




C语言错误处理最佳实践:assert与errno的正确使用方法


C语言错误处理:从基础到高级技术详解
摘要
C语言作为一种高效而灵活的编程语言,在系统软件和应用程序开发中广泛应用。为了提高代码的健壮性和可维护性,错误处理在C语言编程中占据着至关重要的地位。本文从C语言错误处理的基本概念入手,深入探讨了assert宏的使用原理和限制,以及errno机制在错误信息管理中的作用。通过实践技巧的介绍,本文旨在提供编写健壮代码的技术支持,包括错误码的组织、错误处理性能考量以及多线程环境下的应用。案例分析章节通过对实际问题的深入剖析,展示了错误处理在不同场景下的具体应用。最终,本文探讨了高级错误处理技术,包括信号处理、异常捕获及日志记录工具的使用,为C语言开发者提供了全面的错误处理解决方案。
关键字
C语言;错误处理;assert宏;errno机制;多线程;异常处理
参考资源链接:华清远见C语言补习测试题及答案解析
1. C语言错误处理概述
在软件开发过程中,错误处理是确保程序稳定性和可维护性的关键环节。C语言作为一种底层且广泛使用的编程语言,其错误处理机制尤为重要。错误处理不仅涉及到错误检测,还包括错误响应和恢复策略。本章将概述C语言中的错误处理概念和常用方法,为后续章节深入探讨各种错误处理技术打下基础。
错误的分类
在C语言中,错误主要分为两类:系统错误和用户错误。系统错误通常指的是由程序外部因素引起的异常情况,例如硬件故障、资源不足等;用户错误则是由于用户输入错误或操作不当导致的问题。
错误处理的重要性
良好的错误处理机制能够帮助开发者及时发现并解决问题,避免程序崩溃或数据损坏。它还能提供有用的调试信息,加快问题定位和解决的速度。
在C语言中,实现错误处理通常依赖于返回码、errno全局变量、信号处理和断言(assert)等多种机制。为了更好地理解这些技术,第二章将深入探讨assert宏的使用和原理。
2. assert宏的使用和原理
2.1 assert宏简介
assert 宏是 C 语言中提供的一个调试工具,用于在程序运行时检查一个条件表达式是否为真。如果条件表达式的结果为假(即结果为0),则 assert 会打印一条出错信息,并通过调用 abort() 函数终止程序执行。该宏定义在 <assert.h> 头文件中。
assert 宏常用于程序中那些必须成立的条件验证,譬如函数的参数检查、程序逻辑的预设条件等。它是实现错误快速检测的便捷方式,能够在问题发生时快速定位问题所在。
2.2 assert宏的工作原理
assert 宏的工作原理十分简单。当一个断言条件为假时,程序会打印出一条包含断言失败位置信息的错误消息,然后通过 abort() 结束程序执行。assert 宏背后的实现通常依赖于预处理器指令,下面是其基本的工作原理流程:
- 定义宏:在
<assert.h>中定义assert宏。 - 展开宏:预处理器将源代码中的
assert(expression)替换成if (!(expression)) { assert_failed(expression, file, line); }。 - 调用
assert_failed:如果expression的结果为假,程序会调用一个私有的assert_failed函数。 - 错误消息:
assert_failed函数会获取错误信息,如表达式、文件名和行号,并向标准错误输出。 - 调用
abort:输出错误消息后,程序调用abort()函数终止执行。
2.3 如何在代码中正确使用assert
在代码中使用 assert 宏时,应该注意以下几点:
- 明确条件:确保
assert检查的条件是明确且必要的,通常用于验证那些不应该发生的情况。 - 避免副作用:由于
assert可能会在发布版本中被禁用,因此不要在assert表达式中使用有副作用的函数,比如printf。 - 调试与发布版本:在调试版本中启用
assert,而在发布版本中禁用。可以使用编译器定义NDEBUG来控制assert的启用与禁用。 - 错误处理的补充:
assert不是用来替代正常的错误处理逻辑的,而应该作为程序中无法恢复的错误的快速检测手段。
下面是一个 assert 使用的简单例子:
- #include <stdio.h>
- #include <assert.h>
- void check_range(int value) {
- // 假设数组索引必须在0到99之间
- assert(value >= 0 && value <= 99);
- // 其他代码逻辑
- }
- int main() {
- check_range(101); // 断言失败,会触发assert
- return 0;
- }
2.4 assert宏的局限性和替代方案
虽然 assert 很有用,但它有几个局限性:
- 性能开销:在发布版本中,由于定义了
NDEBUG,所有的assert宏都会被预处理器忽略,不进行任何操作。但是,将断言保留在代码中可能会带来轻微的性能损失。 - 条件限制:
assert只能用于表达式结果为真或假的情况,不能用于更复杂的错误检查。 - 无法恢复的错误:
assert的目标是那些不可恢复的错误,这意味着它不适合处理所有类型的错误。
为了替代 assert,可以在代码中实现自定义的检查机制,例如使用函数封装错误检查逻辑,或者使用其他调试工具如日志记录和调试器。
下面是一个简单的自定义错误检查函数例子:

通过这种方式,可以更加灵活地控制错误处理,而不是完全依赖 assert 宏。
3. errno机制详解
3.1 errno的定义和作用
errno 是在 C 语言标准库中定义的一个全局变量,用于表示函数调用过程中发生的错误。每当标准库函数调用失败时,它会被设置为一个特定的错误码,以反映错误的原因。例如,当打开文件失败时,errno 会被设置为 ENOENT,表示“没有该文件或目录”。
3.1.1 errno的类型和定义
errno 通常定义为一个整型变量,其类型为 int。为了确保 errno 可以跨平台使用,它被定义在 <errno.h> 头文件中。在不同的平台和编译器中,errno 可能存储在一个特定的寄存器中,也可能是作为一个线程局部存储变量。
3.1.2 errno的作用域
errno 的作用域通常是全局的,这意味着在一个函数中设置的 errno 值会影响到其他函数。然而,为了避免函数调用链中的 errno 值相互干扰,正确的做法是在每次调用可能修改 errno 的函数之后立即检查它。
3.2 errno与错误码的关系
3.2.1 错误码的分类
错误码通常分为两大类:系统错误码和库函数自定义错误码。系统错误码通常由操作系统定义,并且每个错误码都有对应的宏定义。例如,在 UNIX 系统中,错误码通常以 E 开头,如 EACCES。
3.2.2 如何通过errno获取错误描述
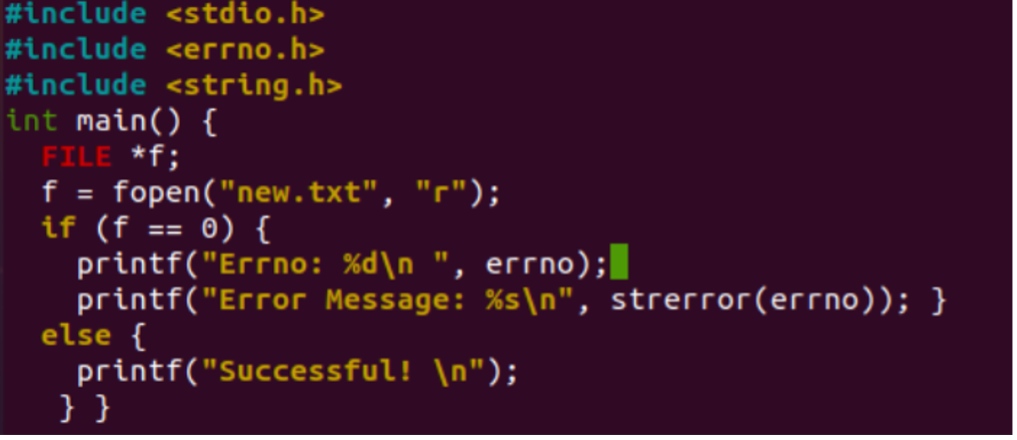
虽然 errno 存储了一个数字错误码,但通常我们不直接查看这个数字,而是使用诸如 strerror 这样的函数将错误码转换为易于理解的错误描述字符串。例如:
- #include <stdio.h>
- #include <errno.h>
- #include <string.h>
- int main() {
- int ret = open("nonexistent_file.txt", O_RDONLY);
- if (ret == -1) {
- perror("open failed");
- // Alternatively, using strerror directly.
- printf("Error: %s\n", strerror(errno));
- }
- return 0;
- }
3.2.3 错误码的命名规则
错误码的命名规则有助于我们识别和理解错误的来源。通常,以 E 开头的错误码表示系统级错误,以其他字母开头的错误码则可能是库函数定义的。错误码的命名通常与错误发生的具体原因有关,比如 EPERM 表示权限被拒绝。
3.3 如何在程序中设置和检查errno
3.3.1 设置errno的正确方法
在某些情况下,程序需要自行设置 errno,特别是当需要提供更详细的错误信息时。正确设置 errno 的方式是直接赋值,但是必须在覆盖之前保存原值,以避免不小心破坏其他部分的错误状态。
- #include <stdio.h>
- #include <errno.h>
- void custom_function() {
- int saved_errno = errno; // 保存当前errno值
- errno = EINVAL; // 设置自定义错误码
- printf("Custom error: %s\n", strerror(errno));
- errno = saved_errno;

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录

文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PySide2故障排除】:DLL加载失败不再成为难题
【打印机故障速解】:HL3150CDN进纸问题的10分钟快速修复法
云计算中的Arthrun:揭秘其卓越的云集成能力
【专业分析】CentOS7.9安装前必备:硬件检查与系统需求深度剖析
【缓存一致性深度解析】:educoder实训作业中的关键挑战及应对
【Tomcat高可用性部署秘诀】:实现零停机时间的策略
GIS设备入门速成:10个核心知识点帮你成为专家
掌握数据库文档精髓:pg016_v_tc.pdf关键信息深度解读
Wireshark基础入门:5分钟掌握网络数据包捕获与分析技巧


专栏目录
文章持续更新中,敬请期待~
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















