【快递行业大数据应用】:洞悉客户需求与服务优化之道
发布时间: 2024-12-04 22:45:33 阅读量: 4 订阅数: 7 
参考资源链接:[快递公司送货策略 数学建模](https://wenku.csdn.net/doc/64a7697db9988108f2fc4e50?spm=1055.2635.3001.10343)
# 1. 快递行业大数据概览
## 1.1 快递行业现状分析
快递行业正经历着前所未有的增长和技术革新。随着电子商务的蓬勃发展,快递服务的需求日益增长,对快递企业的运营效率和准确性提出了更高的要求。大数据技术在快递行业中的应用逐渐成为核心竞争力的一部分,为业务决策提供数据支持,优化运营流程,提升客户服务体验。
## 1.2 大数据在快递行业的角色
大数据技术使得快递公司能够处理和分析海量的物流信息,包括但不限于包裹追踪数据、用户行为数据、运输路线数据等。通过这些数据的深度挖掘,快递企业可以更好地理解市场趋势,预测业务风险,以及优化资源配置。因此,大数据不仅仅是数据分析的工具,更是快递行业持续创新和发展的驱动器。
## 1.3 大数据的挑战与机遇
尽管大数据为快递行业带来了诸多机遇,但是也面临着不少挑战。数据的准确性、实时性和安全性是快递企业需要重点关注的问题。在机遇与挑战并存的环境中,快递行业需要不断创新技术应用,提升数据处理能力,以满足日益增长的市场需求。
# 2. 快递行业数据收集与管理
## 2.1 数据收集的方法和渠道
### 2.1.1 利用传感器和RFID技术
快递行业的大数据收集是一个复杂的过程,涉及到多种数据收集方法。其中一个重要的方法就是利用传感器和RFID技术进行数据的实时收集。传感器可以被安装在运输工具如车辆、无人机等设备上,以收集关于位置、温度、湿度等环境数据,确保货物在整个运输过程中的安全和质量。RFID(无线射频识别)技术可以用于跟踪包裹状态,通过无线信号自动识别目标对象并获取相关数据。
下面是一个简单的示例代码块,演示如何在某个快递包裹上贴上RFID标签,并使用RFID读取器获取包裹的实时数据:
```python
import RFIDReader
from RFIDTags import Tag
# 初始化RFID读取器
rfid_reader = RFIDReader.initialize()
# 定义标签检测回调函数
def on_tag_detected(tag_id):
print(f"Detected RFID tag with ID: {tag_id}")
# 这里可以根据tag_id获取包裹的相关信息并进行后续处理
# ...
# 开始检测RFID标签
rfid_reader.scan(on_tag_detected)
# 运行检测程序直到按下Ctrl+C终止
try:
while True:
pass
except KeyboardInterrupt:
rfid_reader.stop_scan()
```
在上述代码中,`RFIDReader` 是一个虚构的模块,用于表示RFID读取器的初始化和操作。当RFID标签被检测到时,会调用 `on_tag_detected` 函数,并打印出标签的ID。实际应用中,检测到的标签ID可用来查询数据库,获取相应的包裹信息和物流状态。
传感器和RFID技术的应用为快递行业提供了实时数据收集的能力,这些数据对于优化运输路线、预测交货时间、确保货物安全和质量至关重要。
### 2.1.2 用户交互数据的采集
快递服务中用户交互数据的采集同样不可忽视。这包括用户的在线查询记录、使用智能手机应用程序跟踪包裹的活动以及客户服务请求等。这些数据有助于了解客户的需求和偏好,从而提供更加个性化和高效的服务。
例如,可以使用Python编写一个简单的脚本来分析用户通过网页查询包裹的频率和时间段,代码如下:
```python
import requests
from datetime import datetime
# 假设这是用户查询包裹的API端点
TRACKING_API_URL = "https://api.example.com/track包裹ID"
# 用户查询记录字典,键为日期,值为该日期的查询次数
user_queries = {}
def fetch_tracking_data(tracking_id):
# 发送请求到包裹跟踪API
response = requests.get(f"{TRACKING_API_URL}/{tracking_id}")
if response.status_code == 200:
# 假设返回的数据中包含查询时间
query_time = datetime.strptime(response.json()["query_time"], "%Y-%m-%d %H:%M:%S")
date_key = query_time.strftime("%Y-%m-%d")
user_queries[date_key] = user_queries.get(date_key, 0) + 1
print(f"查询包裹 {tracking_id} 在 {query_time.strftime('%Y-%m-%d %H:%M:%S')}")
# 假设有一批跟踪ID需要查询
tracking_ids = ["123456789", "987654321", "1122334455"]
for tracking_id in tracking_ids:
fetch_tracking_data(tracking_id)
# 输出每天的查询次数
for date, count in user_queries.items():
print(f"日期 {date}: 查询次数 {count}")
```
在这个例子中,我们模拟了向一个假设的API发送请求来获取包裹跟踪数据,并记录查询的时间戳。通过分析这些数据,快递公司可以发现用户活跃的高峰时间段,据此优化服务器的负载和响应速度。
通过用户的在线行为分析,快递企业可以更好地理解用户的需要和预期,从而提升服务质量和用户满意度。
## 2.2 数据存储与安全
### 2.2.1 大数据存储解决方案
为了支持高速、大数据量的快递行业数据处理,需要采用高效且可扩展的存储解决方案。在当今的大数据环境中,分布式文件系统如Hadoop的HDFS或者云存储服务如Amazon S3和Azure Blob Storage等,都是常见的选择。这些解决方案能够提供可靠的、高吞吐量的数据存储,同时保持数据的高可用性和容错性。
考虑到存储效率和数据冗余,可以采用类似下面的代码示例来演示如何将数据存储到Hadoop HDFS中:
```bash
hadoop fs -put /local/path/to/data.txt /hdfs/path/to/destination/data.txt
```
上述命令将本地文件系统中的`data.txt`文件上传到HDFS的指定路径。在HDFS中,数据被切割成多个块,分布存储在不同的节点上,以实现数据的高可用性和容错性。这对于存储和处理来自快递行业的海量数据集至关重要。
此外,需要优化数据存储的结构和索引,以便于后续的数据分析和查询操作。
### 2.2.2 数据安全和隐私保护措施
在处理大量的用户数据时,快递公司必须遵守相关的数据保护法规,如GDPR或中国的个人信息保护法(PIPL)。这就要求快递公司不仅需要有强大的数据存储能力,还要保证数据的安全和隐私性。
数据加密是快递公司需要采用的基本数据安全措施之一。通过加密算法,即使数据被未授权的人获取,也无法轻易解读。此外,为了防止数据泄露,还可以采用数据脱敏技术,将敏感信息如姓名、电话号码等替换为不可识别的符号。
下面是一个使用Python进行简单数据脱敏的例子:
```python
from faker import Faker
from sklearn.preprocessing import LabelEncoder
# 假设这是我们需要脱敏的用户信息列表
user_data = [
{"name": "张三", "phone": "13800138000"},
{"name": "李四", "phone": "13900139000"},
# ...
]
# 使用faker生成随机姓名进行替换
fake_names = Faker()
label_encoder = LabelEncoder()
for entry in user_data:
entry["name"] = fake_names.name()
# 电话号码也使用LabelEncoder进行脱敏处理
entry["phone"] = label_encoder.fit_transform([entry["phone"]])[0]
# 输出脱敏后的数据
print(user_data)
```
在上述代码中,我们使用了`Faker`库来生成随机姓名替换真实的姓名,同时使用`LabelEncoder`来转换电话号码。这样可以保护用户隐私,同时保证了数据结构在后续处理中的完整性。
## 2.3 数据整合与预处理
### 2.3.1 跨平台数据集成技术
快递行业需要从多个来源集成数据,包括在线订单系统、运输管理系统、仓储管理系统等。跨平台数据集成技术能帮助企业在不同系统之间同步和共享数据。常见的数据集成工具包括ETL(Extract, Transform, Load)工具、数据集成平台等。
下面是一个简单的ETL流程示例,用于处理和加载数据到数据仓库:
```mermaid
graph LR
A[开始] --> B[数据提取]
B --> C[数据清洗]
C --> D[数据转换]
D --> E[数据加载]
E --> F[数据仓库]
```
在这个流程中:
- **数据提取**:从各个源系统中提取数据,可能是数据库、API或者文件等格式。
- **数据清洗**:使用SQL查询或脚本处理缺失值、异常值、重复记录等。
- **数据转换**:将数据转换成适合分析的格式,如日期格式统一化、货币单位转换等。
- **数据加载**:将清洗和转换后的数据加载到数据仓库或数据湖中供进一步分析。
### 2.3.2 数据清洗和格式化方法
数据清洗是数据分析前的一个重要步骤。它包括识别并修正错误的数据、填充缺失值、纠正数据格式不一致等问题。数据清洗可以

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了快递公司送货策略建模的方方面面。从图论优化送货路径,到需求预测提升供应协调,再到智能分拣和配送系统提升效率,专栏提供了全面的指南。此外,专栏还探讨了大数据应用、可持续送货、成本效益分析、时效性提升、自动化仓库技术、包装优化和服务质量管理标准等重要主题。通过这些深入的见解,专栏旨在帮助快递公司优化送货策略,提升服务质量,并实现可持续发展和成本效益的双重目标。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数字系统设计:层次化方法与实践技巧
参考资源链接:[John F.Wakerly《数字设计原理与实践》第四版课后答案汇总](https://wenku.csdn.net/doc/7bj643bmz0?spm=1055.2635.3001.10343)
# 1. 数字系统设计概述
## 1.1 概念与背景
数字系统设计是IT行业中的一个重要领域,它涉及到使用数字技术来实现信息处理和管理的各种系统。这种设计不仅包括硬件设计,也包括软件的设计和集成,其目标在于构建可靠、高效的系统,满足不同应用的需求。
## 1.2 设计的范围与重要性
数字系统设计的范围非常广泛,从嵌入式系统到复杂的数据中心架构,每一个项目都需要经过精心规划和设计
【中兴光猫配置文件加密解密工具的故障排除】:解决常见问题的5大策略
参考资源链接:[中兴光猫cfg文件加密解密工具ctce8_cfg_tool使用指南](https://wenku.csdn.net/doc/obihrdayhx?spm=1055.2635.3001.10343)
# 1. 光猫配置文件加密解密概述
随着网络技术的快速发展,光猫设备在数据通信中的角色愈发重要。配置文件的安全性成为网络运营的焦点之一。本章将对光猫配置文件的加密与解密技术进行概述,为后续的故障排查和优化策略打下基础。
## 1.1 加密解密技术的重要性
加密解密技术是确保光猫设备配置文件安全的核心。通过数据加密,可以有效防止敏感信息泄露,保障网络通信的安全性和数据的完整性。本
【HOLLiAS MACS V6.5.2数据安全宝典】:系统备份与恢复的最佳实践

参考资源链接:[HOLLiAS MACS V6.5.2用户操作手册:2013版权,全面指南](https://wenku.csdn.net/doc/6412b6bfbe7fbd1778d47d3b?spm=1055.2635.3001.10343)
# 1. 数据安全的重要性与备份概念
## 1.1 信息时代的挑战
随着数字化进程的加速,企
【光刻技术的未来】:从传统到EUV的技术演进与应用
参考资源链接:[Fundamentals of Microelectronics [Behzad Razavi]习题解答](https://wenku.csdn.net/doc/6412b499be7fbd1778d40270?spm=1055.2635.3001.10343)
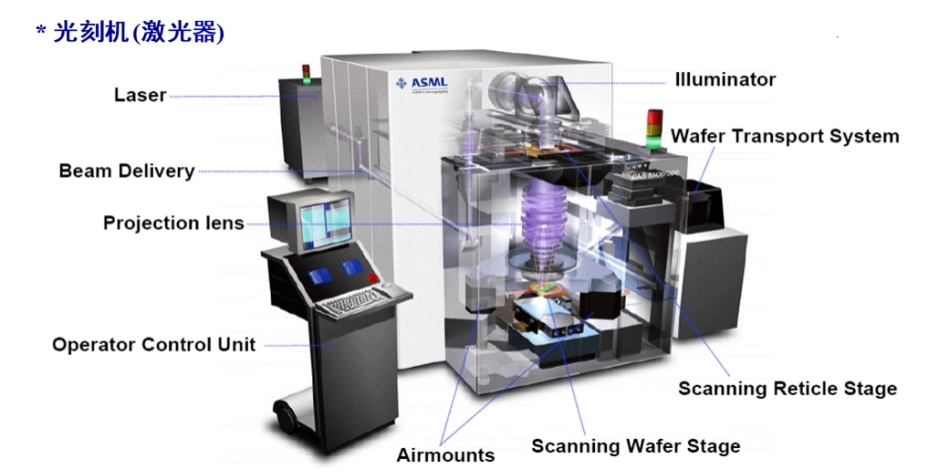
# 1. 光刻技术概述
## 1.1 光刻技术简介
光刻技术是半导体制造中不可或缺的工艺,它使用光学或电子束来在硅片表面精确地复
Trace Pro 3.0 优化策略:提高光学系统性能和效率的专家建议

参考资源链接:[TracePro 3.0 中文使用手册:光学分析与光线追迹](https://wenku.csdn.net/doc/1nx4bpuo99?spm=1055.2635.3001.10343)
# 1. Trace Pro 3.0 简介与基础
## 1.1 Trace Pro 3.0 概述
Trace Pro 3.
状态机与控制单元:Logisim实验复杂数据操作管理
参考资源链接:[Logisim实验教程:海明编码与解码技术解析](https://wenku.csdn.net/doc/58sgw98wd0?spm=1055.2635.3001.10343)
# 1. 状态机与控制单元的理论基础
状态机是一种计算模型,它能够通过一系列状态和在这些状态之间的转移来表示对象的行为。它是控制单元设计的核心理论之一,用于处理各种
74LS181的电源管理与热设计:确保系统稳定运行的要点
参考资源链接:[4位运算功能验证:74LS181 ALU与逻辑运算实验详解](https://wenku.csdn.net/doc/2dn8i4v6g4?spm=1055.2635.3001.10343)
# 1. 74LS181的基本介绍和应用范围
## 1.1 74LS181概述
74LS181是一款广泛使用的4位算术逻辑单元(ALU),具有16种功能,它能执行多个逻辑和算术操作。LS181内部包含一个4位二进制全
奇异值分解(SVD):数据分析的高级应用技术揭秘
参考资源链接:[东南大学_孙志忠_《数值分析》全部答案](https://wenku.csdn.net/doc/64853187619bb054bf3c6ce6?spm=1055.2635.3001.10343)
# 1. 奇异值分解的基本概念和数学原理
在本章中,我们将深入探究奇异值分解(SVD)的基础知识,这是理解SVD在数据分析中应用的关
QN8035芯片PCB布局技巧:电磁兼容性优化指南(专业性+实用型)
参考资源链接:[QN8035 MSOP收音机芯片硬件设计手册](https://wenku.csdn.net/doc/64783ada543f84448813bcf9?spm=1055.2635.3001.10343)
# 1. QN8035芯片概述与电磁兼容性基础
## 1.1 QN8035芯片概述
QN8035芯片是一款广泛应用于智能设备中的高效能处理器。它拥有强大的数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )