Guava的Preconditions类:防御性编程的核心策略
发布时间: 2024-09-26 21:58:01 阅读量: 40 订阅数: 26 

# 1. 防御性编程与Preconditions类概述
在软件开发领域,防御性编程是一种编程范式,旨在提前预测和防止潜在的错误和异常情况。它强调的是构建健壮的代码,而不是假设外部输入或者系统调用总是正确的。防御性编程策略的一个核心组成部分是Preconditions类,这在编程实践中是实现防御性编程的常见手段。Preconditions类是定义在程序中的一系列规则,这些规则用于在执行操作前验证函数或方法参数的有效性。其核心思想是:只有当所有条件满足时,函数才会继续执行;否则,会抛出异常或进行其他错误处理动作,从而避免错误在程序中传播。在本章节中,我们将对防御性编程进行概述,解释它的重要性,以及Preconditions类在其中扮演的关键角色。
# 2. Preconditions类的理论基础
## 2.1 防御性编程的重要性
### 2.1.1 防御性编程概念解析
防御性编程是一种编程范式,其核心思想是在编写代码时就考虑到错误处理和异常情况,尽可能地在源头消除bug,提高软件的健壮性。它要求开发者不仅编写代码来完成指定的功能,还要确保代码能够应对各种非预期的输入和运行时异常。
防御性编程主要通过以下几种策略实现:
- **断言(Assertions)**: 使用断言来检查程序在运行时是否满足某些条件,如果条件不满足,则立即停止执行。
- **异常处理(Exception Handling)**: 使用异常机制来处理程序运行时可能遇到的错误情况,使程序能够从错误中恢复。
- **边界值检查**: 在程序的输入、输出或者算法处理中,对边界值进行重点检查,防止因边界问题导致的错误。
### 2.1.2 防御性编程与软件质量
软件质量是衡量软件产品是否满足需求规格的重要指标。高质量的软件往往具备高可靠性、易维护性、易测试性和易用性等特点。防御性编程通过提前预防错误,减少了软件运行时发生故障的可能性,从而直接提升了软件质量。
实现防御性编程需要考虑以下几点:
- **代码可读性**: 代码清晰易懂,维护和重构更加方便。
- **代码可维护性**: 通过规范化和模块化,使得软件在遇到问题时可以快速定位和修复。
- **代码可测试性**: 通过设计测试用例并让代码易于测试,可以持续保证代码质量。
## 2.2 Preconditions类在防御性编程中的角色
### 2.2.1 类的定位与作用
在Java编程语言中,`Preconditions`类是一个被广泛使用的工具类,专门用来在方法执行前进行参数校验,保证方法接收到的数据是合法的,从而避免在方法体内进行大量的参数检查,提高代码的可读性和可维护性。
`Preconditions`类通过提供一系列的静态方法,简化了参数校验的过程。例如,`checkNotNull`方法用于校验参数是否为非空,`checkArgument`方法用于校验给定的表达式是否为真。
### 2.2.2 设计哲学和最佳实践
`Preconditions`类的设计哲学在于将参数校验集中管理,使得开发者可以聚焦于业务逻辑的实现。其最佳实践包括:
- **尽早失败(Early Return)**: 一旦发现输入参数不满足要求,立即返回错误信息,避免进一步的执行。
- **可读性**: 使用明确的方法命名和参数命名,使得校验逻辑清晰,便于阅读和理解。
- **异常信息丰富**: 当参数校验失败时,提供详细的异常信息,帮助开发者快速定位问题。
- **重用性**: 避免在代码中重复编写相同的参数校验逻辑,使用`Preconditions`类进行集中管理。
接下来,我们将深入了解`Preconditions`类的核心方法,并探讨如何在实践中应用这些方法,确保代码的健壮性和质量。
# 3. Preconditions类核心方法详解
Preconditions类作为防御性编程的实践者提供了丰富的核心方法,为参数校验提供了便利。本章节将详细介绍参数校验的常见场景,以及如何使用Preconditions类以及如何处理预期与实际的差异。
## 3.1 参数校验的常见场景
### 3.1.1 非空检查
非空检查是防御性编程中最为常见的参数校验场景之一,目的是确保在方法执行前,相关的输入参数不为null,从而避免在后续操作中抛出NullPointerException。
```java
Preconditions.checkNotNull(myObject, "Input parameter myObject cannot be null.");
```
在上述代码中,如果`myObject`为null,将会抛出一个`NullPointerException`,异常信息为"Input parameter myObject cannot be null."。这使得开发者能立即知晓哪个参数违反了非空预设,便于快速定位问题。
### 3.1.2 范围校验
范围校验是对参数的取值范围进行检查,常用于确保数值或者字符串等符合业务逻辑的范围要求。例如,校验年龄是否在合理范围内:
```java
Preconditions.checkArgument(age >= 0 && age <= 150, "Age must be between 0 and 150.");
```
如果`age`参数不在0到150之间,将抛出`IllegalArgumentException`,提示"Age must be between 0 and 150.",这有助于防止不合理的数据对系统造成影响。
## 3.2 Preconditions类的使用示例
### 3.2.1 基本使用方法
使用Preconditions类的基本方法非常简单,主要包括非空校验和参数有效性的校验。基本的使用模板如下:
```java
public void myMethod(YourClass arg) {
Preconditions.checkNotNull(arg, "arg cannot be null");
Preconditions.checkArgument(arg.isValid(), "arg must be valid");
// 方法内部逻辑
}
```
### 3.2.2 自定义异常信息
在实际开发中,常常需要向调用者提供更加具体的错误信息,这时可以自定义异常信息:
```java
public void myMethod(String input) {
if (input == null || input.trim().isEmpty()) {
throw new IllegalArgumentException("Input cannot be null or empty.");
}
// 方法内部逻辑
}
```
自定义异常信息允许开发者根据实际情况提供更丰富的上下文信息,有助于调试和问题定位。
## 3.3 预期与实际的差异处理
### 3.3.1 异常抛出策略
异常抛出策略包括定义何时抛出什么类型的异常,以及如何处理这些异常。以下是常见的一种策略:
```java
public class MyService {
public void processRequest(Request request) throws ProcessingException {
try {
// 预处理逻辑
// 核心处理
if (request == null) {
throw new IllegalArgumentException("Request cannot be null.");
}
// 后处理逻辑
} catch (IllegalArgumentException e) {
throw new ProcessingException("Processing failed due to invalid request.", e);
}
}
}
```
在上述代码中,根据方法中的业务逻辑,我们定义了当请求参数`request`为null时抛出`IllegalArgumentException`,并将其封装在一个自定义的`ProcessingException`中。这使异常处理更加具体,并有助于在更宽的上下文中分析错误。
### 3.3.2 错误信息的传递与处理
错误信息的传递与处理是确保系统稳定运行的关键。良好的错误处理机制能够将错误信息精确地传递给调用者,同时也要注意错误信息的敏感性,防止信息泄露。例如:
```java
public class PreconditionFailedException extends RuntimeException {
public PreconditionFailedException(String message) {
super(message);
}
public PreconditionFailedException(String message, Throwable cause) {
super(message, cause);
}
}
// 在方法中使用
if (!isValidInput(inpu
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《com.google.common.util.concurrent 库入门介绍与使用》专栏深入解析了 Guava 库中用于并发编程的组件,提供了 20 个核心组件的使用技巧和最佳实践。专栏涵盖了各种主题,包括:
* ListenableFuture:简化异步编程
* RateLimiter:实现流量控制
* Cache:优化本地缓存
* EventBus:实现事件驱动架构
* ServiceManager:管理服务生命周期
* Strimzi:构建高可用消息系统
* Hashing:构建强健的哈希解决方案
* Multimap:高级集合操作
* Optional:避免空指针异常
* Preconditions:防御性编程
* Enums:高级枚举操作
* AtomicDouble:高效原子操作
* RangeSet 和 RangeMap:区间数据结构
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Hi3798MV310芯片实战攻略】:从入门到精通,解锁多媒体处理及应用领域的全部秘密

# 摘要
Hi3798MV310芯片是一款专为多媒体处理而设计的高性能处理器,涵盖了从理论基础到实际应用的全方位内容。本文首先对Hi3798MV310芯片进行了概览,接着深入探讨了多媒体处理的理论和技术,包括数据格
深入揭秘ZYNQ架构:混合信号处理的艺术与系统级芯片设计技巧
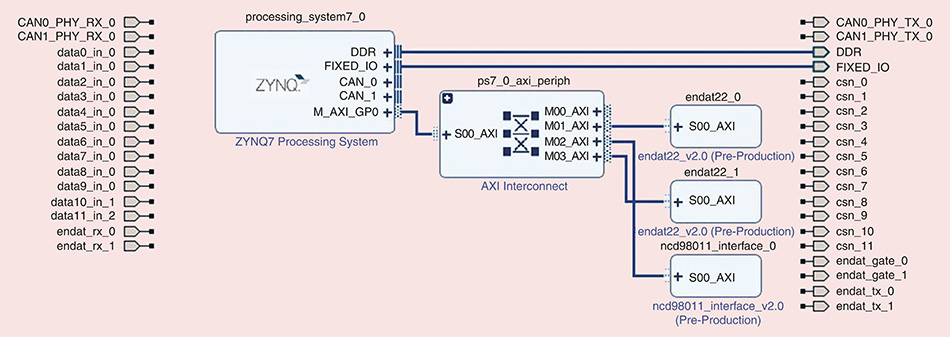
# 摘要
本文综述了ZYNQ架构的优势、基础组件、互连结构以及软件支持,详细解析了ZYNQ在混合信号处理方面的应用,包括模拟与数字信号处理的基础理论和ZYNQ平台的具体实现方式,并通过案例分析进一步阐述了其在实际应用中的表现。此外,本文还探讨了系统级芯片设计的技巧和优化策略,重点介绍了ZYNQ在
【快速掌握】TSC条码打印机基础教程:条码打印原理与操作大全

# 摘要
TSC条码打印机在现代商业和工业领域扮演着至关重要的角色,通过提供准确、高效的条码打印服务,它简化了信息追踪和管理流程。本文首先介绍了TSC条码打印机的基本概念和组成部分,随后深入讲解了条码的构成基础、印刷技术以及解码原理。文章还提供了一份详尽的操作指南,涵盖了硬件安装、软件操
【LTC2944高效电量监测系统构建】:技术要点与实战演练

# 摘要
本文全面介绍了LTC2944电量监测芯片的功能、设计要点及其在电量监测系统中的应用。首先概述了LTC2944的主要特性和工作原理,然后详细阐述了基于该芯片的硬件设计、软件开发和配置方法。文章进一步通过实验室测试和现场应用案例分析,提供了实战演练的深入见解。最后,探讨了故障排除和系统维护的实践,以及监测技术的未
【硬件设计的时序优化】:布局布线到延时控制的实战策略
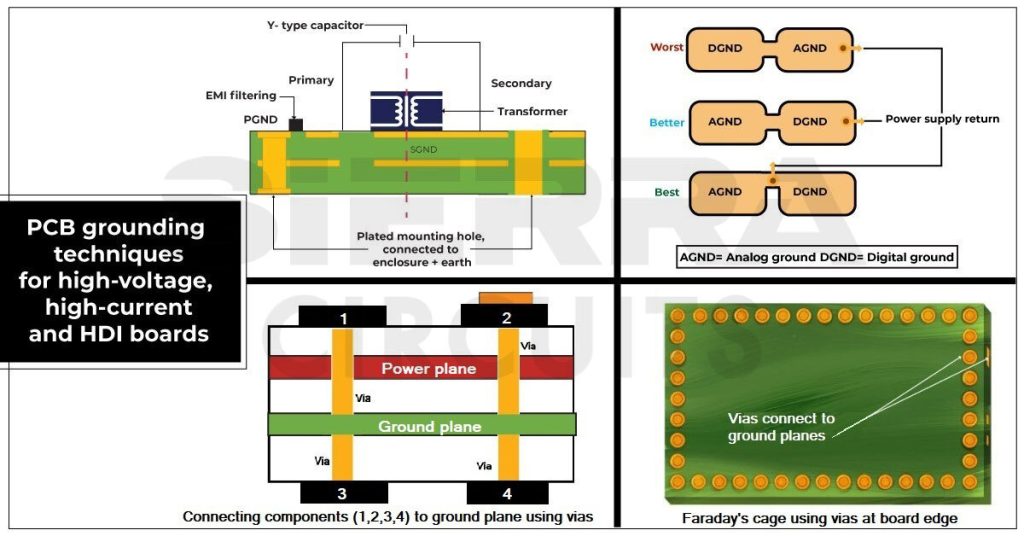
# 摘要
时序优化在硬件设计中起着至关重要的作用,直接影响到电路的性能和可靠性。本文首先强调了布局布线在硬件设计中的基础理论与实践的重要性,探讨了电路布局的关键因素和布线策略以确保信号完整性。接着,文章深入分析了延时控制的原理,包括时钟树的构建和优化以及信号传播时延的分析,
YRC1000性能提升攻略:代码效率优化的关键步骤

# 摘要
本论文首先评估并优化了YRC1000的性能基础,深入探讨了其硬件与软件架构,性能监控工具的使用,以及性能瓶颈。其次,本论文讨论了代码效率优化理论,包括性能评估、优化原则、分析方法和具体策略。在实践层面,本文详细阐述了编程语言的选择、算法优化和编译器技术对YRC1000性能的影响。此外,论文还涉及系统级性能调优,包括操作系统设置、硬件资源管理与系统监控。最后,通过案例研究,展示了YRC1000优化
【VLAN配置秘籍】:华为ENSP模拟器实战演练攻略

# 摘要
本文综合介绍了虚拟局域网(VLAN)的基础知识、配置、故障排除、安全策略及进阶技术应用。首先解析了VLAN的基本概念和原理,随后通过华为ENSP模拟器入门指南向读者展示了如何在模拟环境中创建和管理VLAN。文章还提供了VLAN配置的技巧与实践案例,重点讲
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )