Python中的文本挖掘技术实践
发布时间: 2024-04-02 22:03:37 阅读量: 63 订阅数: 44 

文本挖掘技术
# 1. 文本挖掘技术概述
文本挖掘技术在当今信息爆炸的时代发挥着越来越重要的作用。通过对海量文本数据的分析和挖掘,可以从中提取有用信息,帮助人们更好地理解文本内容、做出决策以及发现潜在的规律和趋势。本章将介绍文本挖掘技术的概念、应用领域以及Python在文本挖掘中的重要性。
- **1.1 什么是文本挖掘技术**
文本挖掘技术(Text Mining)是指从文本数据中自动或半自动地获取高质量信息的过程。这包括对文本数据的分析、建模和挖掘,以揭示其中隐藏的有用信息。文本挖掘技术结合了自然语言处理、机器学习和数据挖掘等多个领域的技术,旨在从大规模文本数据中提取知识和智能。
- **1.2 文本挖掘技术的应用领域**
文本挖掘技术被广泛应用于各个领域,包括但不限于:
- 情感分析:通过分析用户评论、社交媒体等文本数据,了解用户对产品或事件的情感倾向。
- 垃圾邮件过滤:识别和过滤垃圾邮件,提高用户体验和信息安全。
- 情报分析:从海量情报文本中挖掘有用信息,支持决策和行动。
- **1.3 Python在文本挖掘中的重要性**
Python作为一种简洁、易学、强大的编程语言,在文本挖掘领域得到了广泛的应用。Python拥有丰富的文本处理库(如NLTK、Scikit-learn等),提供了丰富的工具和算法支持。同时,Python社区活跃,有大量的开源项目和工具可供使用,使得使用Python进行文本挖掘任务更加高效和便捷。Python的易读性和易用性也使得初学者能够快速上手,并且适合于快速原型开发和实验。
通过本章的介绍,读者将对文本挖掘技术有一个整体的认识,并了解到Python在文本挖掘中的重要性。接下来,我们将深入探讨文本挖掘技术的具体实践和应用。
# 2. 文本预处理
文本预处理在文本挖掘中起着至关重要的作用,它可以帮助我们清洗文本数据、减少噪音,使文本数据更具可分析性。在Python中,有许多常用的文本预处理技术,包括文本数据清洗及去噪、分词与词性标注、去停用词与词根化等。接下来,我们将逐一介绍这些技术的实践方法。
#### 2.1 文本数据清洗及去噪
文本数据经常包含各种噪音,比如HTML标签、特殊字符、数字等,这些噪音会影响文本挖掘的结果。因此,我们需要对文本数据进行清洗,去除这些噪音。
```python
import re
def clean_text(text):
# 去除HTML标签
text = re.sub('<.*?>', '', text)
# 去除特殊字符和数字
text = re.sub('[^a-zA-Z]', ' ', text)
# 将所有字母转为小写
text = text.lower()
return text
```
**代码解释:**
- 使用正则表达式去除HTML标签:`re.sub('<.*?>', '', text)`
- 去除特殊字符和数字:`re.sub('[^a-zA-Z]', ' ', text)`
- 将所有字母转为小写:`text.lower()`
#### 2.2 分词与词性标注
分词是将文本按照一定规则切分成词语的过程,在文本挖掘中非常重要。词性标注则是为每个词语标注其词性,可以帮助我们更好地理解文本数据。
```python
from nltk import word_tokenize
from nltk import pos_tag
text = "This is a sample sentence for tokenization and POS tagging."
tokens = word_tokenize(text)
pos_tags = pos_tag(tokens)
print("Tokens:", tokens)
print("POS Tags:", pos_tags)
```
**代码解释:**
- 使用NLTK库的`word_tokenize()`函数对文本进行分词
- 使用`pos_tag()`函数对分词结果进行词性标注
#### 2.3 去停用词与词根化
在文本挖掘中,停用词(Stop Words)对分析结果影响较大,因为它们在文本中出现频率高但对文本特征表示能力低。另外,词根化(Stemming)可以将词汇还原到其原始形式,以减少词形变化带来的干扰。
```python
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer
stop_words = set(stopwords.words('english'))
stemmer = PorterStemmer()
def remove_stopwords_and_stemming(text):
tokens = word_tokenize(text)
filtered_tokens = [stemmer.stem(token) for token in tokens if token.lower() not in stop_words]
return filtered_tokens
```
**代码解释:**
- 使用NLTK库提供的停用词表`stopwords.words('english')`去除停用词
- 使用Porter Stemmer进行词根化处理:`stemmer.stem(token)`
通过以上文本预处理步骤,我们可以更好地准备文本数据,为后续的特征提取和分析做好准备。
# 3. 文本特征提取
在文本挖掘中,文本特征提取是非常重要的一环,它可以帮助我们将文本数据转换成计算机可以理解和处理的形式。本章将介绍几种常用的文本特征提取方法,包括词袋模型、TF-IDF特征提取以及Word2Vec技术。
#### 3.1 词袋模型(Bag of Words)
词袋模型是一种简单但常用的文本特征提取方法,它将文本表示为一个由文本中所有词汇构成的集合,忽略了词汇在文本中的顺序,只关注词汇的出现次数。在Python中,可以使用CountVectorizer类来实现词袋模型的特征提取:
```python
from sklearn.feature_extraction.text import CountVectorizer
# 创建一个CountVectorizer对象
vectorizer = CountVectorizer()
# 定义文本数据
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
# 将文本数据转换为词袋模型的特征矩阵
X = vectorizer.fit_transform(corpus)
# 打印特征矩阵的稀疏表示
print(X.toarray())
# 打印特征词汇
print(vectorizer.get_feature_names())
```
通过词袋模型,我们可以将文本数据转换为向量表示的形式,便于接下来的文本分类或聚类分析。
#### 3.2

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 Python 编程语言为核心,深入探讨数据分析和机器学习的方方面面。涵盖了从数据预处理和可视化到机器学习算法、特征选择和降维等基础概念。专栏还介绍了神经网络、卷积神经网络、RNN 和 LSTM 等高级算法,以及自然语言处理、文本挖掘、推荐系统和聚类等领域。此外,专栏还探讨了时间序列分析、异常检测、强化学习等主题。通过本专栏,读者可以全面了解 Python 在数据分析和机器学习领域的应用,提升数据分析和机器学习技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【硬件实现】:如何构建性能卓越的PRBS生成器

# 摘要
本文全面探讨了伪随机二进制序列(PRBS)生成器的设计、实现与性能优化。首先,介绍了PRBS生成器的基本概念和理论基础,重点讲解了其工作原理以及相关的关键参数,如序列长度、生成多项式和统计特性。接着,分析了PRBS生成器的硬件实现基础,包括数字逻辑设计、FPGA与ASIC实现方法及其各自的优缺点。第四章详细讨论了基于FPGA和ASIC的PRBS设计与实现过程,包括设计方法和验
NUMECA并行计算核心解码:掌握多节点协同工作原理
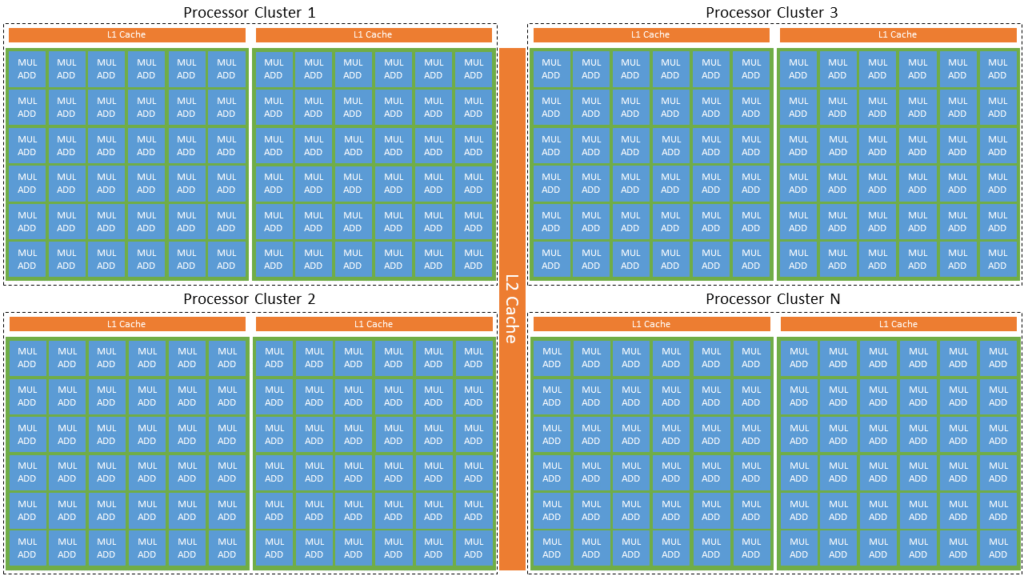
# 摘要
NUMECA并行计算是处理复杂计算问题的高效技术,本文首先概述了其基础概念及并行计算的理论基础,随后深入探讨了多节点协同工作原理,包括节点间通信模式以及负载平衡策略。通过详细说明并行计算环境搭建和核心解码的实践步骤,本文进一步分析了性能评估与优化的重要性。文章还介绍了高级并行计算技巧,并通过案例研究展示了NUMECA并行计算的应用。最后,本文展望了并行计
提升逆变器性能监控:华为SUN2000 MODBUS数据优化策略

# 摘要
逆变器作为可再生能源系统中的关键设备,其性能监控对于确保系统稳定运行至关重要。本文首先强调了逆变器性能监控的重要性,并对MODBUS协议进行了基础介绍。随后,详细解析了华为SUN2000逆变器的MODBUS数据结构,阐述了数据包基础、逆变器的注册地址以及数据的解析与处理方法。文章进一步探讨了性能数据的采集与分析优化策略,包括采集频率设定、异常处理和高级分析技术。
小红书企业号认证必看:15个常见问题的解决方案

# 摘要
本文系统地介绍了小红书企业号的认证流程、准备工作、认证过程中的常见问题及其解决方案,以及认证后的运营和维护策略。通过对认证前准备工作的详细探讨,包括企业资质确认和认证材料
FANUC面板按键深度解析:揭秘操作效率提升的关键操作
# 摘要
FANUC面板按键作为工业控制中常见的输入设备,其功能的概述与设计原理对于提高操作效率、确保系统可靠性及用户体验至关重要。本文系统地介绍了FANUC面板按键的设计原理,包括按键布局的人机工程学应用、触觉反馈机制以及电气与机械结构设计。同时,本文也探讨了按键操作技巧、自定义功能设置以及错误处理和维护策略。在应用层面,文章分析了面板按键在教育培训、自动化集成和特殊行业中的优化策略。最后,本文展望了按键未来发展趋势,如人工智能、机器学习、可穿戴技术及远程操作的整合,以及通过案例研究和实战演练来提升实际操作效率和性能调优。
# 关键字
FANUC面板按键;人机工程学;触觉反馈;电气机械结构
【UML类图与图书馆管理系统】:掌握面向对象设计的核心技巧
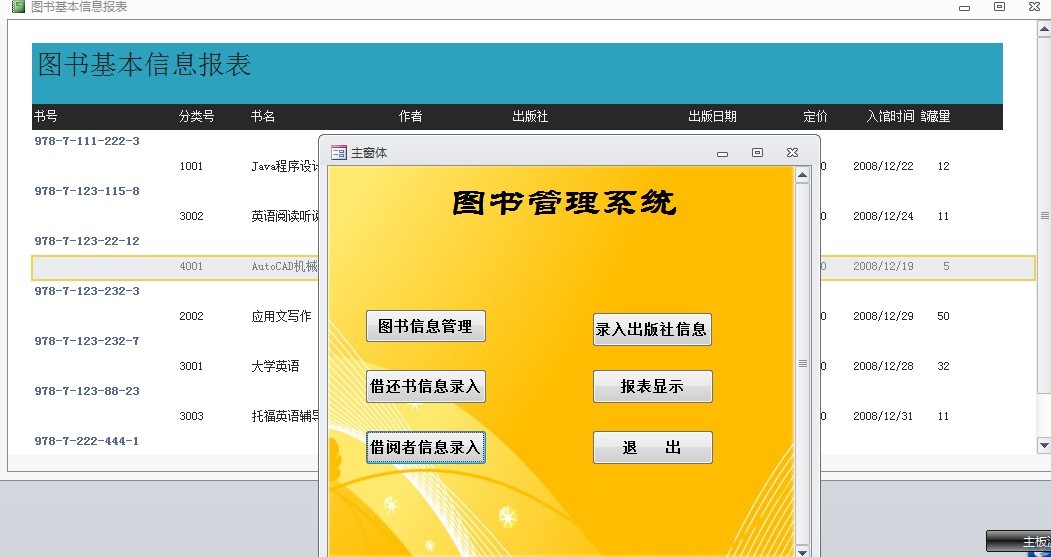
# 摘要
本文旨在探讨面向对象设计中UML类图的应用,并通过图书馆管理系统的需求分析、设计、实现与测试,深入理解UML类图的构建方法和实践。文章首先介绍了UML类图基础,包括类图元素、关系类型以及符号规范,并详细讨论了高级特性如接口、依赖、泛化以及关联等。随后,文章通过图书馆管理系统的案例,展示了如何将UML类图应用于需求分析、系统设计和代码实现。在此过程中,本文强调了面向对象设计原则,评价了UML类图在设计阶段
【虚拟化环境中的SPC-5】:迎接虚拟存储的新挑战与机遇
# 摘要
本文旨在全面介绍虚拟化环境与SPC-5标准,深入探讨虚拟化存储的基础理论、存储协议与技术、实践应用案例,以及SPC-5标准在虚拟化环境中的应用挑战。文章首先概述了虚拟化技术的分类、作用和优势,并分析了不同架构模式及SPC-5标准的发展背景。随后
硬件设计验证中的OBDD:故障模拟与测试的7大突破
# 摘要
OBDD(有序二元决策图)技术在故障模拟、测试生成策略、故障覆盖率分析、硬件设计验证以及未来发展方面展现出了强大的优势和潜力。本文首先概述了OBDD技术的基础知识,然后深入探讨了其在数字逻辑故障模型分析和故障检测中的应用。进一步地,本文详细介绍了基于OBDD的测试方法,并分析了提高故障覆盖率的策略。在硬件设计验证章节中,本文通过案例分析,展示了OBDD的构建过程、优化技巧及在工业级验证中的应用。最后,本文展望了OBDD技术与机器学习等先进技术的融合,以及OBDD工具和资源的未来发展趋势,强调了OBDD在AI硬件验证中的应用前景。
# 关键字
OBDD技术;故障模拟;自动测试图案生成
海康威视VisionMaster SDK故障排除:8大常见问题及解决方案速查
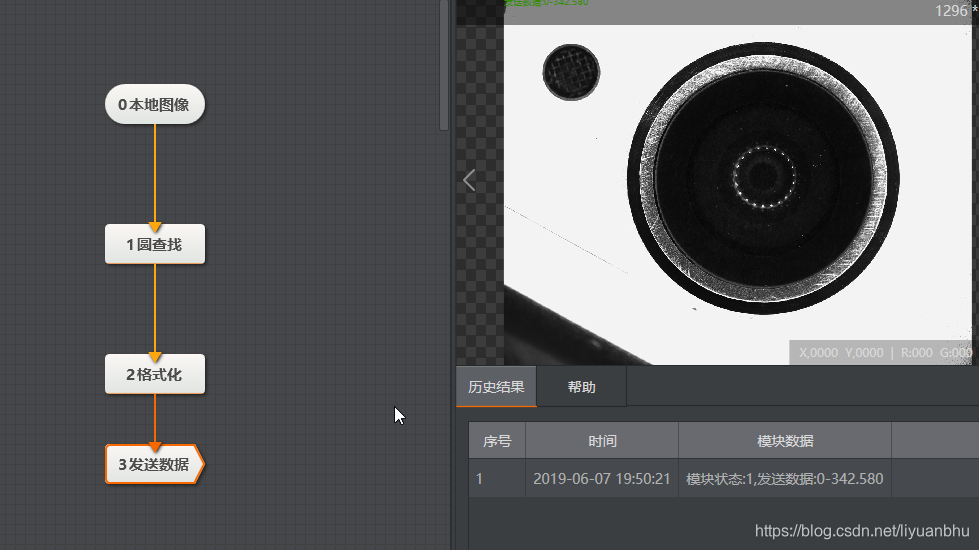
# 摘要
本文全面介绍了海康威视VisionMaster SDK的使用和故障排查。首先概述了SDK的特点和系统需求,接着详细探讨了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )