【PHP数据库优化宝典】:10个秘诀提升数据库性能
发布时间: 2024-07-16 19:06:49 阅读量: 34 订阅数: 39 

oracle数据库性能优化宝典

# 1. 数据库优化概述
数据库优化是指通过一系列技术和方法,提升数据库性能和效率的过程。其目标是提高数据查询、处理和存储的速度,同时降低系统资源消耗。数据库优化涉及多个方面,包括数据库设计、查询优化、性能监控和分析、缓存调优以及维护和安全等。
数据库优化对于现代企业至关重要,因为数据已成为业务运营和决策的关键资产。优化后的数据库可以提高应用程序响应时间,减少延迟,并支持更大的数据量和更复杂的查询。此外,优化还可以降低硬件和软件成本,并提高整体系统可靠性。
# 2. 数据库设计与优化
### 2.1 表结构优化
#### 2.1.1 数据类型选择
数据类型选择是表结构优化中至关重要的一步,它直接影响着数据库的存储空间、查询效率和数据完整性。选择合适的数据类型可以最大限度地减少存储空间浪费,提高查询速度,并确保数据的准确性。
| 数据类型 | 特点 | 适用场景 |
|---|---|---|
| 整数类型 (INT, TINYINT, SMALLINT, BIGINT) | 存储整数,范围和精度不同 | 存储整数数据,如 ID、数量等 |
| 浮点数类型 (FLOAT, DOUBLE) | 存储浮点数,精度和范围不同 | 存储浮点数据,如价格、温度等 |
| 字符串类型 (VARCHAR, CHAR) | 存储可变长度或固定长度的字符串 | 存储文本数据,如姓名、地址等 |
| 日期时间类型 (DATE, TIME, DATETIME) | 存储日期、时间或日期时间 | 存储日期和时间相关数据 |
| 布尔类型 (BOOLEAN) | 存储真假值 | 存储布尔值,如是否已完成等 |
**选择原则:**
* 根据数据的实际范围和精度选择合适的类型。
* 优先使用占用空间较小的类型,如 INT 而不是 BIGINT。
* 对于可变长度字符串,使用 VARCHAR 而不是 CHAR,以节省存储空间。
* 避免使用 NULL 值,因为它会降低查询效率。
#### 2.1.2 索引设计
索引是数据库中一种重要的数据结构,它可以快速查找数据,提高查询效率。精心设计的索引可以显著提升数据库性能。
**索引类型:**
* **B+ 树索引:**最常用的索引类型,具有高效的插入、删除和查找性能。
* **哈希索引:**对于等值查询非常高效,但插入和删除性能较差。
* **全文索引:**用于对文本数据进行快速搜索。
**索引选择原则:**
* 为经常查询的列创建索引。
* 为具有高基数的列创建索引,即不同值较多的列。
* 避免为小表或经常更新的表创建索引。
* 对于联合查询,创建复合索引,将多个列组合在一起。
**代码示例:**
```sql
-- 创建 B+ 树索引
CREATE INDEX idx_name ON table_name (column_name);
-- 创建哈希索引
CREATE INDEX idx_name ON table_name (column_name) USING HASH;
-- 创建全文索引
CREATE FULLTEXT INDEX idx_name ON table_name (column_name);
```
**逻辑分析:**
* `CREATE INDEX` 语句用于创建索引。
* `ON table_name` 指定索引所在的表。
* `(column_name)` 指定索引的列。
* `USING HASH` 指定使用哈希索引。
* `FULLTEXT` 指定创建全文索引。
**参数说明:**
* `idx_name`:索引的名称。
* `table_name`:表的名称。
* `column_name`:列的名称。
# 3. 数据库性能监控与分析
### 3.1 性能监控工具
#### 3.1.1 数据库日志分析
数据库日志是记录数据库操作和事件的重要信息来源。通过分析数据库日志,可以发现数据库的性能问题,例如:
- **慢查询:**日志中会记录执行时间较长的查询,可以帮助识别需要优化的查询。
- **死锁:**日志中会记录死锁发生的详细信息,可以帮助分析死锁原因并采取措施避免。
- **连接错误:**日志中会记录连接数据库失败的错误信息,可以帮助诊断连接问题。
#### 3.1.2 性能指标监控
性能指标监控工具可以实时收集和展示数据库的各种性能指标,例如:
- **CPU使用率:**衡量数据库服务器的CPU利用率,过高的CPU使用率可能导致性能下降。
- **内存使用率:**衡量数据库服务器的内存利用率,过高的内存使用率可能导致内存溢出。
- **I/O操作:**衡量数据库服务器的磁盘I/O操作,过多的I/O操作可能导致性能瓶颈。
- **查询执行时间:**衡量查询的执行时间,可以帮助识别慢查询。
### 3.2 性能分析方法
#### 3.2.1 慢查询分析
慢查询分析是识别和优化执行时间较长的查询的过程。可以通过以下步骤进行慢查询分析:
1. **识别慢查询:**使用性能监控工具或数据库日志分析工具识别执行时间较长的查询。
2. **分析查询计划:**查看查询计划以了解查询的执行方式,识别潜在的性能问题。
3. **优化查询:**根据查询计划,优化查询语句,例如使用索引、重写查询逻辑或调整查询参数。
#### 3.2.2 索引分析
索引是数据库中的一种数据结构,用于快速查找数据。索引分析可以帮助识别和优化索引,以提高查询性能。可以通过以下步骤进行索引分析:
1. **识别未使用的索引:**分析数据库日志或使用性能监控工具识别未使用的索引。
2. **评估索引覆盖率:**衡量索引覆盖查询中所需数据的百分比,较低的覆盖率可能导致索引无效。
3. **优化索引策略:**根据索引分析结果,调整索引策略,例如创建新的索引、删除未使用的索引或调整索引顺序。
### 代码示例
**数据库日志分析**
```sql
SELECT
*
FROM pg_stat_activity
WHERE
state = 'active'
ORDER BY
query_start DESC;
```
**性能指标监控**
```python
import psycopg2
# 连接数据库
conn = psycopg2.connect(
database="mydb",
user="postgres",
password="mypassword",
host="localhost",
port="5432",
)
# 创建游标
cur = conn.cursor()
# 执行查询
cur.execute("SELECT * FROM pg_stat_activity WHERE state = 'active'")
# 获取结果
rows = cur.fetchall()
# 遍历结果
for row in rows:
print(row)
# 关闭游标和连接
cur.close()
conn.close()
```
**慢查询分析**
```sql
EXPLAIN ANALYZE SELECT * FROM mytable WHERE id = 1;
```
**索引分析**
```sql
SELECT
*
FROM pg_indexes
WHERE
schemaname = 'public'
ORDER BY
indexname;
```
# 4. 数据库缓存与调优
### 4.1 缓存机制
缓存是一种临时存储数据结构,用于存储经常被访问的数据,以提高后续访问的性能。数据库中常用的缓存机制包括:
#### 4.1.1 查询缓存
查询缓存将最近执行过的查询及其结果存储在内存中。当后续查询与缓存中的查询匹配时,数据库将直接从缓存中返回结果,无需重新执行查询。这可以显著提高经常执行的查询的性能。
#### 4.1.2 数据缓存
数据缓存将经常访问的数据页存储在内存中。当需要访问这些数据页时,数据库将直接从缓存中读取,无需从磁盘中读取。这可以减少磁盘 I/O 操作,从而提高数据访问性能。
### 4.2 调优参数
数据库的性能可以通过调整某些配置参数来优化。这些参数包括:
#### 4.2.1 内存配置优化
内存配置参数影响数据库的缓存大小和可用内存量。优化这些参数可以提高缓存命中率和减少内存不足问题。
| 参数 | 说明 |
|---|---|
| innodb_buffer_pool_size | InnoDB 缓冲池大小 |
| innodb_log_buffer_size | InnoDB 日志缓冲区大小 |
| max_connections | 最大连接数 |
#### 4.2.2 连接池优化
连接池是一种预先分配和管理数据库连接的机制。优化连接池参数可以减少创建和销毁连接的开销,从而提高数据库连接性能。
| 参数 | 说明 |
|---|---|
| max_connections | 最大连接数 |
| min_connections | 最小连接数 |
| connection_timeout | 连接超时时间 |
### 代码示例
#### 查询缓存优化
```sql
SET GLOBAL query_cache_size = 1024 * 1024 * 16;
SET GLOBAL query_cache_type = 1;
```
**代码逻辑分析:**
* `query_cache_size` 设置查询缓存的大小为 16MB。
* `query_cache_type` 设置查询缓存类型为 1,表示只缓存 SELECT 查询。
#### 数据缓存优化
```sql
SET GLOBAL innodb_buffer_pool_size = 1024 * 1024 * 128;
```
**代码逻辑分析:**
* `innodb_buffer_pool_size` 设置 InnoDB 缓冲池的大小为 128MB。
#### 连接池优化
```xml
<connectionPool>
<maxSize>50</maxSize>
<minSize>10</minSize>
<connectionTimeout>300</connectionTimeout>
</connectionPool>
```
**代码逻辑分析:**
* `maxSize` 设置最大连接数为 50。
* `minSize` 设置最小连接数为 10。
* `connectionTimeout` 设置连接超时时间为 300 秒。
# 5. 数据库维护与安全
### 5.1 定期维护
#### 5.1.1 数据库备份
数据库备份是数据保护和恢复的关键措施。定期备份数据库可以确保在数据丢失或损坏的情况下,能够快速恢复数据。
**备份类型**
* **完全备份:**备份整个数据库,包括所有数据和结构。
* **增量备份:**仅备份自上次完全备份以来更改的数据。
* **差异备份:**备份自上次完全备份以来更改的所有数据,包括增量备份中未包含的数据。
**备份策略**
制定一个备份策略,确定备份频率、保留时间和备份位置。
* **备份频率:**根据数据的重要性,确定备份的频率,如每天、每周或每月。
* **保留时间:**确定备份的保留时间,以便在需要时可以恢复数据。
* **备份位置:**选择一个安全且可靠的备份位置,如云存储或外部硬盘。
**备份工具**
使用数据库管理系统(DBMS)提供的备份工具或第三方备份软件来执行备份。
#### 5.1.2 数据清理
定期清理数据库中的不需要或过时的数据,可以提高性能和减少存储空间。
* **删除冗余数据:**删除重复或不需要的数据。
* **清理日志文件:**删除不再需要的日志文件。
* **压缩数据:**使用压缩算法压缩数据,以减少存储空间。
### 5.2 安全保障
#### 5.2.1 用户权限管理
实施严格的用户权限管理,以控制对数据库的访问和操作。
* **创建用户和角色:**创建不同的用户和角色,并分配适当的权限。
* **授予最小权限:**只授予用户执行其职责所需的最小权限。
* **定期审查权限:**定期审查用户权限,并根据需要撤销或修改权限。
#### 5.2.2 数据加密
对敏感数据进行加密,以防止未经授权的访问。
* **加密算法:**使用强加密算法,如 AES-256 或 RSA。
* **加密密钥管理:**安全地存储和管理加密密钥。
* **数据脱敏:**在某些情况下,可以对数据进行脱敏,以隐藏敏感信息。
# 6. **6. 数据库选型与部署**
### **6.1 数据库选型因素**
数据库选型是数据库优化过程中至关重要的一步,需要考虑多种因素,包括:
- **数据类型:**不同类型的数据库适合处理不同类型的数据。例如,关系型数据库适合处理结构化数据,而文档型数据库适合处理非结构化数据。
- **性能要求:**数据库的性能要求因应用而异。需要考虑查询速度、并发能力、数据量大小等因素。
- **可扩展性:**随着业务的增长,数据库需要能够扩展以满足不断增长的数据量和并发需求。
- **成本:**数据库的成本包括许可证费用、维护费用和硬件成本。
- **社区支持:**活跃的社区支持可以提供丰富的文档、教程和技术支持,帮助解决问题并优化数据库性能。
### **6.2 数据库部署方案**
数据库部署方案主要分为两种:
- **单机部署:**将数据库部署在一台物理或虚拟服务器上。这种方案适合数据量较小、并发需求较低的应用。
- **分布式部署:**将数据库分布在多个服务器上,通过数据分片和复制机制实现高可用性和可扩展性。这种方案适合数据量较大、并发需求较高的应用。
分布式数据库部署方案又可以细分为以下几种:
- **主从复制:**将数据从主数据库复制到一个或多个从数据库,实现读写分离和高可用性。
- **读写分离:**将数据库分为读库和写库,读库负责处理查询请求,写库负责处理写请求,提高并发能力。
- **分库分表:**将数据根据一定规则分片到不同的数据库或表中,实现数据水平扩展。
数据库选型和部署方案的确定需要综合考虑应用需求、技术能力和成本因素。通过合理的选型和部署,可以为数据库优化奠定良好的基础。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 PHP 数据库实战专栏!本专栏深入探讨了 PHP 数据库开发的方方面面,从连接池优化到性能调优,再到故障排查和版本升级。通过揭秘数据库连接池的原理、掌握事务处理的精髓、优化查询策略、巧妙运用索引、解析死锁问题、管理连接池、备份和恢复数据、安全迁移数据库、运用设计模式、扩展数据库功能、调优数据库性能、控制并发访问、运用缓存机制、升级数据库版本以及排查故障,本专栏将带你全面提升 PHP 数据库开发技能,打造高性能、稳定可靠的数据库解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入浅出Java天气预报应用开发:零基础到项目框架搭建全攻略

# 摘要
Java作为一种流行的编程语言,在开发天气预报应用方面显示出强大的功能和灵活性。本文首先介绍了Java天气预报应用开发的基本概念和技术背景,随后深入探讨了Java基础语法和面向对象编程的核心理念,这些为实现天气预报应用提供了坚实的基础。接着,文章转向Java Web技术的应用,包括Servlet与JSP技术基础、前端技术集成和数据库交互技术。在
【GPO高级管理技巧】:提升域控制器策略的灵活性与效率
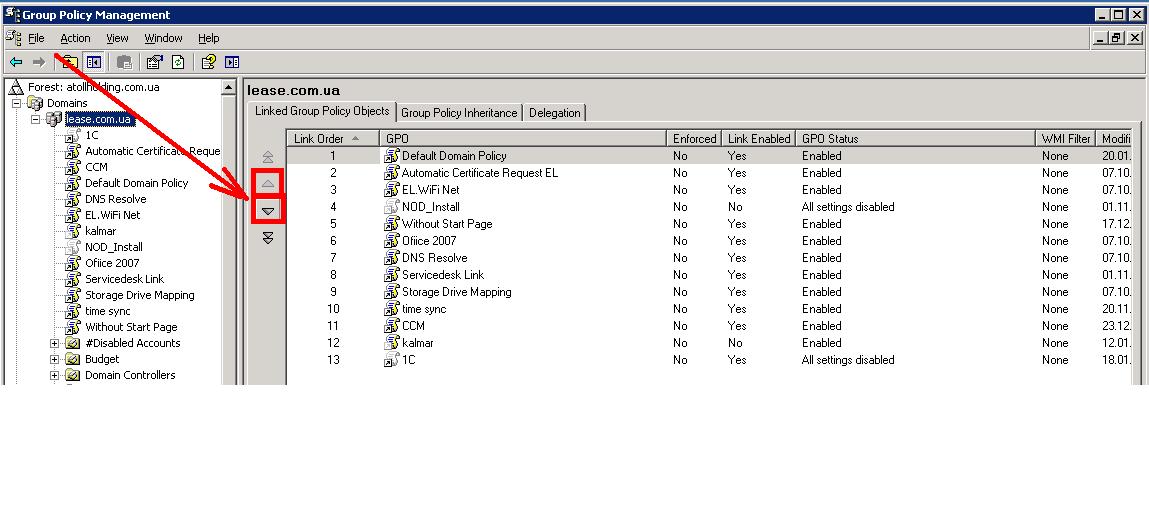
# 摘要
本论文全面介绍了组策略对象(GPO)的基本概念、策略设置、高级管理技巧、案例分析以及安全策略和自动化管理。GPO作为一种在Windows域环境中管理和应用策略的强大工具,广泛应用于用户配置、计算机配置、安全策略细化与管理、软件安装与维护。本文详细讲解了策略对象的链接与继承、WMI过滤器的使用以及GPO的版本控制与回滚策略,同时探讨了跨域策略同步、脚本增强策略灵活性以及故障排除与
高级CMOS电路设计:传输门创新应用的10个案例分析

# 摘要
本文全面介绍了CMOS电路设计基础,特别强调了传输门的结构、特性和在CMOS电路中的工作原理。文章深入探讨了传输门在高速数据传输、模拟开关应用、低功耗设计及特殊功能电路中的创新应用案例,以及设计优化面临的挑战,包括噪声抑制、热效应管理,以及传输门的可靠性分析。此外,本文展望了未来CMOS技术与传输门相结合的趋势,讨论了新型
计算机组成原理:指令集架构的演变与影响

# 摘要
本文综合论述了计算机组成原理及其与指令集架构的紧密关联。首先,介绍了指令集架构的基本概念、设计原则与分类,详细探讨了CISC、RISC架构特点及其在微架构和流水线技术方面的应用。接着,回顾了指令集架构的演变历程,比较了X86到X64的演进、RISC架构(如ARM、MIPS和PowerPC)的发展,以及SIMD指令集(例如AVX和NEON)的应用实例。文章进一步分析了指令集
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
TSPL2批量打印与序列化大师课:自动化与效率的完美结合

# 摘要
TSPL2是一种广泛应用于打印和序列化领域的技术。本文从基础入门开始,详细探讨了TSPL2的批量打印技术、序列化技术以及自动化与效率提升技巧。通过分析TSPL2批量打印的原理与优势、打印命令与参数设置、脚本构建与调试等关键环节,本文旨在为读者提供深入理解和应用TSPL2技术的指
【3-8译码器构建秘籍】:零基础打造高效译码器

# 摘要
3-8译码器是一种广泛应用于数字逻辑电路中的电子组件,其功能是从三位二进制输入中解码出八种可能的输出状态。本文首先概述了3-8译码器的基本概念及其工作原理,并
EVCC协议源代码深度解析:Gridwiz代码优化与技巧

# 摘要
本文全面介绍了EVCC协议和Gridwiz代码的基础结构、设计模式、源代码优化技巧、实践应用分析以及进阶开发技巧。首先概述了EVCC协议和Gridwiz代码的基础知识,随后深入探讨了Gridwiz的架构设计、设计模式的应用、代码规范以及性能优化措施。在实践应用部分,文章分析了Gridwiz在不同场景下的应用和功能模块,提供了实际案例和故障诊断的详细讨论。此外,本文还探讨了
JFFS2源代码深度探究:数据结构与算法解析

# 摘要
JFFS2是一种广泛使用的闪存文件系统,设计用于嵌入式设备和固态存储。本文首先概述了JFFS2文件系统的基本概念和特点,然后深入分析其数据结构、关键算法、性能优化技术,并结合实际应用案例进行探讨。文中详细解读了JFFS2的节点类型、物理空间管理以及虚拟文件系统接口,阐述了其压
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )