【Oracle DMP文件导入秘籍】:10个步骤轻松上手,让数据导入不再困难
发布时间: 2024-07-25 18:18:32 阅读量: 176 订阅数: 41 

java-Web项目部署步骤之Oracle数据库导入.dmp文件数据

# 1. Oracle DMP文件导入概述
Oracle数据泵(Data Pump)是Oracle数据库中用于数据导出和导入的强大工具。它提供了一种快速、可靠且灵活的方式,用于在不同的Oracle数据库实例之间移动数据。
DMP文件导入是一种将数据从DMP导出文件中导入到目标数据库中的过程。DMP文件包含从源数据库导出的数据结构和数据,它使用Oracle数据泵导入实用程序(impdp)导入到目标数据库中。
导入DMP文件涉及几个关键步骤,包括导入前准备、导入过程和导入后验证。导入前准备包括检查目标数据库环境、分配导入用户权限等。导入过程涉及使用impdp实用程序和配置导入参数。导入后验证包括检查数据完整性和一致性。
# 2. DMP文件导入理论基础
### 2.1 DMP文件结构与内容
DMP文件是一种二进制文件,由Oracle数据泵导出实用程序生成。它包含从源数据库导出的数据库对象、数据和元数据。DMP文件结构如下:
- **文件头:**包含文件版本、导出时间和数据库信息。
- **元数据段:**包含数据库对象(表、视图、过程等)的定义和属性。
- **数据段:**包含从数据库中导出的实际数据。
- **尾部:**包含文件校验和信息。
### 2.2 Oracle数据泵导出与导入原理
Oracle数据泵导出和导入实用程序是用于在Oracle数据库之间传输数据的工具。它们基于以下原理:
**导出过程:**
1. 数据泵读取源数据库中的对象和数据。
2. 它将对象和数据序列化为二进制格式并写入DMP文件。
3. 导出过程可以并行运行,以提高性能。
**导入过程:**
1. 数据泵从DMP文件读取对象和数据。
2. 它反序列化对象和数据并将其加载到目标数据库中。
3. 导入过程也可以并行运行,以提高性能。
数据泵导出和导入过程通过以下参数进行配置:
- **导出参数:**指定要导出的对象和数据范围。
- **导入参数:**指定要导入到目标数据库中的对象和数据范围,以及导入选项。
通过理解DMP文件结构和Oracle数据泵导出和导入原理,可以更好地规划和执行DMP文件导入操作。
# 3. DMP文件导入实践操作
### 3.1 导入前准备工作
#### 3.1.1 目标数据库环境检查
在导入DMP文件之前,需要对目标数据库环境进行全面的检查,确保其满足导入要求。主要检查项包括:
- **数据库版本兼容性:**目标数据库版本必须与DMP文件导出时使用的数据库版本兼容或更高。
- **表空间可用性:**导入过程中需要足够的空间来存储导入的数据,因此需要检查目标数据库中是否有足够的可用表空间。
- **对象存在性:**DMP文件包含的表、索引、约束等对象在目标数据库中必须不存在,否则会覆盖或冲突。
- **用户权限:**导入用户需要具有目标数据库中的适当权限,包括创建表、索引和加载数据的权限。
#### 3.1.2 导入用户权限分配
导入用户需要具有目标数据库中的以下权限:
- `CREATE TABLE`:创建表
- `CREATE INDEX`:创建索引
- `GRANT`:授予权限
- `IMPORT`:导入数据
如果导入用户不具有这些权限,则需要通过以下语句授予:
```sql
GRANT CREATE TABLE, CREATE INDEX, GRANT, IMPORT TO import_user;
```
### 3.2 导入过程详解
#### 3.2.1 导入命令语法解析
导入DMP文件的基本语法如下:
```sql
impdp username/password@target_database dumpfile=dumpfile_path remap_schema=source_schema:target_schema
```
其中:
- `username/password`:导入用户的用户名和密码
- `target_database`:目标数据库的连接字符串
- `dumpfile_path`:DMP文件路径
- `remap_schema`:指定源模式和目标模式之间的映射关系
#### 3.2.2 导入参数配置优化
为了优化导入性能,可以配置以下参数:
- **parallel=n**:指定导入并行度,n表示并行进程数。
- **buffer=n**:指定缓冲区大小,单位为MB。
- **commit=n**:指定提交频率,n表示每提交多少行数据。
- **estimate=y**:启用估算统计信息,可以提高导入速度。
例如,以下命令使用并行导入和更大的缓冲区:
```sql
impdp username/password@target_database dumpfile=dumpfile_path remap_schema=source_schema:target_schema parallel=4 buffer=100M
```
### 3.3 导入后数据验证
#### 3.3.1 数据完整性检查
导入完成后,需要检查数据的完整性,确保没有数据丢失或损坏。可以执行以下操作:
- **检查行数:**比较导入前后的表行数,确保一致。
- **验证主键:**检查主键列的值是否唯一且不为空。
- **检查外键:**验证外键列的值是否引用了正确的父表。
#### 3.3.2 数据一致性验证
除了数据完整性,还需要验证数据的逻辑一致性,确保数据符合业务规则。可以执行以下操作:
- **比较数据分布:**比较导入前后的数据分布,确保没有异常值或数据偏移。
- **执行业务规则检查:**编写SQL查询或程序来检查数据是否符合特定的业务规则。
- **进行数据分析:**使用数据分析工具或技术来识别数据中的异常或模式。
# 4. DMP文件导入疑难解答
### 4.1 常见导入错误及解决方法
#### 4.1.1 ORA-31693错误
**错误描述:**
ORA-31693: Table data object "表名" failed to load/unload due to media recovery.
**原因:**
导入表包含未提交的事务,并且目标数据库启用了归档日志模式。
**解决方法:**
* 在导出数据库上提交所有未提交的事务。
* 在导入数据库上禁用归档日志模式,然后重新导入数据。
#### 4.1.2 ORA-01452错误
**错误描述:**
ORA-01452: cannot CREATE UNIQUE INDEX because duplicate keys were found
**原因:**
导入的数据中存在重复的主键或唯一键值。
**解决方法:**
* 检查导出数据,确保没有重复的主键或唯一键值。
* 在导入时使用 `IGNORE` 选项忽略重复数据。
### 4.2 导入性能优化技巧
#### 4.2.1 并行导入
**原理:**
并行导入将导入任务分解为多个并行线程,从而提高导入速度。
**配置:**
```
impdp user/password@database parallel=8
```
**参数说明:**
* `parallel`: 并行线程数。
**代码逻辑分析:**
该命令使用 8 个并行线程导入数据,可以显著提高导入速度,尤其是在导入大量数据时。
#### 4.2.2 索引重建优化
**原理:**
在导入数据后,Oracle 会自动重建索引,这可能会消耗大量时间。通过禁用索引重建,可以提高导入速度。
**配置:**
```
impdp user/password@database indexes=n
```
**参数说明:**
* `indexes`: 是否重建索引。
**代码逻辑分析:**
该命令在导入数据时禁用索引重建,可以节省大量时间,尤其是在导入大量数据时。导入完成后,可以手动重建索引。
# 5. DMP文件导入高级应用
### 5.1 增量导入技术
#### 5.1.1 增量导出原理
增量导出是一种导出数据库中特定时间段内发生变更的数据的技术。它通过记录数据库中的变更日志(redo log)来实现。当执行增量导出时,Oracle会根据变更日志来识别和导出自上次导出后发生变更的数据。
增量导出的优点在于:
- 仅导出变更的数据,节省存储空间和导出时间。
- 可以多次增量导出,并合并到一个完整的导出文件中。
- 适用于需要定期导出变更数据的场景,如数据备份、数据迁移等。
#### 5.1.2 增量导入操作步骤
增量导入操作步骤如下:
1. **准备目标数据库:**确保目标数据库具有与源数据库相同的表结构和索引。
2. **增量导出:**在源数据库中执行增量导出操作,生成增量导出文件。
3. **增量导入:**在目标数据库中执行增量导入操作,将增量导出文件导入到目标数据库中。
4. **合并导入:**如果有多个增量导出文件,可以将它们合并到一个完整的导出文件中,然后执行一次性导入操作。
```sql
-- 增量导出命令
expdp user/password directory=dir dumpfile=incr_dump.dmp logfile=incr_dump.log include=CURRENT_SCN start_scn=SCN_START end_scn=SCN_END
-- 增量导入命令
impdp user/password directory=dir dumpfile=incr_dump.dmp logfile=incr_dump.log exclude=STATISTICS
```
### 5.2 数据迁移工具对比
#### 5.2.1 Oracle Data Pump与SQL*Loader对比
| 特性 | Oracle Data Pump | SQL*Loader |
|---|---|---|
| 数据格式 | 二进制格式 | 文本格式 |
| 导出方式 | 并行导出 | 串行导出 |
| 导入方式 | 并行导入 | 串行导入 |
| 数据完整性 | 保证数据完整性 | 不保证数据完整性 |
| 数据一致性 | 保证数据一致性 | 不保证数据一致性 |
| 适用场景 | 大数据量、复杂数据结构的迁移 | 小数据量、简单数据结构的迁移 |
#### 5.2.2 Oracle Data Pump与GoldenGate对比
| 特性 | Oracle Data Pump | GoldenGate |
|---|---|---|
| 数据传输方式 | 离线传输 | 实时传输 |
| 数据一致性 | 强一致性 | 弱一致性 |
| 数据延迟 | 有延迟 | 无延迟 |
| 适用场景 | 数据备份、数据迁移 | 实时数据同步、数据复制 |
**选择建议:**
- 如果需要保证数据完整性和一致性,并且数据量较大,建议使用Oracle Data Pump。
- 如果需要实时数据同步,并且数据量较小,建议使用GoldenGate。
# 6. DMP文件导入最佳实践
### 6.1 导入计划制定
**6.1.1 导入时间选择**
* 选择数据库负载较低的时段进行导入,避免与其他数据库操作冲突。
* 对于大型导入,考虑在非工作时间或周末进行。
**6.1.2 导入资源分配**
* 根据导入数据量和数据库性能,合理分配导入资源。
* 对于大型导入,增加并行度或使用专用服务器。
* 确保目标数据库有足够的存储空间和内存资源。
### 6.2 导入监控与管理
**6.2.1 导入进度跟踪**
* 使用`impdp`命令的`status`参数跟踪导入进度。
* 监控数据库性能指标,如CPU使用率、内存使用率和I/O活动。
**6.2.2 导入日志分析**
* 导入完成后,检查导入日志文件(通常为impdp.log)以查找任何错误或警告。
* 分析日志文件中的性能指标,以识别改进导入过程的潜在优化点。
```mermaid
graph LR
subgraph 导入计划制定
导入时间选择
导入资源分配
end
subgraph 导入监控与管理
导入进度跟踪
导入日志分析
end
```
**提示:**
* 在导入前创建详细的导入计划,包括时间表、资源分配和监控策略。
* 定期监控导入过程,并在必要时进行调整。
* 导入完成后,验证导入数据的完整性和一致性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Oracle DMP 文件导入的方方面面,提供了一系列实用指南和技巧,帮助用户轻松上手并解决常见问题。从导入秘籍到黑匣子原理解析,再到加速秘诀和疑难杂症全攻略,专栏涵盖了导入过程的各个环节。此外,还提供了针对表空间不足、字符集乱码、数据完整性、数据类型转换、并行处理、数据校验、数据恢复、数据迁移、性能监控、与导出、表空间管理、索引管理、权限管理、日志分析以及数据字典等方面的深入分析和解决方案。通过阅读本专栏,用户可以全面掌握 Oracle DMP 文件导入的知识和技能,确保数据导入过程高效、准确和安全。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【LAMMPS初探】:如何快速入门并掌握基本模拟操作

# 摘要
LAMMPS模拟软件因其在分子动力学领域的广泛应用而著称,本文提供了关于如何安装、配置和使用LAMMPS进行基本和高级模拟操作的全面指南。文章首先介绍了LAMMPS的系统环境要求、安装流程以及配置选项,并详细说明了运行环境的设置方法。接着,重点介绍了LAMMPS进行基本模拟操作的核心步骤,包括模拟体系的搭建、势能的选择与计算,以及模拟过程的控制。此外,还探讨了高级模拟技术,如分子动力学进阶应用
安全第一:ELMO驱动器运动控制安全策略详解

# 摘要
ELMO驱动器作为运动控制领域内的关键组件,其安全性能的高低直接影响整个系统的可靠性和安全性。本文首先介绍了ELMO驱动器运动控制的基础知识,进而深入探讨了运动控制系统中的安全理论,包括安全运动控制的定义、原则、硬件组件的作用以及软件层面的安全策略实现。第三章到第五章详细阐述了ELMO驱动器安全功能的实现、案例分析以及实践指导,旨在为技术人
编程新手福音:SGM58031B编程基础与接口介绍

# 摘要
SGM58031B是一款具有广泛编程前景的设备,本文首先对其进行了概述并探讨了其编程的应用前景。接着,详细介绍了SGM58031B的编程基础,包括硬件接口解析、编程语言选择及环境搭建,以及基础编程概念与常用算法的应用。第三章则着重于软件接口和驱动开发,阐述了库文件与API接口、驱动程序的硬件交互原理,及驱动开发的具体流程和技巧。通过实际案例
【流程标准化实战】:构建一致性和可复用性的秘诀

# 摘要
本文系统地探讨了流程标准化的概念、重要性以及在企业级实践中的应用。首先介绍了流程标准化的定义、原则和理论基础,并分析了实现流程标准化所需的方法论和面临的挑战。接着,本文深入讨论了流程标准化的实践工具和技术,包括流程自动化工具的选择、模板设计与应用,以及流程监控和质量保证的策略。进一步地,本文探讨了构建企业级流程标准化体系的策略,涵盖了组织结构的调整、标准化实施
【ER图设计速成课】:从零开始构建保险公司全面数据模型
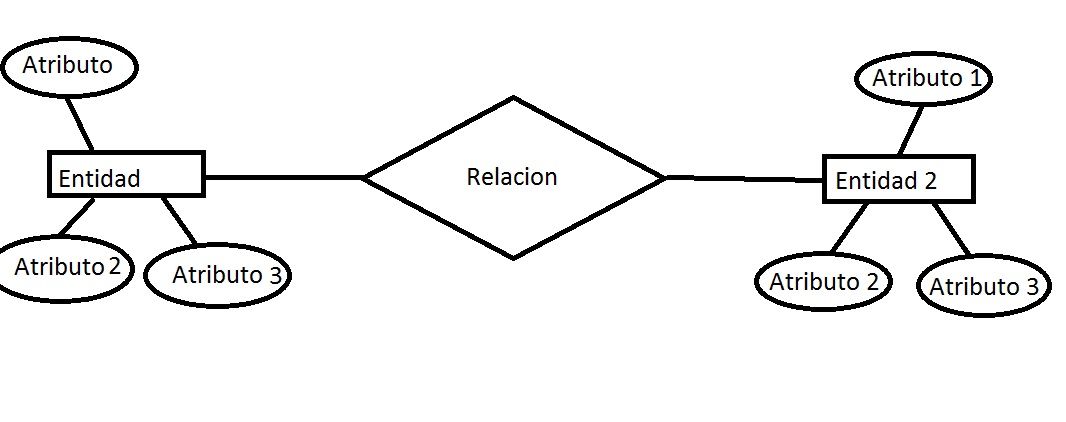
# 摘要
本文详细介绍了实体-关系图(ER图)在保险公司业务流程中的设计和应用。通过理解保险业务流程,识别业务实体与关系,并在此基础上构建全面的数据模型,本文阐述了ER图的基本元素、规范化处理、以及优化调整的策略。文章还讨论了ER图设计实践中的详细实体设计、关系实现和数据模型文档化方法。此外,本文探讨了ER图在数据库设计中的应用,包括ER图到数据库结构的映射、
揭秘Renewal UI:3D技术如何重塑用户体验
![[Renewal UI] Chapter4_3D Inspector.pdf](https://habrastorage.org/getpro/habr/upload_files/bd2/ffc/653/bd2ffc653de64f289cf726ffb19cec69.png)
# 摘要
本文首先介绍了Renewal UI的创新特点及其在三维(3D)技术中的应用。随后,深入探讨了3D技术的基础知识,以及它在用户界面(UI)设计中的作用,包括空间几何、纹理映射、交互式元素设计等。文中分析了Renewal UI在实际应用中的案例,如交互设计实践、用户体验定性分析以及技术实践与项目管理。此外,
【信息化系统建设方案编写入门指南】:从零开始构建你的第一个方案

# 摘要
信息化系统建设是现代企业提升效率和竞争力的关键途径。本文对信息化系统建设进行了全面概述,从需求分析与收集方法开始,详细探讨了如何理解业务需求并确定需求的优先级和范围,以及数据收集的技巧和分析工具。接着,本文深入分析了系统架构设计原则,包括架构类型的确定、设计模式的运用,以及安全性与性能的考量。在实施与部署方面,本文提供了制定实施计划、部署策
【多核与并行构建】:cl.exe并行编译选项及其优化策略,加速构建过程
# 摘要
本文系统地介绍了多核与并行构建的基础知识,重点探讨了cl.exe编译器在多核并行编译中的理论基础和实践
中文版ARINC653:简化开发流程,提升航空系统软件效率

# 摘要
ARINC653标准作为一种航空系统软件架构,提供了模块化设计、时间与空间分区等关键概念,以增强航空系统的安全性和可靠性。本文首先介绍了ARINC653的定义、发展、模块化设计原则及其分区机制的理论基础。接着,探讨了ARINC653的开发流程、所需开发环境和工具,以及实践案例分析。此外,本文还分析了ARINC653在航空系统中的具体应用、软件效率提升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )