使用Flask Blueprint进行模块化开发
发布时间: 2024-01-08 04:42:54 阅读量: 41 订阅数: 44 
# 1. 介绍
## 1.1 什么是Flask Blueprint
Flask Blueprint是Flask框架中用于实现模块化开发的工具。它允许开发者将一个应用拆分成多个独立的模块,并且每个模块都可以有自己的路由、视图函数和静态文件等。
使用Flask Blueprint可以更好地组织和管理大型项目的代码结构,提高代码的可维护性和可扩展性。通过将不同功能的模块以蓝图的形式注册到核心应用中,可以实现代码的解耦和复用。
## 1.2 模块化开发的优势
模块化开发是一种将应用划分成多个模块的开发方法。与传统的单体应用开发相比,模块化开发具有以下优势:
- **代码复用性**:每个模块都是独立的,可以在不同的项目中被复用,减少重复编写代码的工作量。
- **可维护性**:每个模块有自己的职责和功能,易于理解和维护。当需求发生变化时,只需要修改对应模块的代码,不会影响其他模块的工作。
- **团队协作**:不同的开发人员可以独立地开发、测试和维护不同模块的代码,提高团队的工作效率。
- **可扩展性**:通过添加、删除或替换模块,可以轻松地扩展应用的功能,满足不同的需求。
## 1.3 本文的主要内容
本文将介绍如何使用Flask Blueprint进行模块化开发。首先会搭建一个基本的Flask应用,并配置好相关环境。然后会详细讲解如何创建一个Flask Blueprint模块,并实现模块功能。接下来,将重点讲解如何进行模块化路由注册,防止路由冲突并实现模块间的通信。最后,将介绍如何将模块独立部署,以及解决在独立部署中可能遇到的一些问题。
希望通过本文的学习,读者能够掌握使用Flask Blueprint进行模块化开发的方法和技巧,提高自己在Web应用开发中的能力和水平。
# 2. 搭建Flask应用
在开始使用Flask Blueprint进行模块化开发之前,我们首先需要搭建一个Flask应用作为基础。
#### 2.1 创建Flask应用
首先,我们需要创建一个虚拟环境,以隔离依赖库的版本,并确保项目的独立性。在命令行中执行以下命令:
```
$ python3 -m venv myenv
```
然后,激活虚拟环境:
```
$ source myenv/bin/activate
```
接下来,使用pip安装Flask库:
```
(myenv) $ pip install Flask
```
创建一个名为`app.py`的Python文件,并在其中导入Flask库:
```python
from flask import Flask
# 创建Flask应用
app = Flask(__name__)
# 启动应用
if __name__ == "__main__":
app.run()
```
#### 2.2 配置Flask应用
在搭建Flask应用时,我们通常需要进行一些配置,例如设置数据库连接、设置静态文件路径等。创建一个名为`config.py`的Python文件,并添加以下配置项:
```python
# 配置项
DEBUG = True
SECRET_KEY = "your-secret-key"
DATABASE_URI = "your-database-uri"
STATIC_FOLDER = "static"
```
然后,在`app.py`文件中导入并使用配置:
```python
from flask import Flask
# 导入配置
from config import DEBUG, SECRET_KEY, DATABASE_URI, STATIC_FOLDER
# 创建Flask应用
app = Flask(__name__)
# 配置应用
app.config["DEBUG"] = DEBUG
app.config["SECRET_KEY"] = SECRET_KEY
app.config["SQLALCHEMY_DATABASE_URI"] = DATABASE_URI
app.static_folder = STATIC_FOLDER
# 启动应用
if __name__ == "__main__":
app.run()
```
#### 2.3 注册Blueprint
现在,我们已经创建了一个基本的Flask应用,并进行了配置。接下来,我们将使用Flask Blueprint来实现模块化开发。
首先,创建一个名为`blueprints`的文件夹,在该文件夹下创建一个名为`blog`的文件夹,用于存放博客模块相关代码。
在`blueprints/blog`文件夹中,创建一个名为`__init__.py`的Python文件,用于初始化Blueprint:
```python
from flask import Blueprint
# 创建Blog Blueprint
blog_bp = Blueprint("blog", __name__)
# 导入模块路由
from . import routes
```
在同一文件夹中,创建一个名为`routes.py`的Python文件,用于定义模块的路由:
```python
from flask import jsonify
# 导入Blog Blueprint
from . import blog_bp
# 定义模块路由
@blog_bp.route("/blog")
def get
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
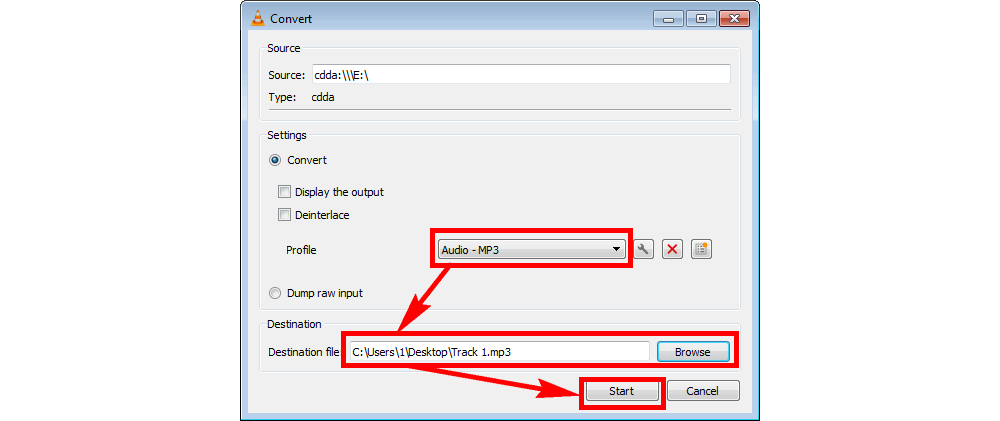
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
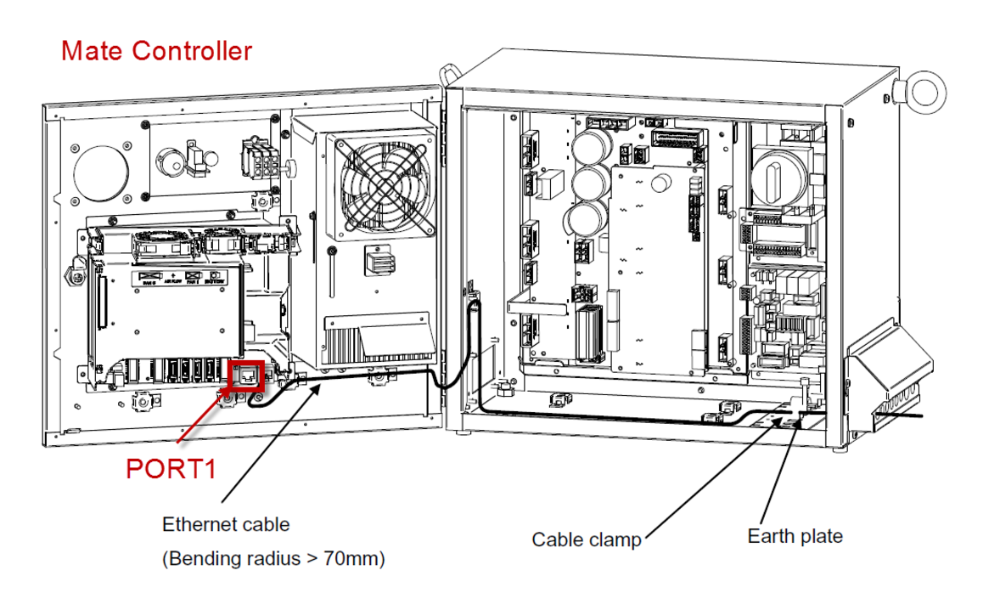
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
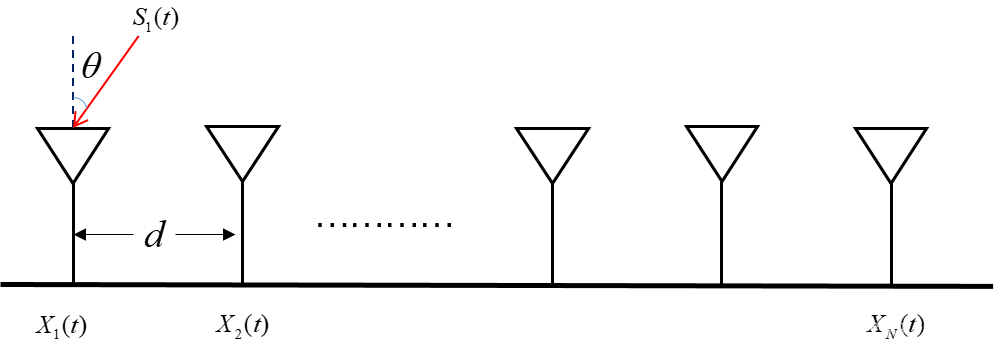
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
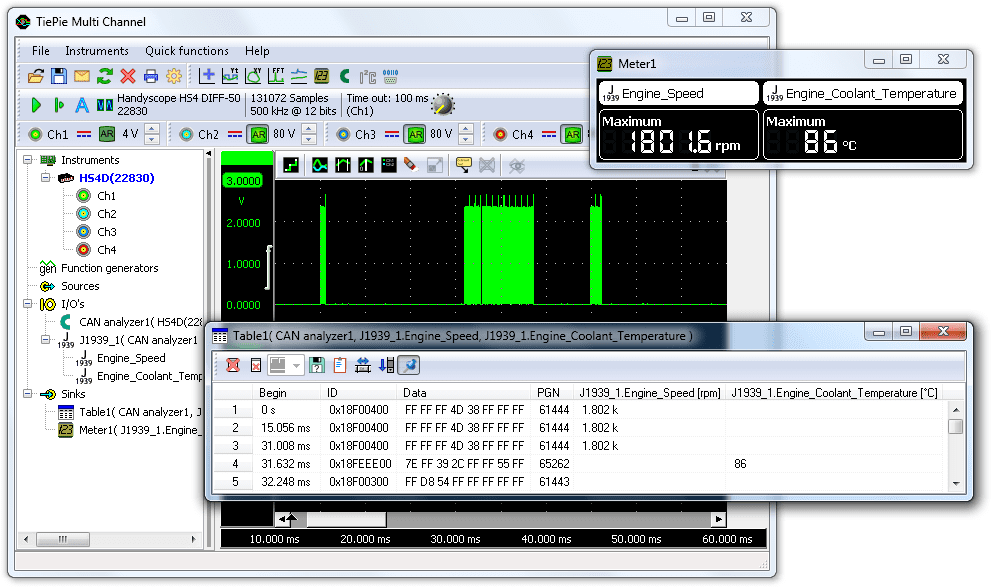
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )