MATLAB自然语言处理:入门指南与实践技巧
发布时间: 2024-12-10 01:06:38 阅读量: 3 订阅数: 15 

MATLAB入门指南:编程技巧.docx
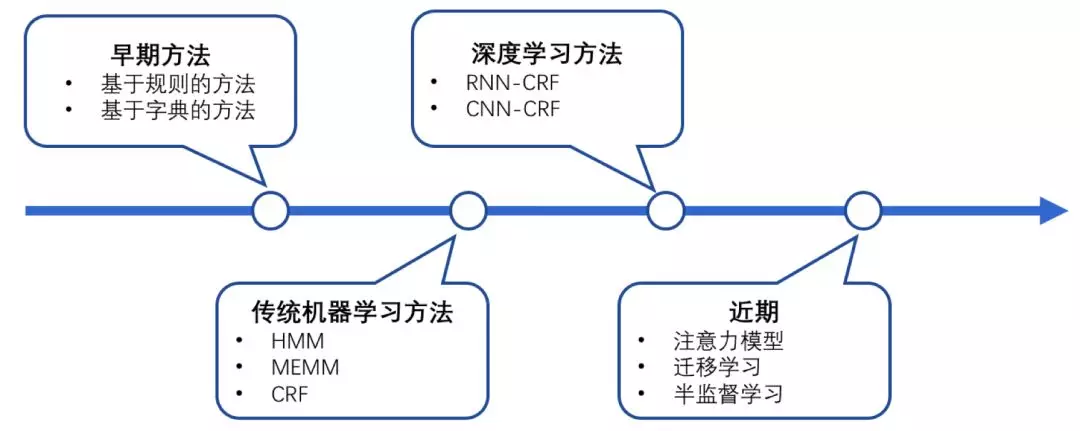
# 1. MATLAB自然语言处理基础
自然语言处理(NLP)是计算机科学和人工智能领域的一个重要分支,它涉及到计算机理解、解释和生成人类语言的能力。MATLAB作为一种强大的数学计算和工程设计软件,其在NLP领域的应用也日益广泛。本章旨在为读者提供MATLAB自然语言处理的基础知识,包括其应用场景、核心概念以及与其他编程语言在NLP上的差异和优势。
在开始使用MATLAB进行自然语言处理前,理解NLP的基本目标和常用术语至关重要。NLP涵盖的任务多种多样,例如词性标注、句法分析、语义分析、情感分析和机器翻译等。MATLAB为我们提供了一套完整的工具箱(如Text Analytics Toolbox),从而简化了处理流程,允许用户能够直接在MATLAB环境中构建和测试复杂的自然语言处理应用。
接下来的章节将详细介绍MATLAB中实现自然语言处理的各个方面,包括文本预处理技术、文本向量化方法以及具体的实践案例研究。读者在掌握了基础知识后,将能够深入探索MATLAB在NLP领域的高级应用,并学会如何优化和管理一个NLP项目。
# 2. MATLAB中的文本预处理技术
在自然语言处理(NLP)领域,文本预处理是一个至关重要的步骤。预处理可以去除文本数据中的噪声,并将其转换为适合机器学习模型处理的格式。MATLAB作为强大的数学计算和数据分析工具,提供了丰富的函数和工具箱用于执行文本预处理任务。本章节将深入探讨MATLAB中的文本预处理技术,并详细介绍关键的子章节内容。
## 2.1 文本清洗的基本步骤
### 2.1.1 删除停用词和标点符号
在文本预处理中,首先需要清理的是停用词和标点符号。停用词是文本中频繁出现但对理解文本含义贡献较小的词汇,如英语中的"the"、"is"等。标点符号同样需要清除,因为它们对于理解句子的情感或主题帮助不大。在MATLAB中,可以通过以下步骤进行删除操作:
```matlab
text = "MATLAB is an excellent tool for NLP, but is it the best?";
stopWords = ["is", "but", "it", "the", "for", "an", "and", "or", "in"];
punctuation = [',', '.', '?', ';', ':', '!', '"', '\''];
% Remove punctuation
for i = 1:length(punctuation)
text = strrep(text, punctuation(i), '');
end
% Remove stop words
stopWordsCell = strvcat(stopWords);
text = strrep(text, stopWordsCell, '');
```
该代码块展示了如何移除文本中的标点符号和停用词。注意`strrep`函数用于替换文本中的特定字符串,而`strvcat`函数将字符串数组垂直拼接。处理后的文本将更加清洁,有助于后续的NLP处理。
### 2.1.2 词干提取和词形还原
为了将文本简化为基本形式,词干提取和词形还原则是必要的步骤。词干提取是将单词还原到词根形式,而词形还原则是将单词还原到基本形式。MATLAB可以使用第三方工具或自定义函数实现这两种操作。例如,使用PorterStemmer进行词干提取:
```matlab
import java.io.File;
import javax.nlp.Stemmer;
stemmer = Stemmer(); % 实例化词干提取器
words = split(text, ' '); % 分词
stemmedWords = cell(size(words)); % 初始化词干词列表
for i = 1:length(words)
stemmer.loadDictionaryFromFile(File("english-small.txt"));
stemmedWords{i} = stemmer.stemSentence(words{i});
end
% 重建文本
stemmedText = strjoin(stemmedWords, ' ');
```
上述代码中,我们使用了Java的`Stemmer`类来提取词干。MATLAB允许直接调用Java类,这为文本处理提供了更广泛的选项。注意,需要下载并指定词干词典文件路径。
## 2.2 分词与词性标注
### 2.2.1 分词算法和应用场景
分词是将连续文本分割成单个的词语或词汇单元。在汉语等无空格语言中,分词尤其重要。MATLAB中可以使用`regexp`函数进行基本的分词操作:
```matlab
text = "MATLAB是处理自然语言的强大工具";
text = regexprep(text, '[\s]', ''); % 移除空格,为分词做准备
tokens = regexp(text, '\w+', 'match'); % 提取单词
```
在上述代码中,`regexprep`用于移除所有空格,而`regexp`则使用正则表达式匹配所有单词字符序列。这个过程可以应用于初步的分词。
### 2.2.2 词性标注的原理与实践
词性标注(Part-of-Speech Tagging)是指识别文本中每个单词的语法类别(如名词、动词、形容词等)。MATLAB中没有内置的词性标注工具,但可以使用外部NLP包来实现此功能。
```matlab
import nltk.POSTagger; % 导入NLTK词性标注器
tagger = POSTagger(); % 实例化词性标注器
text = "MATLAB is powerful.";
tags = tagger.tag(text); % 获取词性标注结果
```
这里展示了一个与NLTK交互的例子,MATLAB通过Java接口与NLTK这样的NLP库进行交互。实际应用中,需要确保相关库或工具已经安装并配置好。
## 2.3 文本向量化方法
### 2.3.1 Bag of Words模型
文本向量化是将文本转换为数值向量的过程,这在机器学习模型中是必需的。Bag of Words模型是一种简单的文本向量化方法,它只关注单词在文档中出现的频率。
```matlab
from sklearn.feature_extraction.text import CountVectorizer;
vectorizer = CountVectorizer();
text = ["MATLAB NLP", "NLP tool"];
bow = vectorizer.fit_transform(text).toarray(); % 创建词频向量
% 输出词袋模型矩阵
disp(bow);
```
在本例中,使用了`CountVectorizer`类进行词袋模型的构建。此代码是MATLAB与Python的交互示例,MATLAB能够调用Python库中的函数。
### 2.3.2 TF-IDF权重计算
TF-IDF(Term Frequency-Inverse Document Frequency)是一种衡量词汇在文档集中重要性的统计方法。该方法能够减少常见词汇对模型的影响,突出稀有词汇的重要性。MATLAB提供了相应的函数实现TF-IDF计算:
```matlab
document = ["MATLAB is a great tool for NLP.", "NLP in MATLAB is powerful."];
count = countWords(document); % 计算词频
tfidf = tfidfMatrix(count, numDocuments(document)); % 计算TF-IDF矩阵
```
这里`countWords`和`numDocuments`是假定的MATLAB内置函数,用于计算词频和文档数。实际应用中,需要使用MATLAB的文本处理工具箱或自定义函数进行相应计算。
### 2.3.3 Word2Vec词嵌入技术
Word2Vec是一种现代的词嵌入技术,它通过预训练神经网络模型将单词映射到高维空间中,使得语义上相近的单词在高维空间中也彼此靠近。MATLAB提供了深度学习工具箱(Deep Learning Toolbox),其中包含了对Word2Vec的支持。
```matlab
filename = "word2vec.bin"; % 假设这是已经训练好的Word2Vec模型文件
wordVectors = loadWordEmbedding(filename);
% 计算单词向量
wordVec = wordVectors("NLP");
```
代码中的`loadWordEmbedding`是自定义函数,用于加载预训练的Word2Vec模型。实际操作时,你可能需要下载一个预训练好的模型或使用自己的数据集进行训练。
## 小结
本章详细介绍了MATLAB在文本预处理方面的一系列技术。从基本的文本清洗到分词、词性标注,再到文本的向量化技术,每一环节都是NLP流程中的关键步骤。通过MATLAB,可以有效地实现这些预处理任务,并为进一步的自然语言处理工作打下坚实的基础。下一章将探讨MATLAB在NLP领域的实际应用案例,如情感分析、文本分类、机器翻译和语言生成等。
# 3. MATLAB自然语言处理实践案例
## 3.1 情感分析应用
### 3.1.1 构建情感分析模型
情感分析是自然语言处理的一个重要应用,它旨在识别和提取文本中的主观信息。在MATLAB中,我们可以使用其丰富的数据处理和机器学习库来构建情感分析模型。以下是构建情感分析模型的步骤。
首先,需要准备和预处理数据集。情感分析的数据集通常包含文本以及对应的标签,例如正面或负面情感。数据预处理可能包括文本清洗、分词、去除停用词等。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MATLAB 机器学习工具箱中强大的模型评估和优化功能。通过一系列文章,您将学习专家级的数据预处理技巧,以构建高效的机器学习模型。此外,您还将掌握从数据到模型优化的全流程,了解如何使用 MATLAB 工具箱评估模型性能、调整超参数并优化模型结果。无论您是机器学习新手还是经验丰富的从业者,本专栏都将为您提供宝贵的见解和实用指南,帮助您充分利用 MATLAB 机器学习工具箱,构建和优化高性能的机器学习模型。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
GT-POWER网格划分技术提升:模型精度与计算效率的双重突破

参考资源链接:[GT-POWER基础培训手册](https://wenku.csdn.net/doc/64a2bf007ad1c22e79951b5
【MAC版SAP GUI快捷键大全】:提升工作效率的黄金操作秘籍

参考资源链接:[MAC版SAP GUI快速安装与配置指南](https://wenku.csdn.net/doc/6412b761be7fbd1778d4a168?spm=1055.2635.3001.10343)
# 1. MAC版SAP GUI简介与安装
## 简介
SAP GUI(Graphical User Interface)是访问SAP系统
【隧道设计必修课】:FLAC3D网格划分与本构模型选择实用技巧
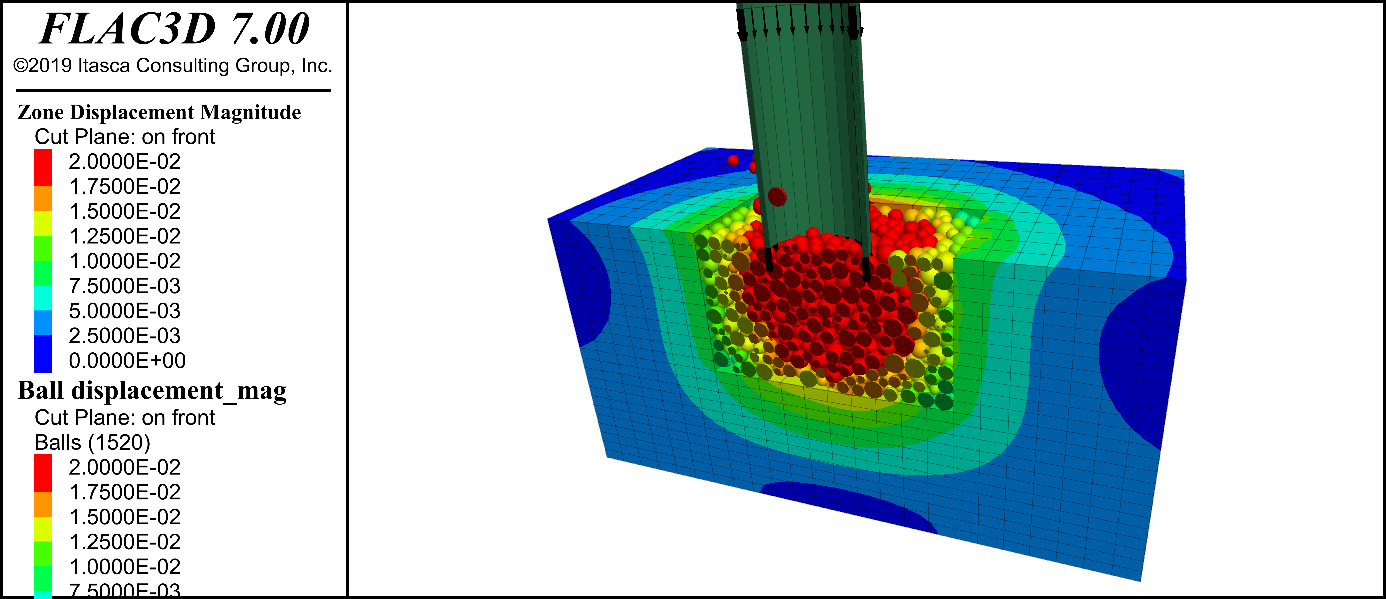
参考资源链接:[FLac3D计算隧道作业](https://wenku.csdn.net/doc/6412b770be7fbd1778d4a4c3?spm=1055.2635.3001.10343)
# 1. FLAC3D简介与应用基础
在本章中,我们将为您介绍FLAC3D(Fast Lagrangian Analysis of Continua in 3 Dimensions)的基础知识以及如何在工程
【故障诊断】:扭矩控制常见问题的西门子1200V90解决方案

参考资源链接:[西门子V90PN伺服驱动参数读写教程](https://wenku.csdn.net/doc/6412b76abe7fbd1778d4a36a?spm=1055.2635.3001.10343)
# 1. 扭矩控制概念与西门子1200V90介绍
在自动化与精密工程领域中,扭矩控制是实现设备精确
【Android设备安全必备】:Unknown PIN问题的彻底解决方案
参考资源链接:[unknow PIn解决方案](https://wenku.csdn.net/doc/6412b731be7fbd1778d496d4?spm=1055.2635.3001.10343)
# 1. Unknown PIN问题概述
## 1.1 问题的定义与重要性
Unknown PIN问题通常指用户在忘记或错误输入设备_PIN码后,导致设备锁定,无
【启动速度翻倍】:提升Java EXE应用性能的10大技巧
参考资源链接:[Launch4j教程:JAR转EXE全攻略](https://wenku.csdn.net/doc/6401aca7cce7214c316eca53?spm=1055.2635.3001.10343)
# 1. Java EXE应用性能概述
Java作为广泛使用的编程语言,其应用程序的性能直接影响用户体验和系统的稳定性。Java EXE应用是指那些通过特定打包工具(如Launc
Python Requests高级技巧大揭秘:动态请求头与Cookies管理

参考资源链接:[python requests官方中文文档( 高级用法 Requests 2.18.1 文档 )](https://wenku.csdn.net/doc/646c55d4543f844488d076df?spm=1055.2635.3001.10343)
# 1. 动态请求头与Cookies管理基础
## 1.1 互联网通信
iOS实时视频流传输秘籍:构建无延迟的直播系统
参考资源链接:[iOS平台视频监控软件设计与实现——基于rtsp ffmpeg](https://wenku.csdn.net/doc/4tm4tt24ck?spm=1055.2635.3001.10343)
# 1. 实时视频流传输基础
## 1.1 视频流传输的核心概念
- 视频流传输是构建实时直播系统的核心技术之一,涉及到对视频数据的捕捉、压缩、传输和解码等环节。掌握这些基本概念对于实现高质量
【绘制软件大比拼】:AutoCAD与其它工具在平断面图中的真实对决

参考资源链接:[输电线路设计必备:平断面图详解与应用](https://wenku.csdn.net/doc/6dfbvqeah6?spm=1055.2635.3001.10343)
# 1. 绘制软件大比拼概览
绘制软件领域竞争激烈,为满足不同用户的需求,各种工具应运而生。本章将为读者提供一个概览,介绍市场上流行的几款绘制软件及其主要功能,帮助您快速了解每款软件
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )