【系统监控与调优】:Linux性能终极优化指南
发布时间: 2025-01-07 11:20:40 阅读量: 9 订阅数: 5 

VM调优实战指南:GC与性能优化
# 摘要
本文旨在探讨Linux系统的性能监控与调优策略。首先介绍了Linux性能监控的基础知识,然后通过实践案例深入讲解了系统资源监控,包括CPU、内存、磁盘I/O和网络性能的监控与分析。接着,文章深入分析了性能分析工具的使用和高级功能,并探讨了系统调优的基础知识与关键性能参数的优化方法。最后,本文提供了常见故障模式的诊断方法和预防性维护策略,强调了自动化监控在性能优化和故障预防中的重要性。整体而言,本文为Linux系统管理员提供了一套完整的性能监控、分析和调优指南。
# 关键字
Linux性能监控;系统资源分析;性能分析工具;性能调优;故障诊断;自动化监控
参考资源链接:[图解微积分基础:从函数到积分应用](https://wenku.csdn.net/doc/3wkprnprex?spm=1055.2635.3001.10343)
# 1. Linux性能监控基础
## 简介
Linux性能监控是确保系统稳定运行和高效响应的关键。本章节旨在为读者提供性能监控的理论基础和实践指南,从系统资源的监控到性能分析工具的应用,再到性能调优的策略,全面覆盖。
## 监控的重要性
在今天日益复杂的系统环境中,性能监控对于预防系统故障、优化资源分配以及提升用户体验至关重要。监控数据可为系统管理员提供决策支持,帮助他们快速定位问题,采取措施并优化系统。
## 基础知识概述
- **系统资源监控**:包括CPU、内存、磁盘I/O、网络等核心资源的使用情况。
- **性能分析工具**:如top、htop、vmstat、iostat等,用于收集和分析系统性能数据。
- **性能调优策略**:涉及内核参数调整、服务性能优化以及资源限制设置,旨在提升系统性能。
通过本章内容的阅读,读者应具备进行基本Linux性能监控的能力,并为深入学习后续章节内容打下坚实的基础。接下来的章节,我们将逐一深入探讨每个监控和分析主题,并给出详尽的操作步骤和案例分析。
# 2. Linux系统资源监控实践
## 2.1 CPU资源监控
### 2.1.1 CPU使用率的分析
为了评估系统的性能,CPU的使用率是至关重要的指标。CPU使用率告诉我们CPU被利用的程度,高使用率可能意味着CPU正在全力工作,但也可能指示存在性能瓶颈。要分析CPU使用率,常用命令有`top`, `htop`, `vmstat`等。
- 使用`top`命令,可以观察到实时的CPU使用情况。通过`top`,你可以查看到系统的负载情况以及按进程分类的CPU使用信息。
- `vmstat`命令提供了关于系统资源使用情况的统计信息,包括CPU使用率。这些信息可以帮助我们识别出CPU密集型进程,并检查是否有过多的上下文切换。
理解CPU使用率时,以下参数尤其重要:
- `us`:用户空间的CPU使用率。
- `sy`:内核空间的CPU使用率。
- `ni`:改变过优先级的进程使用的CPU。
- `id`:CPU空闲时的百分比。
- `wa`:等待I/O完成的CPU时间百分比。
### 2.1.2 进程级别的CPU监控
深入到进程级别,我们可以识别是哪个进程或哪些进程导致了CPU的高负载。这可以通过`top`或`htop`命令实现。`top`命令的默认视图就是按CPU使用率对进程进行排序,而`htop`则提供了颜色编码和更直观的视图来帮助用户识别资源密集型进程。
下面是使用`top`命令分析进程级别CPU使用的示例:
```bash
top - 17:50:23 up 10 days, 5:20, 1 user, load average: 2.50, 1.50, 1.10
Tasks: 249 total, 1 running, 126 sleeping, 0 stopped, 0 zombie
Cpu(s): 75.3%us, 5.4%sy, 0.0%ni, 9.5%id, 9.8%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 32948236k total, 16273396k used, 16674840k free, 167848k buffers
Swap: 4194300k total, 0k used, 4194300k free, 10682340k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4115 user1 20 0 1000m 100m 10m R 86.7 0.3 0:03.06 processA
4116 user2 20 0 500m 50m 10m S 13.3 0.2 0:01.01 processB
```
在上面的例子中,`processA`是使用CPU最多的进程,它占用了86.7%的CPU资源。通过此信息,管理员可以进一步调查`processA`为什么会如此占用资源,或者决定是否需要进行优化或重启。
## 2.2 内存资源监控
### 2.2.1 内存使用情况的分析
内存资源是另一个关键指标,它对系统的性能有着直接的影响。内存分析通常关注总体使用率,包括空闲内存、缓存和缓冲区的使用情况以及交换空间的使用情况。
通过以下命令可以获取内存的使用情况:
- `free`:显示系统总体内存使用情况。
- `top`或`htop`:在进程的上下文中提供内存使用信息。
命令`free`的输出会显示总的内存、已使用的内存、空闲的内存以及缓存和缓冲区的大小。例如:
```bash
total used free shared buff/cache available
Mem: 32948236 16273396 16674840 167848 10682340 16416968
Swap: 4194300 0 4194300
```
从上述输出中,我们能看到系统总体的内存情况,`buff/cache`列显示的是系统使用内存作为缓冲和缓存的大小。此外,`available`列提供了一个较好的可用内存的估计,它考虑了当前未使用但可以回收的缓存。
## 2.3 磁盘I/O监控
### 2.3.1 磁盘性能指标和工具
磁盘I/O是影响系统性能的另一个重要因素。监控磁盘I/O性能,常用指标包括磁盘的读写速度、I/O等待时间和I/O请求的队列长度。
对于磁盘性能监控,可以使用以下工具:
- `iostat`:显示CPU和磁盘I/O的统计信息。
- `iotop`:类似于`top`,但专注于磁盘I/O。
`iostat`命令的基本使用方法如下:
```bash
iostat -x 1
```
该命令会显示磁盘的详细统计信息,并且每秒更新一次数据。输出包括:
- `r/s`:每秒读取操作的数量。
- `w/s`:每秒写入操作的数量。
- `await`:等待I/O平均时间(毫秒)。
- `avgqu-sz`:平均请求队列长度。
通过这些指标,我们可以对磁盘的性能进行详细分析。如果`await`很高,可能意味着磁盘I/O有瓶颈。同样,高`avgqu-sz`值也可能暗示磁盘I/O请求队列过长,需要进一步关注。
## 2.4 网络性能监控
### 2.4.1 网络接口监控和流量分析
网络是现代计算环境中不可或缺的一部分,监控网络性能可以帮助我们确保系统能够有效地处理数据传输。网络监控通常包括监控网络接口的数据传输速率和流量分析。
我们可以使用`ifstat`命令来监控网络接口:
```bash
ifstat -t 1 5
```
这个命令将每秒输出一次网络接口状态,并且总共运行5次。
输出类似于:
```
Time eth0 eth1
10:00:01 0.00k 1.00k
10:00:02 0.00k 0.00k
10:00:03 1.00k 2.00k
10:00:04 0.00k 0.00k
10:00:05 0.00k 1.00k
```
从上述输出中,我们可以看到`eth0`和`eth1`两个网络接口每秒的数据传输速率。如果某个接口的传输速率长时间异常高或低,可能意味着网络配置或硬件存在性能问题。
### 2.4.2 网络故障排除和性能优化
在遇到网络问题时,一个重要的故障排除步骤是查看网络流量的实时统计信息。可以使用`iftop`或`nethogs`工具进行这样的监控。
例如,`iftop`可以提供详细的实时网络接口流量信息,显示进出各IP地址和端口的数据包大小和速率。而`nethogs`则可以显示每个进程的网络活动,帮助我们识别网络使用大户。
下面是一个使用`iftop`的基本例子:
```bash
sudo iftop
```
执行后,你将看到一个类似以下的实时流量界面:
```
TX: cum: 3.99MB peak: 3.50Mb
RX: cum: 3.99MB peak: 3.50Mb
```
这个界面提供了发送(`TX`)和接收(`RX`)数据的累计值和峰值信息。要深入分析,可以使用`iftop`的过滤器功能来观察特定IP地址或端口的流量。
总之,监控和分析网络接口的性能对于维护系统的网络健康至关重要,有助于我们及时发现并解决问题。
请注意,以上内容是根据提供的要求编写的示例章节内容。根据实际文章的需要,每个章节的内容应当更加丰富和详细,且需涵盖分析、优化等具体操作步骤和实例,以满足2000字的一级章节和1000字的二级章节要求。实际编写时,还需注意避免使用过滤性开头描述,以及确保内容的连贯性和深度。
# 3. Linux性能分析工具深入
## 3.1 常用性能分析工具概览
### 3.1.1 工具的分类和选择
在Linux环境下,性能分析工具多种多样,它们各有特色,可以基于不同层面进行系统监控和性能调优。性能分析工具大致可以分为以下几类:
- 系统监控工具:如top, htop, vmstat, iostat, sar等,这些工具能够实时显示系统的运行状态,帮助我们发现资源瓶颈。
- 跟踪和调试工具:如strace, ltrace, tcpdump等,这些工具可以追踪系统调用、信号传递、网络流量等。
- 性能分析工具:如perf, sysstat等,它们通常提供更为深入的性能分析能力,包括函数调用分析、硬件性能事件统计等。
选择合适的性能分析工具首先需要明确分析目标和需求。例如,如果目标是监控CPU使用情况,那么top或htop可能是快速便捷的选择。而对于深入的性能瓶颈诊断,则可能需要使用perf等更专业的工具。
### 3.1.2 工具的安装和配置
安装性能分析工具通常是Linux系统管理的基本技能。大多数性能分析工具可以通过包管理器轻松安装,例如在基于Debian的系统上,可以使用apt:
```bash
sudo apt-get install [tool-name]
```
对于某些特定的工具,可能需要从源码编译安装。在编译安装过程中,需要注意配置选项,以便工具能够充分利用系统资源。例如,安装性能分析工具perf,可以通过下载Linux内核源码,然后编译并安装内核源码中的perf工具。
配置性能分析工具通常涉及调整工具的运行参数,以便更好地满足监控需求。如vmstat的采样频率和采样次数,可以通过命令行参数灵活设定。
## 3.2 系统监控工具的实战应用
### 3.2.1 top和htop的高级使用技巧
top是一个常用的动态实时查看系统运行状态的工具。它的输出可以被定制,例如:
```bash
top -b -n 1 > /tmp/top.txt
```
这条命令表示以批处理模式运行top一次,并将输出重定向到/tmp/top.txt。
htop是一个top的增强版,提供了更加友好的用户界面和更多的交互功能。使用htop时,可以通过F2进入设置菜单,定制显示列等。
### 3.2.2 vmstat和iostat的实际案例
vmstat是一个报告关于系统内存、进程、CPU使用情况的工具。一个典型的vmstat命令如下:
```bash
vmstat 2 10
```
它表示每两秒刷新一次信息,总共刷新10次。输出通常包括以下几个部分:Procs(进程)、Memory(内存)、Swap、IO(磁盘输入输出)、System(系统)、CPU(CPU信息)。
iostat由sysstat包提供,用于监控系统输入输出设备的加载情况。使用iostat的一个实际案例:
```bash
iostat -x /dev/sda 2 5
```
此命令表示监控设备sda的详细统计信息,每两秒刷新一次,总共刷新5次。
## 3.3 性能分析工具的深入探究
### 3.3.1 strace和ltrace的高级特性
strace用于跟踪系统调用,这对于了解程序如何与内核交互非常有用。一个简单的strace用法如下:
```bash
strace -o output.txt command
```
它会记录command命令的系统调用和接收的信号,输出到output.txt文件中。
ltrace用于跟踪库函数调用,特别是C/C++程序中。使用ltrace跟踪动态链接库调用的一个例子:
```bash
ltrace -c ./a.out
```
这条命令会运行a.out程序,并统计库函数调用的数量,输出结果到标准输出。
### 3.3.2 perf和sysstat的高级应用
perf是Linux内核中的性能分析子系统,提供了CPU性能计数器信息、软件追踪等。一个perf的基本用法是查看CPU性能事件:
```bash
perf stat ls
```
这条命令会显示在执行`ls`命令过程中CPU的相关性能数据。
sysstat是一个包,包含了多个用于系统监控的工具,如sar。sar能够收集、报告或保存系统活动信息。使用sar的示例:
```bash
sar -u 2 5
```
这个命令表示每两秒采样一次CPU使用情况,共采样5次。
综上所述,Linux提供了强大的工具集合来进行系统性能分析。通过熟悉并掌握这些工具的高级特性,可以帮助系统管理员和开发者快速定位问题,优化系统性能。
# 4. Linux性能调优策略
## 4.1 系统调优基础
### 4.1.1 内核参数调整概览
在Linux系统中,内核参数提供了对操作系统行为进行微调的能力。调整内核参数可以帮助改善系统性能,同时需要谨慎操作,因为不当的设置可能会导致系统不稳定甚至崩溃。内核参数可以通过`/proc`文件系统动态调整,或者在启动时通过`/etc/sysctl.conf`文件永久设置。
一个典型的内核参数调整例子是针对TCP/IP网络栈的优化。通过调整如下参数,我们可以优化网络通信:
```bash
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 87380 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
```
这些参数分别设置了接收和发送缓冲区的最大值,从而允许系统处理更大的网络负载。
### 4.1.2 调优前的准备工作和风险评估
在进行系统调优之前,首先应该明确调优的目标和预期结果。接下来,对当前系统的性能基线进行评估是至关重要的,这可以通过性能监控工具来完成。了解系统当前的性能瓶颈后,才能更有针对性地进行调优。
在调优之前,必须对系统进行备份,并确保有快速恢复系统的方法。任何调优尝试都应该在非生产环境中先进行测试,以评估其对系统稳定性的影响。此外,所有的更改都应该详细记录,以便于日后追踪和复原。
## 4.2 关键性能参数调优
### 4.2.1 文件系统和磁盘调优
Linux支持多种文件系统,每种文件系统在性能和稳定性方面都有各自的优势。例如,对于高性能存储系统,可以选择XFS或EXT4文件系统,并进行特定的调整以优化性能。
磁盘性能调优的常见策略包括:
- 使用`noatime`挂载选项以减少对文件元数据的写操作。
- 调整文件系统的`block`大小以优化读写性能。
- 采用`电梯算法`(elevator algorithm),即I/O调度程序,来优化磁盘I/O顺序。
### 4.2.2 网络堆栈调优
网络堆栈调优可以提升网络通信的效率和响应时间。一个关键的性能指标是网络数据包的处理速度,可以通过调整内核参数来实现:
```bash
net.core.netdev_max_backlog = 30000
net.ipv4.tcp_max_syn_backlog = 80960
net.ipv4.tcp_timestamps = 1
```
这些设置分别增加了网络设备的处理队列长度、增加了TCP同步请求队列的大小,并启用了TCP时间戳,以减少往返时间(RTT)测量的误差。
## 4.3 应用层调优
### 4.3.1 服务和应用性能优化策略
应用层的性能优化通常涉及到特定服务的配置。例如,Web服务器(如Apache或Nginx)可以通过以下方式优化:
- 优化连接数和线程数,以减少响应时间和增加并发处理能力。
- 使用静态内容压缩,以减少带宽使用和提高加载速度。
- 缓存优化,减少数据库查询的次数,提升数据访问效率。
### 4.3.2 使用cgroup进行资源限制
cgroup是Linux内核提供的一种机制,可以用来限制、记录和隔离进程组所使用的物理资源(如CPU、内存、磁盘I/O等)。利用cgroup可以为不同的应用或服务分配固定的资源,防止资源争用导致的性能问题。
例如,可以通过以下命令来创建一个名为`webapp`的cgroup,并限制其内存使用:
```bash
mkdir /sys/fs/cgroup/memory/webapp
echo $$ > /sys/fs/cgroup/memory/webapp/tasks
echo 512M > /sys/fs/cgroup/memory/webapp/memory.limit_in_bytes
```
这个例子中,`$$`是当前shell的PID,`webapp` cgroup限制使用不超过512MB的内存。
通过使用cgroup,可以实现精细的资源控制和性能调优,确保关键服务在资源有限的情况下仍能保持高性能运行。
# 5. 故障诊断与预防
## 5.1 常见故障模式及诊断
在 Linux 系统的运维过程中,系统故障是不可避免的。对常见故障模式的诊断不仅需要扎实的技术知识,还需要丰富的经验积累。下面将介绍两种常见的故障模式及其诊断方法。
### 5.1.1 系统响应缓慢的排查
当系统出现响应缓慢时,首先需要做的是确认问题范围和影响程度。可以从以下几个方面入手:
1. **CPU 使用情况**:使用 `top` 或 `htop` 命令检查 CPU 的使用率和负载。如果发现某个进程占用 CPU 过高,可以使用 `ps` 或 `top` 命令查找该进程的详细信息。
```bash
top -u 用户名
```
2. **内存使用情况**:系统内存不足或者存在内存泄漏时,也会导致系统响应缓慢。可以使用 `free` 和 `vmstat` 命令查看当前内存使用状况。
```bash
free -m
vmstat 1
```
3. **磁盘 I/O**:如果磁盘 I/O 高,同样会影响系统性能。使用 `iostat` 或 `iotop` 命令来监控磁盘的使用情况。
```bash
iostat -dx 1
```
4. **网络活动**:网络问题也可能导致响应缓慢。通过 `netstat` 或 `ss` 命令可以检查网络连接状况。
```bash
netstat -tulnp
```
5. **系统日志**:检查系统日志文件,如 `/var/log/syslog` 或使用 `journalctl` 查看系统和应用日志,寻找异常信息。
```bash
journalctl -xb
```
### 5.1.2 服务崩溃和重启的分析
服务崩溃和自动重启是另一种常见的故障模式。对于这类问题,分析通常包括以下步骤:
1. **查看服务状态**:首先使用 `systemctl status 服务名` 命令检查服务的状态和最后的日志信息。
```bash
systemctl status httpd
```
2. **核心转储文件分析**:如果服务配置了核心转储(core dump),可以通过分析核心文件来获取崩溃时的内存镜像信息。
```bash
gdb /path/to/binary /path/to/core-file
```
3. **检查配置文件**:检查服务的配置文件是否存在问题,特别是配置项的限制或设置错误。
4. **资源限制**:使用 `dmesg` 或 `/var/log/messages` 查看系统消息,确认是否有资源不足导致的错误。
```bash
dmesg | grep -i 'out of memory'
```
5. **重启日志**:检查服务的重启日志,找出可能的错误模式或重复出现的错误信息。
```bash
journalctl -u 服务名.service
```
## 5.2 预防性维护和自动化监控
故障的预防比修复更重要。通过建立有效的预防性维护和自动化监控机制,可以大大降低故障发生的几率。
### 5.2.1 监控告警系统的建立和管理
构建一个监控告警系统是预防性维护的关键步骤。告警系统通常包括以下几个部分:
1. **数据收集**:通过工具如 `Prometheus`、`Nagios` 或 `Zabbix` 收集系统和应用的关键性能指标。
2. **告警规则**:定义告警规则和阈值,以便在指标超出正常范围时触发告警。
3. **告警通知**:配置告警通知方式,如电子邮件、短信、即时通讯工具等。
4. **告警处理**:对于收到的告警,进行分类和优先级排序,及时响应处理。
5. **日志归档与分析**:定期对告警数据进行分析,找出潜在的故障模式,优化告警规则。
### 5.2.2 定期审计和性能调优的自动化
定期审计和自动化性能调优是保持系统性能稳定的有效手段:
1. **审计工具**:使用 `auditd` 工具进行系统活动的审计跟踪,及时发现潜在的安全威胁或操作错误。
```bash
auditctl -w /etc/shadow -p wa -k shadow-change
```
2. **性能调优**:结合监控数据,使用 `tuned`、`sysctl` 等工具自动调优系统参数,提升性能。
```bash
tuned-adm profile throughput-performance
sysctl vm.swappiness=10
```
3. **自动化脚本**:编写自动化脚本,定期执行系统维护任务,如清理缓存、更新软件包、检查磁盘完整性等。
```bash
#!/bin/bash
# 示例脚本:清理系统缓存
echo 1 > /proc/sys/vm/drop_caches
```
4. **配置管理工具**:使用配置管理工具如 `Ansible`、`Puppet` 等自动化配置管理,确保系统配置的一致性。
```yaml
# Ansible playbook 示例:安装 Nginx
- name: Install Nginx
become: yes
apt:
name: nginx
state: present
```
通过这些策略和工具的结合使用,可以在故障发生前进行预防,保证系统的稳定性和可靠性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《图说微积分.pdf》专栏是一份全面的指南,旨在提升软件性能、系统效率和软件质量。它涵盖了广泛的主题,包括:
* 代码优化策略,帮助开发人员从新手提升为专家
* Linux性能调优指南,提供优化系统性能的终极指南
* 自动化测试框架的高级技巧,提高软件质量
* MySQL和PostgreSQL数据库管理和调优最佳实践
* 前端性能优化细节,提升用户体验
通过深入浅出的讲解和实际案例,该专栏为读者提供了宝贵的见解和可操作的建议,帮助他们提升软件系统和应用程序的性能、可靠性和用户体验。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【FPGA与DisplayPort终极指南】:5大实用技巧,提升你的信号处理效率
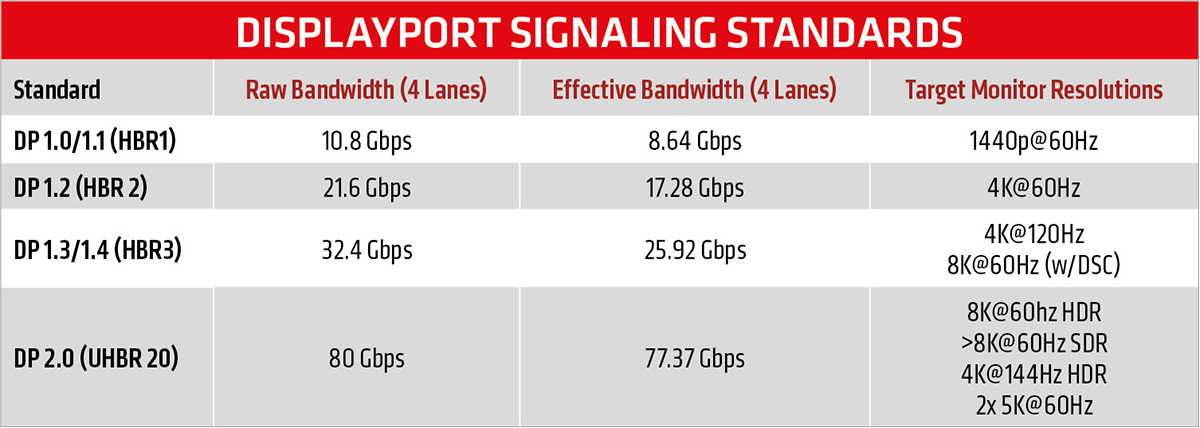
# 摘要
随着高分辨率显示技术的发展,DisplayPort作为重要的视频传输接口标准,被广泛应用于各种显示设备中。本文从FPGA与DisplayPort技术的基础入门开始,详细解读了DisplayPort信号协议的各个方面,包括接口标准、时序控制和信号质量检测。文章深入探讨了FPGA在DisplayPort应用中的角色,涵盖了信号处理、性能优化以及协同设计。进一步地,本文提供了FP
揭秘国产超低功耗以太网芯片JL1101:全面对比RTL8201F,探索物联网新星

# 摘要
本文对国产超低功耗以太网芯片JL1101进行了全面介绍和分析。首先概述了JL1101的基本情况和市场定位,随后与同类产品RTL8201F在核心性能和功能特点方面进行了详细对比。接着,深入探讨了JL1101的硬件接口、编程接口以及安全性与可靠性特性。文章还展示了JL1101在物联网实践应用中的案例,包括智能家居系统、工业物联网集成应用和低功耗传感器网络
【UDIMM应用深度解析】:在服务器系统中的集成与优化

# 摘要
UDIMM(Unbuffered DIMM)技术作为服务器内存解决方案的重要组成部分,在性能优化、硬件兼容性、软件集成及故障排除方面发挥了关键作用。本文详细介绍了UDIMM的工作原理和特性,并深入探讨了其在服务器系统中的集成方法和性能优化策略。此外,针对UDIMM在云计算、高性能计算等新兴应用中的潜力进行了分析,并对未来UDIMM技术的发展趋势和面临的挑战提出了展望。
【AGV动力系统优化】:动力系统设计与优化的终极指南

# 摘要
自动引导车(AGV)的动力系统是其运行效能的核心,本文全面概述了AGV动力系统的设计理论基础、优化实践、管理与维护以及未来的发展趋势。通过对动力系统关键组成部分的分析,阐述了电动机与驱动技术、能量存储与管理等方面的重要性。进一步,本文探讨了设计原则、系统集成与布局、性能优化、故障诊断预防、测试与验证等实践策略。此外,本文还重点介绍
【CS3000系统备份与恢复】
# 摘要
CS3000系统备份与恢复是一个复杂而重要的过程,本文详细探讨了备份与恢复的理论基础、实践策略及技术实现。首先概述了CS3000系统的备份与恢复概念,接着深入分析了不同类型备份及其适用场景,存储策略以及备份执行的调度和监控。在恢复策略方面,讨论了确定RPO与RTO的方法和实现快速恢复的技术,数据恢复流程和恢复测试与验证的重要性。接着,详细评估了备份工具与技术选型,备份数据
【CloudFront配置详解】:网络分发设置与最佳实践的全面指南

# 摘要
随着互联网技术的不断发展,内容分发网络(CDN)已成为优化网络性能、改善用户体验的关键技术之一。本文首先介绍了Amazon CloudFront的基础知识及其核心概念,深入探讨了CloudFront如何实现高效的内容分发及缓存策略。文章还探讨了CloudFr
【电源管理策略】:为uA741正弦波发生器提供稳定电源的终极指南
# 摘要
本文详细探讨了电源管理策略及其对uA741正弦波发生器性能的影响。首先概述了电源管理的基础知识和uA741芯片的工作原理。随后,分析了稳定电源对信号质量和电路性能的重要性,以及电源管理策略的基本原则和电路设计实践。文章还深入讨论了高级电源管理技术如PWM控制技术和动态电压调节的应用,并通过案例分析总结了不同电源管理策略的实际效果。最后,展望了电源管理的未来趋势,强调了新技术
硬石电机控制系统核心剖析:设计理念与关键功能深度解读

# 摘要
本论文全面介绍了硬石电机控制系统的设计理念、硬件架构、软件控制逻辑、系统集成和性能测试。首先概述了电机控制系统的理论基础和设计理念的演变,接着深入解析了硬件组件的功能、角色以及它们之间的协同工作机制。文章详细阐述了控制算法原理、软件模块化和接口设计标准,并探讨了系统集成过程中的关键问题及解决方案。性能测试与验证章节提供了测试指标和方法,并对结果进行了分析与优化建议。最
10kV系统中ATS的编程与配置:按图索骥技术指南
# 摘要
自动转换开关(ATS)系统是一种用于确保电力供应连续性的关键设备,广泛应用于数据中心和关键基础设施中。本文综合概述了ATS系统的基本构成及其硬件组成,深入探讨了ATS设备的工作原理和控制逻辑,以及系统编程的基础知识,包括编程语言的选择、基础语法和开发工具链。针对ATS系统编程实践,本文提供了系统配置、参数设定以及自动切换与故障处理机制的详细指导。此外,本文还涉及了ATS系统的高级配置与优化方法,强调了通信协议、接口集成、系统安全
DEFORM-2D复杂几何体加工仿真:提升工艺设计的核心能力
# 摘要
本文系统性地探讨了DEFORM-2D软件在复杂几何体加工仿真领域的应用。首先,概述了DEFORM-2D的基本原理和仿真基础,随后深入到加工理论和仿真模型的构建。在理论分析中,本文重点讨论了材料力学基础、几何体加工的力学行为,并结合具体案例分析了加工过程的仿真及结果分析。第三章详细介绍了如何构建并优化DEFORM-2D仿真模型,包括模型建立步骤、仿真参数设置以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )