Go语言错误处理秘籍系列:新手到专家的10大最佳实践
发布时间: 2024-10-19 03:43:13 阅读量: 28 订阅数: 22 

Go语言精进之路:从新手到高手的编程思想、方法和技巧1.docx

# 1. Go语言错误处理概述
## 1.1 Go语言错误处理重要性
在软件开发中,错误处理是至关重要的部分,它不仅保障程序的健壮性,还决定了软件的用户体验质量。Go语言(Golang)作为一门现代编程语言,其错误处理机制与众不同,为开发者提供了简洁而强大的错误处理能力。Go语言的错误处理哲学是:明确和直接,鼓励程序员在代码中显式处理错误,而不是忽略它们。
## 1.2 错误处理的基本原则
Go语言通过几个关键机制来处理错误,包括返回值、错误接口以及`defer`语句等。简单来说,一个Go函数可以返回一个`error`类型的值来表示可能出现的错误情况。标准库和第三方库都遵循这一约定,这让错误处理在Go中具有一致性。为了保证错误能够被正确地传递和处理,Go推荐使用`defer`语句来确保资源的正确释放,即使在发生错误的情况下也能保持程序的稳定性。
## 1.3 错误处理实践注意事项
在实际开发中,正确的错误处理能够帮助开发者定位问题、提供清晰的错误信息给最终用户,以及确保系统资源的正确释放。有效的错误处理策略包括区分可恢复的错误和不可恢复的错误,合理使用`panic`和`recover`以及自定义错误类型来扩展错误处理的能力。这一章节将为读者提供Go语言错误处理的基础知识与实践技巧,以帮助他们编写更安全、更健壮的Go程序。
# 2. 理解Go语言的错误机制
## 2.1 Go语言错误类型
### 2.1.1 错误接口和实现
在Go语言中,错误是通过接口`error`表示的,这是实现错误处理的关键机制。`error`接口仅包含一个方法`Error() string`,任何自定义的类型只要实现了这个方法,就可以被当作错误类型使用。这种设计允许开发者构建具有丰富信息和结构的错误类型,而不仅仅是简单的文本消息。
```go
type error interface {
Error() string
}
```
使用自定义错误类型可以包含错误发生的具体上下文信息,这有助于调试和错误恢复。为了说明这一点,考虑以下代码段,其中定义了一个`FileNotFound`错误类型,它携带了文件名的信息。
```go
type FileNotFound struct {
FileName string
}
func (e *FileNotFound) Error() string {
return fmt.Sprintf("file %s not found", e.FileName)
}
```
在上述示例中,`FileNotFound`类型通过实现`Error()`方法,其输出在遇到文件找不到时不仅表明了这是一个错误,还指明了具体的文件名。这是一种提升错误信息质量的有效手段。
### 2.1.2 panic与recover机制
Go语言提供了一种特殊的错误处理机制,即`panic`和`recover`。`panic`用于在检测到不可恢复的错误时停止当前函数的正常执行流程。一旦`panic`被调用,程序就会停止执行当前的函数,并开始逐级向上回退,直到`recover`函数被调用或程序终止。
```go
func panic(interface{})
func recover() interface{}
```
`recover`用于从`panic`引起的程序崩溃中恢复。它必须在`defer`语句中使用,因为`defer`保证了即使在`panic`后,代码也能被执行。
```go
defer func() {
if r := recover(); r != nil {
// 从panic中恢复并处理错误
}
}()
```
在处理`panic`和`recover`时,需要注意正确地封装和清理资源。通常,使用`defer`来确保资源被正确释放,即使在`panic`之后也是如此。
```go
func mustBeZero(i int) {
if i != 0 {
panic(fmt.Sprintf("Value must be zero, got %d", i))
}
}
func main() {
defer fmt.Println("Done")
mustBeZero(1)
fmt.Println("Should not be printed")
}
```
在上述示例中,如果`mustBeZero`函数检测到`i`不为零,则会引发`panic`。`defer`确保在`panic`发生后,`main`函数仍能执行并打印"Done"。
## 2.2 错误处理的惯用法
### 2.2.1 defer, panic, recover结合使用
`defer`、`panic`和`recover`是Go语言中处理错误的重要工具。结合使用这三个特性,可以构建出健壮的错误处理机制。一个典型的惯用法是使用`defer`来关闭资源,使用`panic`来报告错误,并使用`recover`来处理这些错误。
```go
func processFile(name string) (err error) {
f, err := os.Open(name)
if err != nil {
return err
}
defer f.Close()
// 在这里处理文件
// ...
return nil
}
```
在`processFile`函数中,使用`defer`来关闭文件,这是一种保证即使发生错误或`panic`时资源仍被正确释放的惯用法。`defer`函数在`processFile`函数返回之前执行,无论返回原因是正常结束还是因为发生错误。
### 2.2.2 自定义错误类型和包装错误
Go语言鼓励使用自定义错误类型,特别是当标准错误接口不提供足够的信息时。此外,开发者常用`fmt.Errorf`来包装错误,这不仅可以提供额外的上下文,还可以简化错误处理的复杂性。
```go
func doSomeWork() error {
// ...
if someCondition {
return fmt.Errorf("in doSomeWork: %w", errSomeSpecificThingHappened)
}
return nil
}
```
在上述示例中,`fmt.Errorf`函数使用`%w`格式化符来包装错误`errSomeSpecificThingHappened`,这样在调用栈上方的函数就可以更方便地处理这个错误了。包装错误可以在调用栈中传播错误信息,同时保留错误链,这对于调试和错误追踪非常有用。
## 2.3 错误处理的高级话题
### 2.3.1 标准库中的错误处理模式
Go语言的标准库广泛使用了错误处理模式,并为开发者提供了处理常见问题的参考。例如,在I/O操作中,标准库会返回错误,同时通常会提供一种方式来检查错误是否为特定的错误类型。
```go
func copyFile(srcName, destName string) error {
src, err := os.Open(srcName)
if err != nil {
return err
}
defer src.Close()
dest, err := os.Create(destName)
if err != nil {
return err
}
defer dest.Close()
_, err = io.Copy(dest, src)
if err != nil {
return err
}
err = dest.Close()
if err != nil {
return err
}
return nil
}
```
在`copyFile`函数中,对每一个可能产生错误的I/O操作都进行了检查,并在适当的地方返回了错误。这是一种常见的错误处理模式,用于确保文件操作的正确性和鲁棒性。
### 2.3.2 错误处理策略的演进
随着时间的推移,Go语言社区逐渐发展出了一套标准的错误处理策略。一些模式,如将错误信息记录到日志,并使用日志级别表示错误严重性,已经成为习惯用法。此外,Go1.13引入了错误包装的新特性,使得错误处理更加灵活和丰富。
```go
if err != nil {
log.Printf("warning: some operation failed: %v", err)
}
```
在该示例中,通过日志记录错误信息,可以帮助开发者追踪错误发生的位置和上下文,便于后续的调试和问题解决。随着Go语言的演进,我们可以预见,错误处理机制将更加完善,以支持大型系统的复杂需求。
# 3. Go语言错误处理的实践技巧
## 3.1 错误处理的最佳实践案例分析
在处理Go语言错误时,最佳实践可以帮助开发者确保他们的程序既健壮又可维护。让我们深入研究一些在业务逻辑中处理错误的策略以及如何集成第三方库来避免错误处理的常见陷阱。
### 3.1.1 业务逻辑中错误处理的策略
当在Go语言中编写业务逻辑时,错误处理可以决定程序的稳定性和性能。以下是一些处理错误的策略:
- **单一职责原则**:每个函数应该只负责一个任务,这样可以减少错误发生的可能性。如果函数需要执行多个步骤,请将其分解为更小的函数。
- **错误处理层次化**:在更高层次的函数中封装错误处理逻辑,以避免在每个小函数中重复相同的错误检查代码。
- **定义清晰的错误返回**:使用自定义错误类型来明确指定错误的原因和类型,而不是返回模糊的错误信息,如 `"nil"` 或者 `"unknown error"`。
```go
type NotFoundError struct {
Msg string
}
func (e *NotFoundError) Error() string {
return fmt.Sprintf("not found error: %s", e.Msg)
}
// ...
if item == nil {
return &NotFoundError{Msg: "item not found"}
}
```
在上面的例子中,我们定义了一个`NotFoundError`类型来清晰地表示找不到特定项的错误情况。
### 3.1.2 第三方库集成与错误处理
集成第三方库时,正确处理错误显得尤为重要,因为它可以影响到整个应用程序的稳定性。下面是一些集成第三方库时需要注意的实践:
- **验证库的稳定性**:选择那些有良好维护记录和社区支持的库。
- **使用版本控制**:在`go.mod`文件中为第三方库指定明确的版本号,避免因库的变更引起的问题。
- **错误包装**:在调用第三方库函数时,要将它们的错误包装到自定义错误中,这样可以提供更好的上下文信息。
```go
if err := thirdPartyFunc(); err != nil {
return fmt.Errorf("third party error: %w", err)
}
```
在这个代码段中,`fmt.Errorf`与`%w`占位符一起使用,它将第三方库的错误包装在自定义错误中。
## 3.2 错误处理工具和库
尽管Go语言提供了错误处理的基本工具,但第三方库和工具可以进一步增强错误处理的功能和便利性。
### 3.2.1 使用第三方错误处理库
有许多第三方库可以简化错误处理流程并提高错误处理的效率。例如:
- **pkg/errors**:提供更丰富的错误包装和错误追踪功能。
- **go-raymond/errors**:增加了错误模板和格式化功能。
```go
import "***/pkg/errors"
if err := doSomething(); err != nil {
return errors.Wrap(err, "failed to do something")
}
```
上述代码中`errors.Wrap`函数增加了上下文到错误消息中,并保留了原始错误的堆栈跟踪。
### 3.2.2 错误链与错误上下文的追踪
当错误在多个函数调用链中传播时,保留错误的上下文就显得尤为重要。这样可以追溯错误的根源,并理解错误发生的具体位置。
```go
import "***/x/xerrors"
func funcA() error {
return xerrors.New("error in funcA")
}
func funcB() error {
err := funcA()
if err != nil {
return xerrors.Errorf("error in funcB: %w", err)
}
return nil
}
// ...
if err := funcB(); err != nil {
fmt.Printf("%+v", err)
}
```
`xerrors`库提供了一个`%+v`格式化选项,用于打印完整的错误堆栈信息。
## 3.3 避免常见错误处理的陷阱
错误处理中存在一些常见的陷阱,开发者应该小心避免。
### 3.3.1 忽略错误或过度处理错误
错误处理的最常见陷阱之一是完全忽略错误,或者对每个错误都进行过度处理。
- **忽略错误**:这会导致隐藏了本来可以提早发现并处理的潜在问题。
- **过度处理错误**:这可能会使得代码逻辑变得复杂,并可能引发新的错误。
应该有一个清晰的错误处理策略,来决定何时记录错误、何时返回错误、何时从错误中恢复。
### 3.3.2 错误日志记录的最佳实践
错误日志记录是错误处理的一个重要方面。以下是记录错误时的一些最佳实践:
- **记录足够的上下文信息**:应该记录足够的信息来帮助开发者理解错误发生的情境。
- **使用结构化日志**:结构化日志可以方便地进行查询和分析。
- **避免记录敏感信息**:出于安全考虑,不应记录密码、令牌等敏感信息。
```go
log.Printf("error: unable to process item: %v", err)
```
在上面的例子中,我们通过`log.Printf`记录了错误消息,同时提供了一个错误变量作为参数来保持错误信息的结构化。
通过这些实践技巧,Go语言的开发者可以更有效地处理错误,从而提高代码的整体质量和可维护性。
# 4. Go语言中的错误恢复与测试
## 4.1 错误恢复的策略
### 4.1.1 错误恢复的时机和方法
在Go语言的运行时中,错误可能在程序的任何地方发生,无论是同步的还是异步的。因此,设计错误恢复的策略需要考虑代码中的关键部分,以确保资源得到适当的管理,即使在发生错误时也是如此。
错误恢复的一个关键策略是在出现错误时进行适当的资源释放。这通常是通过使用`defer`语句来实现的,它允许我们定义一个在函数退出时会执行的代码块。这个特性对于资源清理至关重要,因为它确保了即使在发生错误的情况下,资源也能被正确地释放。
```go
func main() {
file, err := os.Create("test.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close() // 确保文件在结束时关闭
// 执行文件写入操作...
_, err = file.WriteString("Hello, Go!\n")
if err != nil {
log.Fatal(err)
}
}
```
在上面的例子中,无论写入操作是否成功,`defer`确保文件会关闭。此外,如果在`Create`和`WriteString`调用之间发生错误,我们还可以使用`panic`来立即终止程序,然后通过`defer`函数来清理资源,最后使用`recover`来捕获panic并继续执行或优雅地终止。
### 4.1.2 优雅地关闭资源与错误恢复
优雅地关闭资源意味着在程序或函数退出之前,确保所有的资源都被正确地关闭,而不会导致数据丢失或者资源泄露。在Go中,结合`defer`和`panic`/`recover`机制是一种常见的错误恢复模式,能够确保即使在发生错误时,也能优雅地处理资源释放。
```go
func main() {
// ...省略初始化和错误处理代码...
defer func() {
if r := recover(); r != nil {
// 恢复后进行清理操作
log.Println("Recovered in main:", r)
// 关闭数据库连接,释放其他资源等
}
}()
// 主处理逻辑...
panic("Something went wrong!") // 模拟发生错误
}
```
在这个例子中,如果在主处理逻辑中发生了错误,`defer`函数会捕获`panic`,进行日志记录,并执行必要的资源释放操作。这种模式保证了即使在程序崩溃的情况下,资源也能被妥善处理。
## 4.2 错误的单元测试
### 4.2.1 测试框架和工具介绍
Go语言拥有一个内置的测试框架,它基于`testing`包提供了编写测试和基准测试的功能。错误测试的核心思想是验证在给定的输入和预期条件下,函数或代码的行为是否符合预期。为此,你需要使用断言来检查错误是否是正确的,或者函数调用是否如预期地返回了错误。
测试工具如`go test`命令允许开发者编写测试用例,运行测试并收集结果。测试用例通常以`Test`为前缀命名,`go test`命令会自动执行这些函数。使用这些测试工具,可以对错误处理代码进行彻底的测试,确保它们能够处理各种边界条件和潜在的错误场景。
### 4.2.2 构建全面的错误测试用例
编写全面的错误测试用例包括对正常和异常路径进行测试,确保代码在各种情况下都能正确处理错误。你可以使用`*testing.T`类型提供的`Error`, `Errorf`, `Fail`等方法来记录测试失败,并在测试运行时输出错误信息。
```go
func TestSomethingThatCanFail(t *testing.T) {
_, err := SomethingThatCanFail()
if err == nil {
t.Fatal("Expected an error, but there was none")
}
// 检查错误类型
var myError *MyError
if !errors.As(err, &myError) {
t.Fatalf("Expected error of type *MyError, got: %T", err)
}
// 检查错误内容
if myError.Code != expectedErrorCode {
t.Errorf("Expected error code %d, got %d", expectedErrorCode, myError.Code)
}
}
```
在这个测试用例中,我们首先检查是否收到了错误。如果没有收到错误,则测试失败。接着,我们检查错误是否是预期的类型,并验证错误中包含的数据是否正确。这有助于确保我们的错误处理逻辑能够正确地识别和响应不同类型的错误。
## 4.3 错误模拟与模拟库
### 4.3.1 测试中的错误模拟技巧
错误模拟是测试中常用的一种技巧,它允许开发者模拟外部依赖或函数的返回值,以便测试代码在特定条件下(比如返回错误)的行为。这特别适用于测试那些依赖于外部系统或服务的代码,比如数据库操作和网络调用。
要进行错误模拟,开发者通常需要使用接口和依赖注入。通过定义接口,可以模拟返回特定错误的函数。例如,如果有一个函数`FetchData`返回`data`和`error`,可以在测试中注入一个实现了相同接口但返回错误的模拟版本。
### 4.3.2 模拟库的使用和比较
有许多第三方库可以用于模拟错误,它们简化了创建模拟对象的过程,并提供了丰富的功能,如记录调用、设定返回值和断言。一些流行的模拟库包括`gomock`、`testify`和`gomock`。
比如,`gomock`是一个生成器工具和运行时库,可以用来创建接口的模拟实现:
```go
// 使用gomock创建测试的模拟
func TestFetchData(t *testing.T) {
// 创建gomock控制器和模拟对象
ctrl := gomock.NewController(t)
defer ctrl.Finish()
mockDataFetcher := NewMockDataFetcher(ctrl)
mockDataFetcher.
EXPECT().
FetchData(gomock.Any()).
Return(nil, errors.New("simulated error"))
// 使用模拟对象进行测试
_, err := mockDataFetcher.FetchData("some key")
if err == nil || err.Error() != "simulated error" {
t.Errorf("Expected simulated error, got: %s", err)
}
}
```
在上面的代码中,我们创建了一个模拟对象来代替真实的`DataFetcher`,并且让它在`FetchData`方法被调用时返回一个模拟的错误。通过`gomock`库,可以非常灵活地设置复杂的期望条件和行为。
`testify`库中的`mock`包提供了类似的模拟功能,并且与`gomock`相比,它更加简洁。`testify`的模拟对象可以很容易地与`testify`的`assert`包集成,后者提供了丰富的断言方法来验证测试结果。
通过比较和使用这些不同的库,开发者可以根据项目的需求和团队的喜好选择最适合的模拟策略,从而提高代码的可测试性和错误处理的可靠性。
# 5. Go语言错误处理的未来展望
随着软件开发实践的发展和技术的进步,Go语言的错误处理机制也在不断地演变和进化。本章将探索错误处理的未来趋势,看看Go语言和其他编程语言的错误处理模式,以及探讨成为Go错误处理专家的路径。
## 5.1 错误处理的演变趋势
Go语言作为一种简洁且高效的编程语言,其错误处理机制在多年的发展过程中也在不断优化。Go语言的版本更新,特别是Go 1的推出,标志着Go语言走向成熟和稳定。开发者社区对于错误处理的反馈和建议,也推动了错误处理机制的发展。
### 5.1.1 Go语言版本更新对错误处理的影响
在Go 1.13版本中,`context` 包的`Done`通道增加了接收一个`error`作为通道的可选返回值。这一改变允许调用者在调用`Done()`时,能够得到一个错误值,这通常表示一个因上下文被取消或超时而发生的错误。
```go
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
select {
case <-ctx.Done():
// ctx.Done() closed, ctx.Err() returns context.DeadlineExceeded
fmt.Println(ctx.Err())
case result := <-query:
fmt.Println(result)
}
```
在这个代码示例中,`ctx.Done()` 会因为上下文超时被关闭,从而允许我们在`select`语句中检测到并处理`context.DeadlineExceeded`错误。
此外,Go官方也在探索更优雅的错误处理方式,比如通过返回多个值来区分函数成功执行的结果和错误信息。未来版本的Go可能引入类似`Try/Catch`的异常处理机制,以使得错误处理更加直观和方便。
### 5.1.2 社区与业界的错误处理实践案例
在业界,不同的公司和开源项目基于Go语言的错误处理机制,形成了各自的最佳实践。例如,Kubernetes使用自定义的错误类型来表示特定的失败原因,并在文档中详细记录每种错误类型的处理方式。这些实践案例为Go语言的错误处理提供了丰富的参考,促进了整个社区在错误处理方面的进步。
## 5.2 跨语言的错误处理思路
Go语言的设计哲学强调简洁和效率,错误处理方面也不例外。而其他语言,如Rust,提供了不同的错误处理模式,例如通过`Result`和`Option`类型来处理可能的错误或空值。这些模式为Go语言提供了新的错误处理思路。
### 5.2.1 从Go看其他语言的错误处理模式
Rust语言通过引入`Result<T, E>`枚举类型来处理错误。这个类型有两个变体:`Ok(T)`代表成功并包含结果,而`Err(E)`代表失败并包含错误信息。Rust的这种模式鼓励开发者在编译时处理所有潜在的错误,而不是在运行时。
```rust
fn divide(dividend: f64, divisor: f64) -> Result<f64, String> {
if divisor == 0.0 {
Err("division by zero".to_string())
} else {
Ok(dividend / divisor)
}
}
```
在上述Rust函数示例中,如果除数为零,则函数返回一个包含错误信息的`Result`,否则返回包含计算结果的`Result`。这种模式减少了运行时错误的可能性,并且使得错误处理更为显式和类型安全。
### 5.2.2 跨语言错误处理的可能集成方式
随着多语言编程环境的普及,跨语言的错误处理集成变得越来越重要。例如,在使用Go开发微服务时,可能会调用Python或Node.js编写的其他服务。为了保持一致性,可以采用JSON Web Tokens (JWT) 等标准化的错误表示方法,以便于在不同的语言和系统之间传递错误信息。
```json
{
"error": {
"code": "404",
"message": "Requested resource not found",
"details": "No record found for the given ID"
}
}
```
此JSON结构可以被不同语言编写的客户端和服务端解析,并且易于集成到日志系统、监控系统和其他错误处理基础设施中。
## 5.3 结语:掌握错误处理的专家之道
掌握错误处理技能对每一个程序员来说都至关重要。它不仅仅是编写正确代码的基础,也是构建健壮和可维护系统的前提。
### 5.3.1 错误处理技能的重要性
能够熟练地处理错误的程序员,可以在复杂系统中预见并避免潜在的问题。他们能够编写出更加稳定和可靠的代码,并且在出现问题时能够快速定位和解决。
### 5.3.2 成为Go错误处理专家的路径
成为Go错误处理的专家,需要不断地学习和实践。关注Go语言的官方更新,研究社区中的优秀实践案例,以及阅读和理解其他语言的错误处理机制,都是提高错误处理能力的有效途径。此外,通过在实际项目中不断地应用和优化错误处理策略,可以逐步提升个人在这一领域的专业技能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Go 语言中错误处理的各个方面,从新手到专家。它提供了 10 大最佳实践,全面的解析,进阶教程,以及艺术和哲学方面的见解。专栏还涵盖了高级主题,如自定义错误类型、模式识别、错误记录、单元测试和并发错误处理。通过深入的案例分析、模式识别和流程改进,本专栏旨在帮助读者掌握 Go 语言中的错误处理,打造健壮、清晰且易于管理的代码。它提供了丰富的策略和技巧,帮助开发者避免常见的陷阱,并设计可重用的错误处理组件。无论你是新手还是经验丰富的开发者,本专栏都将为你提供宝贵的见解,帮助你提升 Go 语言错误处理技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ZEMAX zpl脚本构建:一步步教你如何打造首个脚本
# 摘要
ZEMAX ZPL脚本是用于光学设计和系统建模的专用语言。本文从基础入门讲起,逐步深入到ZPL脚本的语法和结构,以及变量和控制结构的使用。通过实践操作,本文指导用户如何应用ZPL脚本进行设计优化、系统建模分析以及数据可视化报告的生成。进一步,本文探讨了高级技巧,包括自定义函数、模块化编程、异常处理和脚本性能优化。在案例分析与实战演练章节中,本文通过实际案例展示了脚本的综合应用。最后,本文展望了ZPL脚本的未来技术趋势和社区资源分享的重要性,以期推动光学设计领域的发展。
# 关键字
ZEMAX;ZPL脚本;光学设计;系统建模;自动化脚本;性能优化
参考资源链接:[ZEMAX中ZPL
【Android SQLite并发控制】:多线程下的数据安全解决方案

# 摘要
随着移动应用的发展,SQLite数据库在Android平台上的并发控制成为优化应用性能和稳定性的重要议题。本文首先介绍了SQLite并发控制的基础知识和Android多线程编程的基础,接着深入探讨了SQLite并发控制机制中的事务机制、锁机制以及并发问题的诊断与处理。在实践应用章节中,本文提供了线程安全的数据访问模式,分析了高并发场景下的
模块化设计指南:TC8-WMShare对OPEN Alliance协议栈的影响详解

# 摘要
模块化设计是现代通信协议架构中提升系统可维护性、可扩展性和稳定性的关键技术。本文首先介绍了模块化设计的基本原理及其重要性,随后深入分析了TC8-WMShare协议的起源、架构以及与OPEN Alliance协议栈的关联。接着,本文探讨了模块化设计在TC8-WMShare协议中的具体实现和应用,以及它对OPE
【RT LAB高级特性】:详解如何优化你的仿真模型与系统
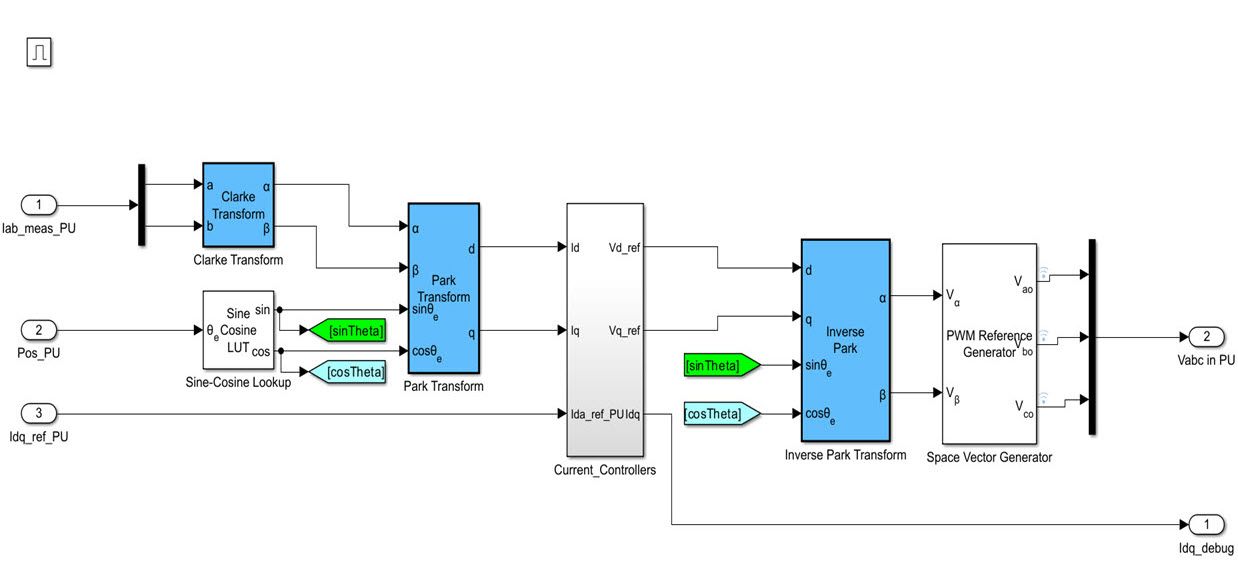
# 摘要
本文全面探讨了RT LAB仿真模型的基础知识、优化理论、高级应用、实践应用以及未来发展趋势。首先
【Silvaco TCAD核心解析】:3个步骤带你深入理解器件特性

# 摘要
Silvaco TCAD是半导体和电子领域中广泛使用的器件模拟软件,它能够模拟和分析从材料到器件的各种物理过程。本文介绍了TCAD的基本原理、模拟环境的搭建和配置,以及器件特性分析的方法。特别强调了如何使用TCAD进行高级应用技巧的掌握,以及在工业应用中如何通过TCAD对半导体制造工艺进行优化、新器件开发的支持和可靠性分析。此外,本文还探讨了TCAD未来发展
【开发者个性化设置】:Arduino IDE主题颜色设置的终极攻略

# 摘要
Arduino IDE作为一个广泛使用的集成开发环境,不仅为开发者提供了便利的编程工具,还支持个性化定制以满足不同用户的需求。本文首先概览了Arduino IDE的功能与用户个性化需求,随后深入探讨了主题颜色设置的理论基础、技术原理及个性化定制的方法。文章详细介绍了如何使用主题颜色编辑器进行内置主题的访问、修改和自定义主题的创建。
【S7-1200与MCGS数据交换秘籍】:交互机制全面解读(数字型、推荐词汇、实用型、私密性)
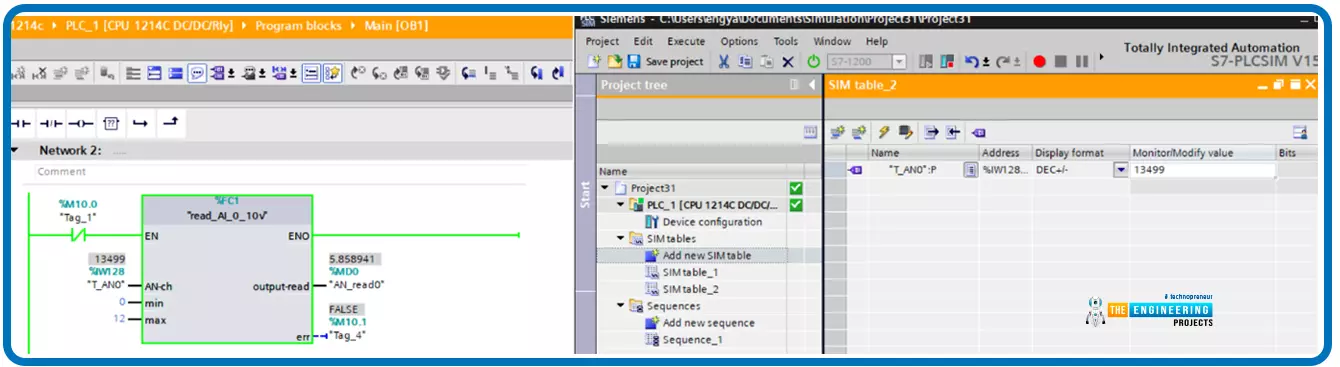
# 摘要
本文深入探讨了S7-1200 PLC与MCGS组态软件之间的数据交换机制。首先介绍S7-1200 PLC和MCGS组态软件的基础知识,接着详细论述数字型数据交换的理论基础和实践操作。本文进一步探讨了深度数据交换中的高级处理技巧、安全性和异常处理方法,并通过实战项目案例来
WinCC变量管理:一步提升效率的批量操作技术

# 摘要
本文全面概述了WinCC变量管理的各个方面,从基本操作到高级技术应用,再到实践案例与扩展应用,最后探讨了未来技术趋势。文章首先介绍了WinCC变量管理的基本概念,详细说明了变量的创建、编辑、批量操作和组织管理。接着,深入探讨了高级技术应用,如动态链接、性能优化和安全性管理。实践案例章节通过真实案例分析,展示了变量管理在工程实践中的应用,以及如何自动化批量操作和解决常见问题。最后,本文展望了WinCC变量管理技术的未来,探讨了新技
Fluent Scheme vs SQL:大数据处理中的关键对比分析

# 摘要
随着大数据技术的快速发展,高效的处理和分析技术变得至关重要。本文首先概述了大数据处理的背景,然后详细分析了Fluent Scheme语言的核心特性和高级特性,包括其数据流处理、嵌入式查询转换和并行处理机制,及其性能优化方法。同时,本文也探讨了SQL语言的基础、在大数据环境中的应用及其性能优化策略。文章进一步对比了Flu
DIP2.0与医疗数据隐私:探讨新标准下的安全与隐私保护
# 摘要
随着数字化医疗的兴起,医疗数据隐私保护变得日益重要。DIP2.0标准旨在提供一种全面的医疗数据隐私保护框架,不仅涉及敏感医疗信息的加密和匿名化,还包括访问控制、身份验证和数据生命周期管理等机制。本文探讨了DIP2.0标准的理论基础、实践应用以及面临的挑战,并分析了匿名化数据在临床研究中的应用和安全处理策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )