【日志优化实践】:ClusterEngine浪潮集群日志分析与管理技巧
发布时间: 2024-12-27 11:09:16 阅读量: 5 订阅数: 7 

ClusterEngine浪潮集群服务平台使用手册-V4.0(1).pdf
# 摘要
本文详细探讨了日志优化在集群架构中的实践基础,重点分析了ClusterEngine集群架构的理解以及集群日志的分析技巧,涵盖了日志收集与分类、内容分析、数据挖掘等方面。同时,本文介绍了集群日志管理策略,包括日志的存储、压缩、保留、清除、审计以及合规性问题。此外,还探讨了日志的可视化与监控技术,包括可视化工具的选择和应用、实时监控系统的构建和警报机制的建立、监控数据的分析与优化。最后,通过集群日志优化的案例研究,分享了成功经验,总结了集群日志管理中的挑战与对策,以及最佳实践。
# 关键字
日志优化;ClusterEngine;日志分析;数据挖掘;日志管理策略;日志可视化
参考资源链接:[浪潮天梭ClusterEngine V4.0:高性能云服务平台使用手册](https://wenku.csdn.net/doc/3ny0y1fdhe?spm=1055.2635.3001.10343)
# 1. 日志优化实践基础
在现代IT运维和系统管理中,日志文件是关键的信息来源,它们记录了系统运行的细节、应用的行为以及可能的错误和警告。对于有经验的IT专业人士来说,有效地管理、查询、分析和优化日志文件至关重要。本章将介绍日志优化的基础知识,为深入探讨集群架构中的日志管理策略和分析技巧打下坚实的基础。
## 1.1 日志的作用与重要性
日志文件的作用远不止于记录错误。它们是诊断问题、监控系统性能和保障安全的重要工具。对于开发者而言,日志能够提供关于应用程序运行状况的实时反馈;对于运维团队来说,日志是理解系统健康状况的窗口。因此,对日志文件的优化是提高系统稳定性和性能的关键步骤。
```markdown
- 错误诊断:通过日志文件中的错误和异常信息来定位问题源头。
- 性能监控:利用日志分析工具,跟踪系统性能,识别瓶颈。
- 安全审计:审查安全相关的日志记录,用于预防和检测潜在的安全威胁。
```
## 1.2 日志优化的目标
日志优化的主要目标是确保日志信息的可读性、可查询性和可维护性。为了实现这些目标,需要对日志内容进行规范、设置合理的日志级别、并采用合适的日志管理系统。优化还包括制定日志保留策略,以确保符合数据保留法规同时避免存储成本过高。
```markdown
- 提高可读性:通过日志格式化和标准化来增强日志的可读性。
- 加强可查询性:实施结构化日志记录,使用日志分析工具来提高查询效率。
- 保障可维护性:设置日志轮转和压缩策略,合理管理存储空间。
```
在接下来的章节中,我们将深入探讨如何使用ClusterEngine集群架构来提升日志管理的效率,并实现日志的高效收集、分析、可视化以及监控。
# 2. 集群日志分析技巧
### 3.1 日志收集与分类
日志收集与分类是集群日志分析的第一步,它确保了日志数据的准确性和可用性。良好的收集和分类方法能够极大地提升日志的可查询性和管理效率。
#### 3.1.1 日志收集方法和工具
在企业环境中,日志收集通常由专门的日志收集工具负责,比如 Fluentd、Logstash 和 Beats。这些工具支持多种日志输入源,可以配置灵活的收集策略,并且易于扩展。
- **Fluentd**: 一个开源的数据收集器,为日志提供了一个统一的层。它的核心是一个插件系统,可以通过安装不同的插件来支持各种日志源和目的地。
- **Logstash**: Elasticsearch 家族的一部分,擅长处理大量日志数据。它可以处理各种格式的数据,并提供强大的数据处理能力。
- **Beats**: 由 Elastic 发起的一个轻量级的日志数据收集器项目,目前包含 Filebeat、Metricbeat、Packetbeat 等多种工具,各司其职。
在配置日志收集工具时,需要考虑如下几个因素:
- **日志源**: 需要收集的日志种类、格式、位置和产生的速率。
- **传输**: 日志传输过程中的安全性和稳定性。
- **目的地**: 收集到的日志最终存储的地点,例如 Elasticsearch、HDFS 或云存储服务。
- **过滤和解析**: 日志收集时的预处理,包括过滤无关数据和解析日志字段。
```yaml
# Filebeat 配置示例
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
output.elasticsearch:
hosts: ["localhost:9200"]
```
上述 YAML 配置片段展示了 Filebeat 如何设置来收集 `/var/log/` 目录下所有 `.log` 文件的日志,并输出到本地 Elasticsearch。
#### 3.1.2 日志分类的重要性与实现
日志分类是将不同类型的日志进行归类管理的过程。合理的分类可以提高日志查询的效率,同时使得日志分析更加精确。
- **静态分类**: 根据日志文件的来源或者目录结构进行分类。
- **动态分类**: 通过日志内容的特征,如关键字、字段值或者正则表达式进行分类。
在实际实现中,可以通过编写日志收集规则或配置,让日志收集工具在收集时同时完成分类。例如,使用 Filebeat 的 `processors` 功能可以实现日志字段的提取和修改:
```yaml
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~
- dissect:
tokenizer: "%{[fields.source]}-%{[fields.type]}"
field: "message"
```
上述配置展示了 Filebeat 如何根据 `message` 字段的内容动态地添加元数据,并将其解析为不同的日志类型。
### 3.2 日志内容分析
日志内容分析是日志管理中一项核心任务,它旨在从日志中提取有意义的信息,并通过模式识别和异常检测来识别潜在的问题。
#### 3.2.1 日志内容解析的方法
日志内容解析是对原始日志文本进行加工和转换的过程,目的是为了提取出有用的信息。这通常涉及到正则表达式、日志结构解析和模式匹配等技术。
- **正则表达式**: 用于匹配日志中的特定模式,例如日期、时间戳、错误代码等。
- **结构解析**: 适用于结构化日志,如 JSON,可以直观地解析出各个字段。
- **自然语言处理**: 对非结构化的日志进行处理,提取关键信息。
```python
import re
import json
# 示例 Python 代码来解析日志
log_line = '{"timestamp": "2023-03-10T15:04:05.000Z", "level": "ERROR", "message": "An error occurred."}'
# 使用正则表达式解析 JSON 日志
match = re.search(r'(\{.*\})', log_line)
if match:
log_json = json.loads(match.group(1))
print(f"Error level: {log_json['level']}")
```
在这个 Python 示例中,通过正则表达式匹配了 JSON 格式的日志行,并将其转换为字典以方便访问。
#### 3.2.2 日志模式识别与异常检测
模式识别和异常检测是日志内容分析的关键环节,目的是在海量日志中快速定位问题。这项工作通常借助机器学习技术来完成。
- **模式识别**: 使用已知日志模式进行匹配,以识别常见事件和异常。
- **异常检测**: 通过统计方法或机器学习算法,从日志数据中识别出异常行为或未知模式。
以 Elasticsearch 的 ML(机器学习)功能为例,可以用来自动识别时间序列数据中的异常模式:
```json
PUT _ml/anomaly_detectors/cluster_system_anomalies
{
"description": "Detect system anomalies",
"function_score": {
"query": { "match_all": {} },
"script_score": {
"script": {
"source": "Math.random()"
}
}
}
}
```
上述 JSON 请求向 Elasticsearch 的机器学习API 发送了一个创建新的异常检测任务的请求,其中使用了脚本分数查询来随机评估数据中的异常情况。
### 3.3 日志数据挖掘
日志数据挖掘是在海量日志数据中提取有价值信息的过程。这通常涉及数据挖掘技术和分析方法。
#### 3.3.1 数据挖掘技术在日志分析中的应用
数据挖掘技术能够帮助分析人员从日志中发现模式和关联规则,如关联分析、聚类分析、分类和预测。
- **关联分析**: 识别在日志事件中经常一起出现的模式,例如,一次特定的错误总是与某个特定操作同时发生。
- **聚类分析**: 将相似的日志条目组合在一起,以便于发现日志中的自然群体。
- **分类和预测**: 基于已有数据训练模型,对新的日志数据进行分类或预测。
```python
from sklearn.cluster import KMeans
# 示例使用 KMeans 算法进行聚类分析
from sklearn.datasets import make_classification
X, _ = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=10, random_state=42)
# 对数据进行聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
# 输出聚类结果
print(kmeans.labels_)
```
在这个 Python 示例中,我们使用 `make_classification` 创建了模拟的日志数据,并利用 KMeans 算法将其分为了三个群组。
#### 3.3.2 从日志数据中提取价值信息
通过数据挖掘,可以从日志中提取到有助于系统优化和故障预防的信息。这包括使用日志分析结果来指导系统设计、性能调优、安全策略制定等。
- **性能调优**: 通过分析日志中与性能相关的指标,如响应时间、吞吐量等,指导系统性能改进。
- **安全分析**: 基于日志中异常行为的模式,增强系统的安全防护能力。
- **业务分析**: 结合业务逻辑和日志数据,挖掘用户的使用习惯,优化产品功能。
在实际操作中,数据挖掘的结果需要结合具体的业务场景来进行解读和应用,以确保从中提取的信息是真实有价值的。
# 3. 集群日志分析技巧
## 3.1 日志收集与分类
### 3.1.1 日志收集方法和工具
在集群环境中,日志收集是理解和诊断问题的第一步。传统的日志收集方法包括使用 `scp`、`rsync` 等工具手动传输文件,这种方法效率低下且难以扩展。随着集群技术的发展,现在有更加自动化、高效的日志收集方法和工具,比如 `Fluentd`、`Logstash` 和 `Filebeat`。
以 `Fluentd` 为例,这是一个开源的数据收集器,用于统一日志层。它允许你用统一的方式去统一处理所有类型的数据源,结构化并且将它们输出到各种系统中。`Fluentd` 的配置非常灵活,并且可以通过插件来处理各种数据。
下面是一个 `Fluentd` 的基本配置示例:
```conf
# Fluentd configuration file
<system>
log_level debug
</system>
# Match all logs to the file output plugin
<match **>
@type file
path /var/log/fluentd-bundle/articles/articles-%Y-%m-%d.%H-%M-%S
time_slice_format %Y-%m-%d %H-%M-%S
time_slice_wait 10m
compress gzip
flush_interval 10s
</match>
```
这个配置会将所有的日志收集到指定的路径,并且按小时进行切割压缩,这样便于日后的分析和处理。
### 3.1.2 日志分类的重要性与实现
日志分类有助于更好地组织日志信息,使得日志的查找和分析更为高效。例如,可以根据日志来源、日志级别或特定的业务逻辑进行分类。分类的实现通常依赖于日志收集工具的配置。
为了实现有效的日志分类,可以在日志生成时,通过 `Syslog` 或者其他日志框架添加相应的标签或元数据。在日志收集时,这些标签或元数据被保留,并且可以用来对日志流进行分组和处理。
下面是一个使用 `Filebeat` 进行日志分类的示例:
```yaml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
tags: ["webserver"]
fields:
app: server
# Output
output.logstash:
hosts: ["logstash:5000"]
```
在这个配置中,我们定义了一个输入源来处理 `/var/log` 目录下所有的 `.log` 文件,并给这些日志添加了 `webserver` 标签和 `app: server` 字段。这些标签和字段可以用于日志的进一步处理和分类。
## 3.2 日志内容分析
### 3.2.1 日志内容解析的方法
解析日志内容是分析的第一步,这通常包括以下步骤:
1. **提取时间戳**:识别并提取日志中的时间戳,这对于后续的时间序列分析非常重要。
2. **解析日志级别**:识别日志是信息(INFO)、警告(WARNING)、错误(ERROR)还是其他级别。
3. **提取元数据**:从日志中提取如服务器IP、端口号、用户ID等元数据。
4. **正文提取**:解析日志消息正文,提取关键信息和异常信息。
一个常用的日志解析工具是 `Logstash`,它是一个开源的数据收集引擎,拥有强大的日志解析功能

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《ClusterEngine浪潮集群服务平台使用手册-V4.0(1).pdf》是一份全面的指南,涵盖了ClusterEngine浪潮平台的各个方面。它提供了一系列宝贵的见解和最佳实践,帮助用户高效监控和诊断集群故障、优化平台运行效率、确保数据一致性、实现自动化部署和管理、制定灾难恢复计划、深入理解故障转移机制、建立实时监控策略、优化日志分析和管理、实施成本优化策略、管理存储解决方案、进行无停机服务升级和迁移,以及执行负载测试和性能调优。通过遵循本手册中的指导,用户可以充分利用ClusterEngine浪潮平台的强大功能,提高集群可靠性、性能和可管理性。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ASR3603性能测试指南:datasheet V8助你成为评估大师

# 摘要
本论文全面介绍了ASR3603性能测试的理论与实践操作。首先,阐述了性能测试的基础知识,包括其定义、目的和关键指标,以及数据表的解读和应用。接着,详细描述了性能测试的准备、执行和结果分析过程,重点讲解了如何制定测试计划、设计测试场景、进行负载测试以及解读测试数据。第三章进一步
【安全设计,可靠工作环境】:安川机器人安全性设计要点

# 摘要
本文全面探讨了安川机器人在安全性方面的理论和实践。首先概述了安川机器人安全性的重要性,并详细介绍了其基本安全特性,包括安全硬件设计、安全软件架构以及安全控制策略。随后,文章分析了安川机器人安全功能的应用,特别是在人机协作、高级安全配置以及安全测试与认证方面的实践。面对实际应用中遇到的挑战,本文讨论了安
【数字电路实验】:四位全加器设计案例,Quartus II全解析
# 摘要
本论文深入探讨了四位全加器的设计原理和实现过程,重点在于利用Quartus II软件和硬件描述语言(HDL)进行设计和测试。首先,介绍
【安全编程实践】:如何防止攻击,提升单片机代码的鲁棒性?

# 摘要
本文深入探讨了单片机安全编程的重要性,从基础概念到高级技巧进行全面概述。首先介绍了单片机面临的安全风险及常见的攻击类型,并对安全编程的理论基础进行了阐述。在此基础上,本文进一步分析了强化单片机编程安全性的策略,包括输入验证、内存保护、安全通信和加密技术的应用。最后,通过实战案例分析,展示了如何在实际开发中应用这些策略
环境影响下的电路性能研究:PSpice温度分析教程(必须掌握)
# 摘要
本文探讨了电路仿真与环境因素的关联,并深入分析了PSpice软件的工作原理、温度分析的基础知识及其在电路设计中的应用。文章首先介绍了PSpice软件及其温度模型的配置方法,然后详述了温度对电路元件性能的影响,并讨论了如何设计仿真实验来评估这些影响。接着,本文探讨了多环境温度下电路性能仿真的高级应用,并提出了散热设计与电路稳定性的关系及其验证方法。最后,文章展望了未来电路设计中温度管理的创新方法,包括新型材料的温度控制技术、
【城市交通规划】:模型对实践指导的6大实用技巧

# 摘要
城市交通规划对于缓解交通拥堵、提升城市运行效率以及确保可持续发展至关重要。本文首先介绍了城市交通规划的重要性与面临的挑战,接着深入探讨了交通规划的基础理论,包括交通流理论、需求分析、数据采集方法等。在实践技巧章节,本文分析了模型选择、拥堵解决策略和公共交通系统规划的实际应用。此外,现代技术在交通规划中的应用,如智能交通系统(ITS)、大数
人工智能算法精讲与技巧揭秘:王万森习题背后的高效解决方案
# 摘要
本论文全面探讨了人工智能算法的基础、核心算法的理论与实践、优化算法的深入剖析、进阶技巧与实战应用以及深度学习框架的使用与技巧。首先介绍了人工智能算法的基本概念,接着详细解析了线性回归、逻辑回归、决策树与随机森林等核心算法,阐述了梯度下降法、正则化技术及神经网络优化技巧。随后,探讨了集成学习、数据预处理、模型评估与选择等算法进阶技巧,并给出了实战应用案例。最
BTN7971驱动芯片应用案例精选:电机控制的黄金解决方案
# 摘要
本文全面介绍了BTN7971驱动芯片,探讨了其在电机控制理论中的应用及其实践案例。首先概述了BTN7971的基本工作原理和电机控制的基础理论,包括H桥电路和电机类型。其次,详细分析了BTN7971在电机控制中的性能优势和高级技术应用,例如控制精度和PWM调速技术。文中还提供了 BTN7971在不同领域,如家用电器、工业自动化和电动交通工具中的具体应用案例。最后,本文展望了BTN7971在物联网时代面临的趋势和挑战,并讨论了未来发展的方向,包括芯片技术的迭代和生态系统构建。
# 关键字
BTN7971驱动芯片;电机控制;PWM调速技术;智能控制;热管理;生态构建
参考资源链接:[B
【电力电子技术揭秘】:斩控式交流调压电路的高效工作原理
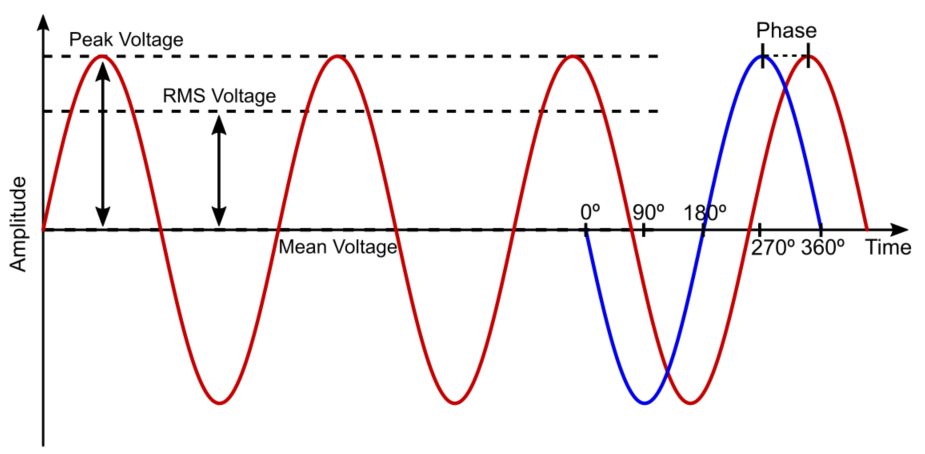
# 摘要
斩控式交流调压电路是电力电子技术中的一个重要应用领域,它通过控制斩波器的导通和截止来实现对交流电压的精确调节。本文首先概述了斩控式交流调压电路的基本概念,接着详细介绍了电力电子技术的基础理论、交流电的基础知识以及斩控技术的工作原理。第三章深入探讨了斩控式交流调压电路的设计,包括电路设计原则、元器件选型分析以及控制策略的实现。第四章和第五章分别介绍了电路的模拟与仿真以及实验与实践,分析了仿真测试流程和实验数据,提供了性能
【RN8209D固件升级攻略】:顺利升级的步骤与关键点
# 摘要
本文全面探讨了RN8209D固件升级的全过程,从前期准备到升级操作步骤,再到升级后的优化与维护以及高级定制。重点介绍了升级前的准备工作,包括硬件和软件的兼容性检查、升级工具的获取以及数据备份和安全措施。详细阐述了固件升级的具体操作步骤,以及升级后应进行的检查与验证。同时,针对固件升级中可能遇到的硬件不兼容、软件升级失败和数据丢失等问题提供了详尽的解决方案。最后,本文还探讨了固件升级后的性能优化
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )