YOLO算法代码实现实战:从头编写Python代码,构建目标检测模型,提升编程能力
发布时间: 2024-08-15 03:55:11 阅读量: 37 订阅数: 50 

Python实现Yolo目标检测全面数据增强脚本 - 提升模型性能和泛化能力

# 1. YOLO算法简介
YOLO(You Only Look Once)是一种单阶段目标检测算法,它可以将图像中所有目标检测和定位任务同时完成。与传统的双阶段目标检测算法(如Faster R-CNN)不同,YOLO算法不需要生成候选区域,而是直接在输入图像上预测目标的边界框和类别。这种单阶段设计使得YOLO算法具有速度快的优点,使其非常适合实时目标检测任务。
# 2. Python代码实现YOLO算法
### 2.1 数据预处理
#### 2.1.1 数据集下载和处理
1. **下载数据集:**从COCO数据集官方网站下载训练集和验证集。
2. **数据解压:**将下载的压缩文件解压到指定目录。
3. **数据整理:**将训练集和验证集的图像和标签文件整理到对应的文件夹中。
```python
import os
import shutil
# 数据集下载路径
dataset_url = "https://github.com/ultralytics/yolov5/releases/download/v6.2/coco64img.zip"
# 数据集解压路径
dataset_dir = "data/coco"
# 下载数据集
os.system(f"wget {dataset_url} -O {dataset_dir}.zip")
# 解压数据集
shutil.unpack_archive(f"{dataset_dir}.zip", dataset_dir)
# 整理数据
os.makedirs(f"{dataset_dir}/images/train2017", exist_ok=True)
os.makedirs(f"{dataset_dir}/images/val2017", exist_ok=True)
os.makedirs(f"{dataset_dir}/labels/train2017", exist_ok=True)
os.makedirs(f"{dataset_dir}/labels/val2017", exist_ok=True)
# 将训练集图像和标签移动到指定文件夹
for filename in os.listdir(f"{dataset_dir}/train2017"):
if filename.endswith(".jpg"):
shutil.move(f"{dataset_dir}/train2017/{filename}", f"{dataset_dir}/images/train2017/{filename}")
elif filename.endswith(".txt"):
shutil.move(f"{dataset_dir}/train2017/{filename}", f"{dataset_dir}/labels/train2017/{filename}")
# 将验证集图像和标签移动到指定文件夹
for filename in os.listdir(f"{dataset_dir}/val2017"):
if filename.endswith(".jpg"):
shutil.move(f"{dataset_dir}/val2017/{filename}", f"{dataset_dir}/images/val2017/{filename}")
elif filename.endswith(".txt"):
shutil.move(f"{dataset_dir}/val2017/{filename}", f"{dataset_dir}/labels/val2017/{filename}")
```
#### 2.1.2 数据增强和归一化
1. **数据增强:**对训练集图像进行随机裁剪、翻转、旋转等增强操作,以增加数据集的多样性。
2. **归一化:**将图像像素值归一化到[0, 1]的范围内,以减少不同图像之间的差异。
```python
import albumentations as A
from albumentations.pytorch import ToTensorV2
# 数据增强变换
transform = A.Compose([
A.RandomCrop(height=416, width=416),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.RandomRotate90(p=0.5),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
])
```
### 2.2 模型构建
#### 2.2.1 网络结构设计
YOLOv5网络结构采用Darknet-53骨干网络,并在其基础上进行了一些改进。具体结构如下:
- **输入层:**416x416x3的图像
- **卷积层:**10个卷积层,用于提取图像特征
- **池化层:**5个最大池化层,用于降采样特征图
- **残差块:**5个残差块,用于增强特征提取能力
- **上采样层:**2个上采样层,用于恢复特征图的分辨率
- **检测头:**3个检测头,用于预测边界框和类别概率
```python
import torch
import torch.nn as nn
# 定义YOLOv5网络
class YOLOv5(nn.Module):
def __init__(self):
super().__init__()
# 骨干网络
self.backbone = nn.Sequential(
# 卷积层1
nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
# 最大池化层1
nn.MaxPool2d(kernel_size=2, stride=2),
# 卷积层2
nn.Co
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入剖析了 YOLO 算法在目标检测领域的建模、原理、技巧、部署、应用和性能评估等各个方面。从零基础入门到实战建模,从数学原理到代码实现,从超参数调优到数据增强,从部署优化到实际应用,全方位覆盖 YOLO 算法的方方面面。专栏还探讨了 YOLO 算法在图像分割、视频分析、自动驾驶、工业检测、安防监控、零售行业、体育赛事和农业等领域的应用,展现了其强大的潜力和广泛的应用场景。通过阅读本专栏,读者可以全面掌握 YOLO 算法的原理、实践和应用,快速提升目标检测建模技能,解决实际业务难题,引领算法前沿。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
爱普生R230打印机:废墨清零的终极指南,优化打印效果与性能

# 摘要
本文全面介绍了爱普生R230打印机的功能特性,重点阐述了废墨清零的技术理论基础及其操作流程。通过对废墨系统的深入探讨,文章揭示了废墨垫的作用限制和废墨计数器的工作逻辑,并强调了废墨清零对防止系统溢出和提升打印机性能的重要性。此外,本文还分享了提高打印效果的实践技巧,包括打印头校准、色彩管理以及高级打印设置的调整方法。文章最后讨论了打印机的维护策略和性能优化手段,以及在遇到打印问题时的故障排除
【Twig在Web开发中的革新应用】:不仅仅是模板

# 摘要
本文旨在全面介绍Twig模板引擎,包括其基础理论、高级功能、实战应用以及进阶开发技巧。首先,本文简要介绍了Twig的背景及其基础理论,包括核心概念如标签、过滤器和函数,以及数据结构和变量处理方式。接着,文章深入探讨了Twig的高级
如何评估K-means聚类效果:专家解读轮廓系数等关键指标
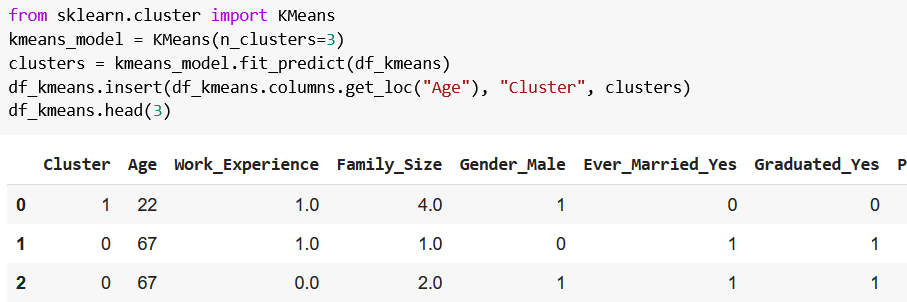
# 摘要
K-means聚类算法是一种广泛应用的数据分析方法,本文详细探讨了K-means的基础知识及其聚类效果的评估方法。在分析了内部和外部指标的基础上,本文重点介绍了轮廓系数的计算方法和应用技巧,并通过案例研究展示了K-means算法在不同领域的实际应用效果。文章还对聚类效果的深度评估方法进行了探讨,包括簇间距离测量、稳定性测试以及高维数据聚类评估。最后,本
STM32 CAN寄存器深度解析:实现功能最大化与案例应用
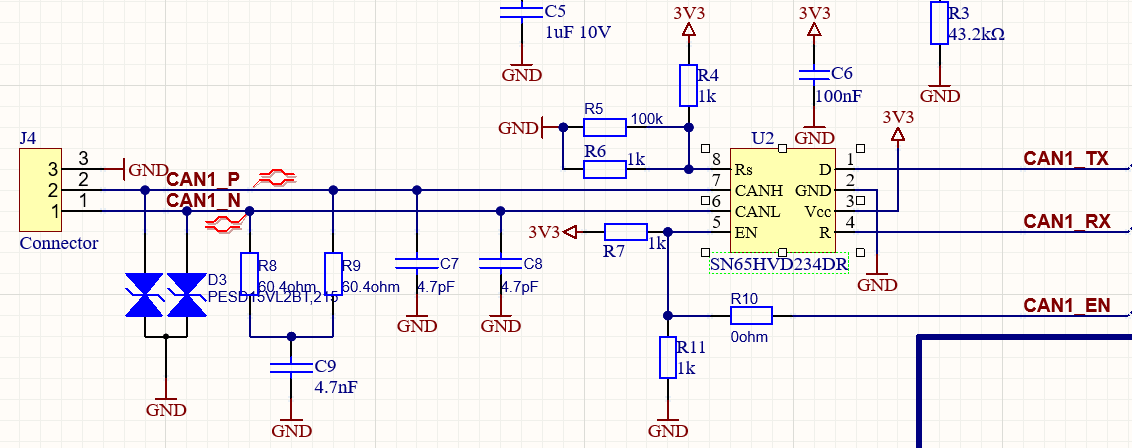
# 摘要
本文对STM32 CAN总线技术进行了全面的探讨和分析,从基础的CAN控制器寄存器到复杂的通信功能实现及优化,并深入研究了其高级特性。首先介绍了STM32 CAN总线的基本概念和寄存器结构,随后详细讲解了CAN通信功能的配置、消息发送接收机制以及错误处理和性能优化策略。进一步,本文通过具体的案例分析,探讨了STM32在实时数据监控系统、智能车载网络通信以
【GP错误处理宝典】:GP Systems Scripting Language常见问题与解决之道
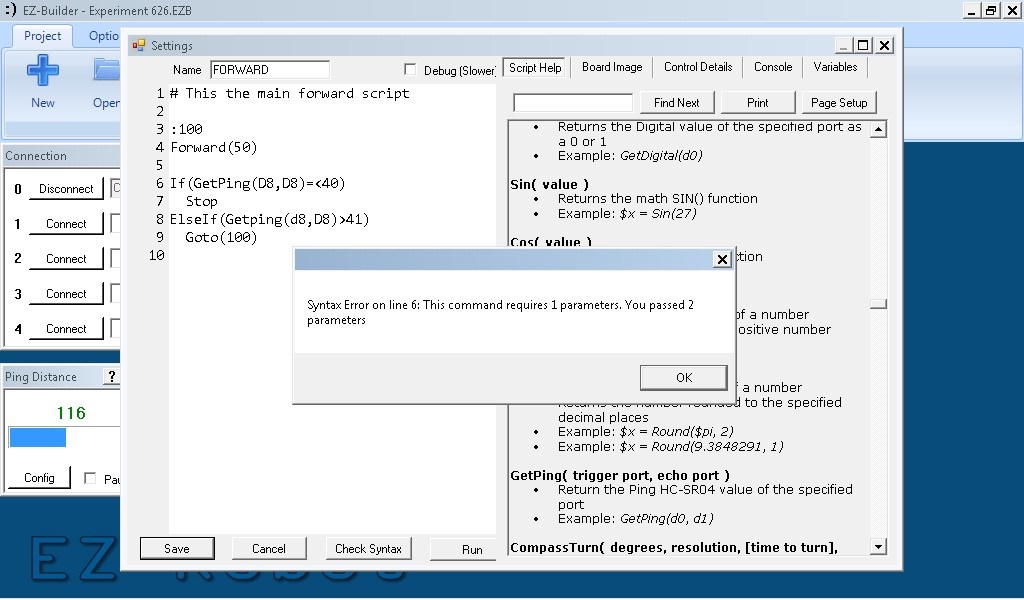
# 摘要
GP Systems Scripting Language是一种为特定应用场景设计的脚本语言,它提供了一系列基础语法、数据结构以及内置函数和运算符,支持高效的数据处理和系统管理。本文全面介绍了GP脚本的基本概念、基础语法和数据结构,包括变量声明、数组与字典的操作和标准函数库。同时,详细探讨了流程控制与错误处理机制,如条件语句、循环结构和异常处
【电子元件精挑细选】:专业指南助你为降噪耳机挑选合适零件

# 摘要
随着个人音频设备技术的迅速发展,降噪耳机因其能够提供高质量的听觉体验而受到市场的广泛欢迎。本文从电子元件的角度出发,全面分析了降噪耳机的设计和应用。首先,我们探讨了影响降噪耳机性能的电子元件基础,包括声学元件、电源管理元件以及连接性与控制元
ARCGIS高手进阶:只需三步,高效创建1:10000分幅图!
# 摘要
本文深入探讨了ARCGIS环境下1:10000分幅图的创建与管理流程。首先,我们回顾了ARCGIS的基础知识和分幅图的理论基础,强调了1:10000比例尺的重要性以及地理信息处理中的坐标系统和转换方法。接着,详细阐述了分幅图的创建流程,包括数据的准备与导入、创建和编辑过程,以及输出格式和版本管理。文中还介绍了一些高级技巧,如自动化脚本的使用和空间分析,以
【数据质量保障】:Talend确保数据精准无误的六大秘诀
# 摘要
数据质量对于确保数据分析与决策的可靠性至关重要。本文探讨了Talend这一强大数据集成工具的基础和在数据质量管理中的高级应用。通过介绍Talend的核心概念、架构、以及它在数据治理、监控和报告中的功能,本文强调了Talend在数据清洗、转换、匹配、合并以及验证和校验等方面的实践应用。进一步地,文章分析了Talend在数据审计和自动化改进方面的高级功能,包括与机器学习技术的结合。最后,通过金融服务和医疗保健行业的案
【install4j跨平台部署秘籍】:一次编写,处处运行的终极指南

# 摘要
本文深入探讨了使用install4j工具进行跨平台应用程序部署的全过程。首先介绍了install4j的基本概念和跨平台部署的基础知识,接着详细阐述了其安装步骤、用户界面布局以及系统要求。在此基础上,文章进一步阐述了如何使用install4j创建具有高度定制性的安装程序,包括定义应用程序属性、配置行为和屏幕以及管理安装文件和目录。此外,本文还
【Quectel-CM AT命令集】:模块控制与状态监控的终极指南

# 摘要
本论文旨在全面介绍Quectel-CM模块及其AT命令集,为开发者提供深入的理解与实用指导。首先,概述Quectel-CM模块的基础知识与AT命令基础,接着详细解析基本通信、网络功能及模块配置命令。第三章专注于AT命令的实践应用,包括数据传输、状态监控
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )