Netty中的NIO与BIO对比与选择
发布时间: 2024-01-11 20:36:57 阅读量: 39 订阅数: 33 
# 1. 引言
## 1.1 简介
Netty是一个高性能、异步事件驱动的网络应用程序框架,它基于Java的NIO技术实现了TCP和UDP传输协议的异步模型。Netty提供了一套抽象的、易于使用的API,可以简化网络应用的开发过程。
在Netty的应用开发中,选择合适的I/O模型对于程序的性能和扩展性至关重要。常见的I/O模型包括同步阻塞I/O(BIO)和非阻塞I/O(NIO)。本文将对这两种模型进行比较,并介绍它们在Netty中的应用。
## 1.2 目的
本文旨在帮助读者了解Netty中的NIO与BIO的不同,以及在实际应用中如何选择合适的I/O模型。通过对比分析它们在性能、并发处理能力和编程复杂度等方面的差异,读者将能够根据自己的需求和情况做出明智的决策。
总之,选择合适的I/O模型对于Netty应用的稳定性、性能和可扩展性至关重要,本文将为读者提供相关知识和指导,帮助读者做出明确的选择和决策。
# 2. I/O模型概述
在网络编程中,I/O模型是指应用程序与内核进行数据交换的方式。常见的I/O模型有同步阻塞I/O(BIO)、非阻塞I/O(NIO)、多路复用I/O(选择器)、异步I/O等。
#### 2.1 同步阻塞I/O(BIO)
同步阻塞I/O,也称为传统的I/O模型,特点是在进行I/O操作时会阻塞线程直到数据准备好或写入完成。BIO模型通常使用InputStream和OutputStream进行数据的读写操作,操作过程是同步的,即读写过程会阻塞线程直到读写完成。
BIO模型中,每当有客户端请求连接时,服务器端都会创建新的线程来处理该请求,这样导致服务器的资源消耗较大。当并发请求数量增多时,会产生大量的线程,导致服务器性能下降。
#### 2.2 非阻塞I/O(NIO)
非阻塞I/O,也称为新的I/O模型(New I/O),是Netty中常用的一种I/O模型。NIO模型通过使用Selector(选择器)来管理多个通道,从而允许单个线程处理多个通道的并发操作。
NIO模型中引入了Channel(通道)和Buffer(缓冲区)的概念。数据通过Channel进行读写,而不再通过InputStream和OutputStream。Buffer用于读写数据,通过Buffer进行数据的存取操作。
NIO模型的非阻塞特性使得线程在进行I/O操作时不会被阻塞,可以继续处理其他任务,提高了系统的并发处理能力。
NIO模型在应对大量连接的场景下,相比BIO模型有更好的性能表现。
```java
import java.nio.ByteBuffer;
import java.nio.channels.SocketChannel;
public class NioExample {
public static void main(String[] args) throws Exception {
SocketChannel socketChannel = SocketChannel.open();
socketChannel.connect(new InetSocketAddress("localhost", 8080));
ByteBuffer buffer = ByteBuffer.allocate(1024);
buffer.put("Hello, Server".getBytes());
buffer.flip();
while (buffer.hasRemaining()) {
socketChannel.write(buffer);
}
buffer.clear();
int bytesRead = socketChannel.read(buffer);
while (bytesRead != -1) {
buffer.flip();
while (buffer.hasRemaining()) {
System.out.print((char) buffer.get());
}
buffer.clear();
bytesRead = socketChannel.read(buffer);
}
socketChannel.close();
}
}
```
在上述示例中,通过SocketChannel与服务器建立连接,并发送数据。然后循环读取服务器返回的数据,直到读取结束。在此过程中,一个线程可以处理多个通道的读写操作。
### 总结
BIO模型是一种同步阻塞I/O模型,适合于连接数较少且处理时间较短的场景。但在高并发场景下性能较差。
NIO模型是一种非阻塞I/O模型,通过使用Selector管理多个通道的并发操作,提高了系统的并发处理能力。适合于连接数较多的场景。
Netty中使用NIO模型作为默认的I/O模型,可以提供更好的性能和扩展性。
# 3. BIO在Netty中的应用
#### 3.1 BIO的基本原理
BIO(Blocking I/O)是一种同步阻塞的I/O模型,其基本原理是一对一的通信模式。在BIO中,服务器端需要为每个客户端请求创建一个独立的线程进行处理,当有新的客户端请求时,服务器必须创建一个新的线程来处理连接,因此在高并发的情况下,线程创建的数量会非常庞大,造成资源浪费和性能下降。
BIO的工作流程如下:
1. 服务器端通过ServerSocket监听客户端的连接请求。
2. 客户端发起连接请求,服务器端接受请求并创建一个新的线程来处理连接。
3. 服务器端接收到客户端的数据请求后,通过输入流获取数据。
4. 服务器端处理完请求后,通过输出流将响应数据返回给客户端。
5. 客户端通过输入流获取服务器端响应的数据。
#### 3.2 BIO的优点及缺点
##### 3.2.1 优点:
- 简单易用:BIO模型相对简单,易于理解和使用。
- 开发成本低:由于阻塞模式下,每个连接都需要一个独立的线程进行处理,因此编写代码相对简单。
##### 3.2.2 缺点:
- 并发性低:在高并发情况下,由于每个连接都需要一个独立的线程进行处理,线程数量会非常庞大,资源消耗较大,导致系统性能下降。
- 阻塞式I/O:BIO模型中,当接收或发送数据时,如果没有数据可读或写入,线程会被阻塞,造成资源浪费。
#### 3.3 BIO在Netty中的具体应用
尽管BIO模型在性能和并发性方面存在不足,但在某些场景下仍然可以在Netty中使用。例如,在一些并发请求较低的场景,如客户端与服务器之间的简单通信,BIO模型可以提供足够的性能。
在Netty中使用BIO模型,可以通过以下代码实现:
```java
public class BIOEchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
// 接收客户端请求数据
ByteBuf in = (ByteBuf) msg;
try {
byte[] bytes = new byte[in.readableBytes()];
in.readBytes(bytes);
String request = new String(bytes, StandardCharsets.UTF_8);
// 处理请求数据
String response = handleRequest(request);
// 返回响应数据给客户端
ByteBuf out = Unpooled.copiedBuffer(response.getBytes());
ctx.write(out);
ctx.flush();
} finally {
// 释放资源
in.release();
}
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
// 异常处理
cause.printStackTrace();
ctx.close();
}
}
```
在上述代码中,我们使用`ChannelInboundHandlerAdapter`来处理客户端的请求。当有数据到达时,通过`channelRead`方法接收数据,然后调用`handleRequest`方法处理请求,最后通过`ctx.write`将响应数据返回给客户端。
虽然上述代码使用了BIO模型,但是由于Netty的线程模型优化,它仍然能够提供良好的性能和并发处理能力。但需要注意的是,BIO模型仍然存在阻塞问题,因此在高并发情况下仍然可能导致性能下降。
# 4. NIO在Netty中的应用
### 4.1 NIO的基本原理
NIO(New I/O)是Java提供的一种基于通道和缓冲区的I/O模型。与BIO(Blocking I/O)不同,NIO使用了事件驱动和非阻塞的方式进行I/O操作,可以大大提高系统的吞吐量和并发处理能力。
NIO的核心组件包括以下几个部分:
- 通道(Channel):作为数据传输的源头和目的地,可以是文件、网络套接字等。
- 缓冲区(Buffer):用于存储数据的缓冲区域,NIO中的I/O操作都是基于缓冲区进行的。
- 选择器(Selector):用于监控多个通道的状态,可以轮询获取感兴趣的事件。
NIO的基本工作流程如下:
1. 创建一个选择器(Selector),将其注册到感兴趣的通道上。
2. 选择器开始轮询通道的事件,当有事件发生时,选择器会通知相应的处理器进行处理。
3. 处理器根据事件类型进行相应的处理,读取或写入数据到缓冲区。
4. 处理器将缓冲区中的数据写入通道或者从通道中读取数据到缓冲区。
通过使用缓冲区和选择器,NIO可以实现非阻塞的、事件驱动的I/O操作,提高系统的性能和响应能力。
### 4.2 NIO的优点及缺点
NIO相比于BIO具有以下优点:
- 非阻塞:NIO使用了非阻塞的方式进行I/O操作,可以在等待数据到达的同时处理其他任务,提高系统的并发能力。
- 事件驱动:NIO采用了事件驱动的模式,通过选择器轮询通道的事件,可以避免使用多线程同时监听多个通道,减少了线程切换的开销。
- 更少的线程:由于NIO的非阻塞特性,相比BIO需要创建更少的线程来处理请求,节省了系统资源。
然而,NIO也存在一些缺点:
- 复杂性:相比于BIO,NIO的编程模型更加复杂,需要处理更多的细节,编写和维护代码的难度较高。
- 难以处理大量的并发请求:当并发请求较大时,NIO的性能可能会下降,因为需要处理更多的事件和缓冲区操作,增加了系统的开销。
### 4.3 NIO在Netty中的具体应用
Netty是一个高性能、异步事件驱动的网络应用框架,基于NIO提供了易于使用的API,简化了网络编程的复杂性。
在Netty中,NIO被广泛应用于处理网络连接、处理请求和响应等场景。Netty通过使用多线程和线程池,可以处理大量的并发请求,并且能够充分发挥NIO的非阻塞特性。
一些常见的NIO在Netty中的应用场景包括:
- 服务端和客户端的网络连接管理
- 处理网络请求和响应
- 实现高效的协议解析和封装
- 支持长连接和心跳机制
通过使用Netty的NIO模型,可以更好地利用现代计算机的性能,提高系统的吞吐量和并发处理能力。同时,Netty还提供了丰富的工具和组件,避免了使用原生NIO时的一些繁琐和复杂的操作。
```java
// 示例代码:使用Netty实现一个简单的基于NIO的Echo服务器
public class EchoServer {
private static final int PORT = 8888;
public static void main(String[] args) throws Exception {
// 创建EventLoopGroup
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
try {
// 创建ServerBootstrap
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// 添加处理器
pipeline.addLast(new EchoServerHandler());
}
})
.option(ChannelOption.SO_BACKLOG, 128)
.childOption(ChannelOption.SO_KEEPALIVE, true);
// 绑定端口,开始接收传入的连接
ChannelFuture f = b.bind(PORT).sync();
// 阻塞直到服务器关闭
f.channel().closeFuture().sync();
} finally {
// 关闭EventLoopGroup,并释放所有资源
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
// 实现ChannelInboundHandlerAdapter处理器
public class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
// 将接收到的消息发送回客户端
ctx.write(msg);
ctx.flush();
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
// 发生异常时关闭通道
cause.printStackTrace();
ctx.close();
}
}
```
以上示例代码展示了一个简单的基于NIO的Echo服务器,采用Netty框架进行开发。通过创建EventLoopGroup、ServerBootstrap和相关处理器,可以快速搭建一个基于NIO的网络服务器。
总结:NIO在Netty中的应用广泛,通过使用Netty框架可以简化NIO的使用,提供了更高级的API和工具,方便开发者进行网络编程。
# 5. NIO与BIO对比分析
在本章节中,我们将对NIO和BIO进行对比分析,从性能、并发处理能力和编程复杂度三个方面进行评估。
#### 5.1 性能对比
在性能方面,NIO相比于BIO具有更高的性能。原因在于NIO基于事件驱动的方式,可以使用单线程处理多个连接,避免了线程的频繁切换和创建带来的开销。相比之下,BIO每个连接都需要一个独立的线程进行处理,当连接数增多时,线程的开销就会变得非常大。
另外,NIO使用了零拷贝技术,减少了数据在内核空间和用户空间的拷贝次数,提高了数据传输的效率。而BIO每次读写都需要将数据从内核空间拷贝到用户空间,再拷贝回内核空间,增加了额外的开销。
#### 5.2 并发处理能力对比
在并发处理能力方面,NIO相比于BIO具有更好的表现。NIO使用单线程处理多个连接的方式,可以充分利用CPU的性能,同时可以处理成千上万个连接。而BIO每个连接都需要一个独立的线程进行处理,当连接数增多时,线程数量也会呈指数级增长,导致系统资源消耗过大,并且线程切换的开销也会增加。
#### 5.3 编程复杂度对比
在编程复杂度方面,NIO相比于BIO更加复杂。NIO使用了Selector、Channel、Buffer等抽象概念,需要掌握这些概念并进行合理的使用。而BIO则使用简单的输入流和输出流进行操作,更容易理解和上手。
此外,NIO的事件驱动模型需要开发者手动管理事件的处理和状态的追踪,相比之下,BIO通过阻塞方式自动处理事件和状态变更,更加便于编程。
综上所述,NIO在性能和并发处理能力方面具有明显优势,但编程复杂度较高。BIO则在编程复杂度较低的同时,性能和并发处理能力相对较低。
### 6. 在Netty中选择合适的I/O模型
在选择合适的I/O模型时,我们需要根据具体的应用场景进行考虑。如果应用需要处理大量的并发连接,并且对性能要求较高,那么选择NIO是一个不错的选择。但如果应用对并发连接数要求不高,但对编程复杂度有要求,那么选择BIO是一个更简单的选择。
另外,我们还需要考虑迁移成本和团队的技术栈。如果团队已经熟悉了BIO的开发方式,并且系统的架构不需求改变,那么选择BIO可能更加适合。但如果团队对NIO有一定的了解,并且愿意为了性能和扩展性做出一些牺牲,那么选择NIO可能更加合适。
综上所述,选择合适的I/O模型既要考虑到性能和并发处理能力,还需要考虑到编程复杂度和团队技术栈。在使用Netty时,建议根据具体的应用场景进行选择,权衡各种因素,以达到最佳的性能和开发效率。
# 6. 在Netty中选择合适的I/O模型
在Netty中选择合适的I/O模型非常重要,因为不同的应用场景对I/O模型有不同的要求。下面将介绍如何根据具体的情况来选择合适的I/O模型,以及在做出选择时需要考虑的迁移成本及其他因素。
#### 6.1 根据应用场景进行选择
- **低延迟**:如果你的应用对延迟非常敏感,那么应该考虑使用NIO模型。NIO的非阻塞特性能够在单个线程上处理多个连接,减少了线程切换和上下文切换的开销,从而降低了延迟。
- **高并发**:对于需要处理大量并发连接的场景,NIO模型同样是一个不错的选择。NIO通过Selector来管理多个Channel,能够更有效地处理大量连接。
- **简单易用**:如果你更看重编程的简单性和易用性,那么BIO可能更适合你。BIO模型编程简单直观,对于一些连接数较少,并且对性能要求不是特别高的应用来说,BIO也是一个不错的选择。
#### 6.2 迁移成本及考虑因素
在选择合适的I/O模型时,还需要考虑以下因素:
- **现有代码结构**:如果你的系统已经是基于BIO编写的,那么切换到NIO可能需要较大的重构工作。同样地,已经基于NIO的系统要切换到BIO也会面临同样的挑战。
- **性能要求**:根据实际的性能要求,评估NIO和BIO的性能差异。如果性能对你的应用非常重要,那么可能需要进行一些性能测试,以确定使用哪种I/O模型。
- **开发人员熟悉度**:考虑团队成员对于不同I/O模型的熟悉程度,以及学习新模型所需的时间和成本。
综合考虑以上因素,可以更准确地选择适合当前应用的I/O模型。
以上就是在Netty中选择合适的I/O模型的一些建议,希望能够帮助你更好地决定使用何种I/O模型来构建高性能的网络应用程序。
```javascript
// 代码示例:在Node.js中选择合适的I/O模型
// 适用于低延迟的场景,使用NIO模型
if (lowLatencyRequired) {
useNIOModel();
}
// 适用于高并发的场景,使用NIO模型
if (highConcurrencyRequired) {
useNIOModel();
}
// 适用于简单易用的场景,使用BIO模型
if (easeOfUseRequired) {
useBIOModel();
}
```
在上面的示例中,我们根据具体的应用场景来选择合适的I/O模型,这样能够更好地满足应用的性能和开发需求。
### 7. 结论
在结论部分将总结出如何理解以上的I/O介绍,并提供一些建议性的决策方案。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
网络通信框架Netty是一种高性能、可扩展的Java异步网络编程工具,本专栏将深入解析Netty源码,全面剖析其基础概念与架构。文章从NIO与BIO对比与选择开始,讲解Netty在网络通信中的优势,接着介绍如何使用Netty进行简单的网络通信,详解Netty中的事件模型,以及如何实现高效的数据传输。随后,探索Netty在WebSocket通信、HTTP协议解析与应用、SSL与加密通信等方面的应用。此外,也将学习如何使用Netty实现自定义协议,编解码器与序列化的实现原理,内存管理与ByteBuf的解析,以及在高可用与容错设计中的应用。最后,探讨Netty在消息可靠性与事务、分布式系统通信中的应用。通过这些文章的阅读,读者将对Netty有深入的了解,并能够熟练应用于实际项目中。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ADXL362应用实例解析】:掌握在各种项目中的高效部署方法
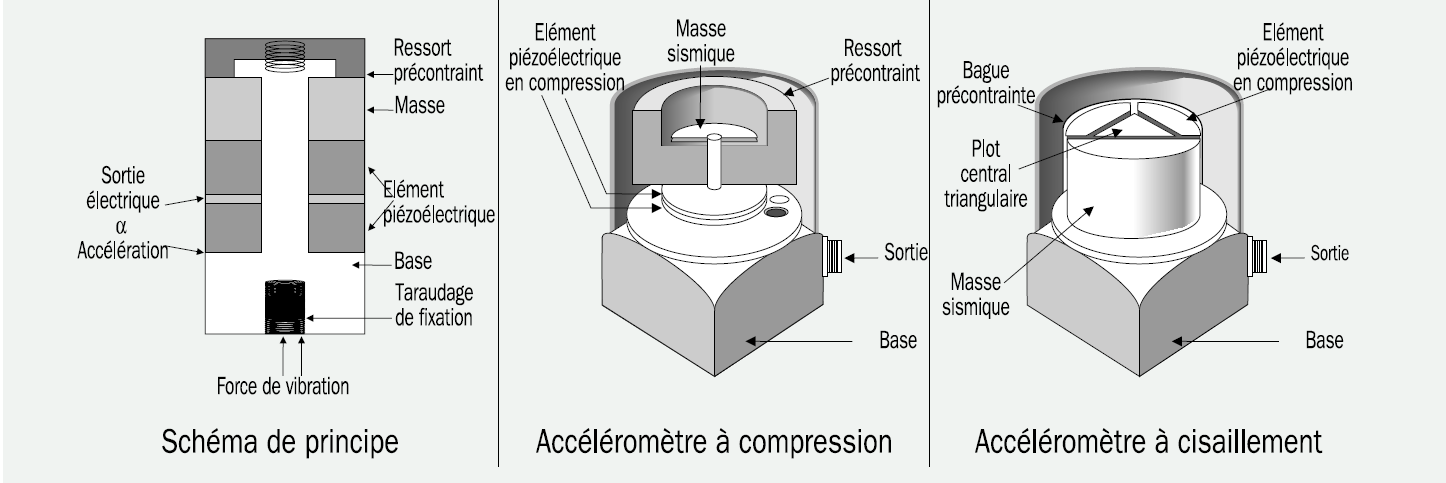
# 摘要
ADXL362是一款先进的低功耗三轴加速度计,广泛应用于多种项目中,包括穿戴设备、自动化系统和物联网设备。本文旨在详细介绍ADXL362的基本概念、硬件集成、数据采集与处理、集成应用以及软件开发和调试,并对未来的发展趋势进行展望。文章首先介绍了ADXL362的特性,并且深入探讨了其硬件集成和配置方法,如电源连接、通信接口连接和配置
【设备充电兼容性深度剖析】:能研BT-C3100如何适应各种设备(兼容性分析)

# 摘要
本文对设备充电兼容性进行了全面分析,特别是针对能研BT-C3100充电器的技术规格和实际兼容性进行了深入研究。首先概述了设备充电兼容性的基础,随后详细分析了能研BT-C3100的芯片和电路设计,充电协议兼容性以及安全保护机制。通过实际测试,本文评估了BT-C3100与多种设备的充电兼容性,包括智能手机、平板电脑、笔记本电脑及特殊设备,并对充电效率和功率管理进行了评估。此外,本文还探讨了BT-C3100的软件与固件
【SAP角色维护进阶指南】:深入权限分配与案例分析

# 摘要
本文全面阐述了SAP系统中角色维护的概念、流程、理论基础以及实践操作。首先介绍了SAP角色的基本概念和角色权限分配的理论基础,包括权限对象和字段的理解以及分配原则和方法。随后,文章详细讲解了角色创建和修改的步骤,权限集合及组合角色的创建管理。进一步,探讨了复杂场景下的权限分配策略,角色维护性能优化的方法,以及案例分析中的问题诊断和解决方案的制定
【CAPL语言深度解析】:专业开发者必备知识指南

# 摘要
本文详细介绍了一种专门用于CAN网络编程和模拟的脚本语言——CAPL(CAN Access Programming Language)。首先,文章介绍了CAPL的基
MATLAB时域分析大揭秘:波形图绘制与解读技巧
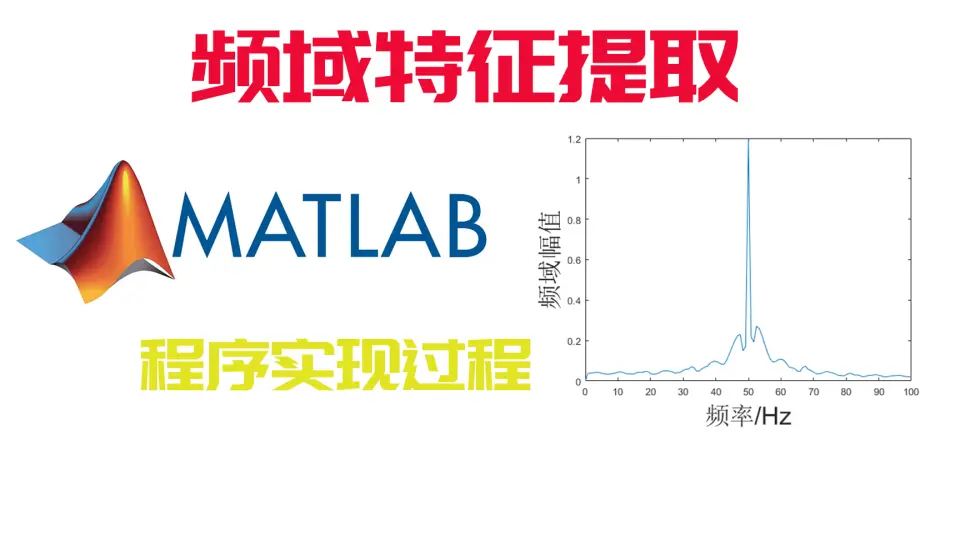
# 摘要
本文详细探讨了MATLAB在时域分析和波形图绘制中的应用,涵盖了波形图的基础理论、绘制方法、数据解读及分析、案例研究和美化导出技巧。首先介绍时域分析的基础知识及其在波形图中的作用,然后深入讲解使用MATLAB绘制波形图的技术,包括基本图形和高级特性的实现。在数据解读方面,本文阐述了波形图的时间和幅度分析、信号测量以及数学处理方法。通过案例研究部分,文章展示了如何应用波形图
汉化质量控制秘诀:OptiSystem组件库翻译后的校对与审核流程

# 摘要
随着软件国际化的需求日益增长,OptiSystem组件库汉化项目的研究显得尤为重要。本文概述了汉化项目的整体流程,包括理论基础、汉化流程优化、质量控制及审核机制。通过对汉化理论的深入分析和翻译质量评价标准的建立,本文提出了一套汉化流程的优化策略,并讨论了翻译校对的实际操作方法。此外,文章详细介绍了汉化组件库
PADS电路设计自动化进阶:logic篇中的脚本编写与信号完整性分析

# 摘要
本文综合介绍PADS电路设计自动化,从基础脚本编写到高级信号完整性分析,详细阐述了PADS Logic的设计流程、脚本编写环境搭建、基本命令以及进阶的复杂设计任务脚本化和性能优化。同时,针对信号完整性问题,本文深入讲解了影响因素、分析工具的使用以及解决策略,提供了高速接口电路设计案例和复杂电路板设计挑战的分析。此外,本文还探讨了自动化脚本与
【Java多线程编程实战】:掌握并行编程的10个秘诀
# 摘要
Java多线程编程是一种提升应用程序性能和响应能力的技术。本文首先介绍了多线程编程的基础知识,随后深入探讨了Java线程模型,包括线程的生命周期、同步机制和通信协作。接着,文章高级应用章节着重于并发工具的使用,如并发集合框架和控制组件,并分析了原子类与内存模型。进一步地,本文讨论了多线程编程模式与实践,包括设计模式的应用、常见错误分析及高性能技术。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )