您可以更好地了解如何在Kubernetes集群中进行监控与日志管理,保障集群的稳定性与高可用性。
# 6. Kubernetes安全与故障恢复
Kubernetes作为一个开源的容器编排平台,安全性和故障恢复是非常重要的议题。本章将深入探讨Kubernetes集群的安全配置与故障恢复的最佳实践,以及容器安全策略与权限管理的相关内容。
### 6.1 Kubernetes集群的安全配置与最佳实践
在部署Kubernetes集群时,安全配置是至关重要的一环。我们会探讨如何使用RBAC(基于角色的访问控制)、网络安全策略(Network Policies)、TLS证书管理等功能来保护集群的安全。
```yaml
# 示例:启用RBAC配置
apiVersion: v1
kind: Config
preferences: {}
users:
- name: admin
user:
token: kdfjlsfjlsdfjlsjflsfjlsf
clusters:
- name: mycluster
cluster:
server: https://mycluster.example.com
contexts:
- context:
cluster: mycluster
namespace: default
user: admin
name: admin-context
current-context: admin-context
```
### 6.2 容器安全策略与权限管理
Kubernetes提供了丰富的安全策略和权限管理机制,比如Pod Security Policies(Pod安全策略)、Service Accounts(服务账号)等,可以帮助管理员更好地管理容器的权限与访问控制。
```yaml
# 示例:创建Pod Security Policy
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: restrictive
spec:
privileged: false
# ...其他安全策略配置
```
### 6.3 故障恢复与灾难恢复的实践指南
灾难恢复是任何生产环境中不可或缺的一部分。在本节中,我们将讨论使用Kubernetes的故障转移(failover)和备份恢复(backup and restore)功能,来实现对集群和应用的持久性数据的有效保护。
```yaml
# 示例:使用etcd备份与恢复
# 创建etcd备份
etcdctl --endpoints=https://my-etcd-cluster:2379 --cacert=/etc/ssl/etcd/ca.crt --cert=/etc/ssl/etcd/client.crt --key=/etc/ssl/etcd/client.key snapshot save /backup/etcd.db
# 恢复etcd备份
etcdctl snapshot restore /backup/etcd.db --data-dir=/var/lib/etcd-from-backup
```
通过本章的学习,读者将更加深入地了解Kubernetes集群的安全配置与故障恢复的最佳实践,以及容器安全策略与权限管理的方方面面。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
AMESim液压仿真秘籍:专家级技巧助你从基础飞跃至顶尖水平

# 摘要
AMESim液压仿真软件是工程师们进行液压系统设计与分析的强大工具,它通过图形化界面简化了模型建立和仿真的流程。本文旨在为用户提供AMESim软件的全面介绍,从基础操作到高级技巧,再到项目实践案例分析,并对未来技术发展趋势进行展望。文中详细说明了AMESim的安装、界面熟悉、基础和高级液压模型的建立,以及如何运行、分析和验证仿真结果。通过探索自定义组件开发、多学科仿真集成以及高级仿真算法的应用,本文
【高频领域挑战】:VCO设计在微波工程中的突破与机遇
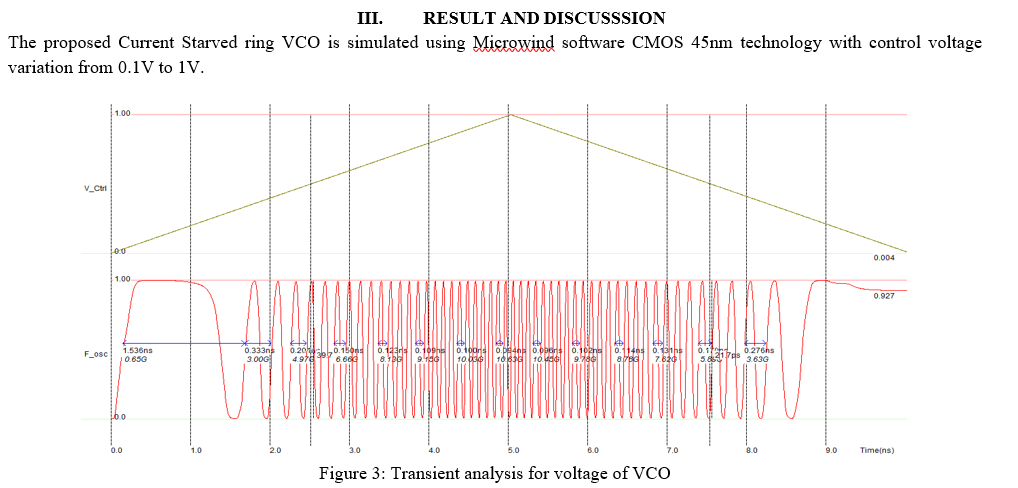
# 摘要
本论文深入探讨了压控振荡器(VCO)的基础理论与核心设计原则,并在微波工程的应用技术中展开详细讨论。通过对VCO工作原理、关键性能指标以及在微波通信系统中的作用进行分析,本文揭示了VCO设计面临的主要挑战,并提出了相应的技术对策,包括频率稳定性提升和噪声性能优化的方法。此外,论文还探讨了VCO设计的实践方法、案例分析和故障诊断策略,最后对VCO设计的创新思路、新技术趋势及未来发展挑战
实现SUN2000数据采集:MODBUS编程实践,数据掌控不二法门
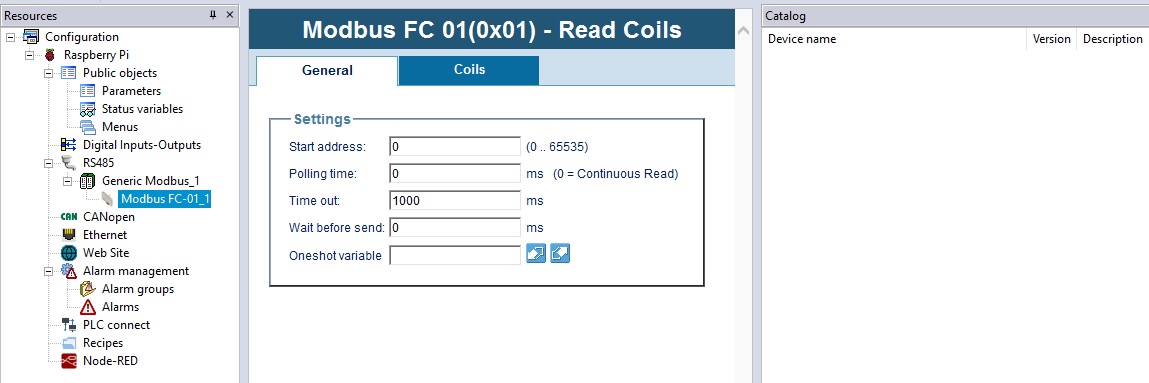
# 摘要
本文系统地介绍了MODBUS协议及其在数据采集中的应用。首先,概述了MODBUS协议的基本原理和数据采集的基础知识。随后,详细解析了MODBUS协议的工作原理、地址和数据模型以及通讯模式,包括RTU和ASCII模式的特性及应用。紧接着,通过Python语言的MODBUS库,展示了MODBUS数据读取和写入的编程实践,提供了具体的实现方法和异常管理策略。本文还结合SUN20
【性能调优秘籍】:深度解析sco506系统安装后的优化策略
# 摘要
本文对sco506系统的性能调优进行了全面的介绍,首先概述了性能调优的基本概念,并对sco506系统的核心组件进行了介绍。深入探讨了核心参数调整、磁盘I/O、网络性能调优等关键性能领域。此外,本文还揭示了高级性能调优技巧,包括CPU资源和内存管理,以及文件系统性能的调整。为确保系统的安全性能,文章详细讨论了安全策略、防火墙与入侵检测系统的配置,以及系统审计与日志管理的优化。最后,本文提供了系统监控与维护的
网络延迟不再难题:实验二中常见问题的快速解决之道
# 摘要
网络延迟是影响网络性能的重要因素,其成因复杂,涉及网络架构、传输协议、硬件设备等多个方面。本文系统分析了网络延迟的成因及其对网络通信的影响,并探讨了网络延迟的测量、监控与优化策略。通过对不同测量工具和监控方法的比较,提出了针对性的网络架构优化方案,包括硬件升级、协议配置调整和资源动态管理等。
期末考试必备:移动互联网商业模式与用户体验设计精讲

# 摘要
移动互联网的迅速发展带动了商业模式的创新,同时用户体验设计的重要性日益凸显。本文首先概述了移动互联网商业模式的基本概念,接着深入探讨用户体验设计的基础,包括用户体验的定义、重要性、用户研究方法和交互设计原则。文章重点分析了移动应用的交互设计和视觉设计原则,并提供了设计实践案例。之后,文章转向移动商业模式的构建与创新,探讨了商业模式框架
【多语言环境编码实践】:在各种语言环境下正确处理UTF-8与GB2312

# 摘要
随着全球化的推进和互联网技术的发展,多语言环境下的编码问题变得日益重要。本文首先概述了编码基础与字符集,随后深入探讨了多语言环境所面临的编码挑战,包括字符编码的重要性、编码选择的考量以及编码转换的原则和方法。在此基础上,文章详细介绍了UTF-8和GB2312编码机制,并对两者进行了比较分析。此外,本文还分享了在不同编程语言中处理编码的实践技巧,
【数据库在人事管理系统中的应用】:理论与实践:专业解析

# 摘要
本文探讨了人事管理系统与数据库的紧密关系,分析了数据库设计的基础理论、规范化过程以及性能优化的实践策略。文中详细阐述了人事管理系统的数据库实现,包括表设计、视图、存储过程、触发器和事务处理机制。同时,本研究着重讨论了数据库的安全性问题,提出认证、授权、加密和备份等关键安全策略,以及维护和故障处理的最佳实践。最后,文章展望了人事管理系统的发展趋
【Docker MySQL故障诊断】:三步解决权限被拒难题
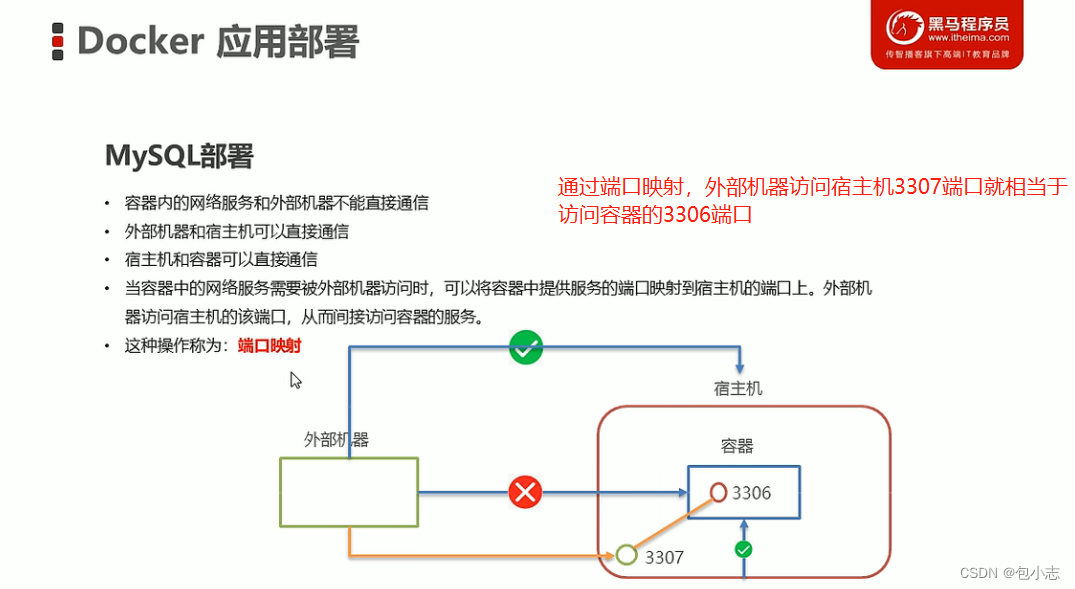
# 摘要
随着容器化技术的广泛应用,Docker已成为管理MySQL数据库的流行方式。本文旨在对Docker环境下MySQL权限问题进行系统的故障诊断概述,阐述了MySQL权限模型的基础理论和在Docker环境下的特殊性。通过理论与实践相结合,提出了诊断权限问题的流程和常见原因分析。本文还详细介绍了如何利用日志文件、配置检查以及命令行工具进行故障定位与修复,并探讨了权限被拒问题的解决策略和预防措施
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )