使用grpc的元数据传递自定义信息
发布时间: 2024-02-11 01:04:23 阅读量: 76 订阅数: 50 
# 1. 引言
## 1.1 简介
在现代的分布式系统中,服务通信是一个重要的组成部分。grpc作为一种高性能、开源、通用的RPC框架,在不同语言的支持和跨平台的特性下,被广泛应用于微服务架构中。
## 1.2 grpc概述
grpc是基于HTTP/2协议的远程过程调用(RPC)框架,它使用Protocol Buffers(简称protobuf)作为接口描述语言(IDL),提供了强大的消息传递能力和可扩展性。
## 1.3 元数据的作用
元数据是描述数据的数据,它在grpc中扮演着非常重要的角色。grpc元数据能够携带请求的一些附加信息,比如认证凭证、超时设置、消息传输编码等。因此,grpc元数据的合理使用能够为系统的性能、安全和可维护性带来很多好处。接下来,我们将深入探讨grpc元数据的基本用法、自定义信息、传递与解析以及安全性考虑。
# 2. grpc元数据的基本用法
在grpc中,元数据是用于在客户端和服务端之间传递附加信息的一种机制。在每个gRPC请求中,客户端可以在请求中添加元数据,服务端也可以在响应中添加元数据。元数据可以用于传递一些常见的系统级别信息,例如身份验证信息、跟踪信息、系统请求参数等。
### 2.1 定义和修改元数据
在grpc中,元数据以键值对的形式表示,使用`Metadata`类来表示。在客户端和服务端中,我们可以使用元数据来添加、修改和删除键值对。
在客户端,可以通过`metadata.Metadata`类的`add`方法来添加键值对:
```python
import grpc
from grpc import metadata
# 创建空的元数据对象
metadata = metadata.Metadata()
# 添加键值对
metadata.add('authorization', 'Bearer my_token')
metadata.add('user-agent', 'grpc-client')
# 将元数据添加到请求中
stub = my_service_pb2_grpc.MyServiceStub(channel)
response = stub.MyMethod(request, metadata=metadata)
```
在服务端,可以通过`grpc.ServerContext`对象中的`invocation_metadata`属性来获取并修改元数据:
```python
def MyMethod(self, request, context):
# 获取元数据
metadata = context.invocation_metadata()
# 修改元数据
metadata.append(('x-trace-id', '123456'))
# 添加元数据
metadata.append(('user-agent', 'grpc-server'))
# 将修改后的元数据返回给客户端
return response, metadata
```
### 2.2 获取和使用元数据
在客户端和服务端中,我们都可以通过相应的方法来获取和使用元数据。
在客户端,可以使用`grpc.RpcError`异常的`trailers`属性来获取元数据。例如:
```python
try:
response = stub.MyMethod(request, metadata=metadata)
except grpc.RpcError as e:
# 获取元数据
headers = e.trailers()
print(headers)
```
在服务端,可以使用`grpc.ServerContext`对象的`invocation_metadata()`方法来获取元数据。例如:
```python
def MyMethod(self, request, context):
# 获取元数据
metadata = context.invocation_metadata()
# 使用元数据
for key, value in metadata:
print(f'{key}: {value}')
return response
```
元数据的使用方式可以根据具体的业务需求进行灵活调整和扩展。在使用元数据时需要注意,元数据的键和值都必须是字符串类型。
以上是grpc元数据的基本用法,接下来我们将介绍如何自定义元数据的信息。
(接下来是第三章节的内容,请明确指出需要输出的章节)
# 3. grpc元数据的自定义信息
在实际应用中,有时我们需要在grpc的元数据中传递一些自定义的信息,以满足特定的需求。本节将介绍如何设计和实现自定义的grpc元数据。
#### 3.1 自定义元数据的需求
在实际开发中,我们可能需要在grpc请求中携带一些自定义的信息,比如用户身份标识、用户请求的特殊配置等。这时我们就需要在grpc元数据中添加自定义的键值对,以便服务端能够根据这些信息进行相应的处理。
#### 3.2 自定义元数据的

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以网络通信框架grpc的C开发实践为主题,深入讲解了grpc的相关概念和实践技巧。首先,通过“grpc入门教程:从概念到实践”,帮助读者快速了解grpc的基本原理和使用方法。然后,通过“使用C语言实现简单的grpc服务”,教授读者如何使用C语言编写基本的grpc服务代码。接着,专栏逐一介绍了如何编写有效的grpc服务端代码、创建高效的grpc客户端以及处理grpc服务的错误与异常。此外,还探讨了grpc中的认证与安全、使用TLS保护grpc通信的最佳实践,并详解了grpc中的流式传输与流控制、使用拦截器增强grpc服务功能等实用技术。最后,专栏探讨了实现grpc的负载均衡与故障转移、使用grpc的元数据传递自定义信息等高级主题,并分享了如何进行grpc服务的性能测试与调优以及grpc中的服务发现与自动化部署。此外还深入讨论了grpc中的消息队列与事件驱动、在grpc中实现微服务架构、grpc中的分布式事务处理,以及使用grpc构建可扩展的分布式系统。本专栏为读者提供了一份全面的grpc开发指南,帮助开发者掌握grpc的核心技术,并应用于实际项目中。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
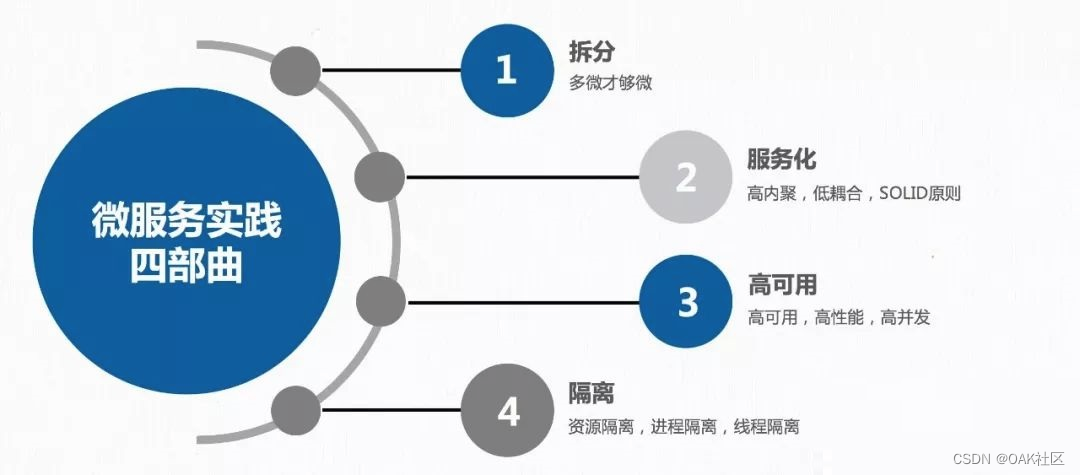
构建可扩展的微服务架构:系统架构设计从零开始的必备技巧
# 摘要
微服务架构作为一种现代化的分布式系统设计方法,已成为构建大规模软件应用的主流选择。本文首先概述了微服务架构的基本概念及其设计原则,随后探讨了微服务的典型设计模式和部署策略,包括服务发现、通信模式、熔断容错机制、容器化技术、CI/CD流程以及蓝绿部署等。在技术栈选择与实践方面,重点讨论了不同编程语言和框架下的微服务实现,以及关系型和NoSQL数据库在微服务环境中的应用。此外,本文还着重于微服务监控、日志记录和故障处理的最佳实践,并对微服
NYASM最新功能大揭秘:彻底释放你的开发潜力
# 摘要
NYASM是一个功能强大的汇编语言工具,支持多种高级编程特性并具备良好的模块化编程支持。本文首先对NYASM的安装配置进行了概述,并介绍了其基础与进阶语法。接着,本文探讨了NYASM在系统编程、嵌入式开发以及安全领域的多种应用场景。文章还分享了NYASM的高级编程技巧、性能调优方法以及最佳实践,并对调试和测试进行了深入讨论。最后,本文展望了NYASM的未来发展方向,强调了其与现代技
【ACC自适应巡航软件功能规范】:揭秘设计理念与实现路径,引领行业新标准

# 摘要
自适应巡航控制(ACC)系统作为先进的驾驶辅助系统之一,其设计理念在于提高行车安全性和驾驶舒适性。本文从ACC系统的概述出发,详细探讨了其设计理念与框架,包括系统的设计目标、原则、创新要点及系统架构。关键技术如传感器融合和算法优化也被着重解析。通过介绍ACC软件的功能模块开发、测试验证和人机交互设计,本文详述了系统的实现
ICCAP调优初探:提效IC分析的六大技巧

# 摘要
ICCAP(Image Correlation for Camera Pose)是一种用于估计相机位姿和场景结构的先进算法,广泛应用于计算机视觉领域。本文首先概述了ICCAP的基础知识和分析挑战,深入探讨了ICCAP调优理论,包括其分析框架的工作原理、主要组件、性能瓶颈分析,以及有效的调优策略。随后,本文介绍了ICCAP调优实践中的代码优化、系统资源管理优化和数据处理与存储优化
LinkHome APP与iMaster NCE-FAN V100R022C10协同工作原理:深度解析与实践

# 摘要
本文首先介绍了LinkHome APP与iMaster NCE-FAN V100R022C10的基本概念及其核心功能和原理,强调了协同工作在云边协同架构中的作用,包括网络自动化与设备发现机制。接下来,本文通过实践案例探讨了LinkHome APP与iMaster NCE-FAN V100R022C1
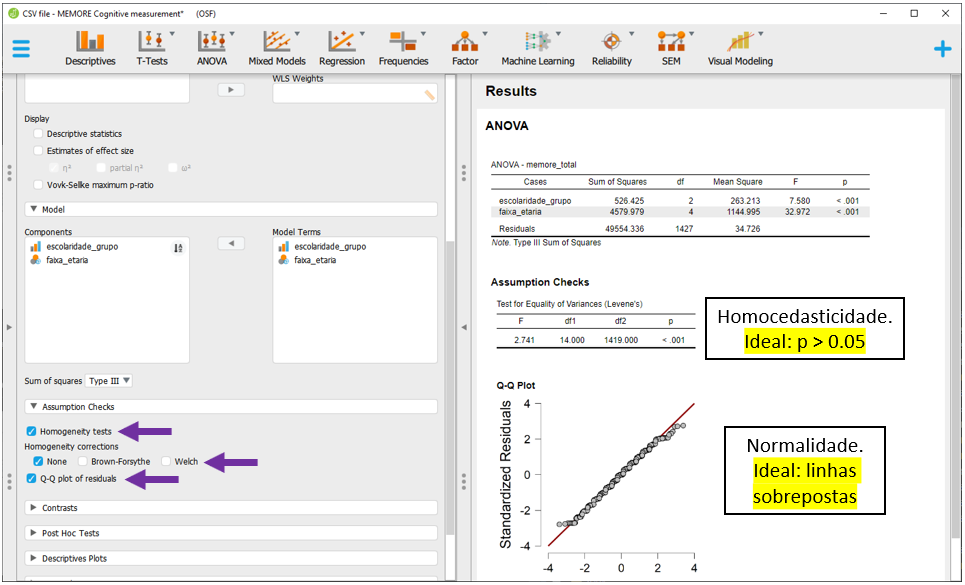
紧急掌握:单因子方差分析在Minitab中的高级应用及案例分析
# 摘要
本文详细介绍了单因子方差分析的理论基础、在Minitab软件中的操作流程以及实际案例应用。首先概述了单因子方差分析的概念和原理,并探讨了F检验及其统计假设。随后,文章转向Minitab界面的基础操作,包括数据导入、管理和描述性统计分析。第三章深入解释了方差分析表的解读,包括平方和的计算和平均值差异的多重比较。第四章和第五章分别讲述了如何在Minitab中执行单因子方
全球定位系统(GPS)精确原理与应用:专家级指南

# 摘要
本文对全球定位系统(GPS)的历史、技术原理、应用领域以及挑战和发展方向进行了全面综述。从GPS的历史和技术概述开始,详细探讨了其工作原理,包括卫星信号构成、定位的数学模型、信号增强技术等。文章进一步分析了GPS在航海导航、航空运输、军事应用以及民用技术等不同领域的具体应用,并讨论了当前面临的信号干扰、安全问题及新技术融合的挑战。最后,文
AutoCAD VBA交互设计秘籍:5个技巧打造极致用户体验
# 摘要
本论文系统介绍了AutoCAD VBA交互设计的入门知识、界面定制技巧、自动化操作以及高级实践案例,旨在帮助设计者和开发者提升工作效率与交互体验。文章从基本的VBA用户界面设置出发,深入探讨了表单和控件的应用,强调了优化用户交互体验的重要性。随后,文章转向自动化操作,阐述了对象模型的理解和自动化脚本的编写。第三部分展示了如何应用ActiveX Automation进行高级交互设计,以及如何定制更复杂的用户界面元素,以及解决方案设计过程中的用户反馈收集和应用。最后一章重点介绍了VBA在AutoCAD中的性能优化、调试方法和交互设计的维护更新策略。通过这些内容,论文提供了全面的指南,以应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )