Java网络编程中的日志记录与故障排查
发布时间: 2024-02-21 09:26:07 阅读量: 41 订阅数: 27 

一个可靠、通用、快速且灵活的 Java 日志记录框架
# 1. 理解Java网络编程中的日志记录
### 1.1 为什么日志记录在Java网络编程中至关重要?
在Java网络编程中,日志记录是至关重要的,它可以帮助我们跟踪程序的执行状态,排查问题,监控性能,并且为故障排查提供关键信息。
### 1.2 常见的日志记录框架及其比较
介绍常见的Java日志记录框架,如Log4j、Logback、java.util.logging等,比较它们的特点、适用场景和性能。
### 1.3 设置和配置日志记录器
讲解如何在Java网络编程中设置和配置日志记录器,包括日志级别、输出目的地、格式化等配置。
接下来,我们将深入探讨日志级别和日志输出。
# 2. 日志级别和日志输出
日志级别和日志输出在Java网络编程中起着至关重要的作用。在这一章节中,我们将深入探讨不同日志级别的含义及其在网络编程中的使用场景,介绍如何在Java程序中输出日志以及日志格式化和输出目的地的设置。
### 2.1 不同日志级别的意义和使用场景
在日志记录中,通常有不同的日志级别,如DEBUG、INFO、WARN、ERROR等。不同级别的日志适用于不同的场景:
- DEBUG:用于调试目的,记录详细的程序执行信息,可用于追踪代码执行流程。
- INFO:常用于输出程序正常执行的关键信息,如程序启动、初始化完成等。
- WARN:表示潜在的问题,不会导致程序崩溃,但可能会影响系统正常运行。
- ERROR:用于记录错误信息,表示程序遇到了严重的问题,需要及时处理。
### 2.2 如何在Java网络编程中输出日志?
在Java网络编程中,通常使用日志记录框架如Log4j、Logback等来输出日志。以下是一个简单示例使用Log4j记录日志:
```java
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
public class NetworkLoggerExample {
private static final Logger logger = LogManager.getLogger(NetworkLoggerExample.class);
public static void main(String[] args) {
logger.debug("Debug message");
logger.info("Info message");
logger.warn("Warn message");
logger.error("Error message");
}
}
```
代码总结:以上代码演示了如何在Java程序中使用Log4j记录日志,并输出不同级别的日志信息。
### 2.3 日志格式化和日志输出目的地
日志格式化可以让日志信息更易读,常见的格式包括时间戳、日志级别、类名、线程ID等。同时,可以将日志输出到不同的目的地,如控制台、文件、数据库等。下面是一个使用Logback进行日志格式化和输出到文件的示例:
```xml
<configuration>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>application.log</file>
<encoder>
<pattern>%date [%thread] %-5level %logger{35} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="FILE"/>
</root>
</configuration>
```
代码总结:以上示例配置了一个FileAppender,将日志输出到文件"application.log",并设置了日志格式为包含时间戳、线程信息、日志级别和日志内容的格式。
通过本章节的学习,你将更加了解日志记录中不同日志级别的使用方法,以及如何进行日志格式化和输出到不同目的地的配置。
# 3. 日志记录最佳实践
在Java网络编程中,良好的日志记录实践可以帮助开发人员更快速地定位和解决问题,提高系统的可靠性和稳定性。下面是一些日志记录的最佳实践:
#### 3.1 如何编写清晰、有意义的日志信息?
在编写日志信息时,应该遵循以下几个原则:
- **准确性**:确保日志信息能够准确反映出当前系统状态或事件的关键信息,避免过于模糊或冗余的描述。
- **可读性**:尽量使用简洁清晰的语言表达,避免过长的句子或复杂的词汇,以便他人能够快速理解日志信息。
- **上下文信息**:在日志信息中包含足够的上下文信息,比如事件发生的时间、位置、相关参数等,有助于问题的定位和分析。
```java
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class NetworkService {
private static final Logger logger = LoggerFactory.getLogger(NetworkService.class);
public void sendData(String data) {
logger.info("Sending data: {}", data);
// Send data logic here
}
}
```
**代码总结**:在上面的示例中,我们展示了如何使用SLF4J和Logback来记录发送数据的日志信息,其中包含了要发送的数据内容。
**结果说明**:当调用`sendData`方法时,日志将输出类似"Sending data: Hello, World!"的信息,清晰地显示了发送的数据内容。
#### 3.2 避免常见的日志记录陷阱
在日志记录过程中,有一些常见的陷阱需要避免:
- **过度记录**:避免记录大量无关紧要的信息,会增加日志文件大

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨Java系列技术中网络编程与NIO、AIO的进阶实践。从实现简单的HTTP服务器与客户端到多线程处理技巧,再到NIO的非阻塞I/O与Selector的应用,以及AIO异步I/O编程入门指南,专栏全方位解析网络编程中的关键技术。通过比较AIO在网络编程中的应用与效率,以及基于Java NIO/AIO的异步网络通信实践,帮助读者构建高性能的网络服务器。此外,还探讨了数据序列化与反序列化、异常处理与错误检测、负载均衡与高可用性解决方案,以及日志记录与故障排查等方面的技术。无论是初学者还是有经验的开发者,都能从本专栏中获得实用的网络编程知识和技巧,助力他们在Java网络编程领域取得更大的成就。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
JLINK_V8固件烧录故障全解析:常见问题与快速解决

# 摘要
JLINK_V8作为一种常用的调试工具,其固件烧录过程对于嵌入式系统开发和维护至关重要。本文首先概述了JLINK_V8固件烧录的基础知识,包括工具的功能特点和安装配置流程。随后,文中详细阐述了烧录前的准备、具体步骤和烧录后的验证工作,以及在硬件连接、软件配置及烧录失败中可能遇到的常见问题和解决方案
【Jetson Nano 初识】:掌握边缘计算入门钥匙,开启新世界

# 摘要
本论文介绍了边缘计算的兴起与Jetson Nano这一设备的概况。通过对Jetson Nano的硬件架构进行深入分析,探讨了其核心组件、性能评估以及软硬件支持。同时,本文指导了如何搭建Jetson Nano的开发环境,并集成相关开发库与API。此外,还通过实际案例展示了Jetson Nano在边缘计算中的应用,包括实时图像和音频数
MyBatis-Plus QueryWrapper故障排除手册:解决常见查询问题的快速解决方案
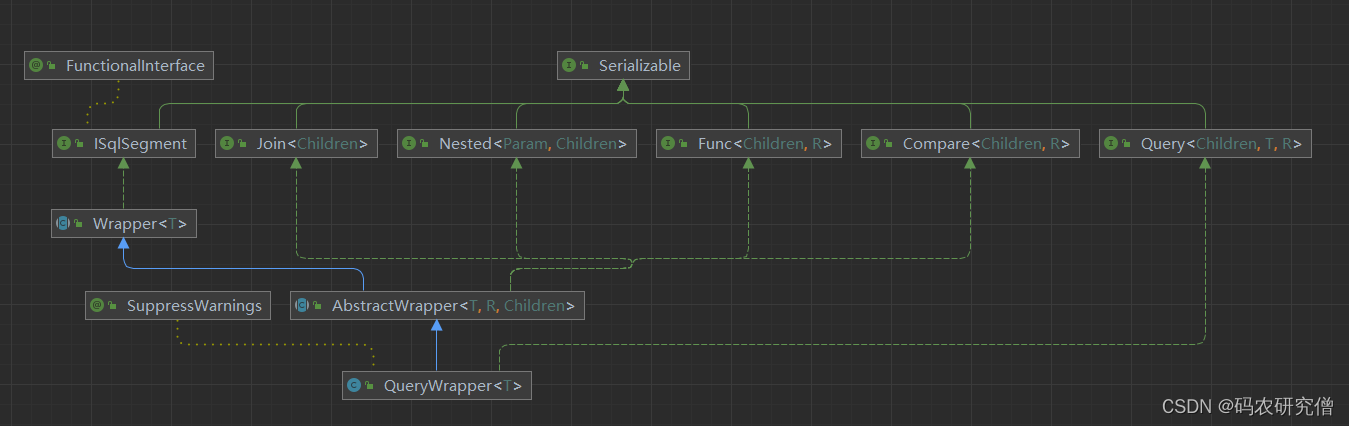
# 摘要
MyBatis-Plus作为一款流行的持久层框架,其提供的QueryWrapper工具极大地简化了数据库查询操作的复杂性。本文首先介绍了MyBatis-Plus和QueryWrapper的基本概念,然后深入解析了QueryWrapper的构建过程、关键方法以及高级特性。接着,文章探讨了在实际应用中查询常见问题的诊断与解决策略,以及在复杂场
【深入分析】SAP BW4HANA数据整合:ETL过程优化策略

# 摘要
SAP BW4HANA作为企业数据仓库的更新迭代版本,提供了改进的数据整合能力,特别是在ETL(抽取、转换、加载)流程方面。本文首先概述了SAP BW4HANA数据整合的基础知识,接着深入探讨了其ETL架构的特点以及集成方法论。在实践技巧方面,本文讨论了数据抽取、转换和加载过程中的优化技术和高级处理方法,以及性能调优策略。文章还着重讲述了ETL过
电子时钟硬件选型精要:嵌入式系统设计要点(硬件配置秘诀)

# 摘要
本文对嵌入式系统与电子时钟的设计和开发进行了综合分析,重点关注核心处理器的选择与评估、时钟显示技术的比较与组件选择、以及输入输出接口与外围设备的集成。首先,概述了嵌入式系统的基本概念和电子时钟的结构特点。接着,对处理器性能指标进行了评估,讨论了功耗管理和扩展性对系统效能和稳定性的重要性。在时钟显示方面,对比了不同显示技术的优劣,并探讨了显示模块设计和电源管理的优化策略。最后,本
【STM8L151电源设计揭秘】:稳定供电的不传之秘

# 摘要
本文对STM8L151微控制器的电源设计进行了全面的探讨,从理论基础到实践应用,再到高级技巧和案例分析,逐步深入。首先概述了STM8L151微控制器的特点和电源需求,随后介绍了电源设计的基础理论,包括电源转换效率和噪声滤波,以及STM8L151的具体电源需求。实践部分详细探讨了适合STM8L151的低压供电解决方案、电源管理策略和外围电源设计。最后,提供了电源设计的高级技巧,包括
NI_Vision视觉软件安装与配置:新手也能一步步轻松入门

# 摘要
本文系统介绍NI_Vision视觉软件的安装、基础操作、高级功能应用、项目案例分析以及未来展望。第一章提供了软件的概述,第二章详细描述了软件的安装流程及其后的配置与验证方法。第三章则深入探讨了NI_Vision的基础操作指南,包括界面布局、图像采集与处理,以及实际应用的演练。第四章着重于高级功能实
【VMware Workstation克隆与快照高效指南】:备份恢复一步到位

# 摘要
VMware Workstation的克隆和快照功能是虚拟化技术中的关键组成部分,对于提高IT环境的备份、恢复和维护效率起着至关重要的作用。本文全面介绍了虚拟机克隆和快照的原理、操作步骤、管理和高级应用,同时探讨了克隆与快照技术在企业备份与恢复中的应用,并对如何
【Cortex R52 TRM文档解读】:探索技术参考手册的奥秘
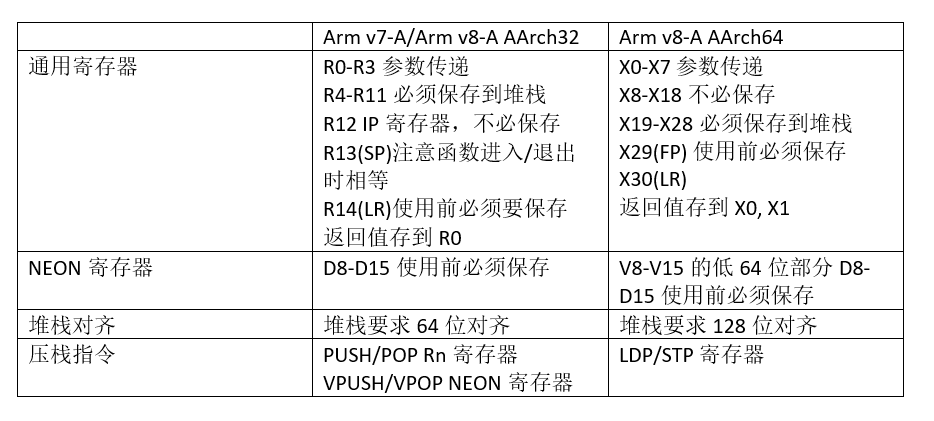
# 摘要
本文深入探讨了Cortex R52处理器的各个方面,包括其硬件架构、指令集、调试机制、性能分析以及系统集成与优化。文章首先概述了Cortex R52处理器的特点,并解析了其硬件架构的核心设计理念与组件。接着,本文详细解释了处理器的执行模式,内存管理机制,以及指令集的基础和高级特性。在调试与性能分析方面,文章介绍了Cortex R52的调试机制、性能监控技术和测试策略。最后,本文探讨了Cortex R52与外部组件的集成,实时操作系统支持,以及在特定应
西门子G120变频器安装与调试:权威工程师教你如何快速上手

# 摘要
西门子G120变频器在工业自动化领域广泛应用,其性能的稳定性与可靠性对于提高工业生产效率至关重要。本文首先概述了西门子G120变频器的基本原理和主要组件,然后详细介绍了安装前的准备工作,包括环境评估、所需工具和物料的准备。接下来,本文指导了硬件的安装步骤,强调了安装过程中的安全措施,并提供硬件诊断与故障排除的方法。此外,本文阐述了软件配置与调试的流程,包括控制面板操作、参数设置、调试技巧以及性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )