初步了解:MapReduce中的Map函数
发布时间: 2023-12-16 14:08:42 阅读量: 56 订阅数: 22 

MapReduce基础
# 1. 引言
## 1.1 MapReduce简介
MapReduce是一种分布式计算框架,主要用于处理大规模数据集。它通过将数据分片处理,并在集群中并行执行,以提高数据处理的效率和速度。MapReduce框架最初由Google开发,并在2004年的一篇论文中正式介绍,随后被Apache Hadoop项目采用和推广。
## 1.2 MapReduce的工作原理
MapReduce的工作原理是基于两个主要的操作:Map(映射)和Reduce(归并)。Map操作将输入数据转换为键值对的集合,再由Reduce操作将相同键的数据进行合并和计算。整个过程可以分为三个阶段:分片和分发、Map操作和Reduce操作。
## 1.3 Map函数在MapReduce中的作用
Map函数是MapReduce中的一个重要组成部分,它负责执行具体的数据处理逻辑。Map函数的输入是一对键值对,输出也是一对键值对。Map函数根据业务需求,将输入数据映射为中间结果,供Reduce函数后续的处理使用。
Map函数在MapReduce中起到以下几个作用:
- 数据分片:将输入数据划分为多个片段,并将每个片段分配给不同的Map任务进行处理。
- 数据转换:根据业务逻辑,将输入数据转换为中间结果,并输出给Reduce函数。
- 数据过滤和清洗:对输入数据进行预处理,包括清除无效数据、过滤掉不必要的信息等。
- 数据聚合和计算:根据业务需求,对输入数据进行聚合和计算,生成最终的输出结果供Reduce函数使用。
Map函数的设计和实现直接影响MapReduce的性能和效率。在接下来的章节中,我们将详细讨论Map函数的定义、输入数据处理、业务逻辑处理和输出数据处理等方面的内容。
# 2. Map函数的定义与基本结构
### 2.1 Map函数的定义
Map函数是MapReduce编程模型中的一个关键组件,它负责处理输入数据并生成中间结果。在MapReduce中,Map函数是一种并行的计算方式,它将输入数据逐个转换为键值对,并将这些键值对作为中间结果输出。
Map函数的定义可以简单概括为:对于给定的输入数据,逐个处理元素,并将处理结果输出为键值对。具体而言,Map函数接受一对输入键值对 (key, value),经过处理后,产生一组中间键值对 (intermediateKey, intermediateValue)。其中,输入键值对表示原始数据的一条记录,中间键值对表示经过处理后的数据。
### 2.2 Map函数的输入与输出
Map函数的输入数据是划分好的数据块或数据片段。对于大规模数据集,这些数据块通常会被划分成若干个逻辑分片,每个分片包含一部分数据记录。
Map函数的输出数据是中间结果的一组键值对。在Map函数执行过程中,对输入数据进行处理后生成的每个键值对都会被输出。这些中间结果将供Reduce函数进行进一步处理和聚合。
### 2.3 Map函数的基本结构
Map函数的基本结构一般包括以下几个步骤:
**步骤一:接收输入数据**
首先,Map函数需要从输入数据源中获取数据块或数据片段。这些数据可以存储在各种数据存储介质中,如HDFS、数据库或内存中。
**步骤二:数据处理与转换**
接收到输入数据后,Map函数将对数据进行逐个处理。根据具体业务需求,Map函数可以进行各种复杂的数据转换、计算或分析操作。常见的处理方式包括数据清洗、数据提取、数据转换、特征抽取等。
**步骤三:生成中间结果**
经过数据处理与转换后,Map函数会生成一组中间结果。每个中间结果都是一个键值对,其中键表示数据的某个属性或特征,值则表示该属性对应的统计结果或计算值。
**步骤四:输出中间结果**
最后,Map函数将生成的中间结果输出。这些中间结果将会作为输入传递给Reduce函数进行进一步处理和聚合。输出的中间结果通常会进行排序和归并操作,以方便后续的Reduce阶段处理。
综上所述,Map函数在MapReduce编程模型中扮演了非常重要的角色。它负责处理输入数据并生成中间结果,为Reduce函数提供输入数据,从而实现数据的分片、处理和聚合。正确编写和优化Map函数可以提高整个MapReduce作业的执行效率和性能。在接下来的章节中,将详细探究Map函数在数据输入、业务逻辑处理和输出数据处理方面的具体实现细节。
# 3. Map函数的输入数据处理
在MapReduce中,Map函数是对输入数据进行处理的核心部分。本章将介绍Map函数应如何处理输入数据,包括数据分片与分布、输入数据的读取与解析,以及输入数据的预处理与清洗。
### 3.1 数据分片与分布
在MapReduce中,输入数据一般会被分割成多个数据块,并分布在不同的计算节点上进行并行处理。数据分片的目的是为了提高处理速度和可扩展性。通常,分片策略可以根据数据大小、处理能力、网络带宽等因素进行灵活调整。
数据分片与分布的过程由MapReduce框架自动完成,无需手动干预。在执行Map函数之前,框架会将输入数据块分发给各个计算节点,并将相应的数据块路径信息传递给Map函数。
### 3.2 输入数据的读取与解析
Map函数需要从输入数据中获取数据记录,并将其解析为可供处理的数据格式。具体的数据读取与解析方式根据输入数据的格式来确定。一般来说,常见的数据格式有文本文件、CSV文件、JSON文件等。
以文本文件为例,可以使用文件读取操作来获取每行数据,并对数据进行处理。以下是一个简单的Java代码示例:
```java
// 读取文本文件,将每行数据作为输入数据
try {
BufferedReader reader = new BufferedReader(new FileReader("input.txt"));
String line;
while ((line = reader.readLine()) != null) {
// 处理数据操作
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
```
对于其他格式的文件,可以使用相应的库或工具进行读取和解析操作。例如,可以使用CSVParser来读取和解析CSV文件,使用JSON库来读取和解析JSON文件。
### 3.3 输入数据的预处理与清洗
在处理输入数据之前,通常需要对数据进行预处理和清洗,以提高数据的质量和准确性。预处理和清洗的步骤可以包括去除无效数据、去除重复数据、转换数据格式等。
预处理和清洗的方式取决于数据的具体情况和需求。例如,在文本数据中,可以使用正则表达式来匹配和替换指定的字符或字符串。以下是一个Python的示例:
```python
import re
# 预处理和清洗文本数据
data = "Hello, world!"
cleaned_data = re.sub(r"[^\w\s]", "", data) # 去除标点符号
```
除了使用正则表达式,还可以使用其他数据处理和转换的方法,如字符串操作、数据转换工具等,根据实际需求进行选择和使用。
以上是Map函数的输入数据处理过程。通过合适的数据分片与分布,以及正确的数据读取、解析和预处理,可以使Map函数能够高效、准确地处理输入数据,并为后续的业务逻辑处理奠定良好的基础。
下一章节将介绍Map函数的业务逻辑处理,包括具体的业务逻辑、执行效率的优化和异常情况的处理。
# 4. Map函数的业务逻辑处理
在MapReduce中,Map函数是用来处理输入数据的关键部分之一。Map函数的主要作用是将输入的数据进行业务逻辑处理,将其转化为键值对形式的中间数据,以便后续的Shuffle和Reduce环节使用。本章将详细介绍Map函数的具体业务逻辑、执行效率的优化以及处理特殊情况的异常情况处理。
#### 4.1 Map函数的具体业务逻辑
在编写Map函数时,我们需要根据具体的业务需求来定义数据处理逻辑。通常情况下,Map函数会对输入的每一条数据进行处理,并生成相应的键值对。在处理大数据时,为了提高执行效率,需要尽量编写简洁高效的业务逻辑。
以下是一个简单的示例,假设我们需要对输入数据中的单词进行计数:
```python
# 伪代码示例
def map_function(input_key, input_value):
# 将输入的文本内容按空格切分为单词列表
words_list = input_value.split()
# 遍历单词列表,每个单词生成一个键值对,键为单词,值为1
for word in words_list:
emit_intermediate(word, 1)
```
在上述示例中,map_function函数接收输入的键和值,首先对值进行处理,将文本内容切分为单词列表,然后遍历单词列表,为每个单词生成一个键值对,键为单词,值为1。这样就完成了对输入数据的处理,并生成了中间数据。
#### 4.2 如何优化Map函数的执行效率
为了提高Map函数的执行效率,我们可以采取一些常见的优化策略,例如:
- 减少不必要的内存和磁盘I/O操作,尽量使用内存计算,减少数据倾斜。
- 使用合适的数据结构和算法,例如使用哈希表来快速查找和更新中间结果。
- 考虑并行处理,将输入数据划分为多个片段并行处理,以提高处理速度。
#### 4.3 处理特殊情况的异常情况处理
在实际应用中,可能会遇到一些特殊情况,例如输入数据格式异常、网络异常等,这时候我们需要在Map函数中添加相应的异常处理逻辑,保证程序的稳定运行。
以下是一个简单的异常处理示例,假设在处理过程中可能会遇到输入数据为空的情况:
```python
# 伪代码示例
def map_function(input_key, input_value):
if input_value is None or input_value == "":
# 处理空数据,可以记录日志或者直接忽略
log("Empty input data")
return
# 正常处理逻辑
# ...
```
在上面的示例中,我们添加了针对空数据的异常处理逻辑,以避免空数据对后续处理造成影响。
通过以上对Map函数的业务逻辑处理、执行效率优化和异常情况处理的介绍,我们可以更好地理解Map函数在MapReduce中的重要性和作用,以及在实际场景中的应用技巧和注意事项。
# 5. Map函数的输出数据处理
在MapReduce中,Map函数的输出数据是生成Reduce函数的输入数据。因此,Map函数的输出数据处理非常重要,它涉及到结果的排序、归并和写入存储等方面。本章将详细介绍Map函数的输出数据处理过程。
### 5.1 Map函数的输出数据格式与结构
Map函数的输出数据通常采用键值对(key-value)的形式。在Java中,常用的数据结构是`MapWritable`,它是`Writable`接口的实现类,用于表示键值对。在Python中,常用的数据结构是字典(dictionary),其中键表示数据的类型,值表示数据的具体值。
具体来说,Map函数的输出数据结构可以定义如下:
```java
public class MapOutput {
private Object key;
private Object value;
// 构造函数、Getter和Setter方法等省略
}
```
```python
class MapOutput:
def __init__(self, key, value):
self.key = key
self.value = value
# 其他方法省略
```
### 5.2 输出数据的排序与归并
Map函数的输出数据通常是分布式存储的,可能存在于不同的节点上。因此,在将数据传递给Reduce函数之前,需要对Map函数的输出数据进行排序和归并。
在Java中,可以使用`JobConf`的`setOutputKeyComparatorClass`方法和`setOutputValueGroupingComparator`方法指定按键值进行排序和分组。在Python中,可以使用`sorted`函数对字典列表进行排序,并使用`groupby`函数进行分组。
具体的排序与归并操作可以参考以下示例代码:
```java
// Java示例代码
public class MapOutputComparator extends WritableComparator {
public MapOutputComparator() {
super(MapOutput.class, true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
MapOutput outputA = (MapOutput) a;
MapOutput outputB = (MapOutput) b;
// 根据键值进行排序
int compareResult = outputA.getKey().compareTo(outputB.getKey());
return compareResult;
}
}
// Python示例代码
def sort_and_group(map_outputs):
from itertools import groupby
# 对Map函数的输出数据按键值进行排序
sorted_outputs = sorted(map_outputs, key=lambda x: x.key)
# 对排序后的输出数据按键值进行分组
grouped_outputs = groupby(sorted_outputs, key=lambda x: x.key)
return grouped_outputs
```
### 5.3 输出数据的写入与存储
Map函数的输出数据处理完成后,需要将数据写入存储介质,以便Reduce函数进行处理。常用的存储介质包括本地文件、数据库、分布式文件系统等。
在Java中,可以使用`Context`的`write`方法将数据写入存储介质。在Python中,可以使用文件操作或数据库操作的相关函数将数据写入存储介质。
以下是Java和Python示例代码:
```java
// Java示例代码
public class MapFunction extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// Map函数的业务逻辑处理
// 将处理结果写入存储介质
context.write(word, one);
}
}
// Python示例代码
def map_function(key, value):
# Map函数的业务逻辑处理
# 将处理结果写入存储介质
write_to_storage(key, value)
```
在实际应用中,可以根据具体的需求选择合适的存储介质,并设计相应的写入逻辑。
本章介绍了Map函数的输出数据处理过程,包括数据格式与结构、排序与归并以及写入与存储。对于Map函数的输出数据处理,需要根据具体情况选择合适的数据结构和排序策略,并确保数据能够顺利地写入存储介质中,以供Reduce函数进行下一步处理。
# 6. 案例分析与实践应用
在本章中,我们将通过具体的案例分析和实践应用来深入理解Map函数在大数据处理中的作用和价值,以及在实际项目中使用Map函数的经验与技巧。
#### 6.1 实例分析:使用Map函数解决大数据处理问题
在这一节中,我们将介绍一个实际的案例,通过使用Map函数来解决大数据处理问题。我们将展示具体的代码实现,并分析其效果和优化方法。
以下是一个简化的示例代码,使用Python语言实现Map函数处理大量文本数据的案例:
```python
# 导入必要的库
import re
# 定义Map函数
def map_function(line):
# 对输入的文本数据进行分词处理
words = re.findall(r'\b\w+\b', line)
# 遍历词列表,输出键值对
word_count_pairs = [(word, 1) for word in words]
return word_count_pairs
# 读取文本数据
input_data = [
"MapReduce is a programming model and an associated implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.",
"The MapReduce algorithm contains two important tasks, namely Map and Reduce.",
"Map takes a set of data and converts it into another set of data, where individual elements are broken down into tuples (key/value pairs)."
]
# 调用Map函数处理数据
mapped_data = []
for line in input_data:
mapped_data.extend(map_function(line))
# 输出处理结果
print(mapped_data)
```
通过上述代码示例,我们可以看到Map函数的具体实现和处理过程,它将输入数据分割、处理,并生成键值对输出。在实际项目中,我们可以根据具体的业务需求对Map函数进行进一步的优化和扩展,比如增加数据过滤、采样和数据聚合等操作,以提高处理效率和准确性。
#### 6.2 实践应用:在实际项目中使用Map函数的经验与技巧
在这一节中,我们将分享在实际项目中使用Map函数的经验和技巧,包括如何合理设计Map函数、处理大规模数据时的注意事项、以及如何优化Map函数的执行效率等方面的经验。
在实际项目中,我们通常会遇到各种复杂的业务需求和数据处理场景,合理而高效地使用Map函数是非常重要的。例如,可以通过使用高性能的数据结构、并行处理和分布式计算等技术手段,来优化Map函数的执行效率;同时,对于特定的业务场景,也可以结合Map函数与其他数据处理技术(如Filter、Reduce等)来实现更加复杂的数据处理逻辑。
#### 6.3 主流Map函数的比较与选择
在这一节中,我们将对主流的Map函数进行比较与选择,分析不同的Map函数在处理大数据时的优劣势,以及如何根据具体的业务需求来选择合适的Map函数实现。
在实际项目中,我们可能会遇到多种Map函数的选择,比如Hadoop MapReduce、Spark的Map函数、Flink的Map函数等。针对不同的场景和需求,我们需要权衡它们在性能、扩展性、容错性等方面的差异,选择最适合的Map函数来实现我们的业务逻辑。
通过以上实例分析和实践经验的分享,我们可以更加全面地了解Map函数在大数据处理中的应用和实践,为我们在实际项目中合理地运用Map函数提供参考和指导。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏主要介绍MapReduce技术及其各个方面的应用。首先,通过简明介绍,帮助读者初步了解什么是MapReduce技术以及其基本原理。接着,通过初级教程和初学者指南,详细介绍了MapReduce中的Map和Reduce函数的作用和使用方法,以及如何编写MapReduce程序。然后,通过深入剖析和高级技巧,讲解了MapReduce的数据流程、分区和排序等高级技术。随后,通过优化指南和实用示例,提供了提升MapReduce程序性能的优化策略和实战经验。此外,还介绍了如何编写自定义的MapReduce数据类型、使用Combiner函数、调整并发度以及使用压缩技术等高级技术和优化策略。最后,通过实际案例和进阶教程,展示了MapReduce在数据清洗、数据聚合、图计算、文本处理、机器学习和图像处理等方面的实际应用。整个专栏致力于帮助读者全面了解和掌握MapReduce技术,并能够运用于各种实际问题中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
新手必读:VITA57.1接口卡标准规范与应用入门

# 摘要
VITA57.1接口卡作为模块化标准平台,对现代电子系统的硬件扩展和性能优化发挥着关键作用。本文首先介绍了VITA57.1接口卡的基本概念、标准规范及其在硬件结构方面的详细剖析,包括物理特性、模块化设计、热管理和散热解决方案。随后,文章探讨了软件支持与开发环境,涉及驱动程序、开发工具、调试环境以及与主流平台的集成方法。在应用案例分
四层板协同设计:信号层与电源层的完美配合

# 摘要
随着电子系统复杂性的增加,四层板设计在高速数字系统中的应用日益广泛。本文首先介绍了四层板设计的基本概念,随后深入探讨了信号层设计的理论基础,包括信号完整性的定义、影响以及布局原则,并分析了信号层与电源层的交互作用。第三章详述了电源层设计的结构、功能、设计原则及其与信号层的协同优化。第四章通过实际案例分析和测试验证,展示了信号层与电源层设计的应用实践。最后,第五章展望了四层板设计在高速数字系统、热管理、电磁兼容性方
【IQ2010 WIFI频段干扰解决方案】:提升无线网络性能的秘密武器
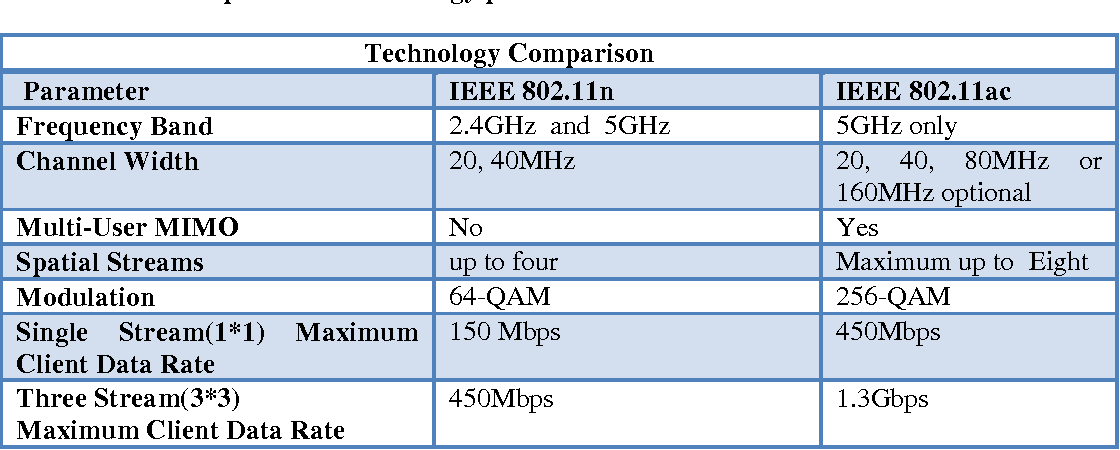
# 摘要
随着无线网络的广泛部署,WIFI频段干扰已成为影响网络性能和用户体验的重要问题。本文从WIFI频段干扰的基础知识出发,深入探讨了干扰的原因和机制,以及干扰对网络性能和用户体验的具体影响。在此基础上,本文详细介绍了IQ2010 WIFI频段干扰解决方案的理论基础、工作原理、优势分析,并讨论了该方案在实践应用中的安装配置、性能测试和进阶应用。通过对IQ201
技术文档背后的逻辑:BOP2_BA20_022016_zh_zh-CHS.pdf深度解读

# 摘要
技术文档作为信息技术领域的基石,在信息交流、知识传承与专业技能传播中扮演着至关重要的角色。本文深入探讨了技术文档的重要性与作用,以及如何通过分析文档结构来有效地提取和理解其中的信息。通过研究文档编写前的准备工作、写作技巧及视觉辅助的运用,以及格式与排版设计对信息传达效率的影响,我们提出了提升技术文档编
【SEO优化策略】:提升花店网页在搜索引擎的排名

# 摘要
本文全面介绍了搜索引擎优化(SEO)的基础知识、关键词研究、内容创作、技术SEO实施以及SEO策略的监控与调整。首先,章节一为读者提供了SEO优化的基本概念。随后,章节二深入探讨了关键词的选择、布局和效果分析,强调了长尾关键
ADS1256在STM32上的性能优化:提升数据采集效率的关键
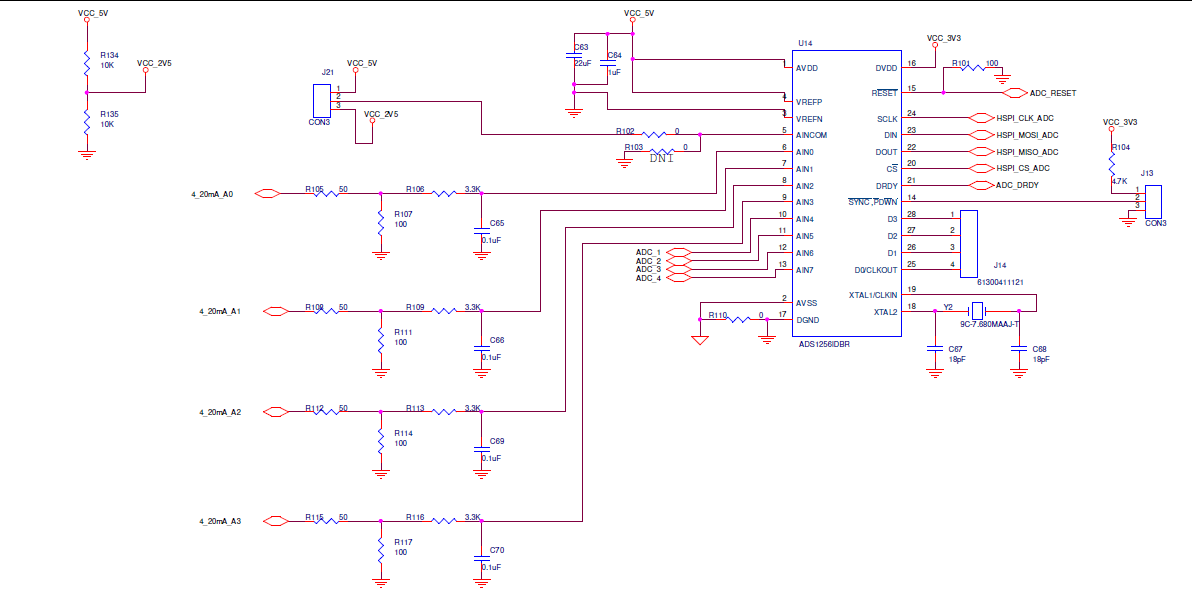
# 摘要
本文对ADS1256在STM32平台上的应用及其性能优化进行了详细探讨。首先介绍了ADS1256与STM32的基础知识,包括硬件连接和初始化步骤,以及基本数据读取与处理方法。随后,论文深入分析了性能瓶颈的理论基础,探讨了性能优化的策略,如缓存和中断处理的优化,以及性能测试的实施与
【提升S7-200 SMART采集效率】:Kepware数据处理高级技巧揭秘
# 摘要
本论文系统地介绍了Kepware在S7-200 SMART应用中的实践,涵盖了数据采集、配置、性能优化及故障排除等方面。首先,文章概述了Kepware与S7-200 SMART的连接配置,包括硬件接口、通信协议选择和驱动安装。接着,重点探讨了数据模型、点管理、同步机制以及如何通过性能监控、数据请求优化和缓存策略来提升数据采集效率。在高级数据处理方面,论文详细阐述了结构化数据的映射、解析技术及事件驱动采集的策略。最后,本文提供了系统稳定性维护的策略,并通过行业案例分析展望了Kepware技术的未来发展趋势。
# 关键字
Kepware;S7-200 SMART;数据采集;性能优化;故
存储效率倍增术:IBM M5210阵列性能优化的5大策略
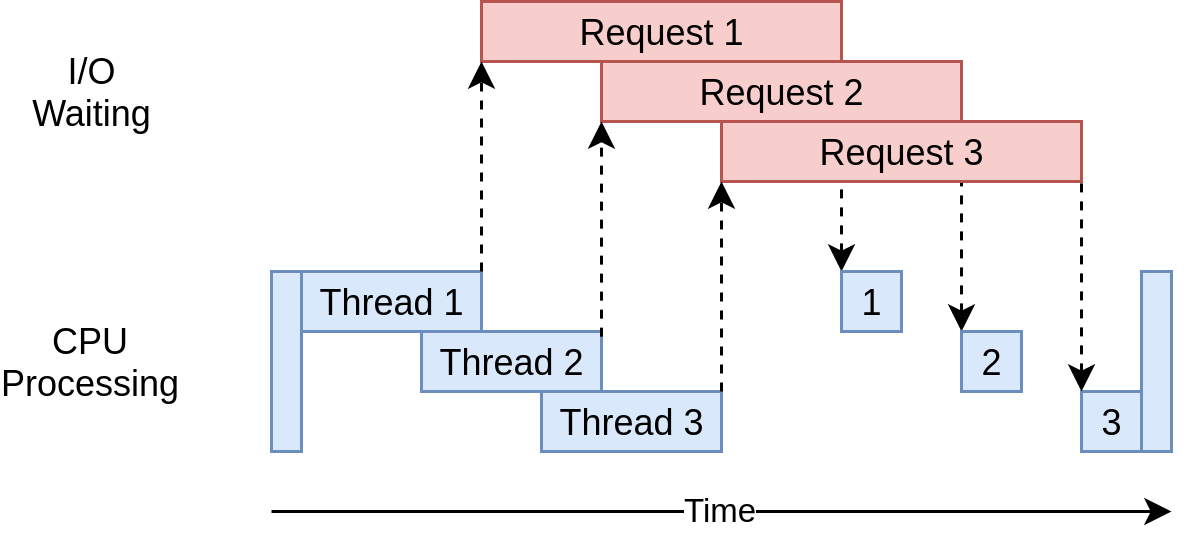
# 摘要
随着企业数据量的不断增长,对存储系统性能的要求也日益提高。本文首先概述了IBM M5210存储阵列的功能与特点,随后介绍了性能优化的理论基础,并对存储性能关键指标进行了详细解析。本文进一步深入探讨了存储系统架构优化原则,包括RAID配置、存储池设计、缓存优化等方面的策略和影响。在实践中,对IBM M5210通过硬件升级、软件调整、系统监控和故障诊断等手段进行性能调优,并通过多个案例分析,展示了在
【水晶报表自定义公式详解】:报告灵活性提升的秘密
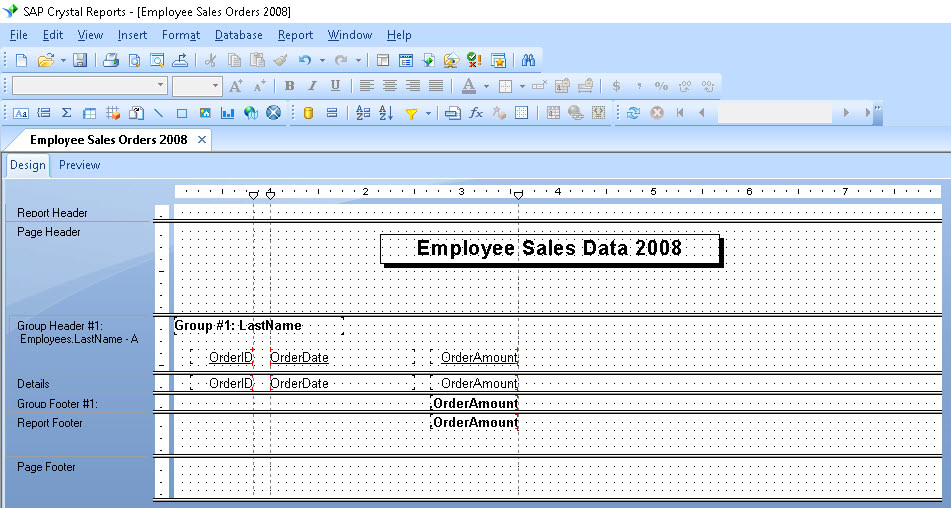
# 摘要
水晶报表是企业级数据可视化的重要工具,能够通过自定义公式实现复杂的数据处理与展示。本文首先介绍了水晶报表的基本概念与功能,然后详细阐述了自定义公式的理论基础,包括其定义、结构、逻辑与比较运算以及数学和字符串函数的使用。进阶部分,文章探讨了高级应用,如处理复杂数据类型、创建和使用自定义函数,以及错误处理与调试技巧。通过实践案例分析,本文展示了公式的实际应用,如需求分析转换、数据汇总和性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )