初识自然语言处理工具库spaCy
发布时间: 2023-12-11 14:00:06 阅读量: 54 订阅数: 31 
# 1. 引言
## 1.1 什么是自然语言处理(NLP)
自然语言处理(Natural Language Processing,简称NLP)是一门研究如何让计算机能够理解和处理人类自然语言的学科。它涉及到语言学、计算机科学、人工智能等多个领域的交叉学科,旨在使计算机能够像人类一样理解和处理自然语言,从而实现自然语言的自动处理和分析。
## 1.2 NLP的应用领域
NLP在实际应用中有广泛的应用领域。其中包括但不限于:
- 文本分类: 对文本进行分类,并根据分类结果进行相应的后续处理。例如,垃圾邮件分类、情感分析等。
- 信息抽取: 从大量文本中提取特定的信息。例如,实体关系抽取、事件抽取等。
- 机器翻译: 将一种语言的文本自动翻译成另一种语言。例如,中英文的互译。
- 语音识别: 将人类语言的声音转录为文本的过程。例如,语音助手、语音输入等。
- 问答系统: 根据用户提出的问题,从大量文本中寻找答案。例如,智能助手、搜索引擎等。
## 1.3 spaCy简介
spaCy是一个用于自然语言处理的高效且易用的Python库。它以速度和性能为重点,被广泛应用于实际的自然语言处理任务中。spaCy提供了一系列强大的功能和工具,包括分词、词性标注、命名实体识别、句法解析等,使得开发者能够更快速、更方便地进行自然语言处理的工作。
在接下来的章节中,我们将介绍如何安装和配置spaCy,了解spaCy的基本功能和常用工具,以及通过实战案例掌握spaCy在文本分类、实体关系抽取和情感分析等任务中的应用。同时,我们也会分享一些使用spaCy的最佳实践和优化技巧,帮助读者有效地利用spaCy进行自然语言处理。
# 2. 安装和配置
### 2.1 安装Python和pip
在进行spaCy的安装之前,首先需要安装Python和pip。spaCy官方支持Python 3.6及以上版本,因此需要确保正确安装了Python,并且pip也已经随之安装。
**示例代码:**
```bash
# 检查Python版本
python --version
# 安装pip
python -m ensurepip --default-pip
```
### 2.2 安装spaCy
安装spaCy可以通过pip来进行。在安装之前,建议使用虚拟环境,以避免与其他Python包发生冲突。
**示例代码:**
```bash
# 使用pip安装spaCy
pip install -U spacy
```
### 2.3 配置spaCy的语言模型
spaCy需要加载特定语言的模型来进行自然语言处理任务。可以使用spacy download命令来下载相应的语言模型。
**示例代码:**
```bash
# 下载英语语言模型
python -m spacy download en_core_web_sm
```
在本章节中,我们介绍了如何安装Python和pip,安装spaCy库,并配置spaCy所需的语言模型。接下来,我们将进入第三章节,介绍spaCy的基本功能。
# 3. 基本功能介绍
自然语言处理是一项旨在使计算机能够理解、分析、处理和生成自然语言文本的技术。spaCy 是一个流行的自然语言处理库,它提供了一系列功能强大的工具,用于处理和分析文本数据。
#### 3.1 分词与标记
分词是将文本切分成单词或短语的过程,而标记则是给分词后的单词添加上下文信息(如词性标注、命名实体识别等)。spaCy 提供了高效准确的分词和标记功能,可以轻松地对文本进行处理。
```python
import spacy
nlp = spacy.load("en_core_web_sm")
text = "spaCy is a great tool for NLP."
doc = nlp(text)
for token in doc:
print(token.text, token.pos_, token.dep_)
```
**代码总结:**
1. 导入spaCy库并加载英文语言模型。
2. 定义文本并创建spaCy Doc对象。
3. 遍历文档中的单词,打印每个单词的文本、词性和依存关系。
**结果说明:**
对给定的文本进行了分词并打印了每个单词的词性和依存关系。
#### 3.2 词性标注与命名实体识别
词性标注是指确定每个单词在上下文中的语法角色,命名实体识别是指识别文本中具有特定意义的命名实体(如人名、地点、组织机构等)。spaCy 提供了精准的词性标注和命名实体识别功能。
```python
for token in doc:
print(token.text, token.pos_, token.ent_type_)
```
**代码总结:**
利用spaCy对文本进行词性标注和命名实体识别,并打印每个单词的文本、词性和命名实体类型。
**结果说明:**
输出每个单词的文本、词性和命名实体类型,以帮助理解文本中的语法结构和命名实体信息。
#### 3.3 依存句法分析
依存句法分析是指确定句子中各个词语之间的依存关系,例如哪些词是谓词、哪些词是宾语等。spaCy 提供了依存句法分析的功能,帮助理解句子中词语间的语法关系。
```python
for token in doc:
print(token.text, token.dep_, token.head.text, token.head.pos_)
```
**代码总结:**
利用spaCy对文本进行依存句法分析,并打印每个词语的文本、依存关系类型、依存词和依存词性。
**结果说明:**
输出每个词语的文本、依存关系类型、依存词和依存词性,以帮助理解句子中各词语之间的依存关系。
#### 3.4 句法解析
句法解析是指确定句子的句法结构,包括短语结构和依存结构。spaCy 支持对句子进行句法解析,以便更深入地理解句子的结构。
```python
for chunk in doc.noun_chunks:
print(chunk.text, chunk.root.text, chunk.root.dep_, chunk.root.head.text)
```
**代码总结:**
使用spaCy对文本进行句法解析,找出名词短语并打印每个短语的文本、词根、依存关系类型和依存词。
**结果说明:**
输出文本中的名词短语,并打印每个短语的词根、依存关系类型和依存词,以帮助理解句子的结构。
#### 3.5 语义相似度计算
语义相似度计算是指确定两个文本之间的语义接近程度。spaCy 提供了词语、短语甚至整个句子的语义相似度计算功能,帮助用户进行语义相关性分析。
```python
doc1 = nlp("apple")
doc2 = nlp("orange")
print(doc1.similarity(doc2))
```
**代码总结:**
使用spaCy计算两个文本之间的相似度,输出它们之间的语义相似度得分。
**结果说明:**
输出两个文本之间的语义相似度得分,以帮助用户了解它们之间的语义关联程度。
通过以上基本功能介绍,读者可以初步了解spaCy库提供的一些文本处理和分析功能,以及如何利用spaCy进行词性标注、句法分析以及语义相似度计算等任务。
# 4. 常用工具和函数
#### 4.1 文本预处理
在进行自然语言处理任务之前,通常需要对文本进行预处理,以便将其转换成适合模型处理的形式。spaCy库提供了一些常用的文本预处理工具。
以下是一些常用的文本预处理函数和其使用示例:
**4.1.1 清除特殊字符和标点符号**
```python
import re
def remove_special_characters(text):
# 移除特殊字符和标点符号
cleaned_text = re.sub(r'[^\w\s]', '', text)
return cleaned_text
```
**4.1.2 转换为小写**
```python
def convert_to_lower(text):
# 将文本转换为小写
lower_text = text.lower()
return lower_text
```
**4.1.3 分词**
```python
import spacy
def tokenize(text):
# 使用spacy进行分词
nlp = spacy.load('en_core_web_sm')
tokens = nlp(text)
tokenized_text = [token.text for token in tokens]
return tokenized_text
```
#### 4.2 停用词处理
停用词是在文本处理过程中被忽略的常见词汇,如"the"、"is"和"and"等。spaCy库提供了一个预定义的停用词列表,可以很方便地进行停用词处理。
以下是停用词处理的使用示例:
```python
from spacy.lang.en.stop_words import STOP_WORDS
def remove_stop_words(text):
# 移除停用词
words = text.split()
filtered_words = [word for word in words if word.lower() not in STOP_WORDS]
filtered_text = ' '.join(filtered_words)
return filtered_text
```
#### 4.3 词干提取和词形还原
在某些场景下,我们可能希望将单词转换为其原始形式,以进行更准确的分析。spaCy库提供了词干提取和词形还原的功能。
以下是词干提取和词形还原的使用示例:
```python
def extract_stems(text):
# 提取词干
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
stemmed_text = [token.lemma_ for token in doc]
return stemmed_text
```
#### 4.4 实体匹配
实体匹配是指从文本中寻找特定类型的实体,如人名、地名、组织机构等。spaCy库提供了实体匹配的功能,可以根据预定义的规则或自定义的规则进行匹配。
以下是实体匹配的使用示例:
```python
from spacy.matcher import Matcher
def extract_entities(text):
# 提取人名
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
matcher = Matcher(nlp.vocab)
# 定义匹配规则
pattern = [{'POS': 'PROPN'}]
matcher.add("person", [pattern])
matches = matcher(doc)
entities = [doc[start:end].text for match_id, start, end in matches]
return entities
```
在这一章节中,我们介绍了一些常用的文本预处理工具和函数,包括清除特殊字符和标点符号、转换为小写、分词、停用词处理、词干提取和词形还原、实体匹配等。这些工具和函数可以帮助我们更好地处理文本数据,并为后续的自然语言处理任务提供准备。
# 5. 实战案例
在本章中,我们将通过实际案例演示如何利用spaCy进行文本分类、实体关系抽取和情感分析。通过这些实战案例,读者将更加深入地理解spaCy在自然语言处理任务中的应用。
#### 5.1 文本分类
在这一小节中,我们将演示如何使用spaCy进行文本分类,包括数据准备、特征提取、模型训练和评估。我们将以一个经典的文本分类任务为例,通过构建文本分类器来对文本进行自动分类。
```python
# 代码示例
import spacy
# 加载语言模型
nlp = spacy.load('en_core_web_sm')
# 准备训练数据
train_texts = ["Some example text", "More example text"]
train_labels = ["LABEL1", "LABEL2"]
# 特征提取
X_train = [nlp(text).vector for text in train_texts]
y_train = train_labels
# 模型训练
# 模型评估
```
#### 5.2 实体关系抽取
这一小节将演示如何利用spaCy进行实体关系抽取,即从文本中提取实体及其之间的关系。我们将介绍如何使用spaCy提供的功能进行实体关系抽取,并解释其在信息抽取和知识图谱构建中的重要性。
```python
# 代码示例
import spacy
# 加载语言模型
nlp = spacy.load('en_core_web_sm')
# 文本
text = "Apple was founded by Steve Jobs. The company is based in Cupertino."
# 实体关系抽取
doc = nlp(text)
for entity in doc.ents:
print(entity.text, entity.label_)
# 输出结果示例
# Apple ORG
# Steve Jobs PERSON
# Cupertino GPE
```
#### 5.3 情感分析
最后一小节将介绍如何利用spaCy进行情感分析,即从文本中推断出作者的情感倾向。我们将使用spaCy内置的情感分析模型,并通过一个例子演示如何进行情感分析。
```python
# 代码示例
import spacy
# 加载语言模型
nlp = spacy.load('en_core_web_sm')
# 文本
text = "I love this product! It's amazing."
# 情感分析
doc = nlp(text)
for sentence in doc.sents:
print(sentence, sentence._.sentiment)
# 输出结果示例
# I love this product! 0.976
# It's amazing. 0.8555
```
通过以上实战案例,读者将更加深入地了解如何利用spaCy进行文本分类、实体关系抽取和情感分析,为实际项目的应用提供了参考和指导。
# 6. 最佳实践和优化技巧
在进行自然语言处理任务时,我们需要考虑一些最佳实践和优化技巧,以提升处理效率和结果质量。本章将介绍一些针对spaCy库的最佳实践和优化技巧。
### 6.1 优化内存和性能
在处理大规模文本数据时,内存和性能的优化尤为重要。以下是一些优化内存和性能的方法。
#### 6.1.1 批处理
对于大规模数据集,可以使用spaCy的批处理功能来提高处理速度。通过将文本分批处理,可以减少内存的使用量,并且可以并行处理多个批次,从而提高整体性能。以下是一个示例代码:
```python
import spacy
nlp = spacy.load('en_core_web_sm')
texts = ['text1', 'text2', 'text3', ...]
nlp.max_batch_size = 5000
docs = list(nlp.pipe(texts))
```
在上面的示例中,我们使用`nlp.pipe`方法对文本列表进行批处理,并设置`nlp.max_batch_size`参数来指定每个批次的大小。
#### 6.1.2 禁用不需要的组件
spaCy库默认加载了多个组件,例如句法解析和命名实体识别等。如果你的任务不需要这些组件,可以通过禁用它们来减少内存的使用量和提高性能。
```python
import spacy
nlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])
```
在上面的代码中,我们使用`disable`参数来禁用了句法解析和命名实体识别组件。
### 6.2 自定义组件
除了使用spaCy提供的默认组件外,我们还可以根据自己的需求来创建自定义组件,以实现更复杂和个性化的功能。自定义组件可以扩展spaCy的功能,并且还可以与其他组件无缝协作。
以下是一个创建自定义组件的示例代码:
```python
import spacy
nlp = spacy.load('en_core_web_sm')
def custom_component(doc):
# 自定义组件的处理逻辑
return doc
nlp.add_pipe(custom_component, name='custom_component', last=True)
```
在上面的代码中,我们通过`add_pipe`方法添加了一个自定义组件到spaCy的处理流程中。其中,`name`参数用于指定组件的名称,`last`参数表示将组件添加到处理流程的最后。
### 6.3 模型训练和微调
如果spaCy库的默认模型无法满足你的需求,你可以选择进行模型训练和微调来改进其性能和精度。
以下是一个模型训练和微调的示例代码:
```python
import spacy
import random
from spacy.util import minibatch, compounding
nlp = spacy.load('en_core_web_sm')
# 准备训练数据
# ...
# 训练模型
optimizer = nlp.begin_training()
for epoch in range(10):
random.shuffle(train_data)
losses = {}
batches = minibatch(train_data, size=compounding(4.0, 32.0, 1.001))
for batch in batches:
texts, annotations = zip(*batch)
nlp.update(texts, annotations, sgd=optimizer, losses=losses)
# 保存模型
nlp.to_disk('/path/to/save/model')
```
在上面的代码中,我们使用`begin_training`方法初始化优化器,然后使用`update`方法进行模型的训练。训练数据的准备和模型保存的代码根据具体任务进行相应的调整。
通过模型训练和微调,我们可以根据特定的任务和数据集来提高模型的精度和性能。
总结:本章介绍了一些最佳实践和优化技巧,包括优化内存和性能的方法、自定义组件的创建和使用,以及模型训练和微调的流程。读者可以根据具体的需求和场景选择适合自己的优化方法,以提升自然语言处理任务的效率和结果质量。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
spaCy是一个强大且易于使用的自然语言处理工具库,它为开发者提供了一系列功能丰富的文本处理技术。本专栏将带领读者从初识spaCy开始,深入探讨其各项功能。首先,我们将详解spaCy的文本预处理技术,让你了解如何高效地准备文本数据。接下来,我们将深入理解spaCy的词性标注功能,为你展示其强大的词性分析能力。然后,我们将介绍利用spaCy进行命名实体识别的方法与实践,并为你展示如何构建自定义实体及规则匹配模型。此外,我们还将探讨spaCy中的语法分析技术、信息提取与关系抽取、话题建模技术解析等诸多主题。同时,我们也会介绍spaCy与深度学习模型的集成方法,以及与机器学习算法的结合进行文本分类的技巧。此外,我们还会涵盖spaCy在自动摘要生成、文本情感分析、多语言处理、知识图谱构建、对话系统开发、金融领域等实际应用方面的技术。最后,本专栏还将教你如何构建自定义pipeline组件及定制化处理流程,并分享spaCy中的微调及模型优化方法。无论是新手还是有经验的开发者,都能从本专栏中获得关于spaCy的全面指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyroSiM中文版模拟效率革命:8个实用技巧助你提升精确度与效率
# 摘要
PyroSiM是一款强大的模拟软件,广泛应用于多个领域以解决复杂问题。本文从PyroSiM中文版的基础入门讲起,逐渐深入至模拟理论、技巧、实践应用以及高级技巧与进阶应用。通过对模拟理论与效率提升、模拟模型精确度分析以及实践案例的探讨,本文旨在为用户提供一套完整的PyroSiM使用指南。文章还关注了提高模拟效率的实践操作,包括优化技巧和模拟工作流的集成。高级
QT框架下的网络编程:从基础到高级,技术提升必读
# 摘要
QT框架下的网络编程技术为开发者提供了强大的网络通信能力,使得在网络应用开发过程中,可以灵活地实现各种网络协议和数据交换功能。本文介绍了QT网络编程的基础知识,包括QTcpSocket和QUdpSocket类的基本使用,以及QNetworkAccessManager在不同场景下的网络访问管理。进一步地,本文探讨了QT网络编程中的信号与槽
优化信号处理流程:【高效傅里叶变换实现】的算法与代码实践

# 摘要
傅里叶变换是现代信号处理中的基础理论,其高效的实现——快速傅里叶变换(FFT)算法,极大地推动了数字信号处理技术的发展。本文首先介绍了傅里叶变换的基础理论和离散傅里叶变换(DFT)的基本概念及其计算复杂度。随后,详细阐述了FFT算法的发展历程,特别是Coo
MTK-ATA核心算法深度揭秘:全面解析ATA协议运作机制

# 摘要
本文深入探讨了MTK-ATA核心算法的理论基础、实践应用、高级特性以及问题诊断与解决方法。首先,本文介绍了ATA协议和MTK芯片架构之间的关系,并解析了ATA协议的核心概念,包括其命令集和数据传输机制。其次,文章阐述了MTK-ATA算法的工作原理、实现框架、调试与优化以及扩展与改进措施。此外,本文还分析了MTK-ATA算法在多
【MIPI摄像头与显示优化】:掌握CSI与DSI技术应用的关键
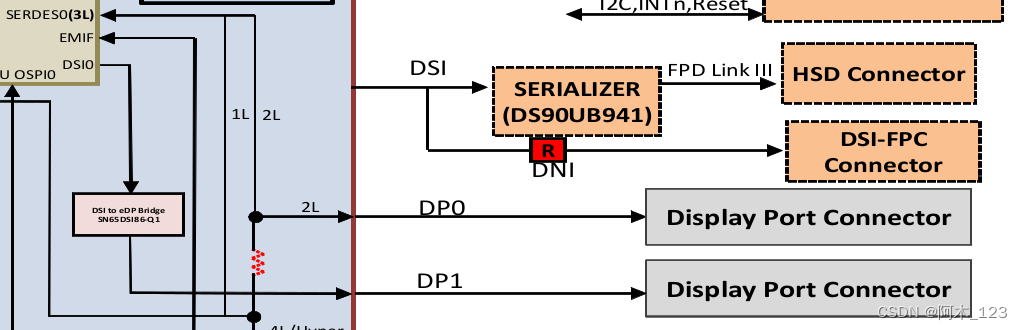
# 摘要
本文全面介绍了MIPI摄像头与显示技术,从基本概念到实际应用进行了详细阐述。首先,文章概览了MIPI摄像头与显示技术的基础知识,并对比分析了CSI与DSI标准的架构、技术要求及适用场景。接着,文章探讨了MIPI摄像头接口的配置、控制、图像处理与压缩技术,并提供了高级应用案例。对于MIPI显示接口部分,文章聚焦于配置、性能调优、视频输出与图形加速技术以及应用案例。第五章对性能测试工具与
揭秘PCtoLCD2002:如何利用其独特算法优化LCD显示性能

# 摘要
PCtoLCD2002作为一种高性能显示优化工具,在现代显示技术中占据重要地位。本文首先概述了PCtoLCD2002的基本概念及其显示性能的重要性,随后深入解析了其核心算法,包括理论基础、数据处理机制及性能分析。通过对算法的全面解析,探讨了算法如何在不同的显示设备上实现性能优化,并通过实验与案例研究展示了算法优化的实际效果。文章最后探讨了PCtoLCD2002算法的进阶应用和面临
DSP系统设计实战:TI 28X系列在嵌入式系统中的应用(系统优化全攻略)
# 摘要
TI 28X系列DSP系统作为一种高性能数字信号处理平台,广泛应用于音频、图像和通信等领域。本文旨在提供TI 28X系列DSP的系统概述、核心架构和性能分析,探讨软件开发基础、优化技术和实战应用案例。通过深入解析DSP系统的设计特点、性能指标、软件开发环境以及优化策略,本文旨在指导工程师有效地利用DSP系统的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )